







前言:我用fastgpt直接连接chatglm3,没有使用oneai,不是很复杂,只需要对chatglm3项目代码做少量修改就能支持使用embeddings,向量模型用的m3e,效果还可以
我的配置:
处理器:i5-13500
显卡:RTX 4060Ti 16GB
内存:64GB
本文只是记录本人搭建过程,避免遗忘,写的不清楚望理解!
以下文件全部传至阿里云盘
1.ChatGLM3-6b代码
https://github.com/THUDM/ChatGLM3
模型很大,建议云盘下载
2.FastGPT
https://github.com/labring/FastGPT
3.向量模型m3e
https://huggingface.co/moka-ai/m3e-base
或
https://modelscope.cn/models/xrunda/m3e-base/files
注意:先安装合适的cuda和cudnn版本
cuda下载地址
https://developer.nvidia.com/cuda-toolkit-archive
cudnn下载地址
https://developer.nvidia.com/cudnn
安装步骤请参考
https://blog.csdn.net/Mind_programmonkey/article/details/99688839
部署步骤:
1.下载Anaconda
清华大学镜像网站速度很快
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
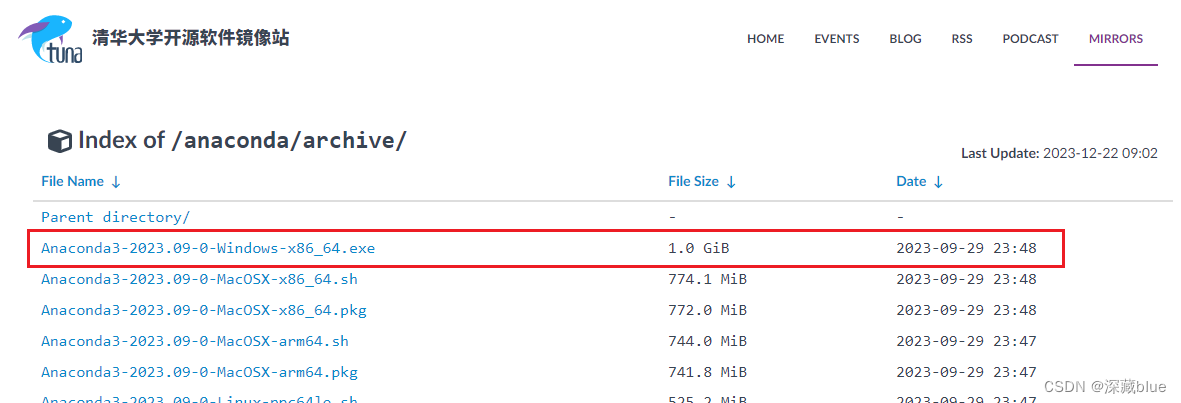
找到适合你系统的文件下载,我用的最新的
安装anaconda
执行以下命令创建chatglm3-6b的conda环境
conda create -n chatglm3-demo python=3.10
conda activate chatglm3-demo
请注意,chatglm3-6b项目需要 Python 3.10 或更高版本
创建完成后进入ChatGLM3-main\composite_demo目录中
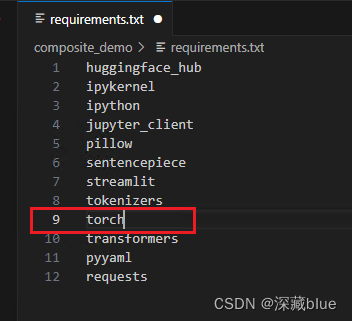
注意:建议把requirements.txt中的torch删掉,稍后重新安装,这个torch会下载成cpu版本的,用gpu运行会报错
然后执行
pip install -r requirements.txt
此外,使用 Code Interpreter 还需要安装 Jupyter 内核:
ipython kernel install --name chatglm3-demo --user
安装torch和torchvision
注意版本!!!
