







当今环境,所有企业都有一个绕不开的问题:信息过载。面对大量的信息资源,一方面,人员流失导致企业知识资产的流失几乎是必然现象,项目也往往受制于关键信息的同频而产生很大的负面影响。另一方面,业务模式无论多么简单,新员工上手的学习曲线同样陡峭,往往在同一类问题的解决上反复浪费资源,重复制造车轮。
解决上述问题,企业知识库算是一个比较合适的方案:一个能够保存企业智慧、促进信息共享、提高工作效率、加速新员工培训、支持决策制定的知识协同系统。员工只需要按照企业制定的统一要求,把属于企业的知识放进去,经知识库加工后输出,逐渐在企业内外部共享使用。随着知识库内容和功能的完善,将为企业管理和协同带来巨大的帮助。
知识库有了雏形,我们就可以借助GPT为企业员工和用户更好的输出知识库内容,提升使用体验,从而提升效率。在本文中,我们将借助OpenAI的GPT和开源程序FastGPT的组合方案,低成本实现企业知识库问答系统的搭建,相比于以往服务商提供的动辄几万块的知识库解决方案,甚至让你不需要花钱就能达到同样甚至更好的效果。
FastGPT简介

免费开源程序FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,支持企业内部免费私有化部署,也支持付费商用多用户版本,目前Github9.2kStar,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!
功能特点:
- 项目开源
FastGPT 遵循附加条件 Apache License 2.0 开源协议,你可以 Fork 之后进行二次开发和发布。FastGPT 社区版将保留核心功能,商业版仅在社区版基础上使用 API 的形式进行扩展,不影响学习使用。 - 独特的 QA 结构
针对客服问答场景设计的 QA 结构,提高在大量数据场景中的问答准确性。 - 可视化工作流
通过 Flow 模块展示了从问题输入到模型输出的完整流程,便于调试和设计复杂流程。 - 无限扩展
基于 API 进行扩展,无需修改 FastGPT 源码,也可快速接入现有的程序中。 - 便于调试
提供搜索测试、引用修改、完整对话预览等多种调试途径。 -
支持多种模型
