







文章目录
HIFUSE: HIERARCHICAL MULTI-SCALE FEATURE FUSION NETWORK FOR MEDICAL IMAGE CLASSIFICATION
摘要
在卷积神经网络(CNN)的推动下,医学图像分类得到了快速发展。由于卷积核的感受野大小固定,很难捕获医学图像的全局特征。尽管基于自注意的Transformer可以对长程依赖关系进行建模,但它具有较高的计算复杂性,并且缺乏局部归纳偏差。大量研究表明,全局和局部特征对图像分类至关重要。然而,医学图像具有许多噪声、分散的特征、类内变异和类间相似性。
本文方法
- 提出了一种三分支层次多尺度特征融合网络结构HiFuse,作为一种新的医学图像分类方法。
- 可以从多尺度层次融合Transformer和CNN的优势,而不破坏各自的建模,从而提高各种医学图像的分类精度。
- 设计了局部和全局特征块的并行层次结构,以在不同语义尺度上有效地提取局部特征和全局表示,具有在不同尺度上建模的灵活性和与图像大小相关的线性计算复杂性。
- 此外,设计了一种自适应层次特征融合块(HFF块),以综合利用在不同层次上获得的特征。
- HFF块包含空间注意力、通道注意力、残差反向MLP以及自适应融合每个分支的各种尺度特征之间的语义信息的快捷方式
代码地址
本文方法
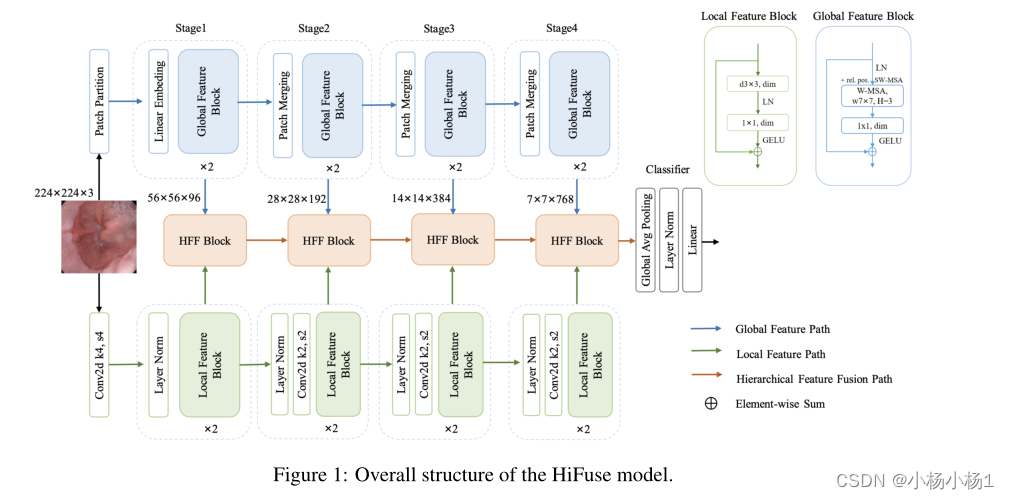
旨在有效地获取不同尺度医学图像的局部空间信息和全局语义表示。我们使用并行结构从全局和局部特征块中提取医学图像的全局和局部信息,通过HFF块融合不同层次的特征,下采样步骤,最终获得分类结果。在接下来的部分中,我们首先介绍了HiFuse模型的总体结构,然后分别介绍了全局特征块和局部特征块。下面是HFF区块的详细信息
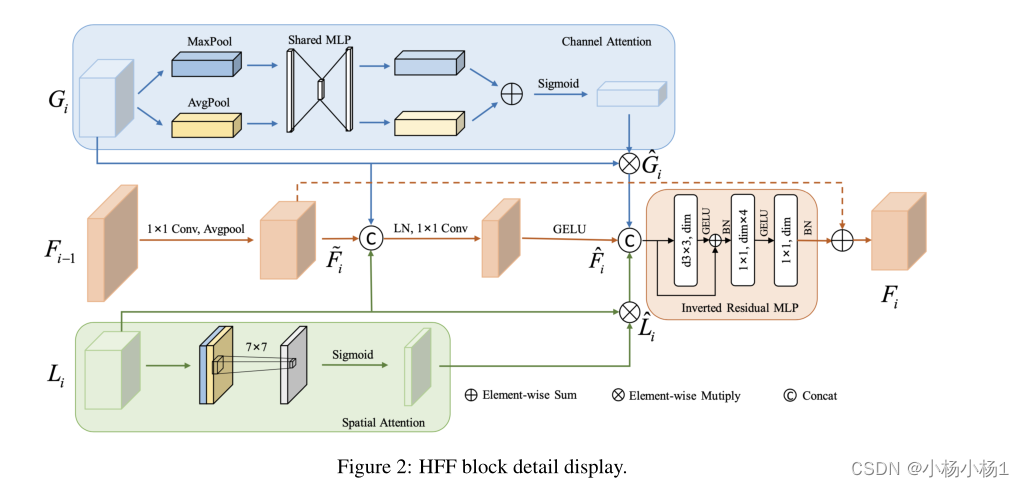
自适应层次特征融合块可以根据输入特征,自适应地融合来自不同层次的局部特征、全局表示以及来自先前层次的融合后的语义信息,如图2所示。其中,Gi表示全局特征块输出的特征矩阵,Li表示局部特征块输出特征矩阵,Fi−1表示前一阶段HFF输出的特征阵,Fi表示该阶段HFF融合生成的特征阵
由于全局特征块中的自注意可以捕获空间和时间全局信息,在一定程度上,HFF块将传入的全局特征馈送到通道注意力(CA)机制中,该机制利用通道映射之间的相互依赖性来改进特定语义的特征表示。
