






Towards Effective Multiple-in-One Image Restoration:A Sequential and Prompt Learning Strategy
论文链接:https://arxiv.org/abs/2401.03379
项目链接:https://github.com/Xiangtaokong/MiOIR
摘要
尽管单一任务图像恢复(IR)已经取得了显著的成功,但训练一个能够同时处理多个IR任务的单一模型仍然是一个挑战。在本项工作中,我们深入研究了包含七个流行IR任务的多合一(MiO)IR问题。我们指出MiO IR面临两个关键挑战:多样化目标的优化和对多个任务的适应。为了应对这些挑战,我们提出了两种简单但有效的策略。第一个策略,称为顺序学习,试图解决如何优化多样化目标的问题,它指导网络以递增的方式逐个学习单独的IR任务,而不是将它们混合在一起。第二个策略,即提示学习,试图解决如何适应不同的IR任务,它帮助网络理解特定任务并提高泛化能力。通过在19个测试集上的评估,我们证明了顺序和提示学习策略可以显著提高常用CNN和Transformer骨干网络的MiO性能。我们的实验还揭示了这两种策略可以相互补充,以学习更好的退化表示并增强模型的鲁棒性。预计我们提出的MiO IR公式和策略可以促进研究如何训练具有更高泛化能力的IR模型。
为了解决上述问题,我们提出了多合一(multiple -in- one, MiO) IR的构想,旨在使用单一模型处理多个IR任务。在MiO IR中有两个关键的挑战:多样化目标优化和任务自适应。然后,我们制定了两种有效的互补策略-顺序学习和提示学习-分别尝试解决这两个挑战。具体来说,我们考虑了7种流行的红外任务,包括超分辨率、去模糊、去噪、去jpeg、去训练、去雾和弱光增强,并训练一个单一的模型来处理它们。与以往研究的设置相比,本文提出的MiO设置**采用高质量的GT图像生成训练和测试数据,避免了低质量监督信号的风险。**这种配方也使我们能够探索MiO IR的独特挑战。
相关概念:
图像恢复与提示学习。提示学习最初是通过研究如何将额外的文本(即提示)作为输入引入到预训练的大型语言模型中,从而获得所需的输出。随着研究的深入,在模型训练或微调中使用不同形式的提示变得越来越普遍。
持续学习。持续学习研究从无限数据流中学习。这种情况是,在训练期间一次只有一个或几个任务可用。因此,持续学习的主要挑战是灾难性遗忘:模型在先前学习任务上的表现会随着新任务的加入而下降。然而,在我们的MiO IR问题中,所有的数据在训练过程中总是可用的,而灾难性遗忘不是我们所关心的。我们提出的顺序学习策略不同于持续学习。
多合一IR模型学习
3.1 多合一图像恢复模型学习
