





 文章提出了一种名为SDFA的自蒸馏特征聚合模块,旨在解决多尺度特征聚合时的上下文一致性问题。SDFA-Net,基于SDFA的网络,采用编码器-解码器架构,利用修改版的Swin-transformer作为编码器,SDFA模块作为解码器。自蒸馏训练策略通过光度和可见性原理选择可靠深度,以指导网络学习。该方法用于自监督单目深度估计,提高了深度预测的准确性。
文章提出了一种名为SDFA的自蒸馏特征聚合模块,旨在解决多尺度特征聚合时的上下文一致性问题。SDFA-Net,基于SDFA的网络,采用编码器-解码器架构,利用修改版的Swin-transformer作为编码器,SDFA模块作为解码器。自蒸馏训练策略通过光度和可见性原理选择可靠深度,以指导网络学习。该方法用于自监督单目深度估计,提高了深度预测的准确性。
1.摘要和介绍(Abstract & Intro)
现有的大部分工作都通过直接串联(straightforward concatenation)或逐个元素添加(element-wise addition)来聚合用于深度预测的多尺度特征,然而,这种特征聚合操作通常忽略了多尺度特征之间的上下文一致性(contextual consisitency between multi-scale features)。针对这个问题,我们提出了自蒸馏特征聚合(SDFA)模块,用于同时聚合一对低尺度和高尺度特征,并保持它们的上下文一致性。SDFA采用三个分支分别学习三个特征偏移图:一个偏移图用于细化输入的低尺度特征,另两个偏移图在设计的自蒸馏方式下细化输入的高尺度特征。然后,我们提出了一种用于自监督单目深度估计的基于SDFA的网络,称为SDFA-Net,该网络使用一组立体图像对进行训练。SDFA Net采用编码器-解码器架构,该架构使用微小Swin变换器[38]的修改版本作为编码器,并使用多个SDFA模块的集成作为解码器。此外,还探索了一种自蒸馏训练策略来训练SDFA网络,该策略通过两个原则从原始深度预测中选择可靠的深度,并使用所选择的深度通过自蒸馏来训练网络。
2.方法论(Methodology)
2.1 网络体系结构
如图所示,所提出的SDFA-Net采用了具有跳跃连接的编码器-解码器架构,用于自监督单目深度估计。
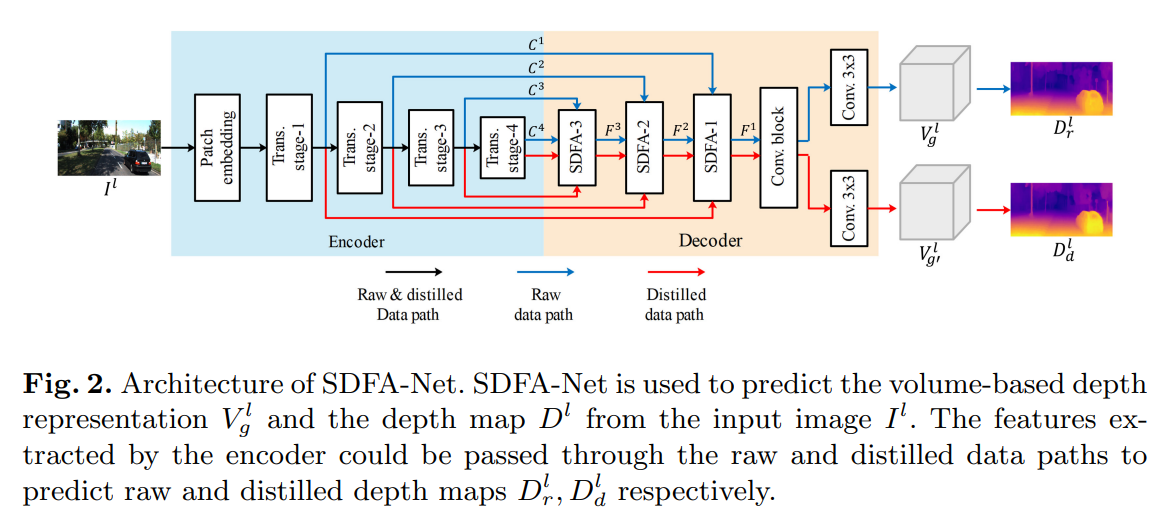
编码器:受视觉变换器(vision transformer)在各种视觉任务中取得成功的启发,我们引入了如下 tiny Swin-transformer的修改版本作为主干编码器,从输入图像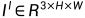 中提取多尺度特征。原始的Swin-transformer包含四个变换级,它通过步长为4的卷积层对输入图像进行预处理,产生4个中间特征
中提取多尺度特征。原始的Swin-transformer包含四个变换级,它通过步长为4的卷积层对输入图像进行预处理,产生4个中间特征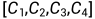 ,分辨率为
,分辨率为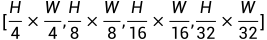 。考虑到丰富的空间信息对深度估计很重要,我们将原始Swin-transformer中步长为4的卷积层更改为步长为2的卷积层,以保留更多的高分辨率图像信息,因此 从Swin-transformer的修改版本中提取的特征是原来的两倍,即