支持 GPT、Claude、文心一言等多种 LLM 模型,未来也将支持自定义的向量模型。
工作原理:

搭建准备
- 服务器:2核2G3M20GB以上即可,推荐入手阿里云99元/年ECS云服务器,推荐购买链接:
云小站_专享特惠_云产品推荐-阿里云 - 域名:阿里云购买域名并在上述购买服务器上进行企业备案(企业备案完成大概1~2周左右时间)。
- API-Key:购买可以支持gpt-3.5和4系列、国内主流AI等多个大模型的聚合API,推荐购买链接:首页 | XD数字商店
以上就是搭建所需全部条件,搭建费用总计成本200元以内,准备好后可继续往下阅读。
搭建步骤
- 在服务器完成宝塔安装(略)
- 服务器端口放行3000(或把默认设置3000修改为自定义的端口并放行)
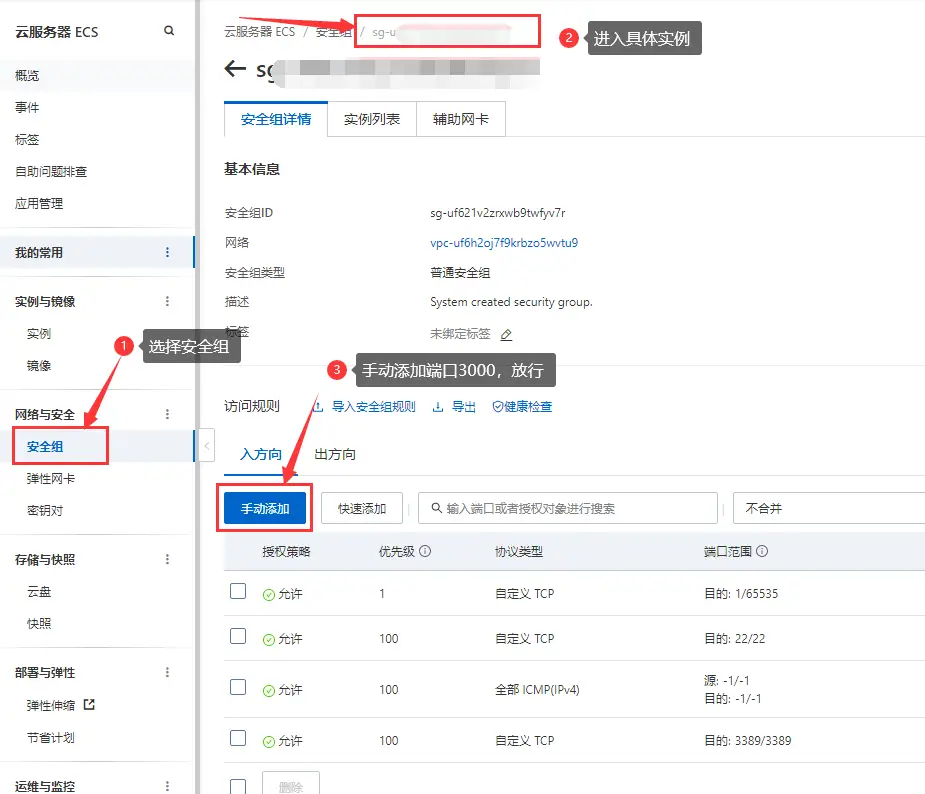
- Docker部署FastGPT
- 打开宝塔,安装Ngixn推荐环境,再在应用商店安装Docker管理器,进入SSH终端;
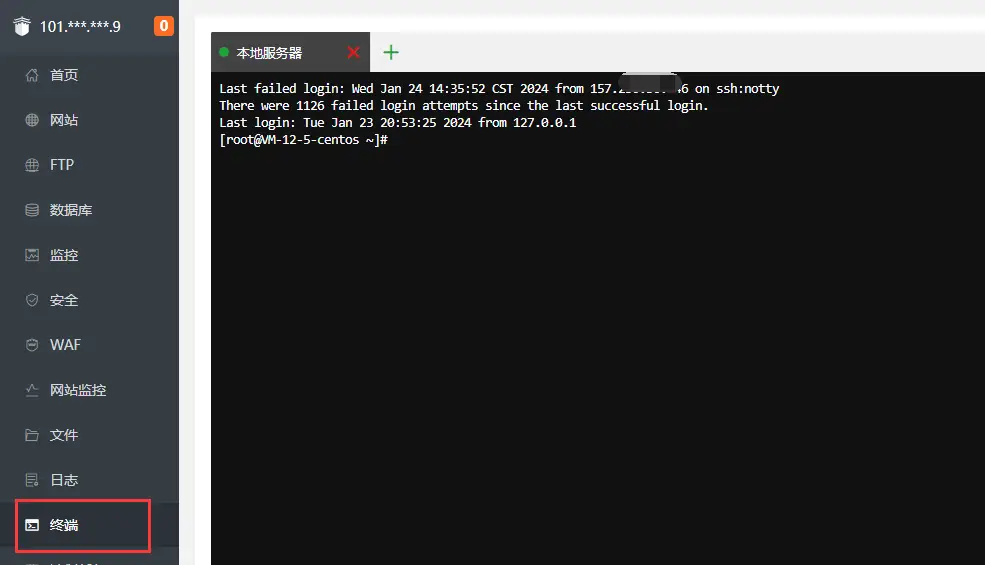
