







文章目录
Laplacian-Former: Overcoming the Limitations of Vision Transformers in Local Texture Detection
摘要
近期研究表明,Vision Transformer(ViT)模型在各种计算机视觉任务中表现出色。然而,相较于传统的卷积神经网络(CNN)模型,ViT模型往往难以捕捉图像的高频信息,这可能限制了其对局部纹理和边缘信息的准确感知能力。鉴于人体组织中的异常情况(如肿瘤和病变)在结构、纹理和形状上存在巨大差异,因此高频信息,尤其是纹理信息,对于有效的语义分割任务至关重要。
本文通过自适应地重新校准拉普拉斯金字塔中的频率信息来增强自注意力图。
利用了双注意力机制,包括高效的注意力和频率注意力。高效的注意力机制将自注意力的复杂度降低到线性,并产生相同的输出,有选择性地增强了形状和纹理特征的贡献。
还引入了一种新颖的高效增强多尺度桥接,有效地将编码器中的空间信息传递到解码器中,同时保留了基本特征。
方法
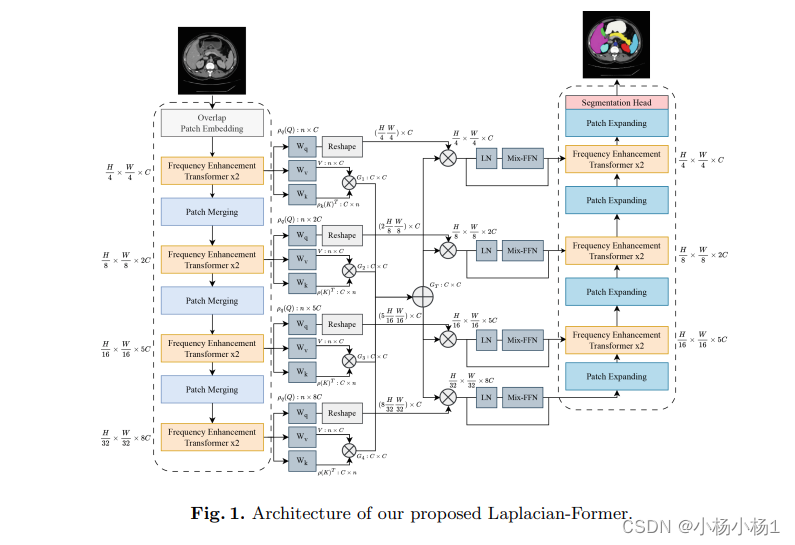
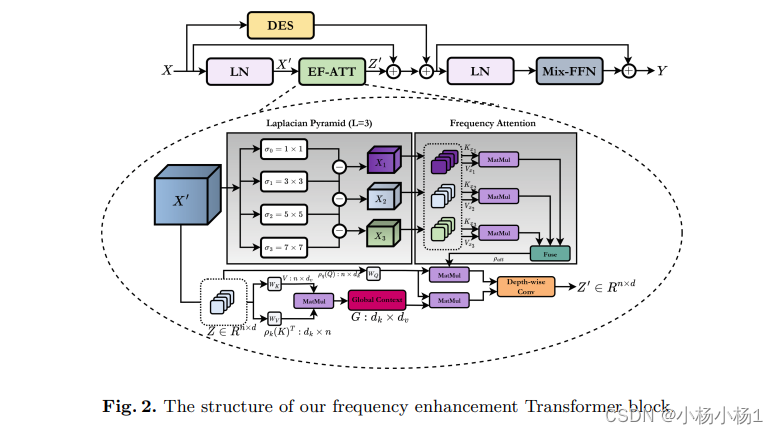
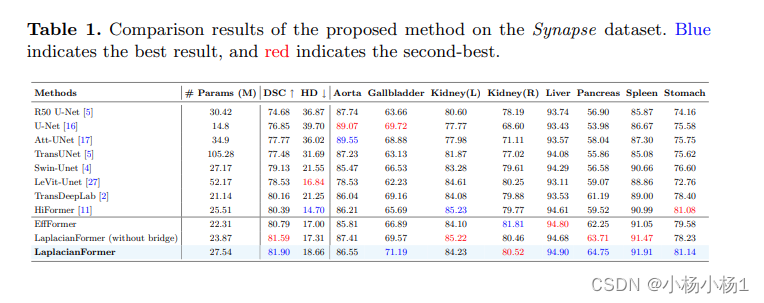
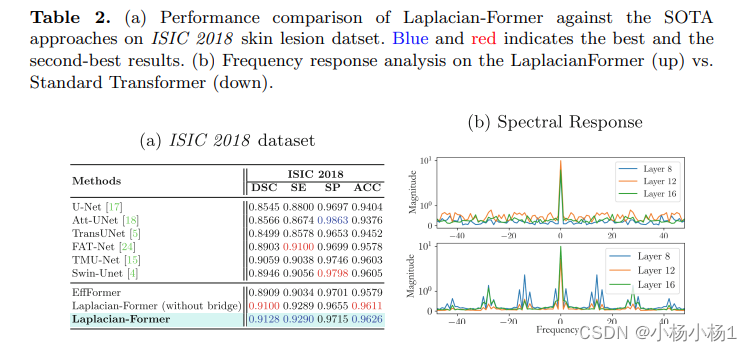
实验结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