刚刚创建的conda环境是python3.10版本,torch和torchvision要和python版本对应
torch-2.0.0+cu117-cp310-cp310-win_amd64.whl
torchvision-0.15.0+cu117-cp310-cp310-win_amd64.whl
文件已传云盘
如果你需要的torch和torchvision不是这两个,请到下面网站查询下载
https://download.pytorch.org/whl/
在conda环境中安装torch和torchvision
进入torch和torchvision所在路径下
执行
pip install torch-2.0.0+cu117-cp310-cp310-win_amd64.whl
pip install torchvision-0.15.0+cu117-cp310-cp310-win_amd64.whl
我把模型和代码放在同级目录下
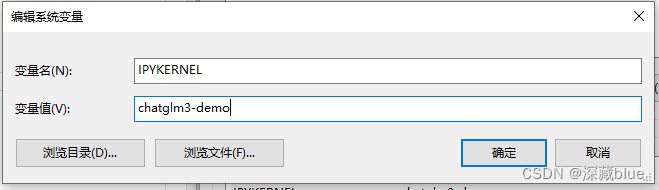
然后配置系统环境变量,新建两个环境变量,如下,MODEL_PATH填写你模型的路径
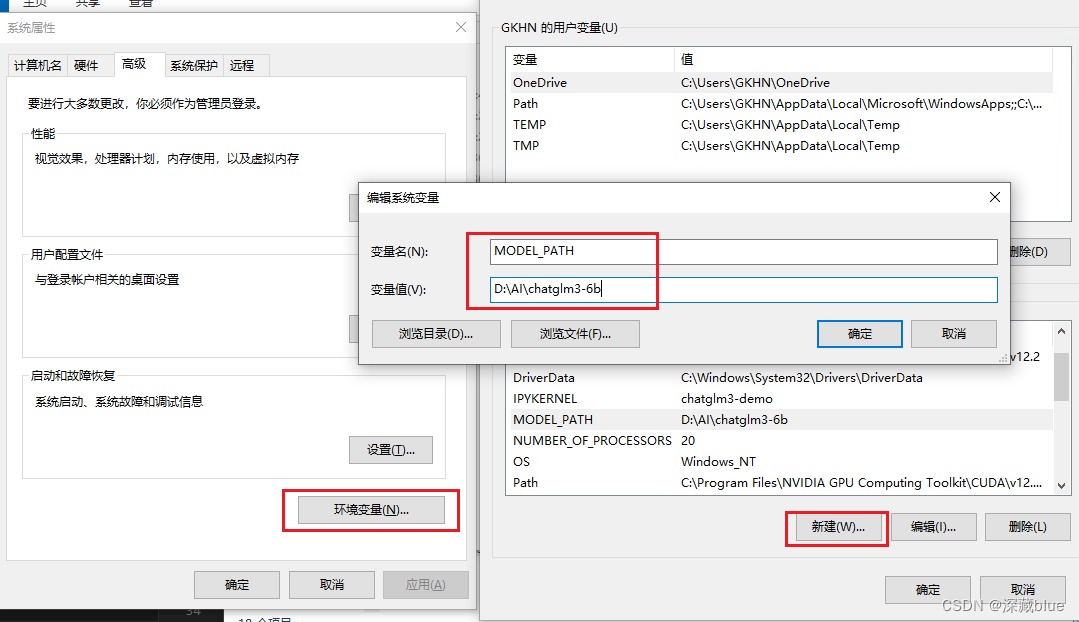
然后打开client.py修改下处
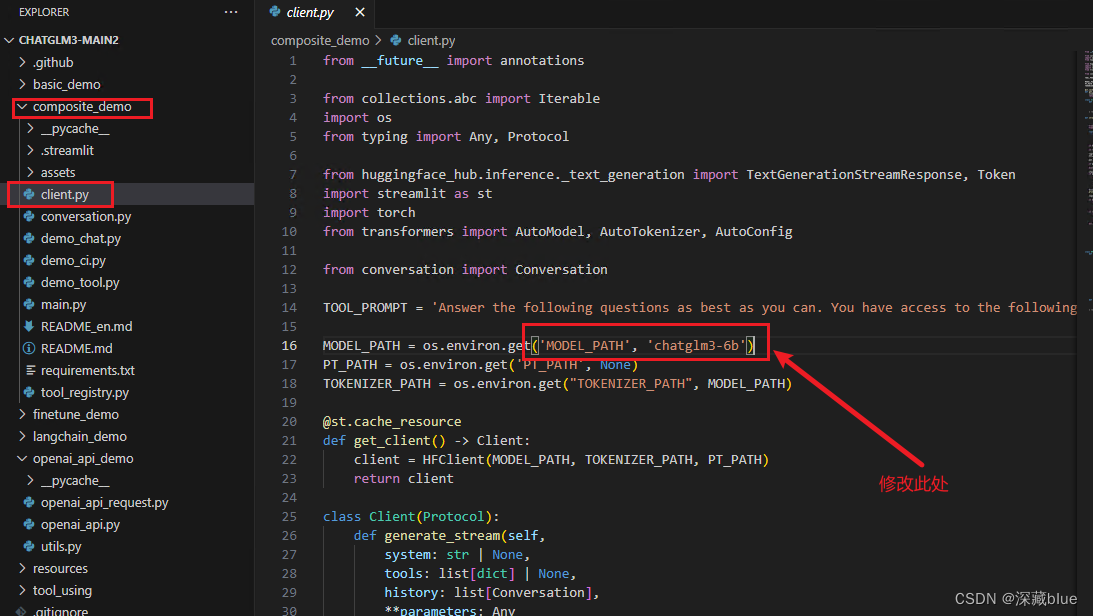 修改完
修改完
运行以下命令在本地加载模型并启动 demo:
streamlit run main.py
如果正常启动,证明环境和代码没有问题!
