






第三天,学习利用爬虫获取人脸数据,及数据分析数据可视化,通过百度人脸识别的数据分析得出统计图。
Day3作业
整合前三天的代码功能,要求包括数据采集、数据分析、数据可视化,把运行结果截图到日报中,只允许同小组的同学截图相同 。
人脸识别代码
可以实现检测年龄、颜值、性别、是否带眼镜
from aip import AipFace
import base64
""" 你的 APPID AK SK """
APP_ID = '26456423'
API_KEY = '9fYx8NCKyoZneZ3QfUSkCw1A'
SECRET_KEY = 'wLrN0SFtuvCUVYDZoD2qGa99kghi8RTt'
def img2base64(path):
"""
把图片文件转换为基于base64的字符串,以便用于网络传播
:param path: 图片的路径
:return: 转换后的结果
"""
file = open(path, 'rb') # 使用读取的方式去打开图片文件
data = file.read() # 读取文件信息
base = base64.b64encode(data) # base64编码
base = base.decode('utf-8') # 以utf-8的方式解码
file.close() # 关闭文件
return base # 返回数据
def detect_face():
"""
人脸检测
:return: 百度服务器返回的人脸检测数据
"""
client = AipFace(APP_ID, API_KEY, SECRET_KEY)#创建客户端
options = {"face_field":"age,beauty,gender,glasses"}#参数年龄、颜值、性别、眼镜
image = img2base64("000014.jpg")
result = client.detect(image, "BASE64" ,options)
print(result)
age = result['result']['face_list'][0]['age']
beauty = result['result']['face_list'][0]['beauty']
gender = result['result']['face_list'][0]['gender']['type']
glasses = result['result']['face_list'][0]['glasses']['type']
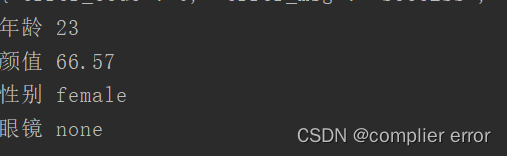
print("年龄", age)
print("颜值", beauty)
print("性别", gender)
print("眼镜", glasses)
if __name__ == '__main__':
detect_face()
使用方法
将下载的图片放到工程文件目录下,且此处代码改为图片后缀