。考虑到丰富的空间信息对深度估计很重要,我们将原始Swin-transformer中步长为4的卷积层更改为步长为2的卷积层,以保留更多的高分辨率图像信息,因此 从Swin-transformer的修改版本中提取的特征是原来的两倍,即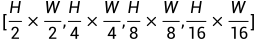 。
。
解码器:解码器使用从编码器提取的多尺度特征{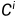 }
}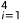 作为其输入,并输出视差logit体积(disparity-logit volume)
作为其输入,并输出视差logit体积(disparity-logit volume)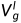 作为场景深度表示。解码器由三个SDFA模块(标注为SDFA-1、SDFA-2、SDFA-3)、一个卷积块和两个卷积输出层组成。SDFA模块被提出用于自适应地聚合具有可学习偏移图的多尺度特征,这将在2.2中详细描述。卷积块用于将聚合特征的空间分辨率恢复为输入图像的大小,由最近的上采样操作和两个3×3卷积层组成,使用ELU激活。为了在自蒸馏方式下训练SDFA模块,避免训练两个网络,编码的特征可以通过两条数据路径通过解码器,并通过不同的偏移映射进行聚合。两个3×3卷积输出层用于在训练阶段预测两个深度表征,分别定义为原始的深度表征和蒸馏的深度表征。因此,这两个数据路径被定义为原始数据路径和蒸馏数据路径。一旦训练了所提出的网络,给定任意测试图像,在推理阶段,仅使用输出的提取深度表示
作为场景深度表示。解码器由三个SDFA模块(标注为SDFA-1、SDFA-2、SDFA-3)、一个卷积块和两个卷积输出层组成。SDFA模块被提出用于自适应地聚合具有可学习偏移图的多尺度特征,这将在2.2中详细描述。卷积块用于将聚合特征的空间分辨率恢复为输入图像的大小,由最近的上采样操作和两个3×3卷积层组成,使用ELU激活。为了在自蒸馏方式下训练SDFA模块,避免训练两个网络,编码的特征可以通过两条数据路径通过解码器,并通过不同的偏移映射进行聚合。两个3×3卷积输出层用于在训练阶段预测两个深度表征,分别定义为原始的深度表征和蒸馏的深度表征。因此,这两个数据路径被定义为原始数据路径和蒸馏数据路径。一旦训练了所提出的网络,给定任意测试图像,在推理阶段,仅使用输出的提取深度表示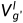 作为其最终深度预测。
作为其最终深度预测。
2.2 自蒸馏特征聚合
具有可学习特征偏移图的自提取特征聚合(SDFA)模块的提出是为了自适应地聚合多尺度特征并保持它们之间的上下文一致性。它联合使用来自前一层的低尺度解码特征及其来自编码器的相应特征作为输入,并输出聚合特征,如下图所示。这两个特征是从原始或提取的数据路径输入的。
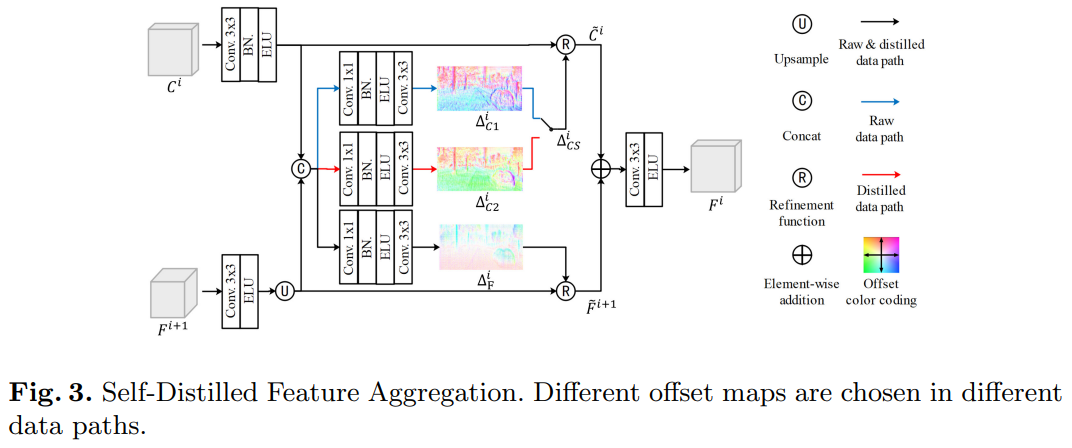
如上图所示,在设计的模块SDFA-i(i=1,2,3)下,来自其前一层的特征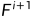 (特别地
(特别地 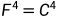 )通过ELU激活的3×3卷积层,并通过标准双线性插值进行上采样。同时,使用具有批量归一化(BN:Batch Normalization)和ELU激活的额外3×3卷积层来调整来自编码器的相应特征的信道维度,使其与的信道维度相同。然后,通过上述操作获得的两个特征被连接在一起,并通过三个分支来预测偏移图