接下来配置openai_api.py实现知识库
2.配置openai_api.py实现知识库
1.修改openai_api.py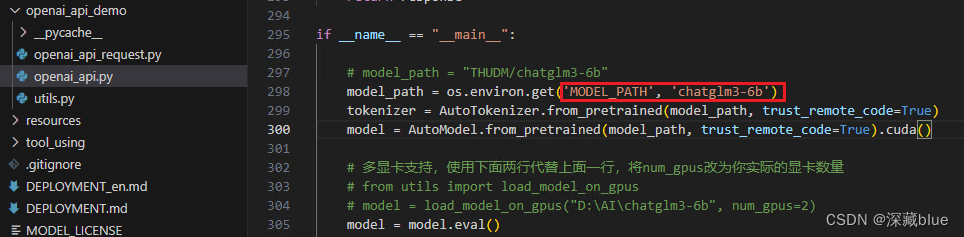
2.进入D:\AI\ChatGLM3-main\openai_api_demo

执行代码
python openai_api.py
会报错,提示缺少loguru或者sse_starlette或者fastapi等等等
缺少哪个包执行哪个包的安装语句就可,如下
pip install 包名
例如:pip install fastapi
等待安装完成再次运行python openai_api.py,安装完缺少的包就可运行成功了

打开postman进行测试
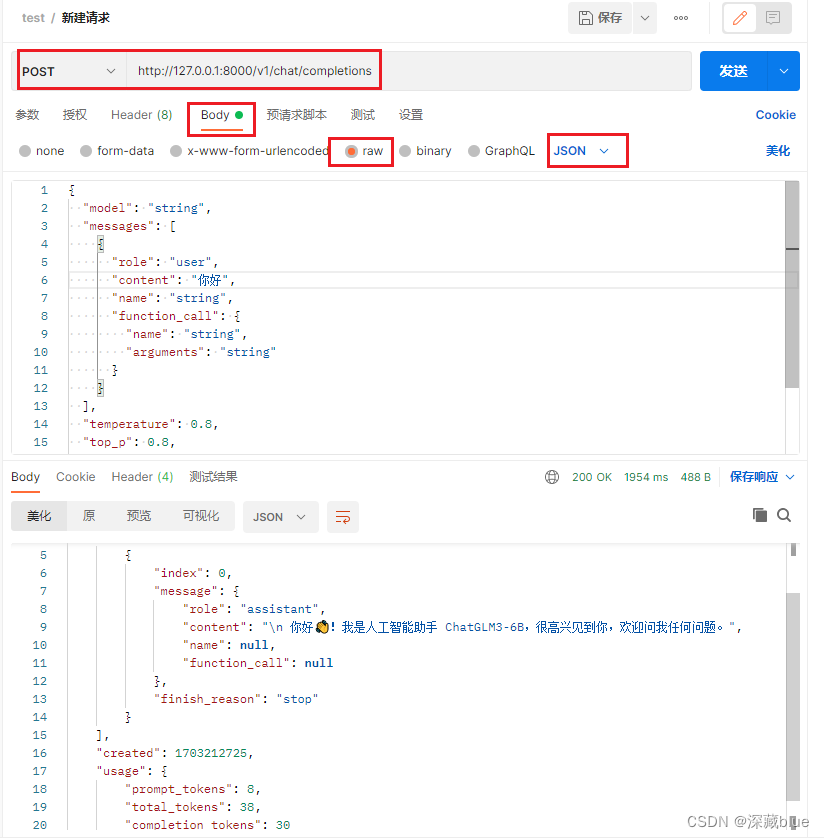
请求体代码
{
"model": "string",
"messages": [
{
"role": "user",
"content": "你好",
"name": "string",
"function_call": {
"name": "string",
"arguments": "string"
}
}
],
"temperature": 0.8,
"top_p": 0.8,
"max_tokens": 0,
"stream": false,
"functions": {},
"repetition_penalty": 1.1
}
运行成功
3.接下来修改openai_api.py代码,建议直接复制以下代码替换openai_api.py中所有代码
import time
from contextlib import asynccontextmanager
from typing import List, Literal, Optional, Union
import os
import torch
import uvicorn
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from loguru import logger
from pydantic import BaseModel, Field
from sse_starlette.sse import EventSourceResponse
from transformers import AutoTokenizer, AutoModel
import numpy as np
import tiktoken
from sentence_transformers import SentenceTransformer
from sklearn.preprocessing import PolynomialFeatures
from utils import process_response, generate_chatglm3, generate_stream_chatglm3
@asynccontextmanager
async def lifespan(app: FastAPI): # collects GPU memory
yield
if torch.cuda.is_available():
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI(lifespan=lifespan)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class ModelCard(BaseModel):
id: str
object: str = "model"
created: int = Field(default_factory=lambda: int(time.time()))
owned_by: str = "owner"
root: Optional[str] = None
parent: Optional[str] = None
permission: Optional[list] = None
class ModelList(BaseModel):
object: str = "list"
data: List[ModelCard] = []
class FunctionCallResponse(BaseModel):
