







目录
起因是本人选了一个并行计算相关的课程,最后有一个课程设计,于是做了此项工作。
主要用到了一个大佬的程序,我就做了环境配置,debug等操作。下面贴上原作链接。
灰度图像处理——基于GPU的并行编程模型CUDA程序设计_图像 灰度化 cuda-CSDN博客
因为原作没有具体说明此程序的环境是怎么配置的,我在此说明一下。
首先是三个程序的安装:CUDA+VS2022+opencv
建议安装顺序,CUDA在VS2022之后安装,会避免一些在VS中编译CUDA相关代码失败的问题,opencv的安装顺序则随意
opencv的下载安装教程:
下面贴出了opencv官网,选择版本,我直接选的4.8.0
下载完成打开选择路径(建议全英文路径)然后安装。
完成后开始设置环境变量(找到你安装opencv的路径对应的添加进去)
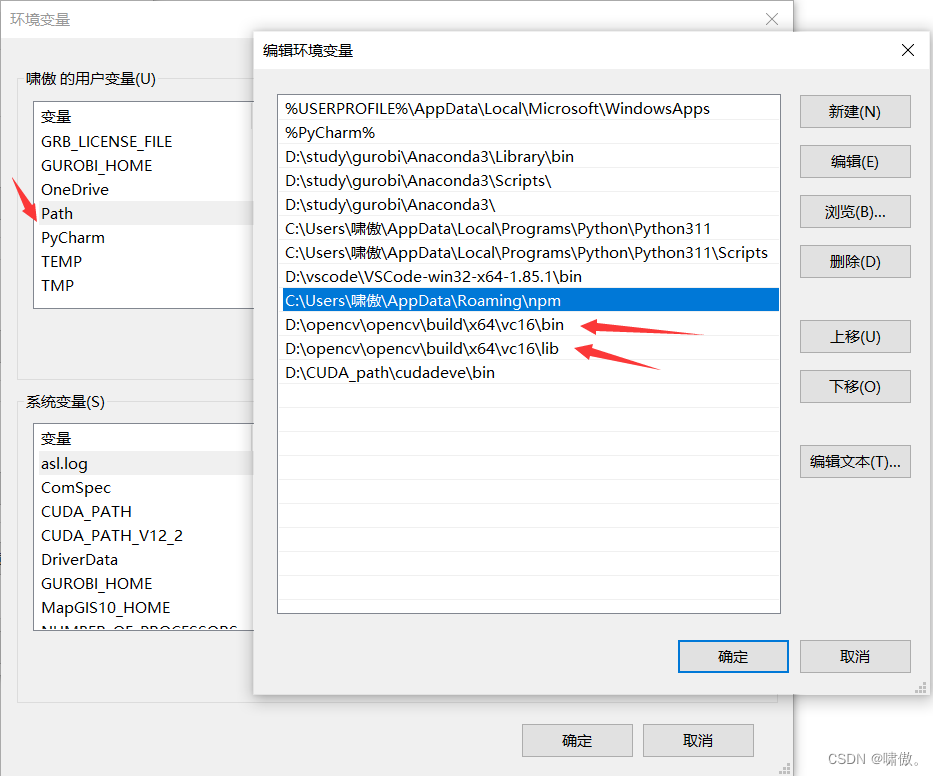
opencv安装结束
vs2022安装教程贴一个链接
Visual Studio 2022安装与使用教程-CSDN博客
——————————————————————————————————————————
目前为止装完vs2022和opencv,我们可以先测试一下
1.打开Visual Studio,新建一个项目

注意项目路径这块必须全英,不然可能要出问题

2.配opencv环境

到这个界面,点一下里面空白,出现三个点,选择路径
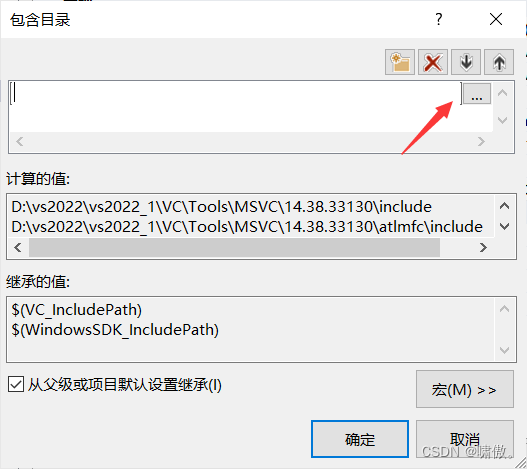
到如下图界面,找到你的opencv路径里面的include,确保这个界面include是被选中状态,点击选择文件夹
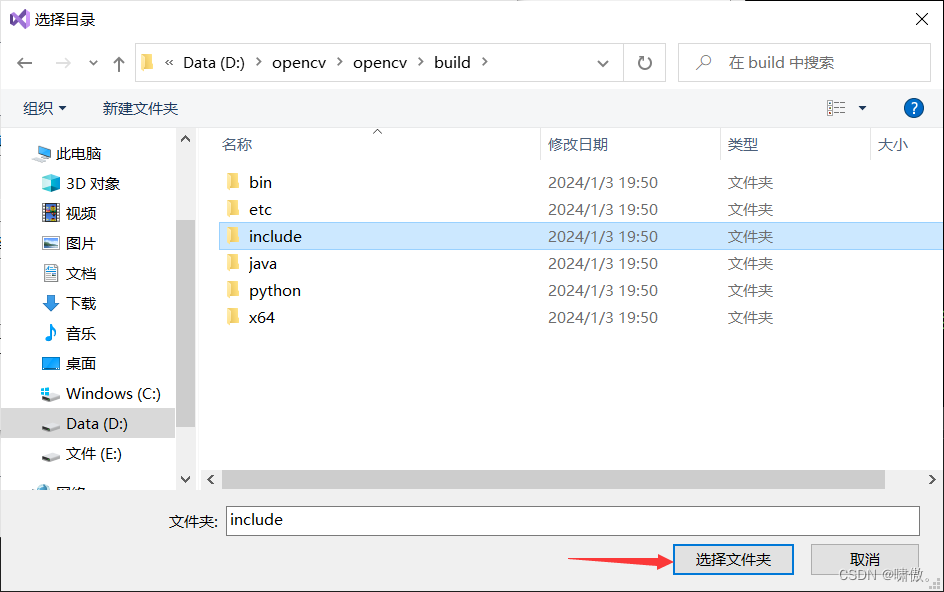
