







Vision Transformer Based Multi-class Lesion Detection in IVOCT
摘要
心血管疾病是一种高致死率的疾病。血管内光学相干断层扫描(IVOCT)技术可以显著帮助诊断和治疗心血管疾病。然而,从数百张IVOCT图像中定位和分类病变是一项耗时且具有挑战性的任务,尤其对于初级医生而言更是如此。因此,一种自动病变检测和分类模型是非常可取的。为了实现这一目标,
在本研究中,首先收集了一个IVOCT数据集,包括来自69个IVOCT数据的2,988张图像,以及跨三个类别的4,734个病变标注。基于新收集的数据集,提出了一种基于Vision Transformer的多类病变检测模型,称为G-Swin Transformer。
模型的关键部分是网格注意力机制,用于建模连续IVOCT图像之间的关系。通过大量实验证明,所提出的G-Swin Transformer能够有效地定位IVOCT图像中的不同类型的病变,明显优于基线方法在所有评估指标上的表现。代码可以通过以下链接获得。
代码地址
方法
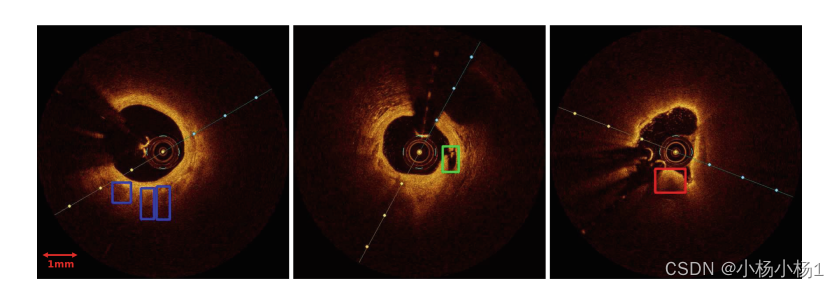
Fig. 1. 数据集的示例图像和标注。每个IVOCT数据都转换为PNG图像进行标注。蓝色/绿色/红色框分别表示巨噬细胞、空洞/剥离、血栓的边界框。(在线彩色图)
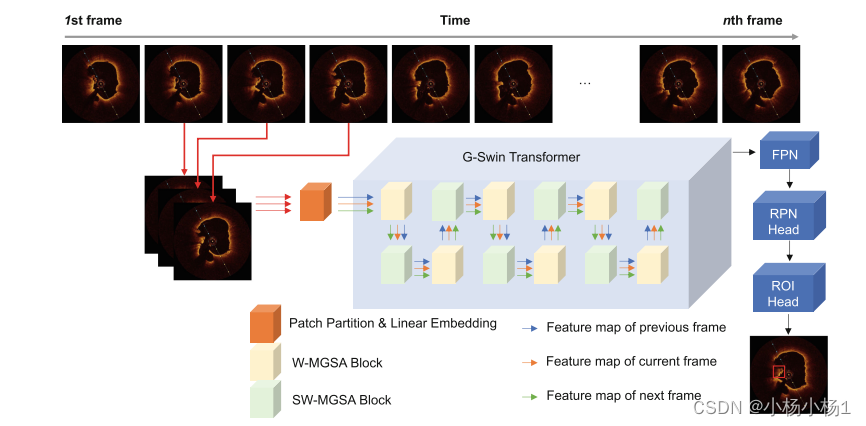
Fig. 2. 整体模型结构。提出的G-Swin Transformer被用作骨干网络。检测头部遵循Faster-RCNN的头部设计。W-MGSA和SW分别指窗口式多头网格自注意力和平移窗口。
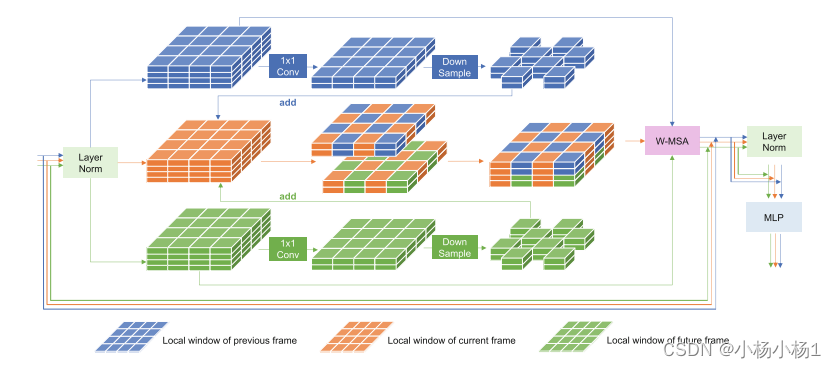
Fig. 3. 所示为提出的网格注意力。蓝色/橙色/绿色特征图分别属于前一帧/当前帧/下一帧的局部窗口。在进行维度缩减和下采样操作后,前一帧和下一帧的特征图被添加到当前帧的特征图中。(彩图在线)
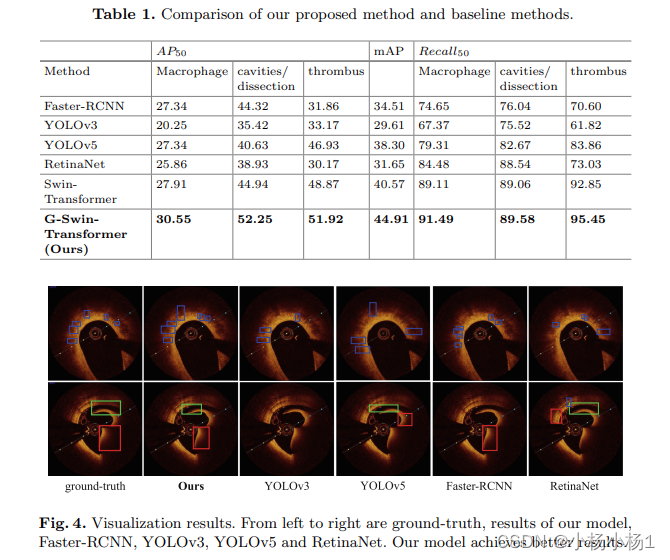
实验结果

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











