









介绍:Impala是Cloudera开发的新型查询系统,它能够对存储在HDFS、HBaseImpala是Cloudera开发的新型查询系统,它能够对存储在HDFS、HBase以及S3上的数据进行快速的交互式SQL查询。此外,Impala与Hive使用了统一的存储系统、同样的元数据库、SQL语法(Hive SQL)、ODB等。
Impala是由C++编写的基于MPP(massively parallel processing)理念的查询引擎,由运行在CDH集群上的不同的守护进程组成,它跟Hive的metastore集成,共用database和tables等信息。具体来说,Impala由三种进程组成:Impalad。
使用impala,用户可以使用传统的SQL知识以极快的速度处理存储在HDFS、HBase和Amazon s3中的数据中的数据,而无需了解Java(MapReduce作业)。由于在数据驻留(在Hadoop集群上)时执行数据处理,因此在使用Impala时,不需要对存储在Hadoop上的数据进行数据转换和数据移动。然而,Impala也有其缺点,例如不提供任何对序列化和反序列化的支持;只能读取文本文件,而不能读取自定义二进制文件。
总的来说,Impala的最大卖点和最大特点就是快速。通过Impala,你可以使用SELECT、JOIN和聚集函数等语法,实时地查询储存在HDFS或HBase上的数据。
1、impala官网
1.1 介绍
1.2 下载
1.3 学习文档
1.4 文档下载
网址:https://impala.apache.org/docs/build/impala-4.3.pdf
2、w3cschool网站