如下图所示再添加第二个路径
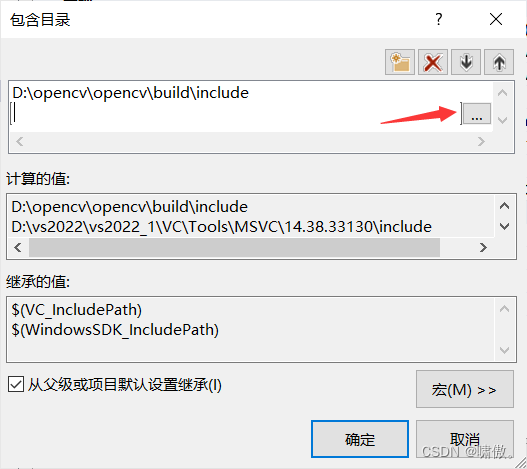
是include文件夹下的opencv2,也添加进去
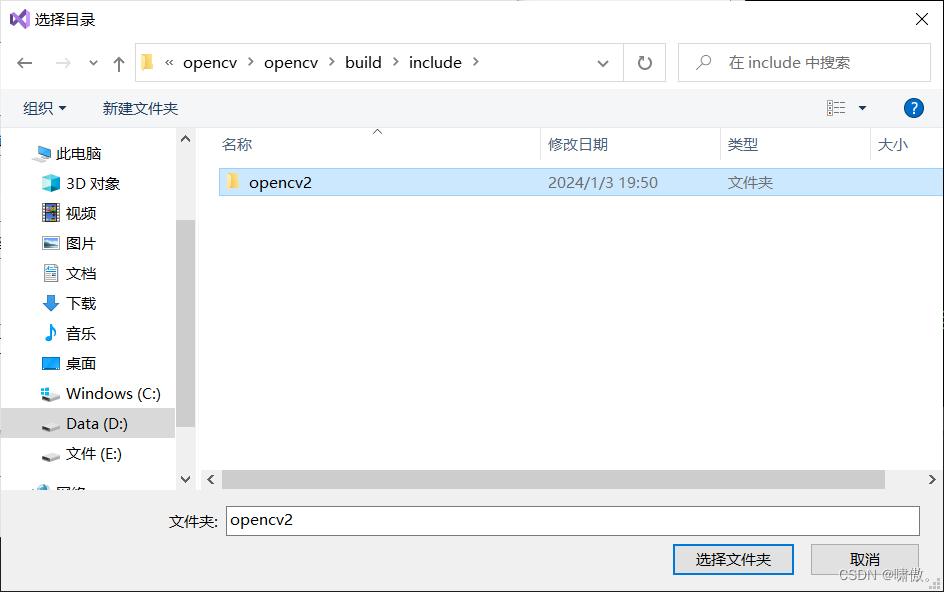
添加完点击确定
3.添加库目录,操作类似
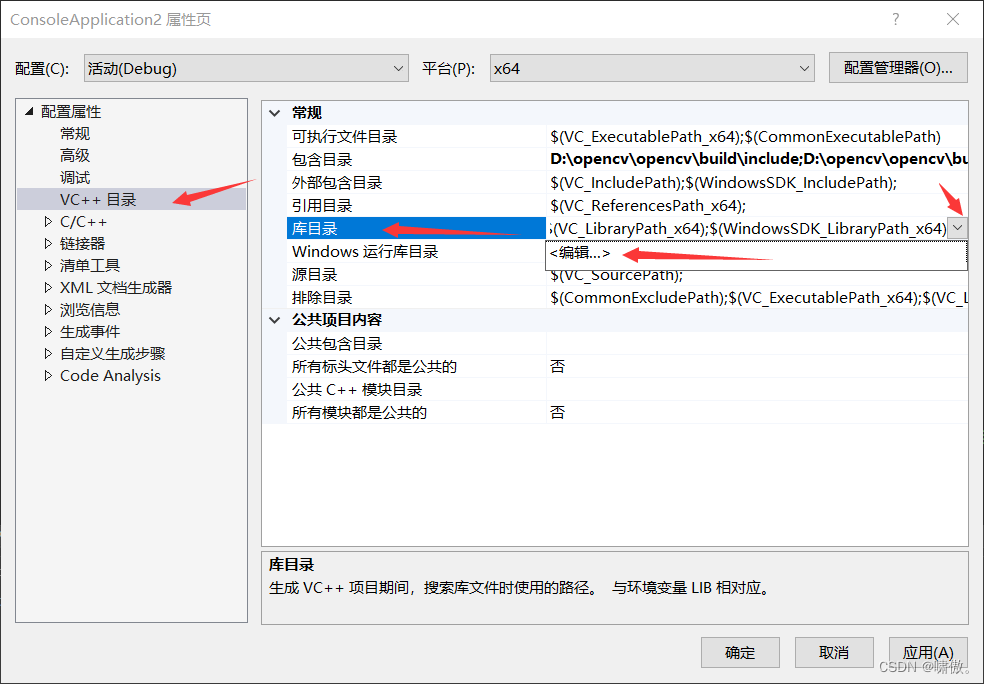
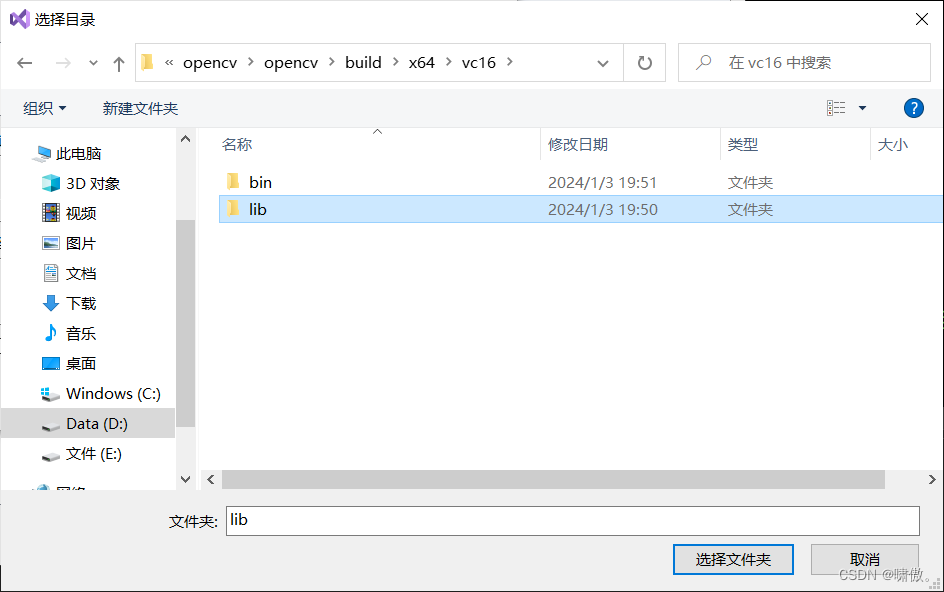
库目录路径如下图所示
 4.添加依赖项
4.添加依赖项
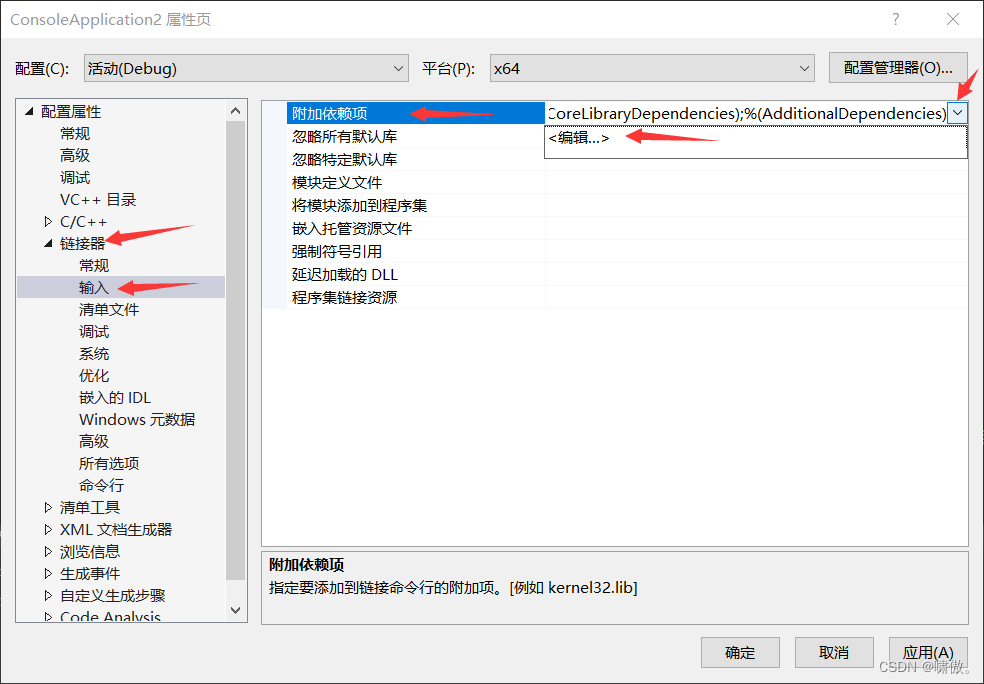
注意这里去你刚才库目录的路径下去看一下里面的内容,如下图所示,然后复制opencv_world480d.lib全名,粘贴到附加依赖项的窗口中