name: Optional[str] = None
arguments: Optional[str] = None
class ChatMessage(BaseModel):
role: Literal["user", "assistant", "system", "function"]
content: str = None
name: Optional[str] = None
function_call: Optional[FunctionCallResponse] = None
class DeltaMessage(BaseModel):
role: Optional[Literal["user", "assistant", "system"]] = None
content: Optional[str] = None
function_call: Optional[FunctionCallResponse] = None
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatMessage]
temperature: Optional[float] = 0.8
top_p: Optional[float] = 0.8
max_tokens: Optional[int] = None
stream: Optional[bool] = False
functions: Optional[Union[dict, List[dict]]] = None
# Additional parameters
repetition_penalty: Optional[float] = 1.1
class ChatCompletionResponseChoice(BaseModel):
index: int
message: ChatMessage
finish_reason: Literal["stop", "length", "function_call"]
class ChatCompletionResponseStreamChoice(BaseModel):
index: int
delta: DeltaMessage
finish_reason: Optional[Literal["stop", "length", "function_call"]]
class UsageInfo(BaseModel):
prompt_tokens: int = 0
total_tokens: int = 0
completion_tokens: Optional[int] = 0
class ChatCompletionResponse(BaseModel):
model: str
object: Literal["chat.completion", "chat.completion.chunk"]
choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]
created: Optional[int] = Field(default_factory=lambda: int(time.time()))
usage: Optional[UsageInfo] = None
@app.get("/v1/models", response_model=ModelList)
async def list_models():
model_card = ModelCard(id="chatglm3-6b")
return ModelList(data=[model_card])
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
async def create_chat_completion(request: ChatCompletionRequest):
global model, tokenizer
if len(request.messages) < 1 or request.messages[-1].role == "assistant":
raise HTTPException(status_code=400, detail="Invalid request")
gen_params = dict(