多合一(MiO)图像恢复旨在使用单一模型处理多个图像恢复任务,其中每个任务的输入图像都受到了单一类型的退化影响。我们选择7个任务包括超分辨率、去模糊、去噪、DeJPEG、去雨、去雾和低光照增强。注意,这7个任务已经覆盖了大多数常见的图像恢复任务。MiO图像恢复可以很容易地扩展到更多的任务。MiO图像恢复模型训练有两个关键挑战。一个挑战是模型优化。所选的图像恢复任务具有不同的退化类型,这可能导致严重的训练冲突。在用不同输入优化模型时,训练曲线可能会剧烈振动,导致陷入不良的局部最小值。另一个挑战是任务适应。期望MiO图像恢复模型能够识别退化类型并执行相应的图像恢复任务。换句话说,它应该能够适应不同的图像恢复任务,并且具有高准确度。这两个挑战使得MiO图像恢复成为一个比单一任务图像恢复更困难的任务。在本项工作中,我们进行了初步尝试,并提出了两种策略来解决这两个挑战。我们希望我们的工作能够激发出更多、更好的解决方案来应对MiO图像恢复问题。
3.2 顺序学习
第一个策略是顺序学习,目的是应对多任务图像恢复(MiO IR)中不同任务优化目标的多样化挑战。如前所述,在MiO IR模型的训练过程中,所有训练数据都是可用的,并且不涉及灾难性遗忘的问题。关键问题是如何为这些任务
{
X
t
}
t
∈
[
T
]
\{X^t\}_{t \in [T]}
{Xt}t∈[T] 找到一个更好的学习策略。一个直接的方法是将所有任务的训练数据混合在一起来训练模型。然而,一些预训练工作发现,即使在非对应图像恢复任务上的预训练也能为其他图像恢复任务的训练提供良好的起点。基于这一观察,如果让网络先学习一些任务,那么先前的任务可以被视为预训练任务,从而为后续任务的训练提供良好的基础。有许多方法可以将
T
T
T 个任务分成不同的组进行顺序训练。作为初步探索,我们采取了最简单的方法。如下图b所示,我们的顺序学习策略是逐步学习图像恢复任务,我们在每一步中增加一个任务,同时在后续的训练步骤中保留先前的任务。至于任务的顺序,我们通过实验发现,许多学习序列都能带来提升。然而,通常更好的做法是先学习那些需要重建高频细节的任务(例如,超分辨率和去模糊等),然后学习那些需要全局亮度调整的任务(例如,去雾和低光照增强)
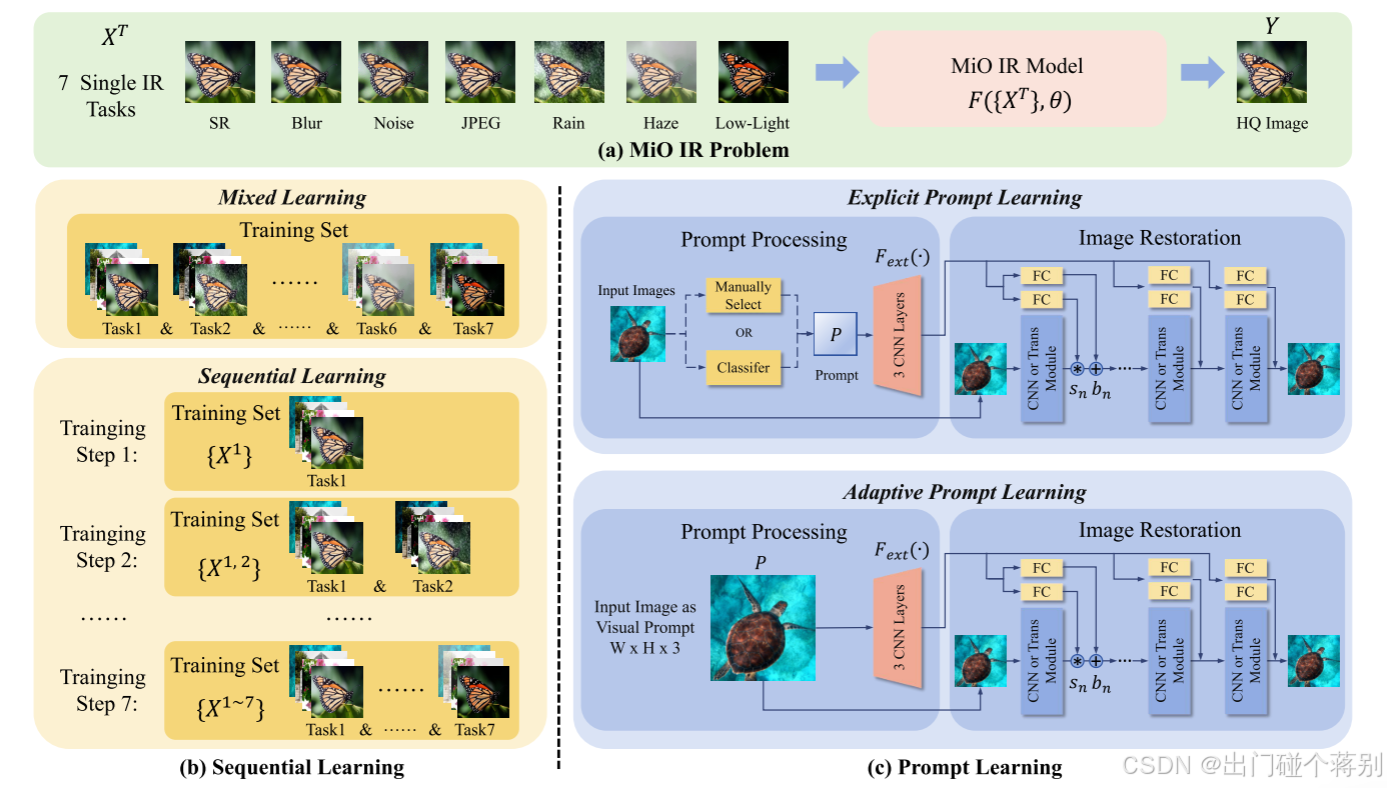
3.3 提示学习
第二个策略是提示学习,旨在解决任务适应的挑战。适当的提示可以帮助网络理解当前的图像恢复任务,并相应地调整重建的方向。在本文中,我们的目标是探索提示学习在MiO IR中的有效性和行为。为此,我们提出了两种最典型且直接的方法:显式提示学习和自适应提示学习。如图c所示,这两种方法在提示提取和注入方面具有相同的选项。我们使用3层CNN作为提取器 F ext ( ⋅ ) F_{\text{ext}}(\cdot) Fext(⋅)从提示( P )中提取特征,然后应用全连接层 F C ( ⋅ ) FC(\cdot) FC(⋅)将特征转换为相应模块输出的合适形状,包括比例 s s s和偏置 b b b。然后我们将 s s s与输出特征相乘并加上 b b b。提示学习过程可以表示为:
s
m
,
b
m
=
F
C
m
(
F
ext
(
P
)
)
,
s_m, b_m = FC_m(F_{\text{ext}}(P)),
sm,bm=FCm(Fext(P)),
f
m
prompt
=
f
m
⋅
s
m
+
b
m
,
f_m^{\text{prompt}} = f_m \cdot s_m + b_m,
fmprompt=fm⋅sm+bm,
其中 f m f_m fm是第 m m m个网络模块的输出特征。提示特征在每个模块之后注入。对于显式提示学习,我们将一个固定的提示与每个图像恢复任务绑定,并在训练和测试期间通过分类器来选择相应的提示。此外,我们也可以手动指定任务类型来选择相应的提示。
由于训练一个高准确度的分类器来识别IR任务类型并不困难,因此无论是使用分类器还是手动选择,都可以被视为直接向网络提供明确的任务类型信息。考虑到显式提示学习的难度并不高,它在分布内数据上的表现应该很好。然而,在真实世界的低质量图像中,有时甚至人类观察者也无法明确地识别出IR任务的类型,因此在这种情况下,显式提示学习可能会失败。自适应提示学习可以作为一种补救措施,我们使用输入图像作为视觉提示来自适应地提取任务类型信息。如图c所示,它与显式提示学习的结构相同,不同之处在于输入图像被用作提示,而不是任何额外的输入。由于我们没有对提示提取器施加任何额外的约束,自适应提示学习模型比显式提示学习更难训练。然而,一旦训练完成,它具有更好的分布外泛化能力,因为网络能够自行决定提取哪些特征。通过引入这两种典型的提示学习方法,我们可以更好地探索它们与提出的顺序学习策略之间的相互促进关系。
4.1 实现细节
训练和测试数据。如第3.1节所述,MiO IR包含7个流行的IR任务,7个退化图像对应一个共同的高质量GT图像
y
y
y。因此,我们使用DIV2K和Flickr2K中的3,450张2K分辨率的图像作为GT。通过将7种类型的退化应用于GT图像,我们获得了24,150张用于训练的低质量(LQ)图像。

表1. 我们使用三组测试集(共19个)来评估模型在分布内、分布外和未知任务数据上的性能。
对于测试,如表1所示,我们准备了三组测试集,即In-Dis、Out-Dis和Unknown。首先,我们从Unsplash收集了100张高质量(HQ)图像,命名为MiO100,作为GT,并将其退化为In-Dis和Out-Dis组,使用7种退化。In-Dis的退化参数与训练数据制备时使用的参数相同,而Out-Dis的参数则超出了训练数据分布。Unknown组包含5个测试集,这些测试集的退化未知(或未公开)来自各种IR竞赛。关于训练和测试数据生成的更多细节,请参见附录。