)通过ELU激活的3×3卷积层,并通过标准双线性插值进行上采样。同时,使用具有批量归一化(BN:Batch Normalization)和ELU激活的额外3×3卷积层来调整来自编码器的相应特征的信道维度,使其与的信道维度相同。然后,通过上述操作获得的两个特征被连接在一起,并通过三个分支来预测偏移图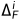 、
、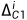 和
和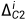 。用于细化上采样偏移图被用于细化上采样。根据使用的数据路径P,开关操作
。用于细化上采样偏移图被用于细化上采样。根据使用的数据路径P,开关操作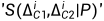 用于从和中选择偏移图,以细化调整后的,公式如下[1]:
用于从和中选择偏移图,以细化调整后的,公式如下[1]:
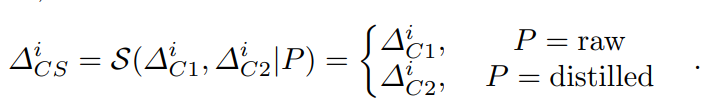
在获得偏移图后,设计了一个精化函数 ,以通过双线性插值内核实现的偏移图∆的引导来精化特征F。具体而言,为了从
,以通过双线性插值内核实现的偏移图∆的引导来精化特征F。具体而言,为了从 生成位置
生成位置 上的精细特征
上的精细特征 ,偏移量为
,偏移量为 ,细化函数公式如下[2]:
,细化函数公式如下[2]:
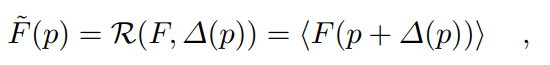
其中'<·>'表示双线性采样操作。相应地,获得细化特征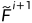 和
和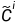 的公式如下[3][4]:
的公式如下[3][4]:

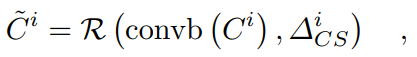
其中'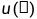 '表示双线性上采样,'conv(·)'表示通过ELU激活的3×3卷积层,'confb(·)'表示具有BN和ELU的3×3卷积层。最后,使用两个细化的特征获得的聚合特征
'表示双线性上采样,'conv(·)'表示通过ELU激活的3×3卷积层,'confb(·)'表示具有BN和ELU的3×3卷积层。最后,使用两个细化的特征获得的聚合特征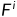 的公式如下[5]:
的公式如下[5]:
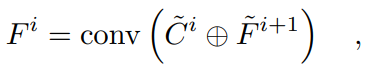
这里'+'表示元素相加。
考虑到(i)由于遮挡和图像模糊,通过自监督训练学习的偏移通常是次优的,以及(ii)通过利用额外的线索(例如,第3.3节中预测的深度图中的一些可靠深度)来学习更有效的偏移,SDFA通过如下设计的自蒸馏方式进行训练。
2.3 自蒸馏的训练策略
为了用一套SDFA模块训练所提出的网络,我们设计了一种自蒸馏训练策略,如图4所示,该策略将每次训练迭代分为三个顺序步骤:自监督前向传播、自蒸馏前向传播和损失计算。
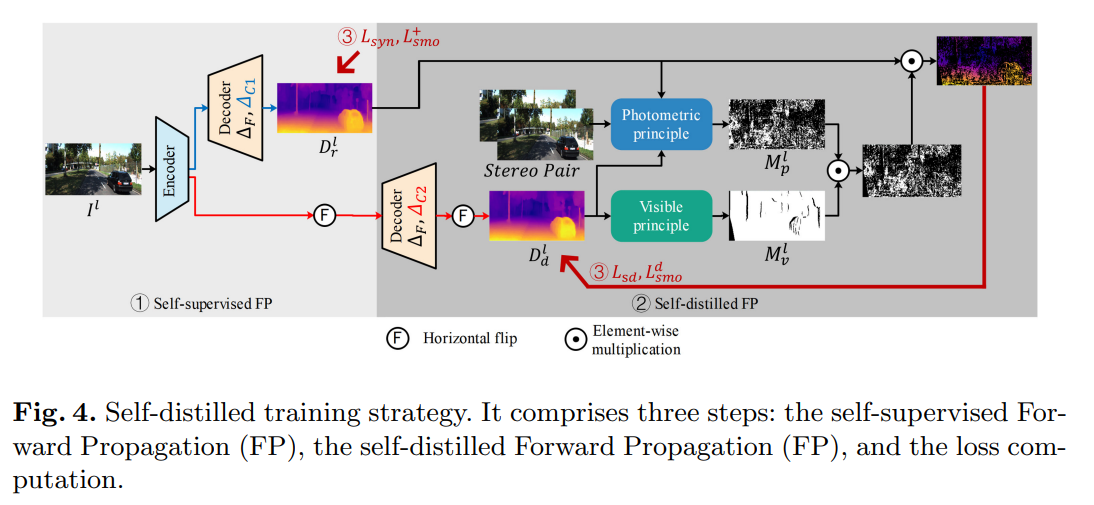
自我监督正向传播。在该步骤中,网络以立体对中的左图像 作为输入,通过原始数据路径输出左视差logit体积
作为输入,通过原始数据路径输出左视差logit体积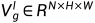 。和用于合成右图像,而原始深度图