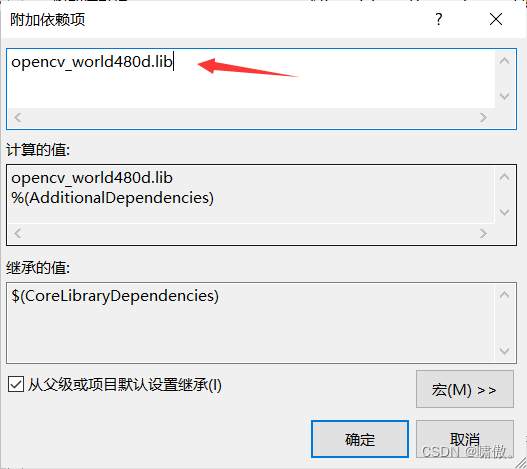
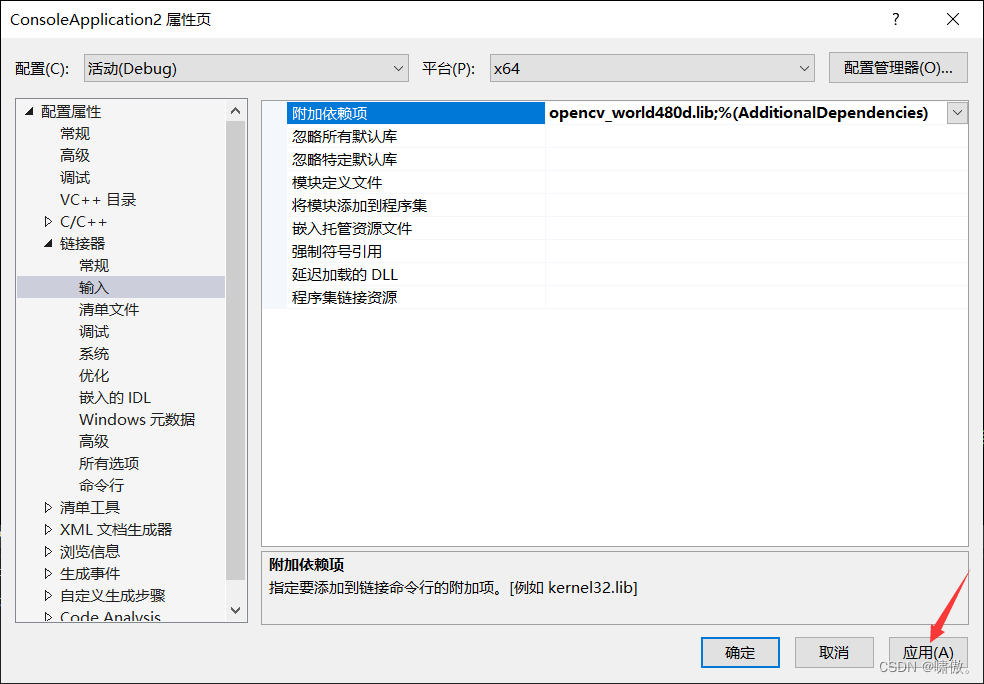
最后不要忘记点应用
5.测试样例
环境配好了要跑一段代码测试一下,我在E:\\picture\\source\\路径下放了一个xiaogong.png图片,然后复制粘贴代码直接运行。
//读取图片并显示
#include "stdio.h"
#include<iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
using namespace cv;
int main()
{
Mat img = imread("E:\\picture\\source\\xiaogong.png");
namedWindow("测试opencv");