- 命令创建文件夹并拉取配置文件:
- 打开宝塔,安装Ngixn推荐环境,再在应用商店安装Docker管理器,进入SSH终端;


mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.jsonCopy
-
- yml和json设置
docker-compose.yml文件主要改三个位置(密码、接口、API-Key),如下图: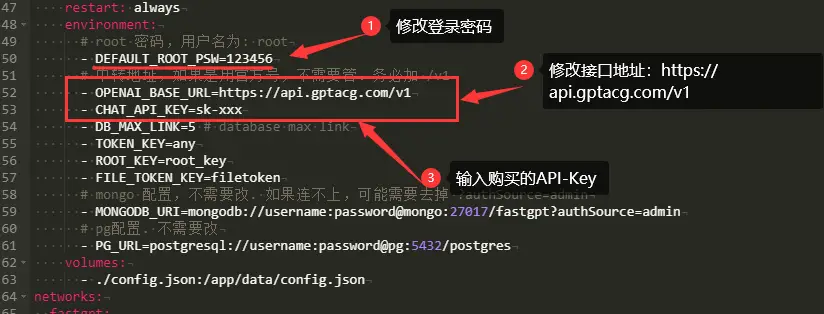
config.json可不修改,按需添加。建议添加默认模型:gpt-4-turbo
- 注意,在国内拉取github源镜像可能会非常缓慢甚至卡住不动,这里建议从yml设置文件中修改镜像源为阿里云,如下图:
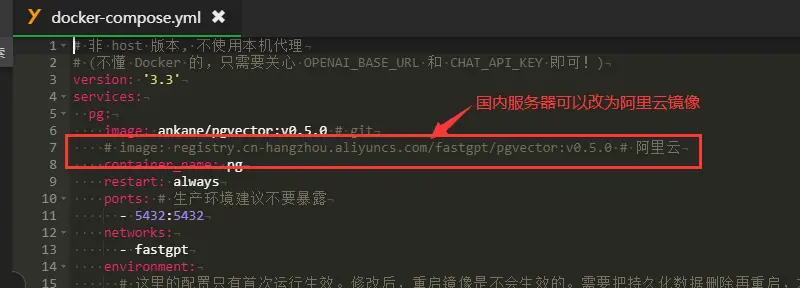
- 分别执行以下三条命令,拉取镜像并启动:
cd fastgpt
docker-compose pull
docker-compose up -d - 完成后,打开你的服务器ip+端口访问,比如:1.1.1.1:3000