。和用于合成右图像,而原始深度图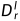 是用获得的。具体而言,给定最小和最大视差
是用获得的。具体而言,给定最小和最大视差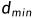 和
和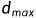 ,我们首先通过指数量化定义离散视差水平
,我们首先通过指数量化定义离散视差水平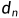 [6]:
[6]:
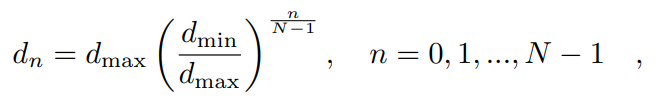
其中,N是视差级别的总数。为了合成右图像,的每个通道以对应的视差偏移,生成右视差logit体积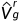 。右视差概率体积
。右视差概率体积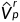 是通过使经过softmax操作而获得的,并且用于立体图像合成[7]:
是通过使经过softmax操作而获得的,并且用于立体图像合成[7]:

其中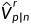 是的第n个通道,"⚪"表示逐元素乘法,
是的第n个通道,"⚪"表示逐元素乘法,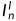 是随偏移的左图像。为了获取原始深度图,经过softmax操作来生成左视差概率体积
是随偏移的左图像。为了获取原始深度图,经过softmax操作来生成左视差概率体积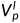 ,根据立体图像合成,的第n个信道近似等于的概率图。并且伪视差图
,根据立体图像合成,的第n个信道近似等于的概率图。并且伪视差图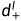 的计算如下[8]:
的计算如下[8]:
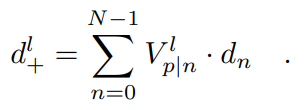
给定立体对的基线长度B和左相机的水平焦距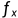 ,左图像的原始深度图的计算为:
,左图像的原始深度图的计算为:
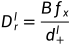
自蒸馏正向传播。为了减轻遮挡的影响并学习更准确的深度,编码器提取的多尺度特征{}被水平翻转,并通过蒸馏数据路径经过解码器,输出新的左视差logit体积。在翻转回之后,蒸馏视差图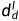 和蒸馏深度图
和蒸馏深度图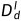 能够通过翻转的经过等式[8]的计算得到。为了在自蒸馏方式下训练SDFA-Net,我们采用两种原理从原始深度图中选择可靠的深度:光度原理和可见光原理。如图4所示,我们分别用两个二进制掩码实现了这两个原理。
能够通过翻转的经过等式[8]的计算得到。为了在自蒸馏方式下训练SDFA-Net,我们采用两种原理从原始深度图中选择可靠的深度:光度原理和可见光原理。如图4所示,我们分别用两个二进制掩码实现了这两个原理。