imshow("测试opencv", img);
waitKey(5000);
}
效果图如下:
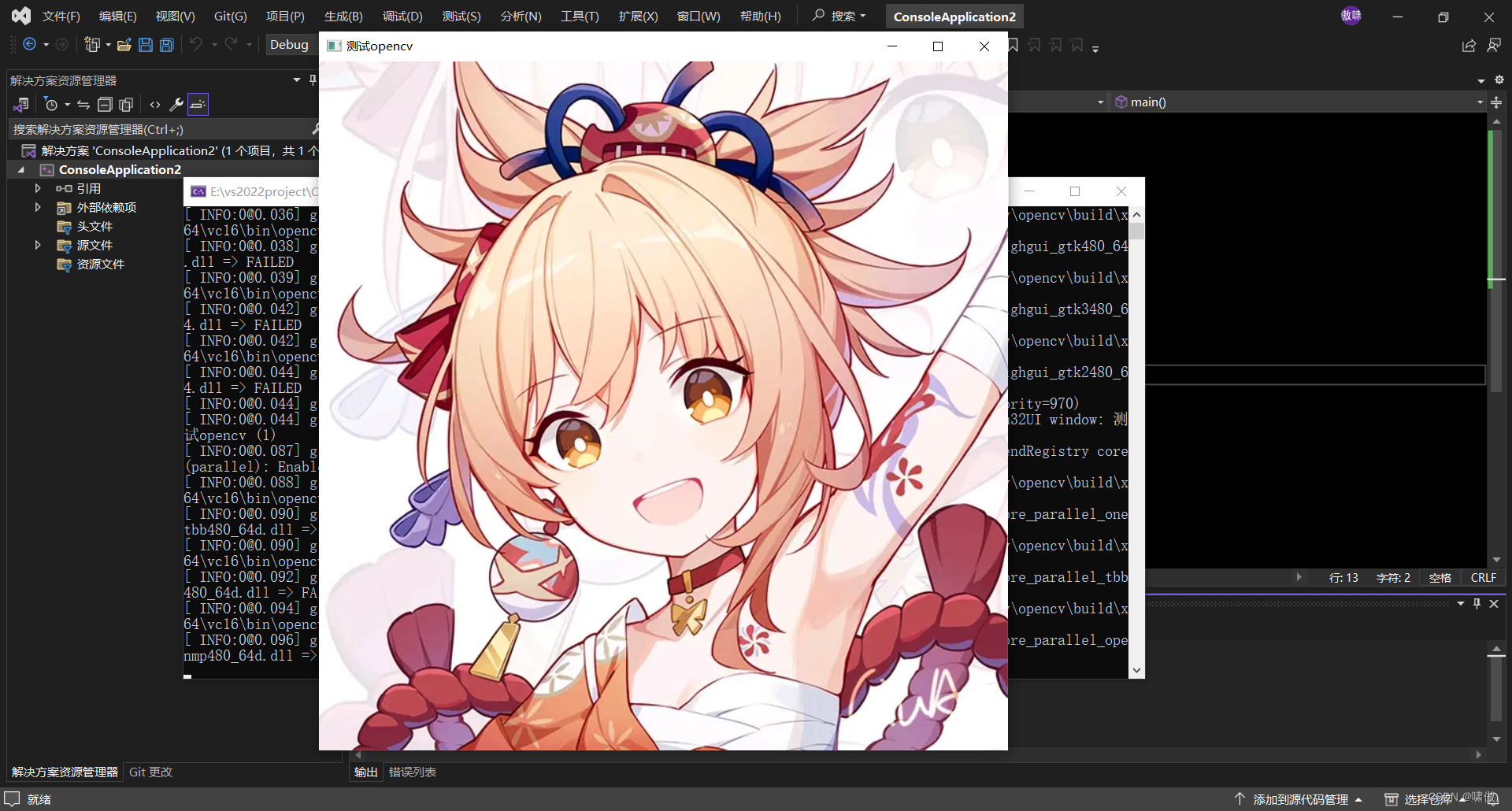
到此为止opencv和vs2022环境配置成功,后续每次新建工程都要重复上述配环境的步骤
———————————————————————————————————————————
CUDA安装
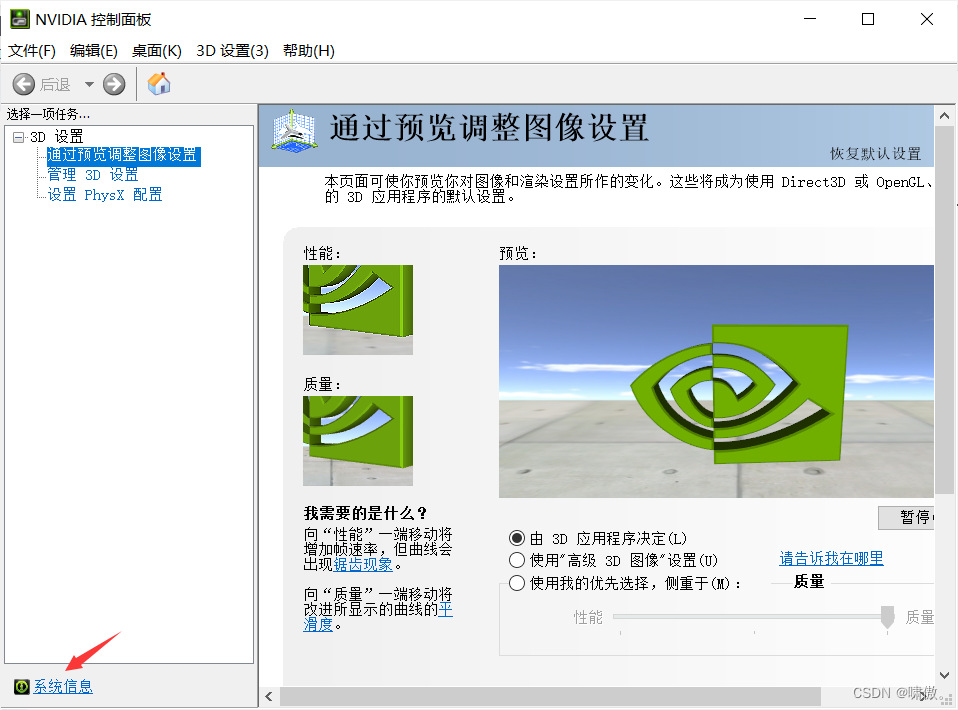
右键NVDIA选择控制面板,选择系统信息,选择组件
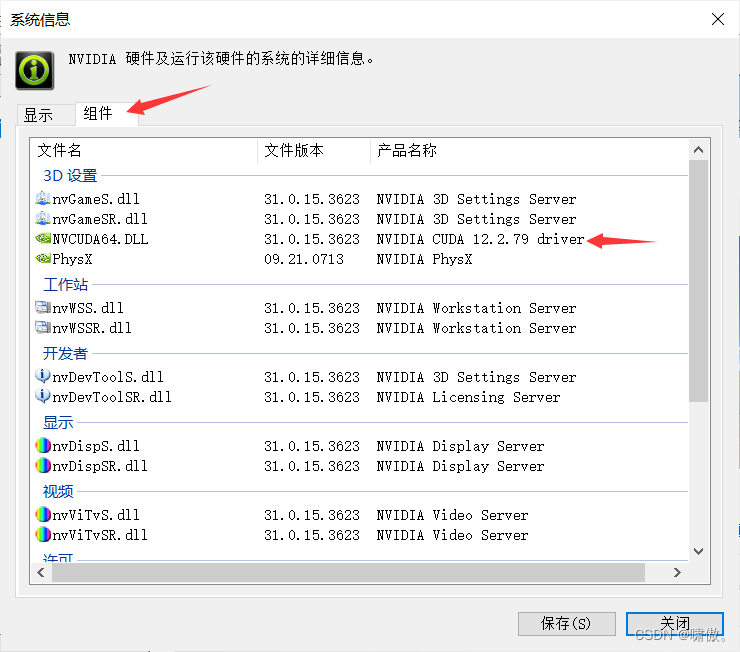
可以看到我的CUDA版本支持是12.2.79,下载CUDA版本不要超过,也不要太老,这里选择CUDA12.2.0,下面贴上CUDA下载链接
CUDA Toolkit Archive | NVIDIA Developer