- yml和json设置
- url绑定程序
- 在域名服务商控制台,将访问域名解析到你的服务器IP,如www.123.com;
- 在宝塔面板→网站→添加网站,设置如图:

- 添加SSL证书(略);
- 反向代理ip,绑定url:
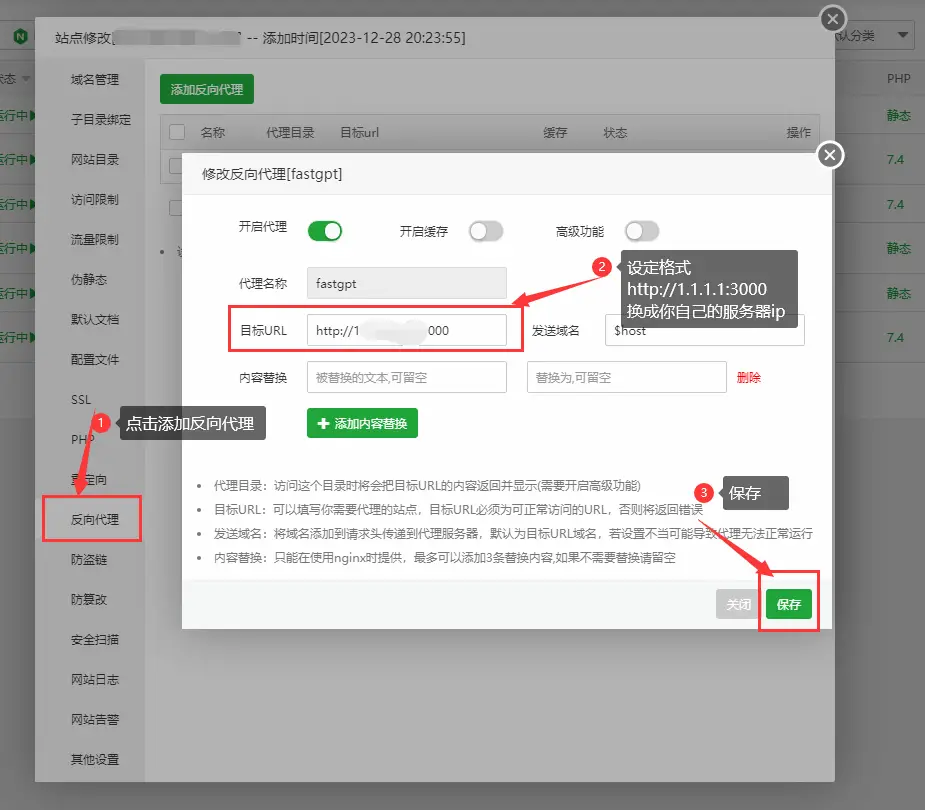
- 通过域名访问成功即完成搭建。







FastGPT使用
搭建成功后,通过用户名和密码访问私有化部署的FastGPT即可展开使用,你可以基于企业特点选择怎样去使用它,这里我们来简要介绍几个核心功能:
- 创建知识库
提前准备好你的投喂资料,然后根据系统提示完成知识库的创建即可: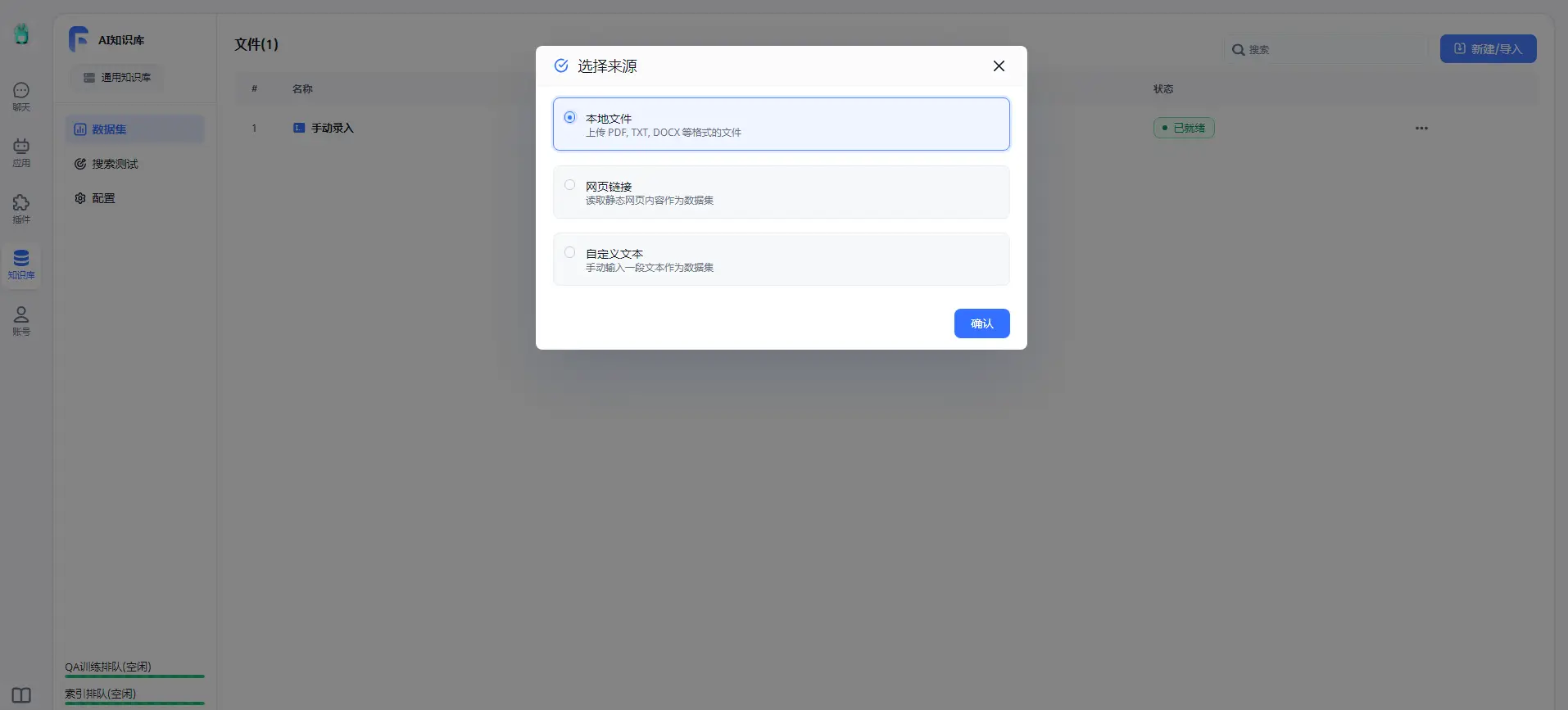
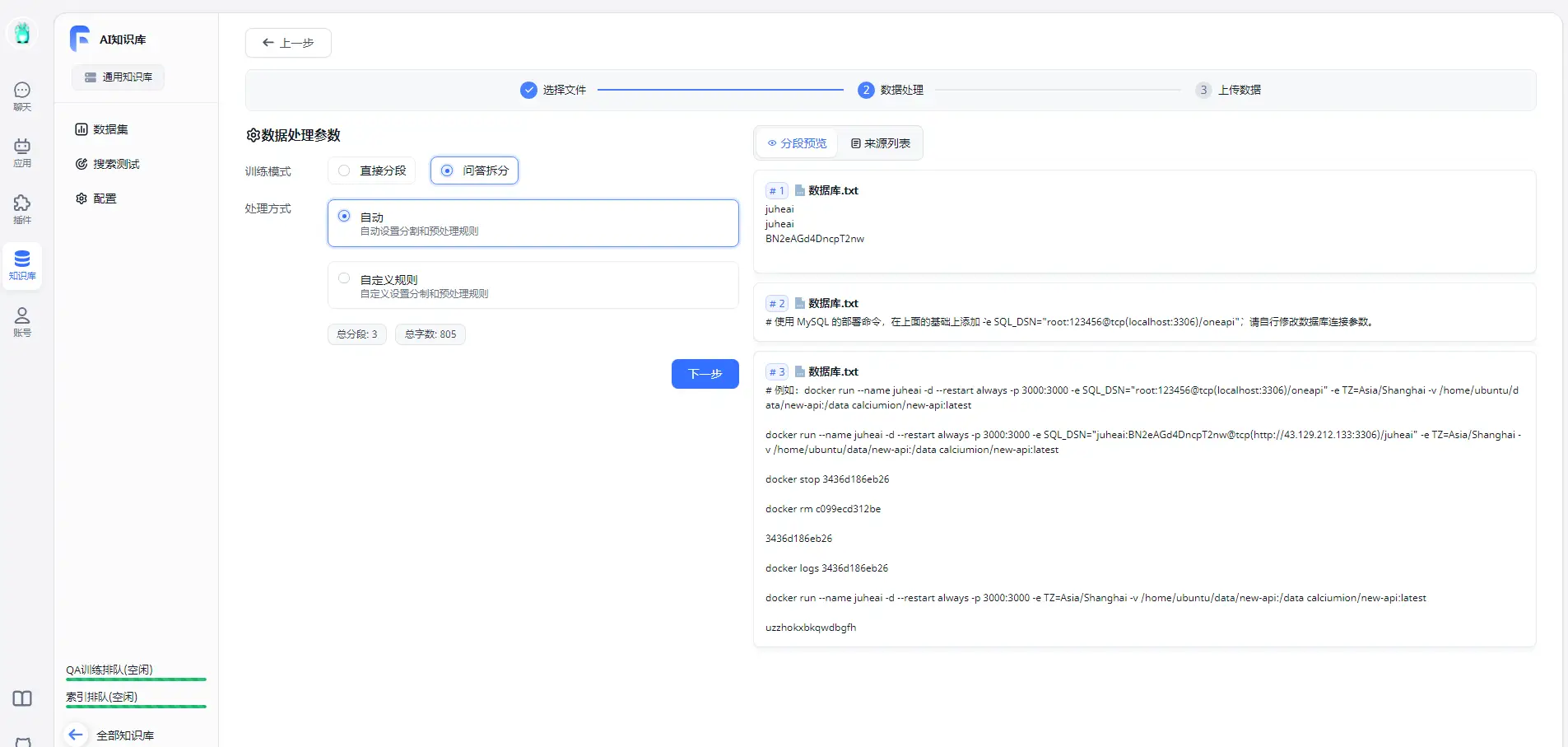
- 绑定应用
新建一个应用,并将知识库与该应用捆绑,你还可以设定回答模型,提示词,语音设置等。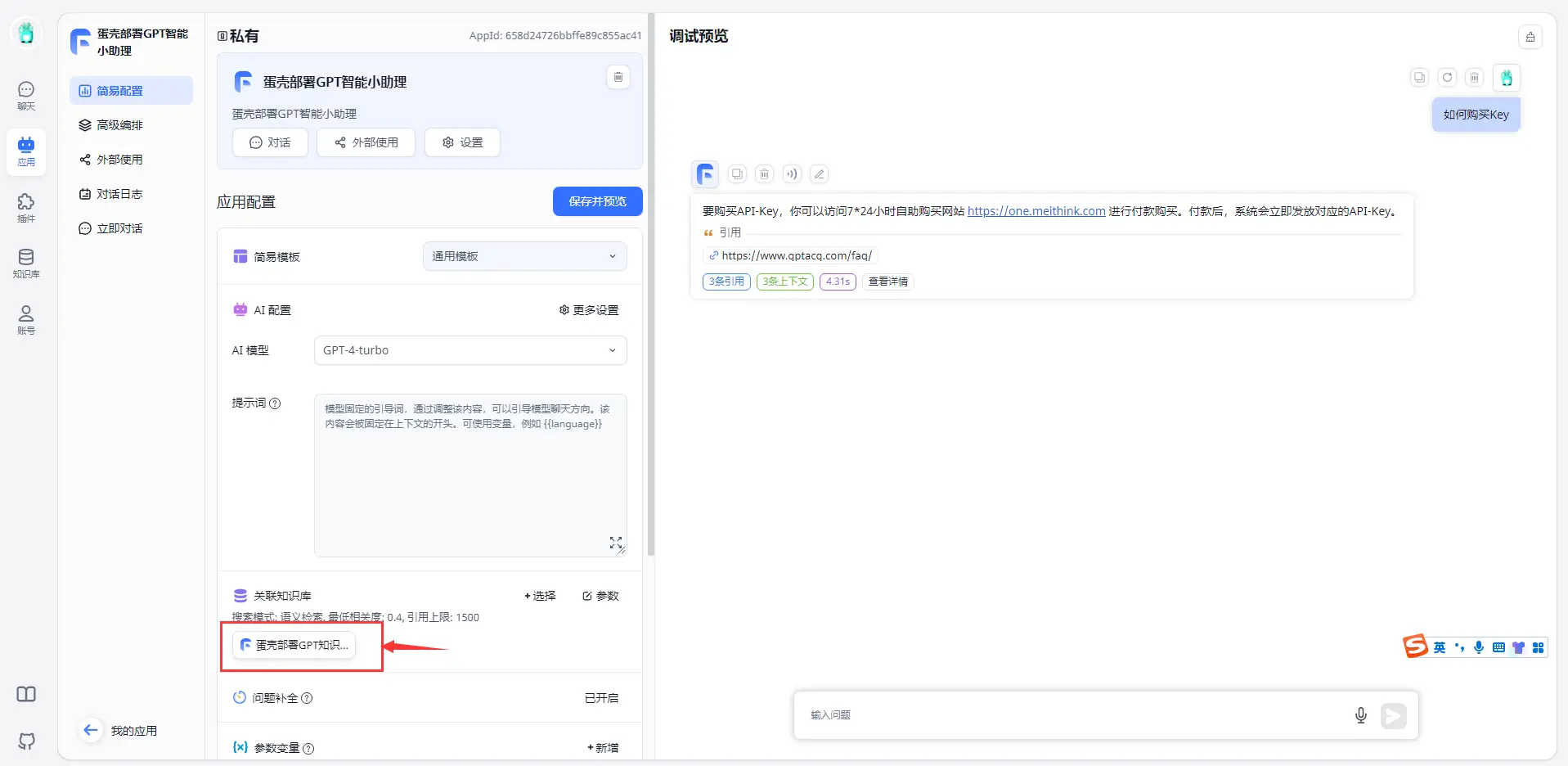