训练设置。我们使用SRResNet和SwinIR作为代表性的CNN和Transformer骨干网络来评估提出的MiO IR学习策略。所有模型都基于PyTorch构建。在模型训练期间,采用L1损失 [53],并使用Adam优化器 [20](β1 = 0.9, β2 = 0.999)。对于SRResNet,批量大小设置为16,对于SwinIR,批量大小为8。补丁大小为128×128。初始学习率设置为2×10^-4,并通过余弦退火策略衰减至10^-7。对于SRResNet,余弦周期为250K次迭代,对于SwinIR,周期为100K。我们分别训练模型10个周期,即总共2,500K和1,000K次迭代。
对于顺序学习,在第1周期使用一个任务 {X1},在第2周期使用两个任务 {X1,2},依此类推。最后,从第7周期开始使用所有任务 {X1~7}。换句话说,我们在前6个周期内逐步添加IR任务,然后从第7周期开始训练所有任务。除非另有说明,训练顺序是超分辨率(‘S’)、去模糊(‘B’)、去噪(‘N’)、DeJPEG(‘J’)、去雨(‘R’)、去雾(‘H’)和低光照增强(‘L’),表示为‘SBNJRHL’。此外,我们为显式提示学习训练了一个简单的分类器,使用交叉熵损失。在1,000K次迭代后,它在In-Dis测试集上达到了0.997的准确率,可以被视为明确知道任务类型。为了比较,我们通过在每个周期混合所有训练数据 {X1~7} 来训练模型。我们称这种学习方法为混合学习,作为我们顺序学习策略的参考。顺序学习的Task Sequence。虽然我们发现顺序学习通常比混合学习表现更好(见表2),但不同IR任务的学习顺序扮演了重要角色。我们将7个任务分为两类:需要局部细节增强的任务,包括‘S’、‘B’、‘N’、‘J’和‘R’,以及需要全局亮度调整的任务,包括‘H’和‘L’。我们使用不同的任务序列来训练SRResNet,并在表2中列出了结果,其中‘H’和‘L’用红色标记。
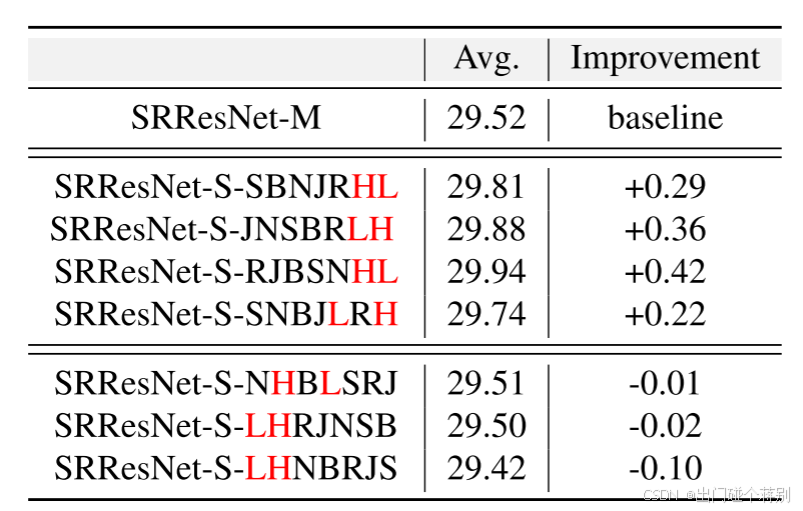
混合学习方法,表示为‘-M’,用作基线。可以看出,当早期学习全局亮度调整任务时,与基线相比,性能提升很小,甚至略有下降。然而,当早期学习细节增强任务时,大多数序列都可以将性能提高0.2 dB以上。请注意,我们的目标不是穷举所有可能的7个任务的顺序,而是找到一个设置任务顺序的原则。因此,在大多数实验中,我们选择了‘SBNJRHL’序列,这不是表2中最好的一个,但足以说明顺序学习策略的有效性。
4.2 学习策略的有效性
