







通过高效率的模型生成来测试DL库
摘要
本文提出了一种新的方法LEMON来测试DL库。通过设计一系列变化规则来探索DL库中代码的不同调用序列和难以掌控的行为。通过启发式策略指导模型朝着“放大由bug引起的不同DL库之间的不一致性”这一方向生成。本文对TensorFlow, Theano, CNTK, MXNet这四个库的多个版本进行了测试并发现了错误,证实了LEMON的有效性。
Introduction
深度学习系统应用广泛,但是也时常有安全事故发生,所以测试很重要。目前大多数研究都关注应用层次,本文着重关注library这一层次。如下图所示:
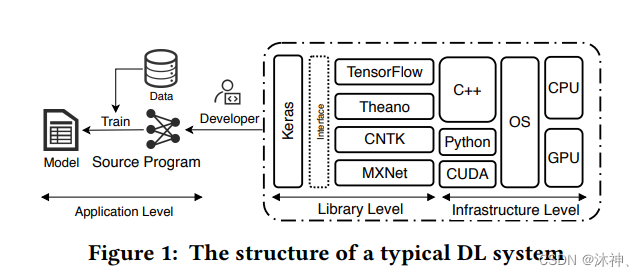
解决该问题主要有两大挑战:一是没有足够多的模型用来测试;二是很难分辨出一个问题是由于真正的bug还是由于某些不确定因素(例如浮点计算偏差)造成。
Background
主要介绍了深度学习的概念、现在流行的深度学习库,说明了本文的研究主要在low-level libraries上。
Metrics for Testing DL Libraries:衡量DL库之间检测到的差异(这里暂时不理解)
方法
系统设计了两种类型的模型改变原则:intact-layer mutation 和 inner-layer mutation。
intact-layer mutation (完整层变化规则):
修改、添加、多层添加、删除、复制、激活函数移除、激活函数替换 总共7条。
Inner-Layer Mutation (内层突变):
随机选择一层中30%的神经元进行突变。 细粒度
Gaussian Fuzzing (GF): (高斯模糊):向神经元的权重添加噪声(根据高斯分布)
Weights Shuffling (WS): 将一个神经元的连接权重用原先层混合(这里暂时不理解)
Neuron Activation Inverse (NAI)(神经元逆向激活):在将神经元输出值传递给激活函数之前,通过改变神经元输出值的符号来反转神经元的激活状态。
Neuron Effect Block (NEB):通过将神经元到下一层的连接权重设置为0,消除神经元在下一层上的效应。
Neuron Switch (NS): 转换一层中的两个神经元,以改变其对下一层的影响
一阶突变和高阶突变
一阶:使用一个变异规则
高阶:迭代使用多个变异规则
基于启发式的模型生成
对于每一代,生成一个模型,尽可能产生比突变前更大的不一致程度,也就是说朝着放大不一致程度的方向上生成模型。
因而提出启发式模型生成方法:每次迭代中,LEMON首先选择要变异的种子,然后选择要应用的变异规则。
选择变异种子
初始种子模型是指给定的现有模型。LEMON通过一阶或高阶突变从该种子模型生成突变模型。为了促进模型生成朝着放大不一致程度的方向发展,LEMON还将具有比突变前更大不一致程度的突变模型视为种子模型。
ACC 求累计不一致程度,ACC(m)越大代表m的不一致程度越大。
如果一个种子模型被用来突变的次数越小,其分数score越高,score越高,他被选择用来突变的概率越大。设计轮盘赌来确定最终的种子模型。
选择变异规则
对于每个变异规则MU,计算其优先级分数,计算方法为 MU放大了不一致的次数 比上 该MU总共使用的次数。然而因为排序结果是根据历史迭代,不能完全代表未来,所以使用马尔科夫链蒙特卡洛方法,通过下图公式计算给定MUa 选择MUb的概率。(这里理解的不是很好,知道大概意思)
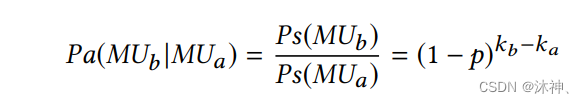
最终算法流程伪代码如下

Evaluation
首先是库 模型 数据集的介绍
Number of Inconsistencies:可以在一定程度上衡量LEMON的效果,越大越好。(这一块没太看懂)
Number of Detected Bugs:检测出错误的数量
比较方法: 分析了多少个不一致和错误是仅仅由LEMON通过初始模型检测出来的;以及多少个不一致和错误是仅仅由LEMON通过变异模型检测出来的。
LEMONr :非启发式,随机选择种子和变异规则。
结果和分析
错误崩溃bug 不一致导致的bug NaN错误 性能缺陷(由内存泄露引起)
讨论
LEMON的可改进方向:
1.当前只是在模型级别突变,未来可以发展到源代码级别。
2.LEMON 采用差分测试,当不同的库产生相同的错误LEMON无法检测出来,未来可引入LEMON的变形测试。(不太清楚)
3.探索更有效的输入数据。
结论
本文在lemon中设计了一系列变化规则,通过改变现有模型来生成新的模型,目的是探索DL库代码的不同使用方式、进行充分的测试。进一步地,本文在LEMON中提出使用启发式策略指导模型得生成过程,目的是使生成的模型能放大真实错误的不一致程度。
整体阅读总结:本文提出了一种新的方法LEMON来测试DL库。要解决的核心问题有两个:第一个是没有足够多的网络模型进行测试,第二个是无法正确识别一个问题的产生究竟是因为BUG导致的还是某些不确定因素导致的。为了解决第一个问题,本文根据现有的模型进行突变,设计出两大类突变规则(分别是intact-layer mutation 和 inner-layer mutation),这两大类规则前者是对模型有较大改动,后者是细粒度的改动,从而生成足够多的模型来测试;为了解决第二个问题,本文采用启发式方法来迭代生成模型,每次迭代尽可能产生比突变前更大的不一致程度,也就是说让其朝着放大不一致程度的方向上生成模型。这样最终的模型在区分bug这一方面可以表现的更好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