messages=request.messages,
temperature=request.temperature,
top_p=request.top_p,
max_tokens=request.max_tokens or 1024,
echo=False,
stream=request.stream,
repetition_penalty=request.repetition_penalty,
functions=request.functions,
)
logger.debug(f"==== request ====\n{gen_params}")
if request.stream:
generate = predict(request.model, gen_params)
return EventSourceResponse(generate, media_type="text/event-stream")
response = generate_chatglm3(model, tokenizer, gen_params)
usage = UsageInfo()
function_call, finish_reason = None, "stop"
if request.functions:
try:
function_call = process_response(response["text"], use_tool=True)
except:
logger.warning("Failed to parse tool call")
if isinstance(function_call, dict):
finish_reason = "function_call"
function_call = FunctionCallResponse(**function_call)
message = ChatMessage(
role="assistant",
content=response["text"],
function_call=function_call if isinstance(function_call, FunctionCallResponse) else None,
)
choice_data = ChatCompletionResponseChoice(
index=0,
message=message,
finish_reason=finish_reason,
)
task_usage = UsageInfo.parse_obj(response["usage"])
for usage_key, usage_value in task_usage.dict().items():
setattr(usage, usage_key, getattr(usage, usage_key) + usage_value)
return ChatCompletionResponse(model=request.model, choices=[choice_data], object="chat.completion", usage=usage)
async def predict(model_id: str, params: dict):
global model, tokenizer
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(role="assistant"),
finish_reason=None
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.json(exclude_unset=True))
previous_text = ""
for new_response in generate_stream_chatglm3(model, tokenizer, params):
decoded_unicode = new_response["text"]
delta_text = decoded_unicode[len(previous_text):]
previous_text = decoded_unicode
finish_reason = new_response["finish_reason"]