- 高级编排
个人感觉这是FastGPT最良心的功能,高级编排是大模型回答前的预判断条件语句,可以更好的分类用户问题并给出更准确的回答。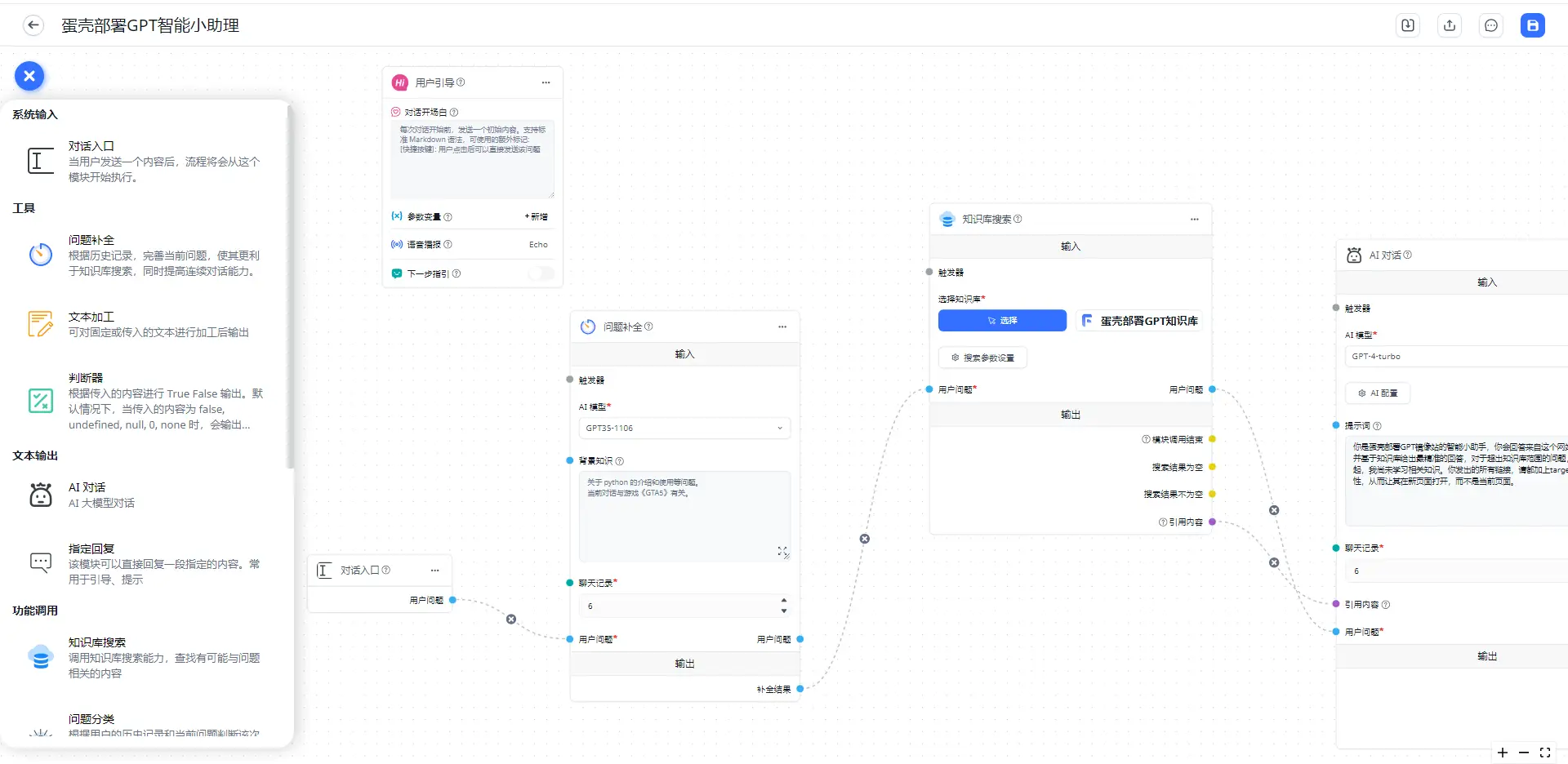
- 设置外链
你可以为你的知识库应用生成无需登录即可访问的外部链接。这样做,我们可以将知识库用在任何我们需要的地方,也可以用frame形式嵌入网站。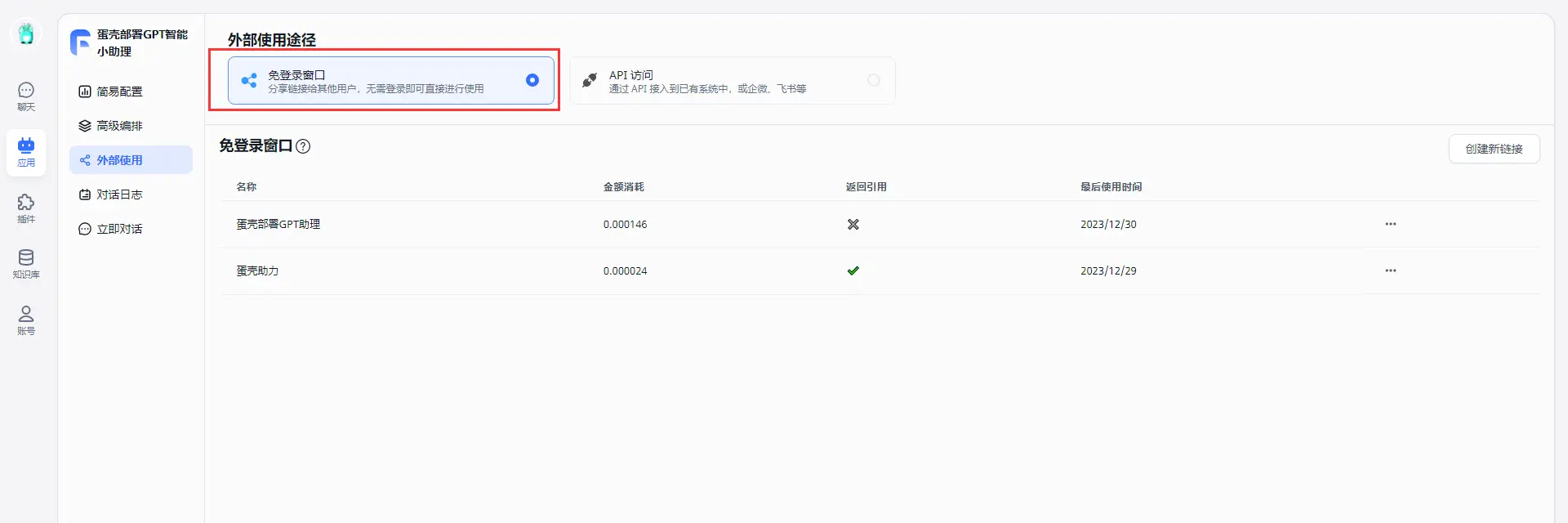
- 设置OpenAI格式的API
此功能是FastGPT得以广泛使用的原因之一。我们可以将知识库以API的形式输出(OpenAI Chat格式),如此以来大大扩展了知识库的使用面积,可以任意场景快速接入知识库,包括我们熟知的Nextchat这一类AI程序,也可以对接使用,方法和接入OpenAI的API一致。因为蛋壳API是聚合了几十种大模型于一身,通过Newapi进行了格式统一,所以我们购买后可以通过蛋壳API任意调用其中的大语言模型,比如gpt系列+知识库、通义千问+知识库、讯飞星火+知识库、智谱清言+知识库等等。模型调用请参考此文章>>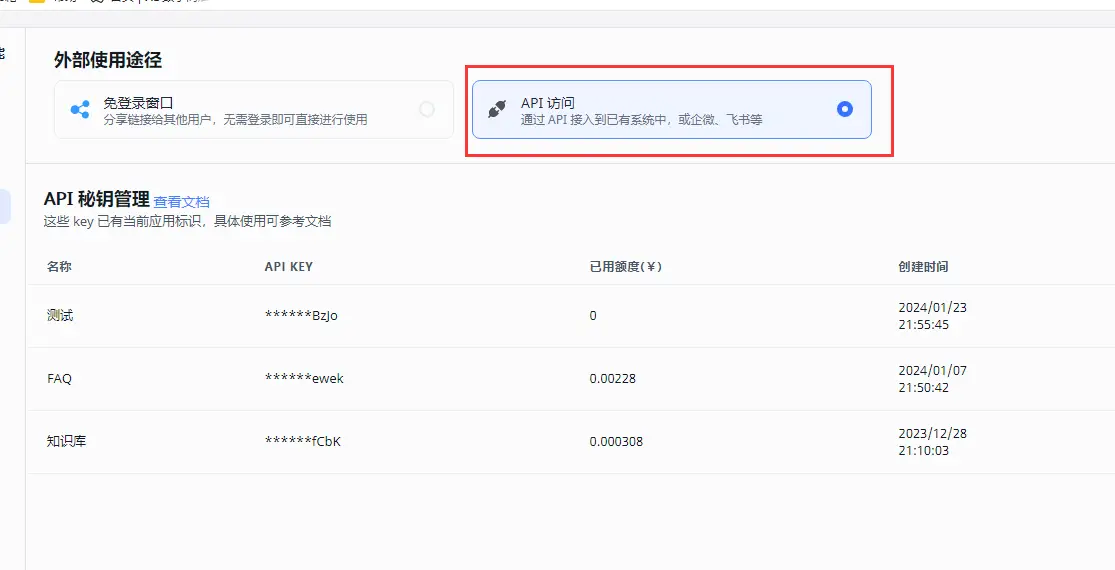