数据采集、数据分析、数据可视化整合代码
from icrawler.builtin import BingImageCrawler
from aip import AipFace
import base64
import time # 用于延迟操作
import os # 用于文件操作
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType # 导入主题
# 颜值统计
count_class_1 = 0
count_class_2 = 0
count_class_3 = 0
count_class_4 = 0
count_class_5 = 0
count_class_6 = 0
count_class_7 = 0
count_class_8 = 0
count_class_9 = 0
count_class_10 = 0
count_class_error = 0
def bing_image_crawler(keyword, max_num):
"""
基于bing搜索引擎爬取图片
:param keyword: 关键字
:param max_num: 数量
"""
bing_crawler = BingImageCrawler(
feeder_threads=2,
parser_threads=4,
downloader_threads=8,
storage={'root_dir': 'bing'})
filters = dict(size='medium')
bing_crawler.crawl(keyword=keyword,
filters=filters,
max_num=max_num)
""" 你的 APPID AK SK """
APP_ID = '16966840'
API_KEY = 'B0e6QoxUB0gwQxxzWT6fCgMU'
SECRET_KEY = 'rGQji0R0X76e4CP9rbcdPbcNRdS6EwC9'
def img2base64(path):
"""
把图片文件转换为基于base64的字符串,以便用于网络传播
:param path: 图片的路径
:return: 转换后的结果
"""
file = open(path, 'rb')
data = file.read()
base = base64.b64encode(data)
base = base.decode('utf-8')
file.close()
return base
def detect_face(img_path):
"""
人脸检测
:param img_path: 人脸检测的图片路径
:return: 百度服务器返回的人脸检测数据
"""
client = AipFace(APP_ID, API_KEY, SECRET_KEY)
options = {"face_field": "age,beauty"}
image = img2base64(img_path)
return client.detect(image, "BASE64", options)
def parse_data(data):
"""
解析服务器返回的数据,并提取颜值分数,根据颜值分数进行等级划分
:param data: 服务器返回的原始结果数据
:return: 颜值等级
"""
# 颜值半秒,控制QPS
time.sleep(0.5)
if data['error_code'] != 0:
print("识别有问题", data)
# 计数+1
global count_class_error
count_class_error += 1
return -1 # 访问有问题
beauty = data['result']['face_list'][0]['beauty']
if beauty >= 90:
# 计数+1
global count_class_10
count_class_10 += 1
return 10
elif beauty >= 85:
# 计数+1
global count_class_9
count_class_9 += 1
return 9
elif beauty >= 75:
# 计数+1
global count_class_8
count_class_8 += 1
return 8
elif beauty >= 65:
# 计数+1
global count_class_7
count_class_7 += 1
return 7
elif beauty >= 55:
# 计数+1
global count_class_6
count_class_6 += 1
return 6
elif beauty >= 45:
# 计数+1
global count_class_5
count_class_5 += 1
return 5
elif beauty >= 35:
# 计数+1
global count_class_4
count_class_4 += 1
return 4
elif beauty >= 25:
# 计数+1
global count_class_3
count_class_3 += 1
return 3
elif beauty >= 15:
# 计数+1
global count_class_2
count_class_2 += 1
return 2
elif beauty >= 5:
# 计数+1
global count_class_1
count_class_1 += 1
return 1
else:
# 计数+1
count_class_error += 1
return -1 # 未知情况
def classify():
"""
【了解】本地磁盘中对各种颜值等级的图片进行分类
:return:无
"""
root_dir = 'bing'
# 列举所有目录下的文件和文件夹
file_list = os.listdir(root_dir)
# 遍历所有文件和文件夹
for i in range(0, len(file_list)):
# 拼装出文件路径
path = root_dir + '/' + file_list[i]
# 如果是文件
if os.path.isfile(path):
# 人脸识别获得其颜值等级
beauty = parse_data(detect_face(path))
# 按照颜值来创建文件夹,拼接出文件夹的路径
dic = root_dir + '/' + str(beauty) + '/'
# 如果识别有问题
if beauty == -1:
dic = 'bing/未识别/'
# 如果文件夹不存在,就新建一个
if not os.path.exists(dic):
os.makedirs(dic)
# 移动图片到等级文件夹中
# 参数1:源文件的路径
# 参数2:新文件的路径
os.rename(path, dic + file_list[i])
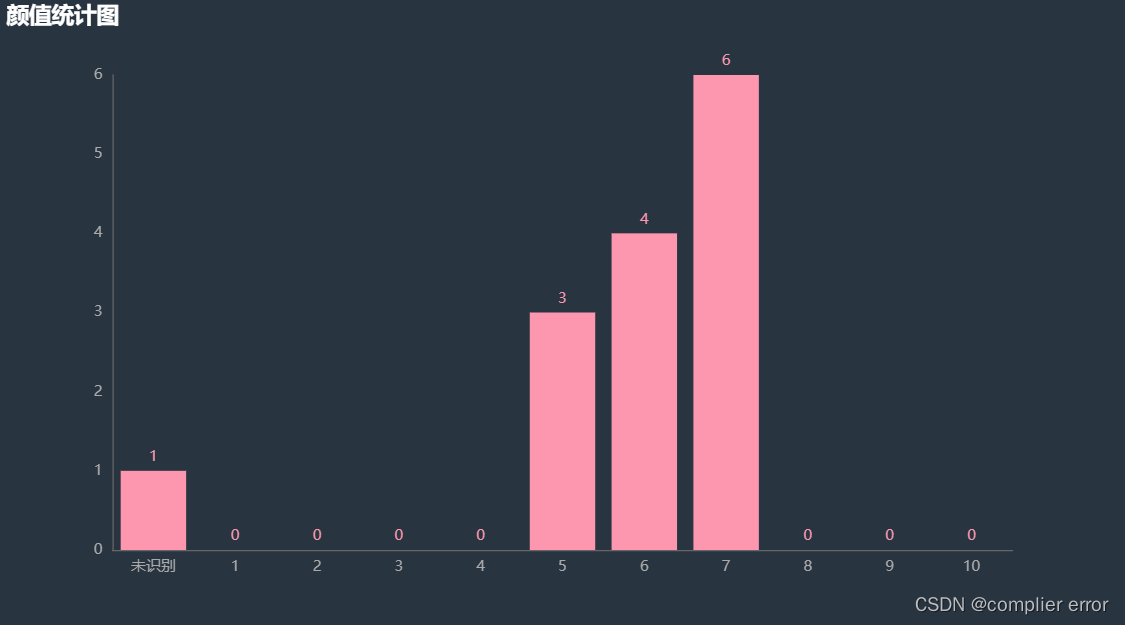
def draw_chart():
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
bar.add_xaxis(["未识别", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10"])
# 增加y轴
bar.add_yaxis("", [count_class_error,
count_class_1,
count_class_2,
count_class_3,
count_class_4,
count_class_5,
count_class_6,
count_class_7,
count_class_8,
count_class_9,
count_class_10])
bar.set_global_opts(title_opts=opts.TitleOpts(title="颜值统计图"))
bar.render()
if __name__ == '__main__':
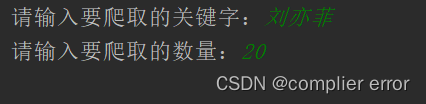
keyword = input("请输入要爬取的关键字:")
max_num = input("请输入要爬取的数量:")
max_num = int(max_num)
# 爬取
bing_image_crawler(keyword, max_num)
print("人脸识别分类中......")
# 分类(包括人脸识别和解析)
classify()
# 画图
draw_chart()
print("程序执行完成")
实现效果
爬取图片

**文件目录:**得到评分为8的图片
这是上次运行的结果得到新的结果得把文件目录的删掉。















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