if len(delta_text) == 0 and finish_reason != "function_call":
continue
function_call = None
if finish_reason == "function_call":
try:
function_call = process_response(decoded_unicode, use_tool=True)
except:
print("Failed to parse tool call")
if isinstance(function_call, dict):
function_call = FunctionCallResponse(**function_call)
delta = DeltaMessage(
content=delta_text,
role="assistant",
function_call=function_call if isinstance(function_call, FunctionCallResponse) else None,
)
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=delta,
finish_reason=finish_reason
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.json(exclude_unset=True))
choice_data = ChatCompletionResponseStreamChoice(
index=0,
delta=DeltaMessage(),
finish_reason="stop"
)
chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk")
yield "{}".format(chunk.json(exclude_unset=True))
yield '[DONE]'
class EmbeddingRequest(BaseModel):
input: List[str]
model: str
def num_tokens_from_string(string: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding('cl100k_base')
num_tokens = len(encoding.encode(string))
return num_tokens
def expand_features(embedding, target_length):
poly = PolynomialFeatures(degree=2)
expanded_embedding = poly.fit_transform(embedding.reshape(1, -1))
expanded_embedding = expanded_embedding.flatten()
if len(expanded_embedding) > target_length:
# 如果扩展后的特征超过目标长度,可以通过截断或其他方法来减少维度
expanded_embedding = expanded_embedding[:target_length]
elif len(expanded_embedding) < target_length:
# 如果扩展后的特征少于目标长度,可以通过填充或其他方法来增加维度
expanded_embedding = np.pad(
expanded_embedding, (0, target_length - len(expanded_embedding))
)
return expanded_embedding
@app.post("/v1/embeddings")
async def get_embeddings(
request: EmbeddingRequest
):
# 计算嵌入向量和tokens数量
embeddings = [embeddings_model.encode(text) for text in request.input]
# 如果嵌入向量的维度不为1536,则使用插值法扩展至1536维度
embeddings = [