在本节中,我们首先在分布内/分布外测试集上应用我们提出的两种学习策略,并评估SRResNet和SwinIR学习到的MiO模型,以验证它们的有效性并分析它们的行为。结果如表3所示,其中混合学习(表示为“-M”)用作基线,“-S”表示顺序学习,“-EP”和“-AP”分别表示显式和自适应提示学习。例如,“SRResNet-S+EP”表示使用顺序学习和显式提示学习训练的SRResNet。
顺序学习的有效性。 首先,我们评估顺序学习在In-Dis测试组上的有效性。如表3所示,与混合学习(“-M”)相比,基本顺序学习(“-S”)可以提高SRResNet/SwinIR在7个任务上的平均PSNR 0.29/0.85 dB。值得一提的是,从SRResNet在去噪任务上的0.18 dB到SwinIR在去雨任务上的2.31 dB,使用这两种骨干网络的所有7个任务的性能都得到了提升,即使是训练最少的任务(即低光照增强)。与混合学习相比,顺序学习改变了训练数据的分布,允许某些任务得到更多的训练。然而,我们的实验验证了主要由于更好的优化而不是仅仅改变不同任务之间的训练数据分布,因为所有任务的性能都得到了提升。
提示学习的有效性。然后,我们通过将其与基线混合学习结合起来评估提示学习的有效性。通过比较表3中“M”与“-M+EP”或“-M+AP”的结果,我们可以看到显式提示学习可以将平均PSNR提高约0.7 dB。然而,自适应提示学习仅使SRResNet提高了0.08 dB,甚至使SwinIR降低了0.60 dB。如第3.3节所述,这是因为自适应提示模型的训练难度更大。这也是所有先前开发的自适应提示学习方法[25, 50, 61]需要额外约束的原因。顺序学习和提示学习的相互促进。顺序学习和提示学习策略针对MiO IR中的不同挑战,并且它们可以相互补充。具体来说,与混合学习基线相比,SwinIR-S+EP和SwinIR-S+AP的性能分别提高了1.21 dB和0.95 dB。如上一段所述,自适应提示学习在与混合学习策略结合时难以训练;然而,当与顺序学习结合时,其性能提高了1.55 dB(SwinIR骨干网络)。这些定量结果表明,这两种策略可以相互补充。不同模型在7个In-Dis测试集上的MiO IR结果的视觉比较如图3所示。我们可以看到,用我们的策略训练的模型与混合训练相比,可以获得更好的视觉效果。更多的视觉比较在附录中提供。
结论
在这项工作中,我们制定了MiO IR问题,并确定了其两个主要挑战-不同目标的优化和对不同任务的适应。针对这些挑战,我们分别提出了顺序学习策略和提示学习策略。这两种策略对CNN和Transformer主干都有很好的效果,它们可以相互促进来学习有效的图像表示。我们的大量实验证明了它们比混合学习基线有显著的优势。此外,他们可以用更少的提示参数来增强最先进的类似于mio的方法。期望我们的发现能够激发更多的工作来解决具有挑战性的MiO IR问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