可以选择自己想下载的版本,我选择12.2.0
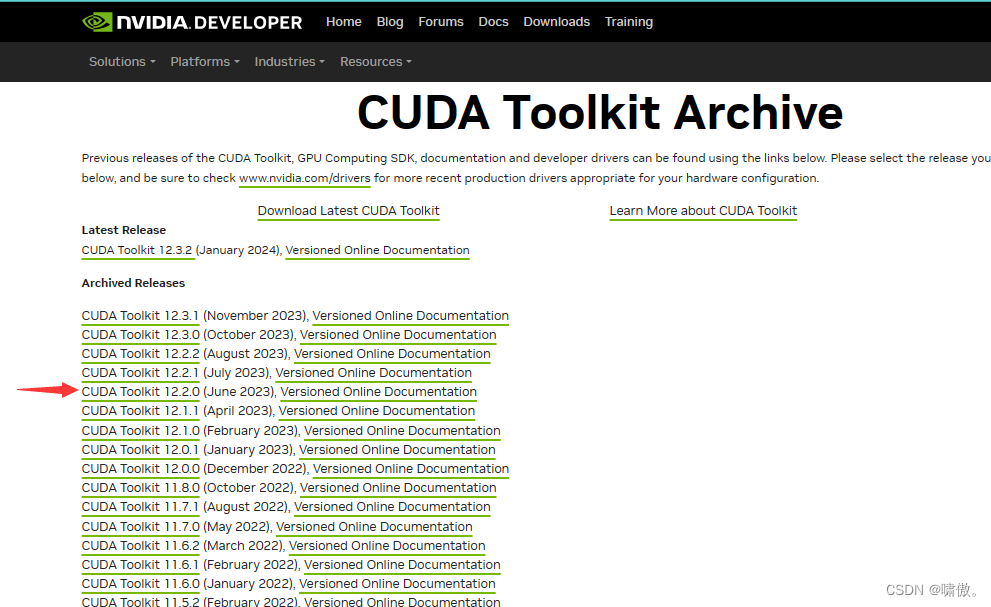
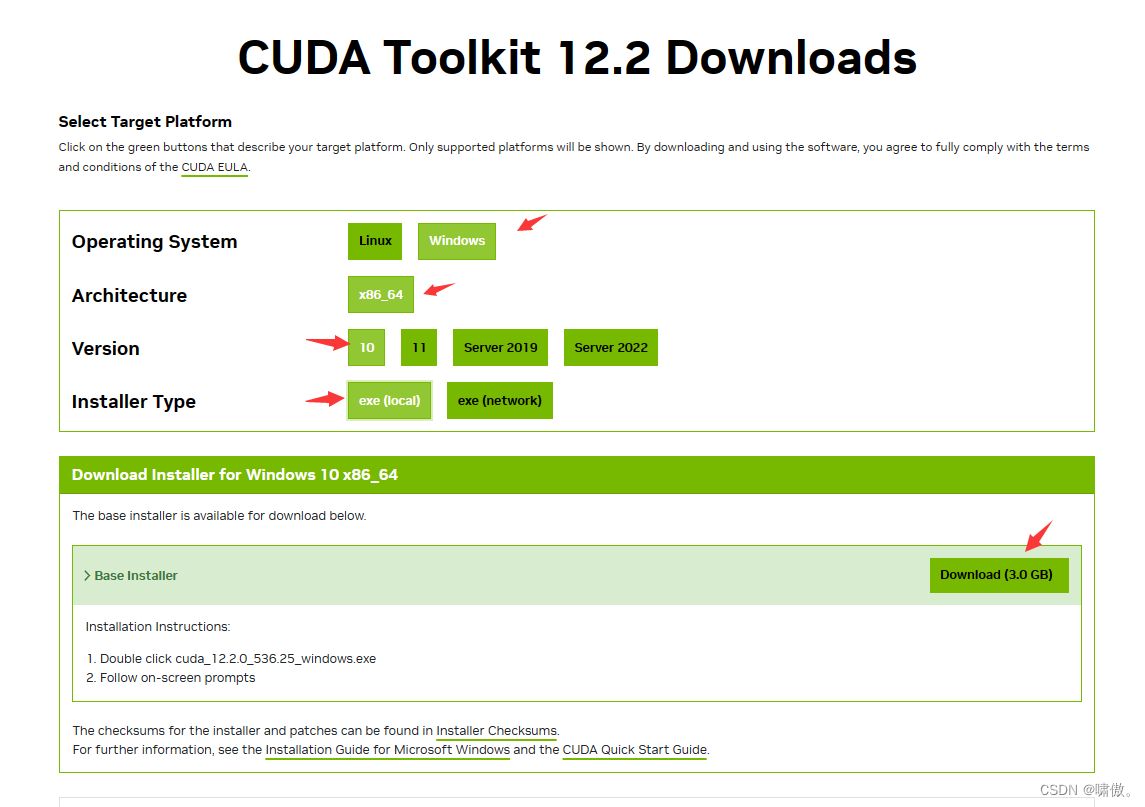
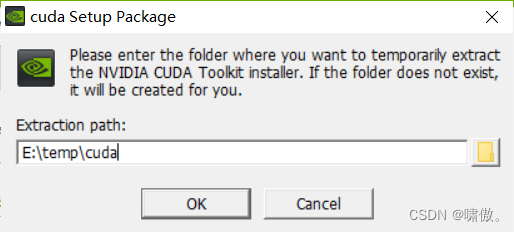
本地下载也不慢,挺快的。下载完打开。这里选择一个空文件夹,因为要存放临时文件,安装完会删除。(有文件的文件夹它不让你选)。
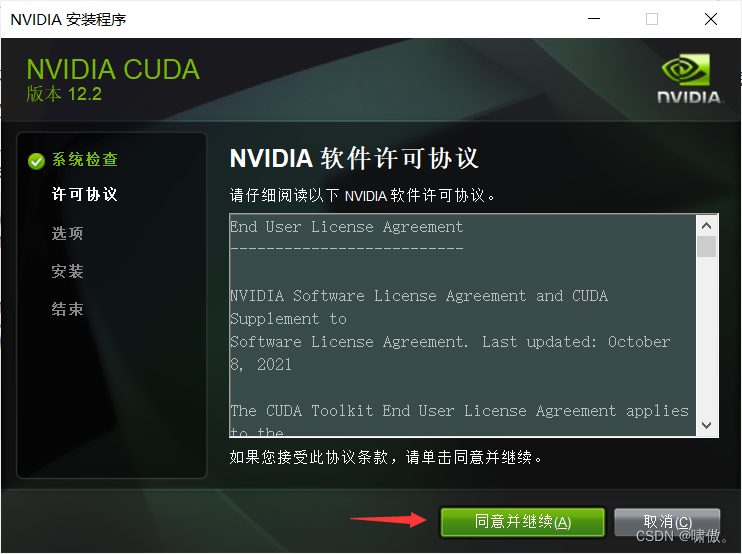

把下面三个取消勾选,用不到,这个时候可能卡,可以点一下后退再回来取消勾选
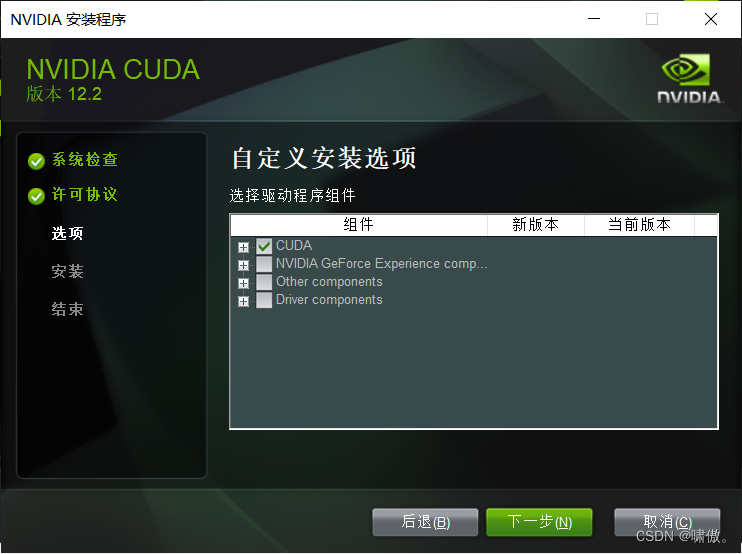