expand_features(embedding, 1536) if len(embedding) < 1536 else embedding
for embedding in embeddings
]
# Min-Max normalization 归一化
embeddings = [embedding / np.linalg.norm(embedding) for embedding in embeddings]
# 将numpy数组转换为列表
embeddings = [embedding.tolist() for embedding in embeddings]
prompt_tokens = sum(len(text.split()) for text in request.input)
total_tokens = sum(num_tokens_from_string(text) for text in request.input)
response = {
"data": [
{"embedding": embedding, "index": index, "object": "embedding"}
for index, embedding in enumerate(embeddings)
],
"model": request.model,
"object": "list",
"usage": {
"prompt_tokens": prompt_tokens,
"total_tokens": total_tokens,
},
}
return response
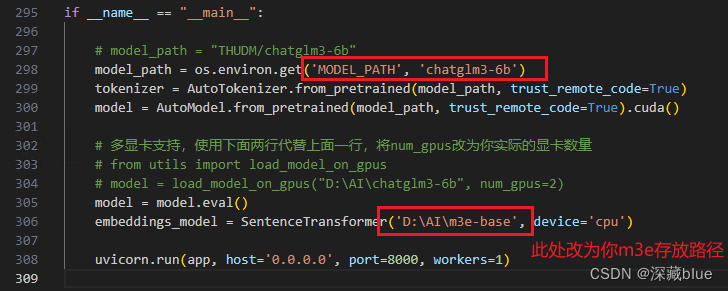
if __name__ == "__main__":
# model_path = "THUDM/chatglm3-6b"
model_path = os.environ.get('MODEL_PATH', 'chatglm3-6b')
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("D:\AI\chatglm3-6b", num_gpus=2)
model = model.eval()
embeddings_model = SentenceTransformer('D:\AI\m3e-base', device='cpu')
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
修改如下两处内容即可
然后再次执行
python openai_api.py
会提示缺包,按上面方法pip安装即可,执行成功即可开始部署FastGPT
3.部署FastGPT
1.需要Linux进行部署,windows有自带的虚拟化功能,可以安装Linux系统,参考
https://zhuanlan.zhihu.com/p/666301493
部署Ubuntu 20.04
因为我装的有Linux虚拟机,就直接在虚拟机上部署了
2.安装Docker、Docker-Compose
3.打开Fast-GPT代码,复制docker-compose.yml文件到Linux系统上
修改以下地方
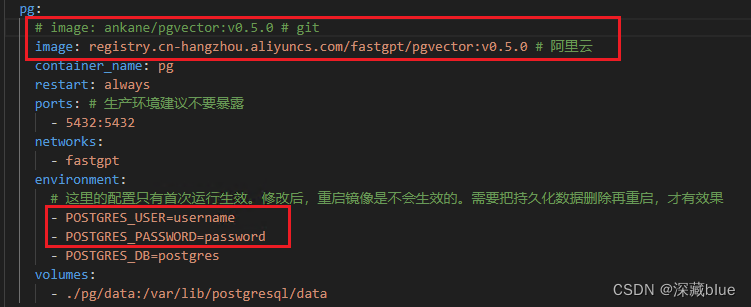
pg的账号密码,我没改,和代码中一样,镜像用的阿里云
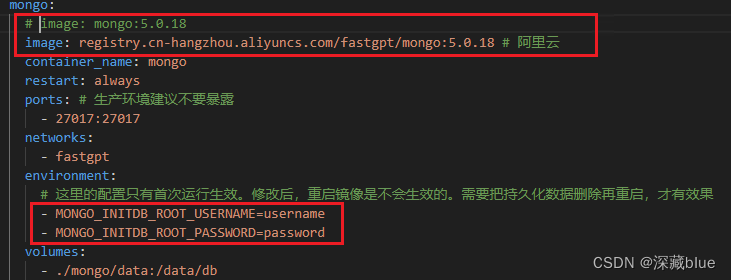
mongo的账号密码,我没改,和代码中一样,镜像用的阿里云
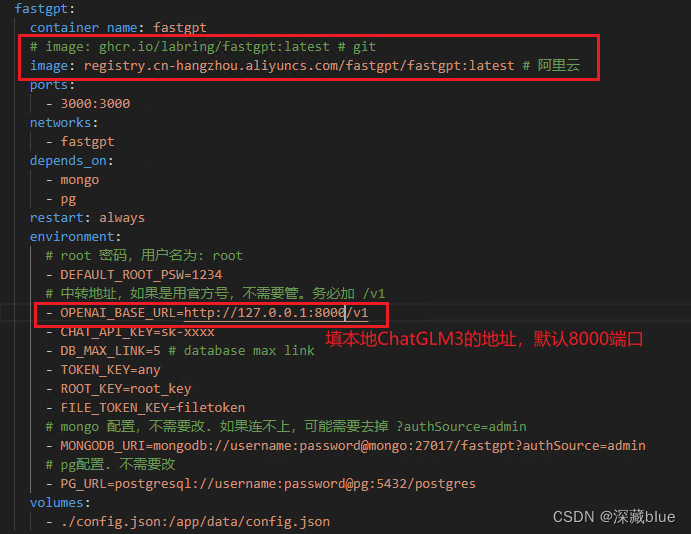
修改阿里云镜像和url地址
4.执行docker-compose.yml文件
在该文件目录下执行
docker compose up -d
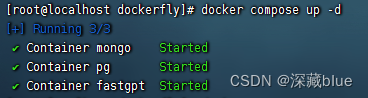
成功后即可打开,默认3000端口
登录,默认root,密码1234
点击应用,新建
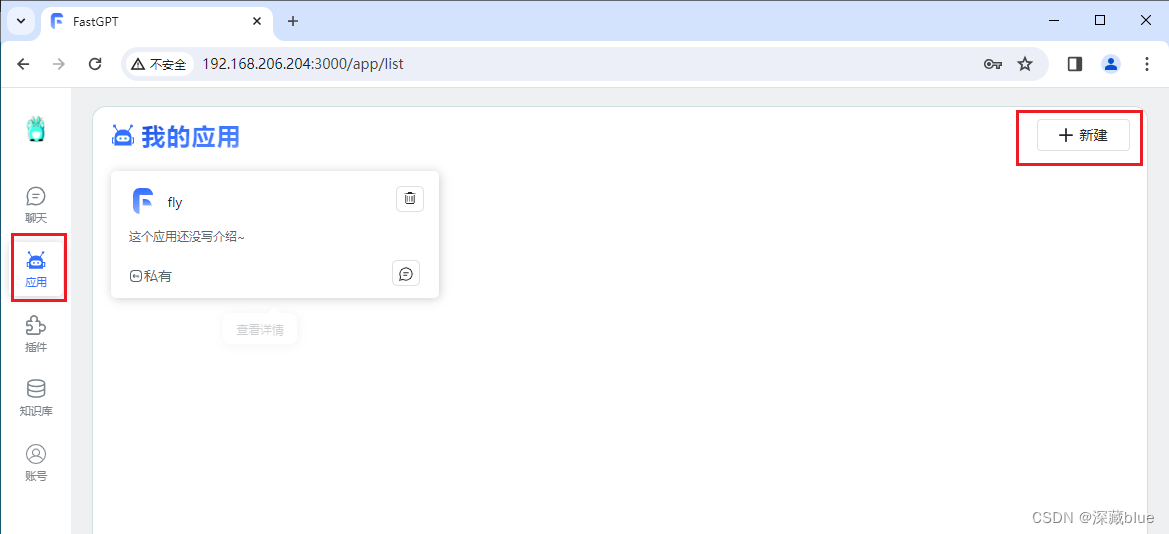
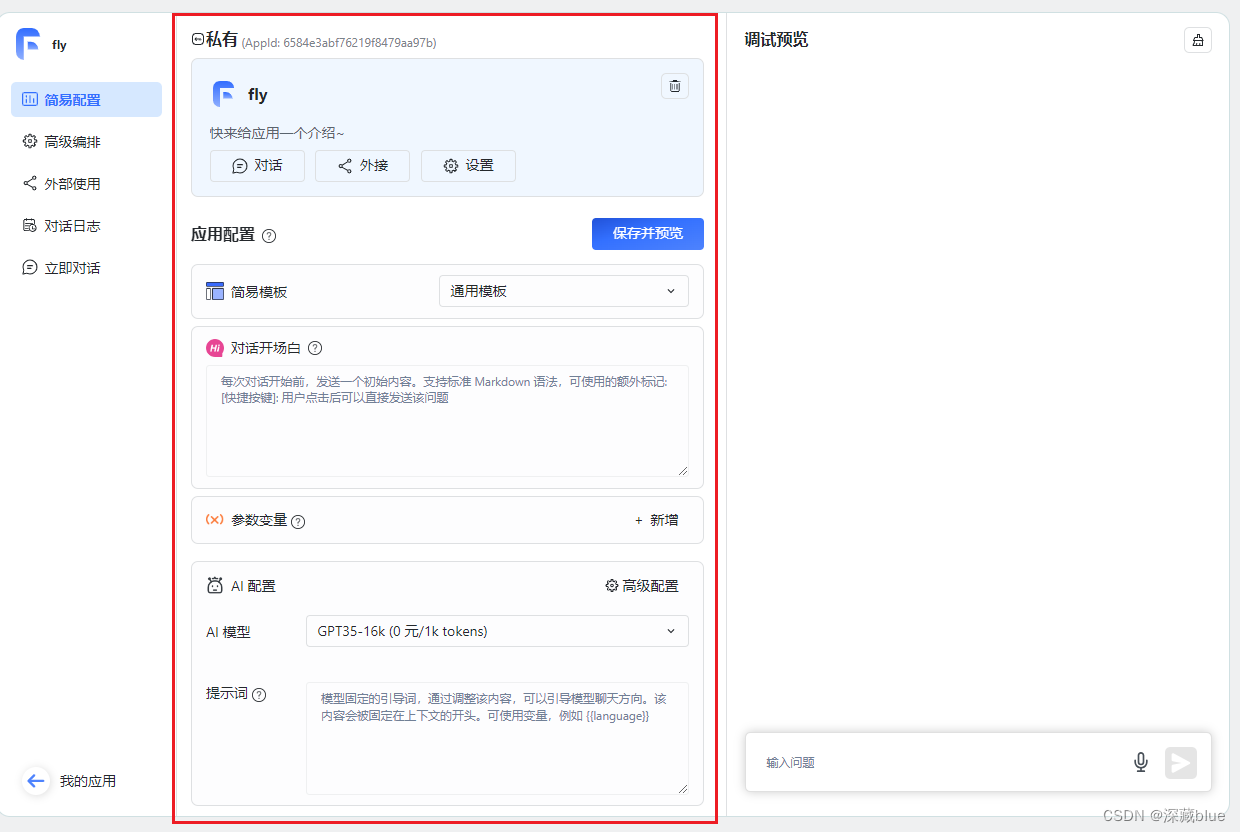
左边框框不用管,因为我们是直连ChatGLM3-6b,直接访问即可
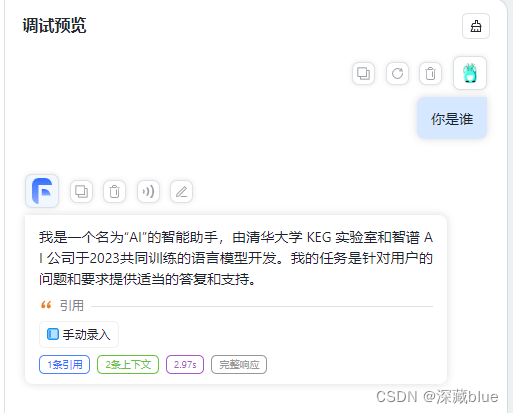
执行成功!
