







DiMix: Disentangle-and-Mix Based Domain Generalizable Medical Image Segmentation
摘要
框架介绍与背景
深度学习技术的迅速发展使得在各个领域都有了重大的革新,但将这项技术有效地应用到新颖和陌生的环境中仍然是一个重大挑战,尤其是在像医学这样专业和昂贵的领域。
解决方案提出
本文介绍了一种新颖的框架,利用基于变换器的解耦学习和样式混合来增强模型的泛化能力,使其能够在未知环境的数据集上表现良好。
关键创新
该框架识别出在不同领域之间不变的特征,并通过内容-样式的解耦和图像合成的结合来学习区分与领域无关的特征。
方法
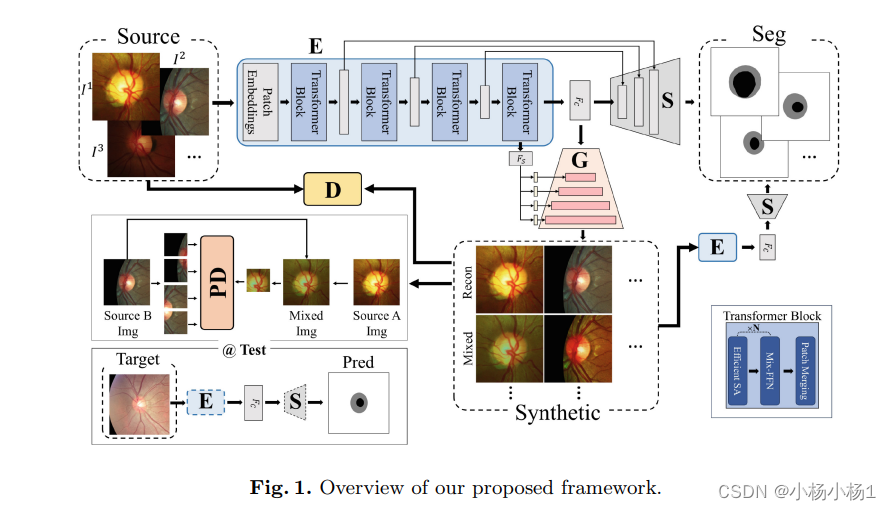
编码器E采用了分层Transformer架构,该架构通过考虑多尺度特征提高了效率和灵活性。这种方法已在先前的研究中得到了充分的记录。分层Transformer能够高效提取多样化的数据表示,相比传统的视觉Transformer具有计算优势。
在Transformer编码器中,使用了三个关键机制:高效自注意力(Efficient SA)、混合前馈网络(Mix-FFN)和补丁合并(Patch Merging)。每个机制在Transformer块内捕获和处理信息时起着重要作用。
高效自注意力机制利用自注意力机制计算查询(Q)、键(K)和值(V)头部。为了减少计算复杂度,我们引入了减少比率(R),以降低计算成本。
在混合前馈网络机制中,我们将卷积层整合到前馈网络(FFN)中,以解决位置信息的潜在泄漏问题。该过程表示为:
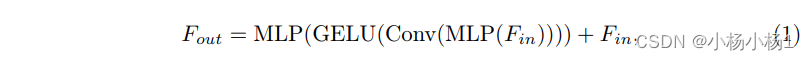
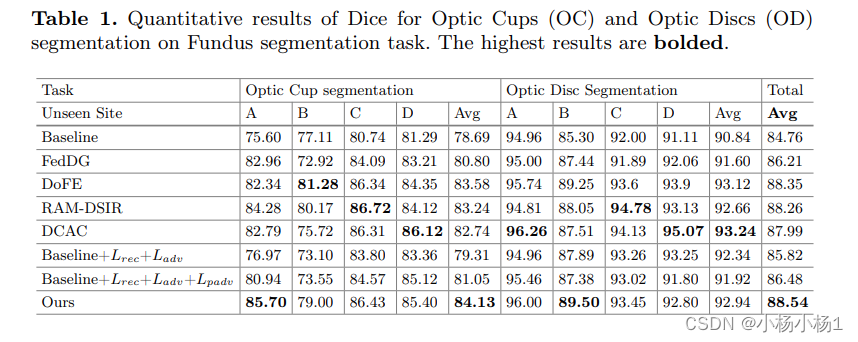
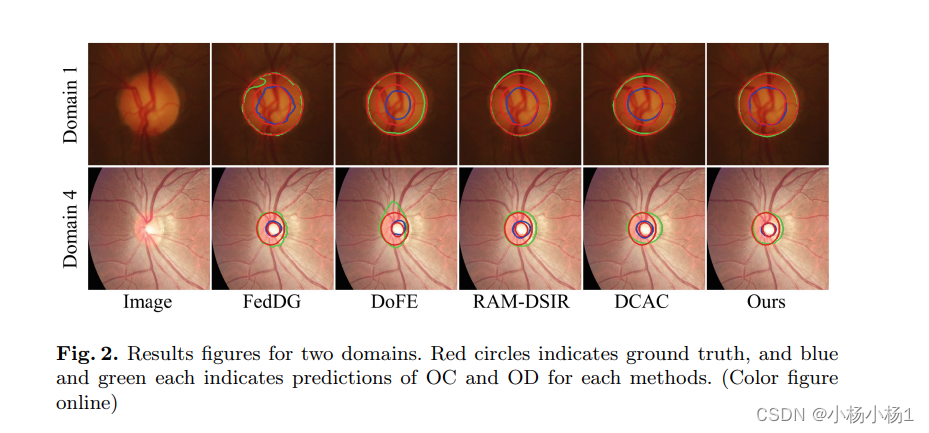
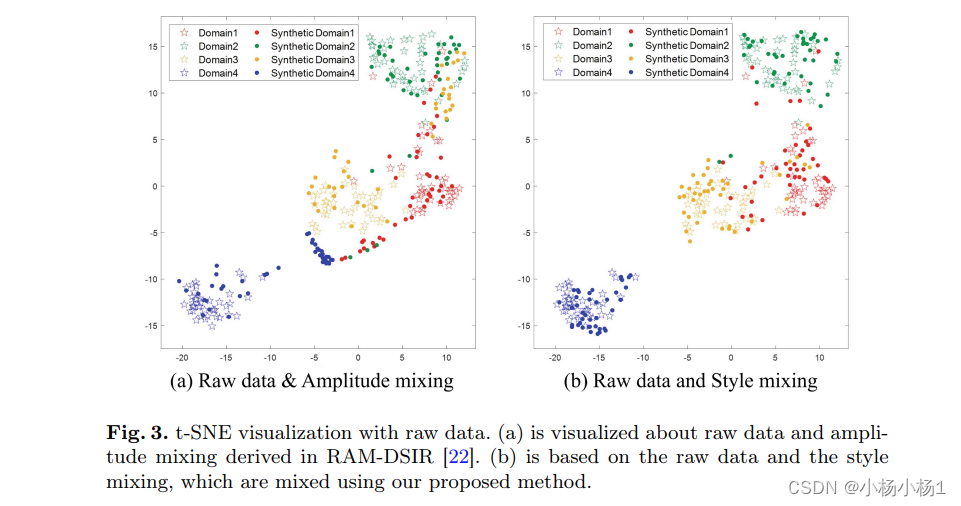
实验结果

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