然后CUDA这里是全勾上的,特别注意Visual Studio那一条,因为我们前面装了vs2022,所以这里勾上,可以方便很多事情,如果你前面没装vs2022或者其他vs版本,那这里要取消勾选Visual Studio这一条,否则CUDA安装不上。
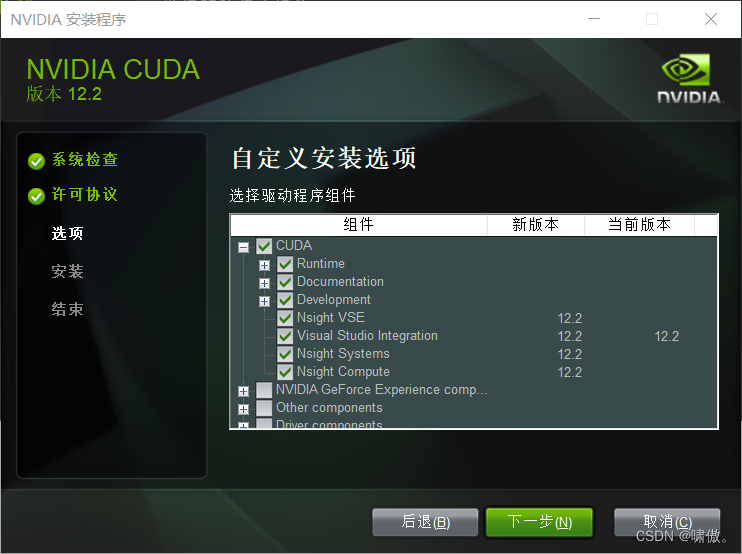
下面这俩自己选路径,最好全英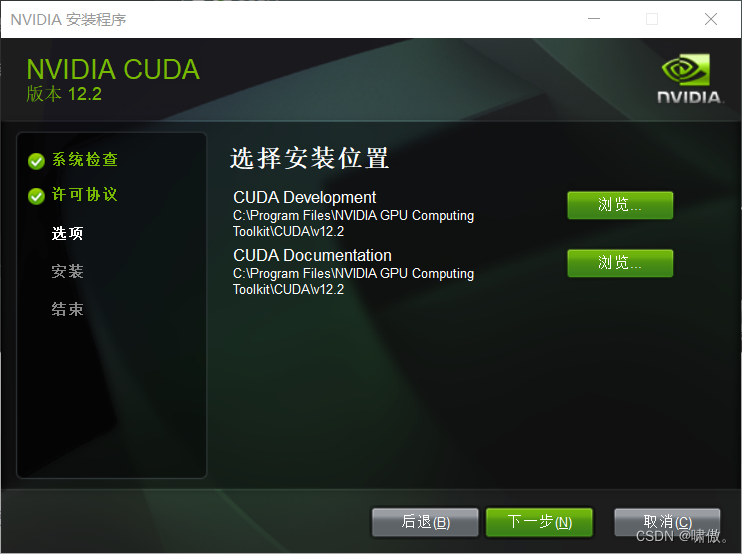
安装完毕,win+r打开cmd命令行,输入nvcc -V,注意V大写,如下显示即为成功,如果不成功,也可能是环境变量问题,请自行百度。
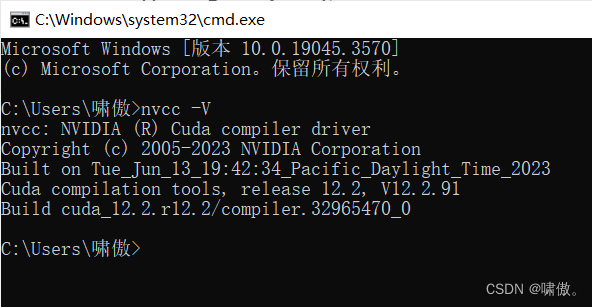
到此,三个程序安装完成。
———————————————————————————————————————————
下面开始跑灰度图像处理的程序