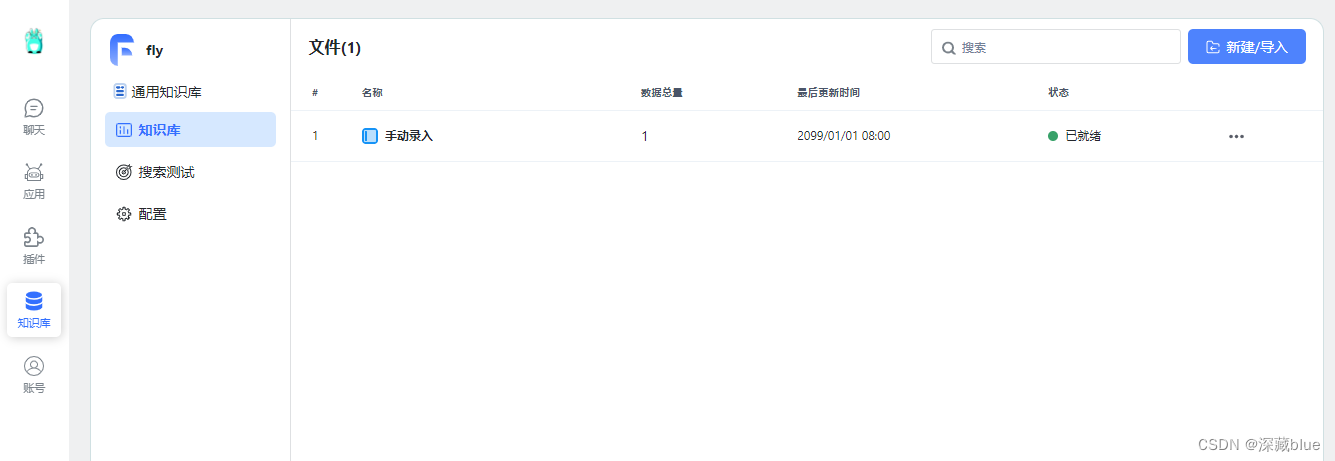
知识库内容,新建数据,然后绑定到应用里即可,后续再详细写
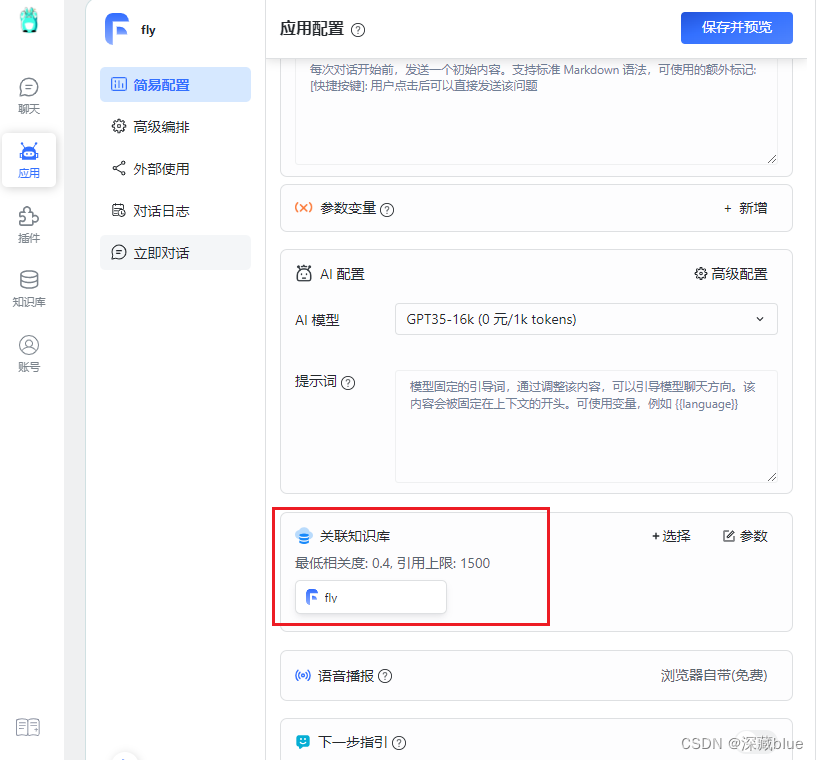
在这里关联完即可问它知识库里的内容了
以上所用所有文件及程序:
https://www.alipan.com/s/Goc66oWkVEw
提取码: 8uv1
ChatGLM3-6b文件和模型不能分享,请到下面链接下载
链接:https://pan.baidu.com/s/1V_y-10Ixx7bFNUuQ9NhF9w
提取码:2s14















 2543
2543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