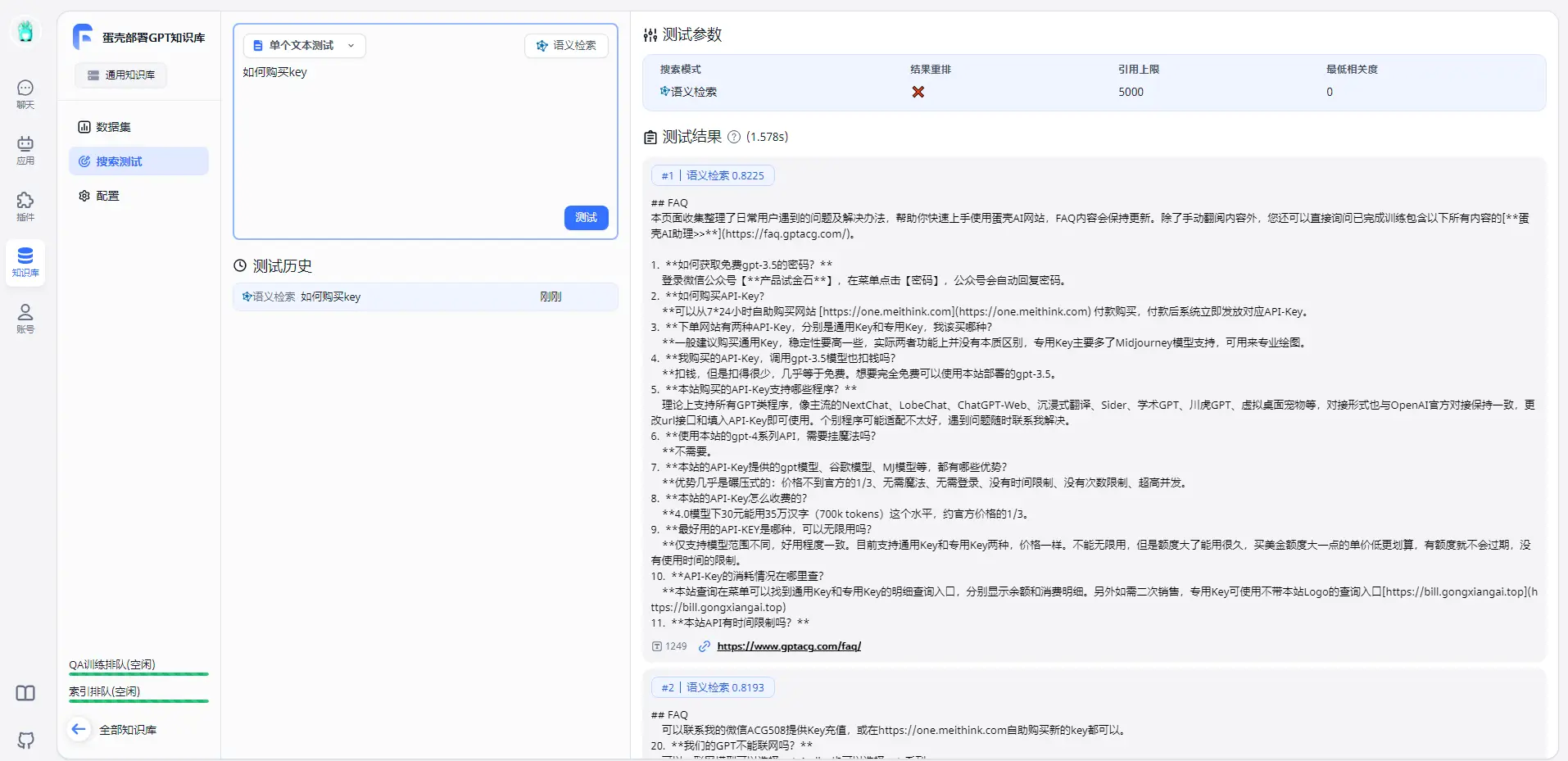
- 效果展示
我基于网站FAQ用FastGPT + gpt-3.5 + chatgpt-demo做了个蛋壳AI客服,蛋壳AI客服访问链接>>: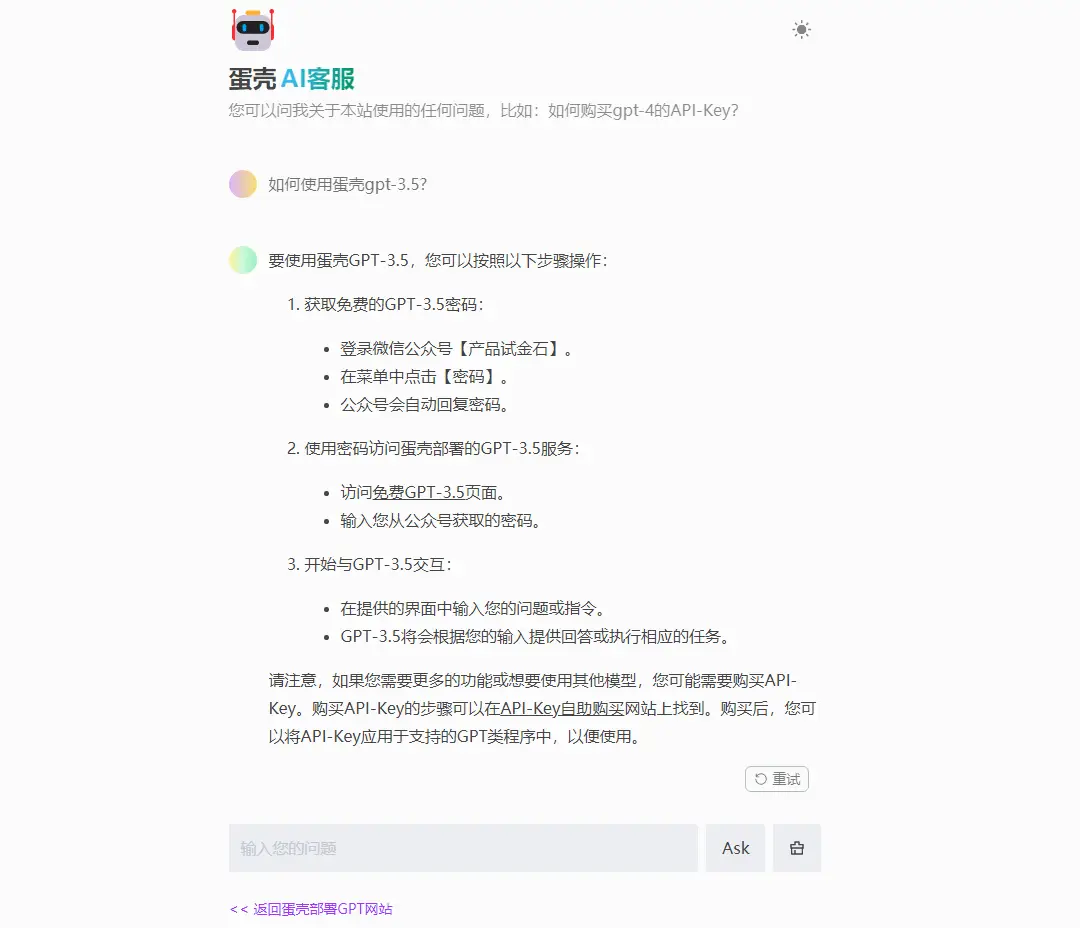
chatgpt-demo项目地址>>








知识库建设思路
目前看来,中国大部分中小企业还是没有知识库概念的,老板不重视,员工更不会重视,就像开篇说的那样,企业在人才流失的同时,也流失了太多本应该属于企业的知识沉淀。企业太缺乏这种资产保护意识了!
FastGPT的出现,从一定意义上来说更加具体了知识库的概念,降低了知识库的入门标准,拉低了成本,我在本文也重点介绍了知识库问答系统搭建的整个过程,总的来说还是非常简单的。如此以来也可以倒逼企业建设属于自己的知识库,降本增效就在眼前,无论企业大小,都可以开始着手尝试应用了!
如果还没有头绪着手开始这件事,以下方式可以参考:
- 指定1名人员作为知识库管理员,并安排其完成基于FastGPT的知识库问答系统搭建,功能使用培训;
- 各个部门指定1名人员并分配后台账号,负责录入并调校本部门知识档案的输出(包含但不限于规章制度、工作流程、优秀案例、企业文化、宣传资料、产品资料、技术文件等等),并定期维护和更新本部门资料;
- 由知识库管理员基于知识库创建不同功能的应用,如新员工AI培训师、AI财务助理、AI客服等等,还可以通过知识库API继续深度开发知识库相关应用程序。
总结
虽然短期来看,搭建企业知识库比较费时费力,并有一定滞后性,甚至影响员工工作的积极性,尤其是在知识库内容不全面急需补充的阶段。但是长期来看,建设企业知识库不仅可以提高企业的运营效率,还可以促进企业的持续学习和发展,提高客户满意度,支持决策制定,降低风险,最终加强企业的竞争力。

















 2231
2231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