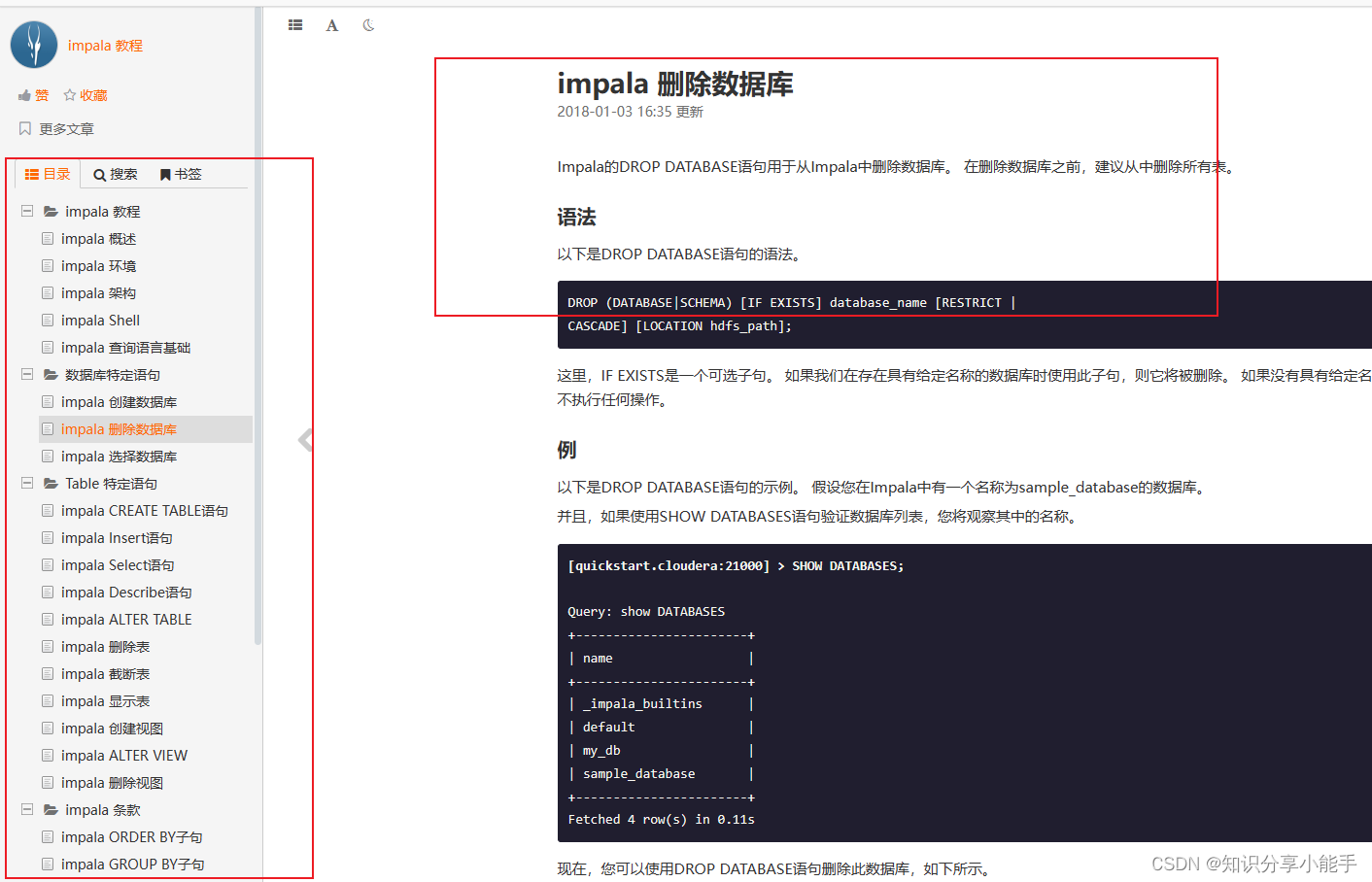
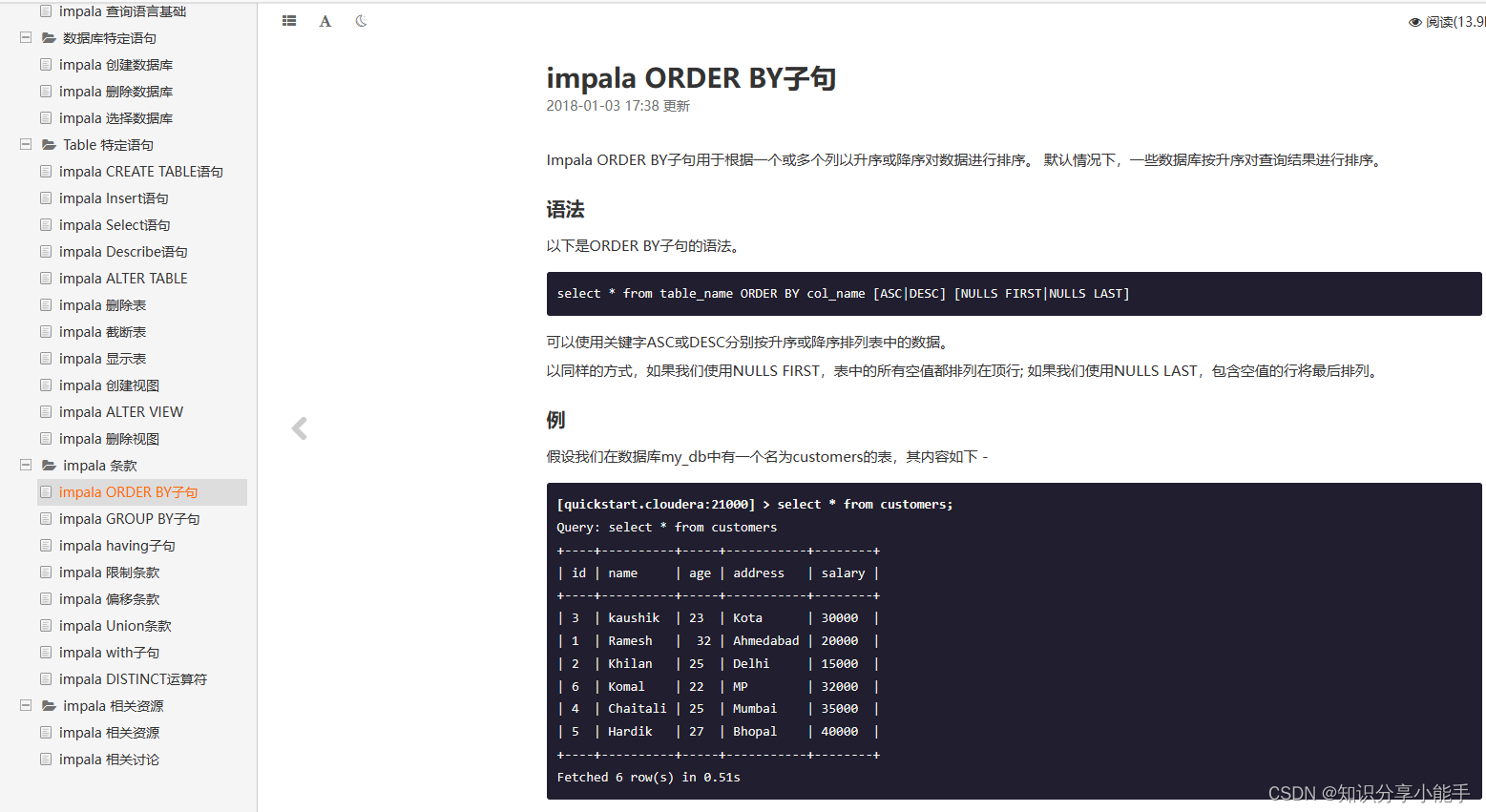
网址:https://www.w3cschool.cn/impala/impala_drop_database.html
2.1 学习内容
3、impala中文网站
网址:https://www.dba.cn/book/impala/IMPALAJiaoCheng/IMPALAGaiShu.html
3.1学习内容
4、学习视频推荐
1、大数据Impala教程丨构建高性能交互式SQL分析平台
网址:https://www.bilibili.com/video/BV1AK411M7Gg/?spm_id_from=333.337.search-card.all.click&vd_source=849186cc0cbe77dd51dcd8d1dc63a69b
2、【尚硅谷】大数据技术之Impala视频教程
网址:https://www.bilibili.com/video/BV1GA411E7V9/?spm_id_from=333.337.search-card.all.click&vd_source=849186cc0cbe77dd51dcd8d1dc63a69b
5 安装部署
网址:https://blog.51cto.com/u_15105906/2864366
以上就是个人觉得不错的学习网站,希望能帮到学习大数据的人!















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