光度原理用于从的像素中选择深度,在这些像素中可以获得更好的重投影左图像。具体地,对于左图像中的任意像素坐标p,其在右图像中的对应坐标p′是通过左深度图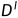 获得的[9]:
获得的[9]:
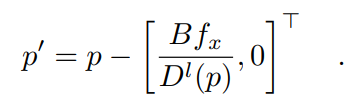
因此,通过将右图像像素p′的RGB值分配给 的像素p来获得重投影的左图像。然后,使用L1损失和结构相似性(SSIM)损失的加权和来测量重投影的图像和原始图像之间的光度差[10]:
的像素p来获得重投影的左图像。然后,使用L1损失和结构相似性(SSIM)损失的加权和来测量重投影的图像和原始图像之间的光度差[10]:
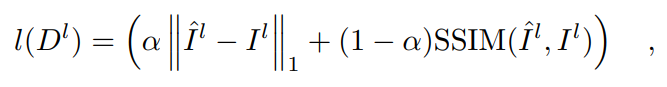
其中,α是一个平衡参数。光度原理公式如下[11]:
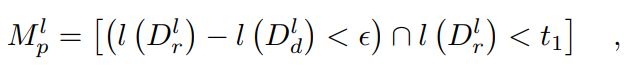
其中,'[·]'是艾弗森括号,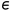 和
和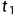 是预定义的阈值。艾弗森括号中的第二项用于忽略具有较大光度误差的不准确深度。
是预定义的阈值。艾弗森括号中的第二项用于忽略具有较大光度误差的不准确深度。
可见原理用于消除仅在左图像中可见的区域中的潜在不准确深度,例如,在右图像中被遮挡或在右图像的边缘之外的像素。可以利用左视差图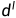 来找到在右图像中被遮挡的像素。具体而言,可以观察到,对于一个任意的像素位置
来找到在右图像中被遮挡的像素。具体而言,可以观察到,对于一个任意的像素位置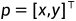 和它在左图中的水平右邻
和它在左图中的水平右邻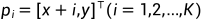 ,如果p的对应位置被右图中的
,如果p的对应位置被右图中的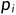 遮挡,它们之间的差异应该接近或等于它们水平坐标的差异 。因此,用蒸馏后的差异图计算出的遮挡掩码被表述为[12]:
遮挡,它们之间的差异应该接近或等于它们水平坐标的差异 。因此,用蒸馏后的差异图计算出的遮挡掩码被表述为[12]:
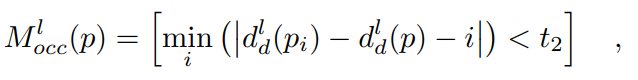
其中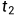 是预定义的阈值。此外,一个边缘外掩码
是预定义的阈值。此外,一个边缘外掩码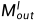 被联合利用,用于过滤掉对应位置在右图之外的像素。因此,可见原理被表述为[13]:
被联合利用,用于过滤掉对应位置在右图之外的像素。因此,可见原理被表述为[13]:
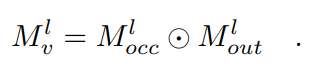
损失计算。在这一步,计算训练SDFA-Net的总损失。值得注意的是,原始深度图是通过最大化真实图像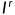 和合成图像
和合成图像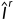 之间的相似度来学习的,而蒸馏深度图是通过自蒸馏学习的。总的损失函数由四个项组成:图像合成损失
之间的相似度来学习的,而蒸馏深度图是通过自蒸馏学习的。总的损失函数由四个项组成:图像合成损失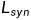 ,自我蒸馏损失