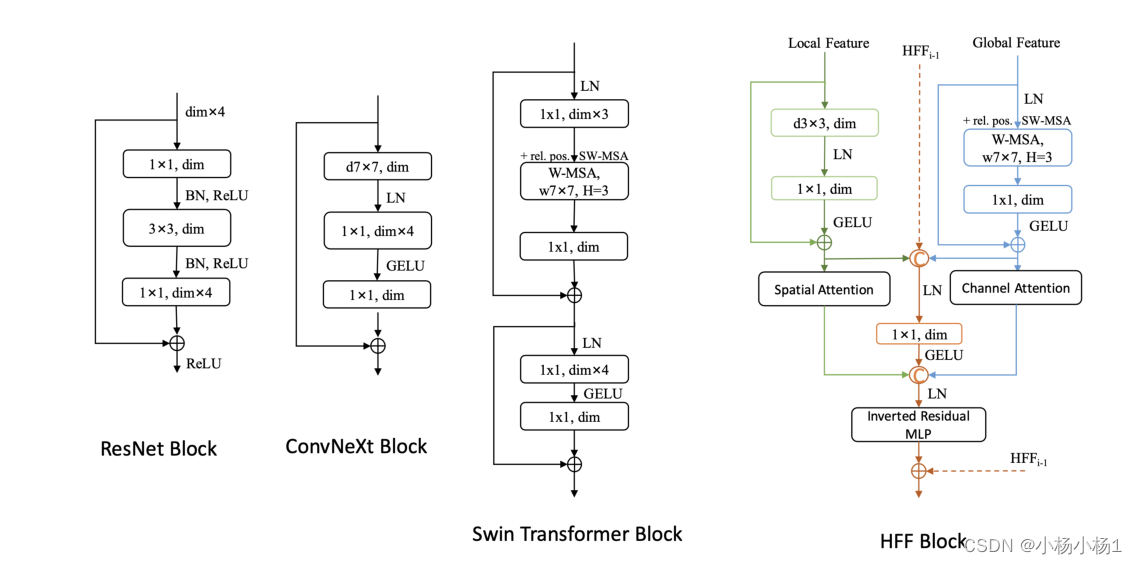
局部特征被输入到空间注意力(SA)机制中,以增强局部细节并抑制不相关区域。最后,每个注意力产生的结果和融合路径将进行特征融合,并连接残差反向MLP(IRMLP)。在一定程度上,避免了梯度消失、爆炸和网络退化的问题,从而有效地捕捉了每个层次的全局和局部特征信息。对于ResNet、Swin Transformer、ConvneXt和我们的HFF块的结构比较,如图3所示。该过程如所示
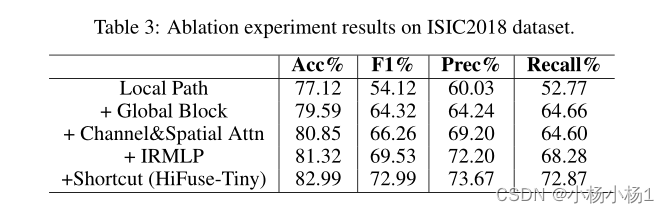
实验结果

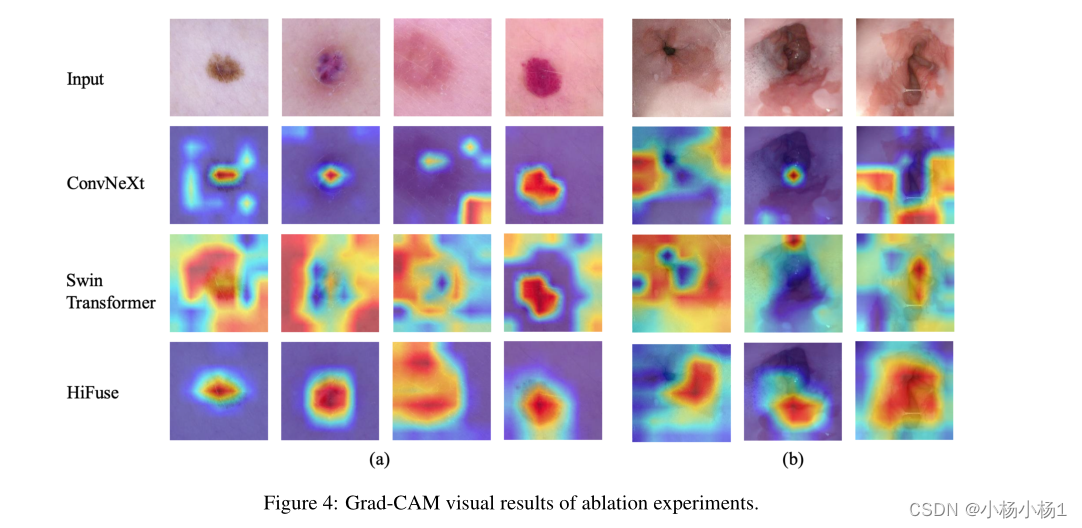
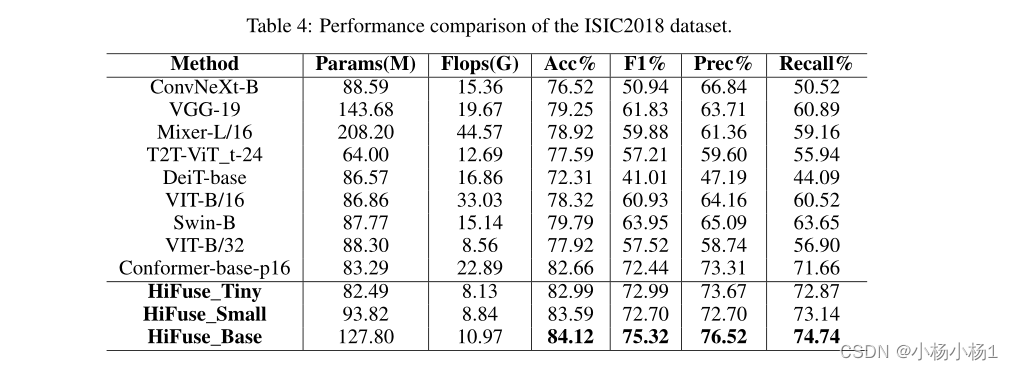
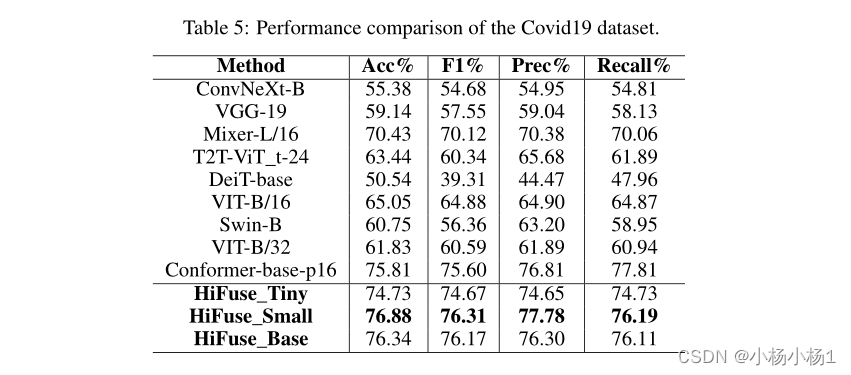
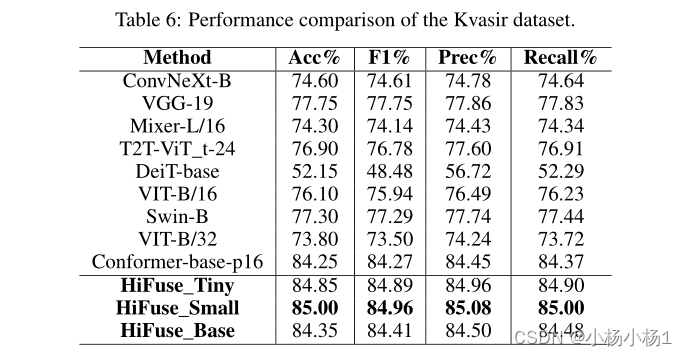


















 6296
6296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