因为安装了CUDA,所以vs2022新建项目时可以在搜索栏搜索cuda,选择cuda模板,创建时务必全英路径

创建完成后,重新配置一遍opencv的环境,不再赘述
然后进入这个项目地址,如图操作进入
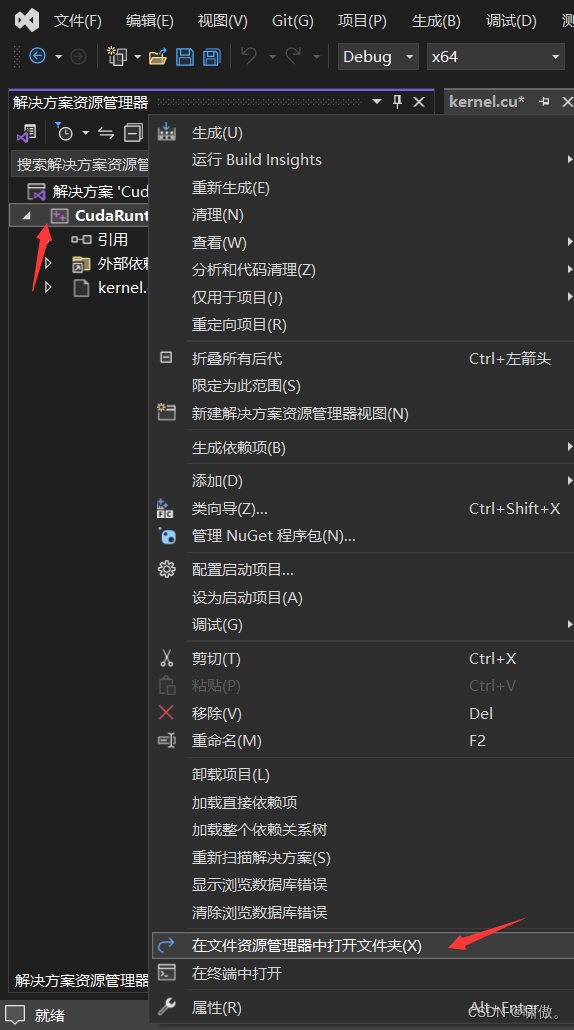
新建如下如图所示的两个文件夹,其中GrayPicture是空的,Picture是存放14张彩色图片
然后,将原作者中串行 程序代码复制直接编译运行,基本如下图所示
结束后,GrayPicture文件夹内可以看到变灰的图片。
原作的并行程序代码复制粘贴也一样能跑。
———————————————————————————————————————————
结束
















 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