,自我蒸馏损失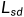 ,原始平滑度损失
,原始平滑度损失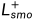 ,以及蒸馏平滑度损失
,以及蒸馏平滑度损失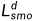 。
。
图像合成损失包括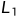 损失和感知损失[30],用于反映真实的右图像和合成的右图像之间的相似度[14]:
损失和感知损失[30],用于反映真实的右图像和合成的右图像之间的相似度[14]:
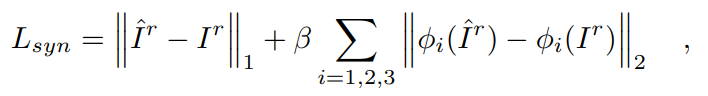
其中,'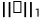 '和'
'和'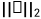 '代表L1和L2准则,
'代表L1和L2准则,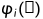 表示预训练的VGG19的第i个池化层的输出,β是一个平衡参数。
表示预训练的VGG19的第i个池化层的输出,β是一个平衡参数。
自蒸馏损失采用损失从原始深度图蒸馏出精确的深度图,其中精确的深度是由光度和可见光掩码 和
和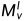 选择的[15]:
选择的[15]:
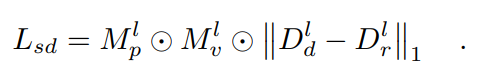
边缘感知的平滑度损失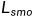 被用于约束伪视差图
被用于约束伪视差图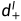 和蒸馏悬殊地图的连续性[16][17]:
和蒸馏悬殊地图的连续性[16][17]:
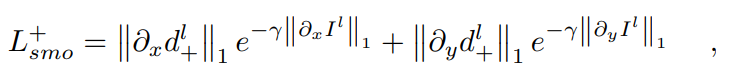
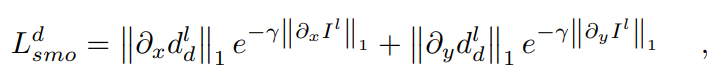
其中'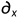 '、'
'、'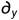 '分别为水平和垂直方向的微分算子,γ为调整边缘保存程度的参数。
'分别为水平和垂直方向的微分算子,γ为调整边缘保存程度的参数。
因此,总损失是上述四项的加权和,其表述为[18]:
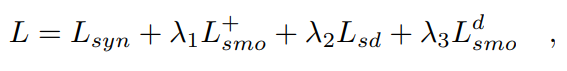
其中{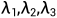 }是三个预设的权重参数。考虑到在自我监督方式下学习的深度在早期训练阶段是不可靠的,在这些训练迭代中
}是三个预设的权重参数。考虑到在自我监督方式下学习的深度在早期训练阶段是不可靠的,在这些训练迭代中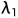 和
和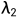 被设置为零,而自我蒸馏的前向传播被禁用。
被设置为零,而自我蒸馏的前向传播被禁用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









