






目录
GPT-1:期望在GPT-1结构上使用无监督训练+有监督微调微调的框架解决问题
自回归语言模型(Autoregressive LM)与自编码语言模型(Autoencoder LM)
XLNet的优化3 - Relative Segment Encodings
GPT
transformer -> GPT -> BERT -> GPT-2 -> GPT-3
基于Transformer Decoder的自回归语言模型
最大化似然函数:文本出现的联合概率,取log之后会变成求和,设置了一个窗口大小k,在窗口内的当前词之前的词的概率下当前词为目标词的概率的乘积
GPT-1:期望在GPT-1结构上使用无监督训练+有监督微调微调的框架解决问题
无监督训练
由去掉了encoder-decoder attention的decoder block(即单纯masked multi-head attention)组成,每一层都是masked预测的结构 + position-wise的前向传播层,即我们在预测词u时,把窗口内前面的k个词拿出来组成U,对U做一个词嵌入的投影加上位置信息的编码:得到第一层的输入,之后的n层都是把上一层的输出拿出来作为下一层的输入,对最后一个块的输出再做一个投影做softmax可以得到概率分布。
![]()
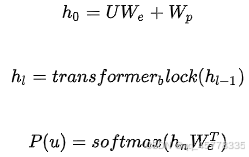
在GPT-1上做无监督训练的终止条件:通过准确率来评价训练何时停止
有监督微调
给定输入序列 ![]() 和标签 Y,可以通过语言模型得到
和标签 Y,可以通过语言模型得到 ![]() ,经过输出层后对 Y 进行预测:
,经过输出层后对 Y 进行预测:
![]()
损失函数: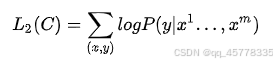
微调目标函数:![]()
通过将问题转化为文本段落拼接,在分类任务,推理任务,句子相似性,问答任务上都可以应用。
其他细节:使用BPE,GELU,adam,参数量117M
GPT-2: zero-shot
当模型的容量非常大且数据量足够丰富时,仅仅靠语言模型的学习便可以完成其他有监督学习的任务,不需要在下游任务微调。
与GPT-1区别:
- GPT-2的输入会加入提示词,比如:“TL;DR:”,GPT-2模型就会知道是做摘要工作了,有点prompt-learning/In Context Learning的感觉。
- 在结构上,基于GPT-1的单向transformer编码结构,将layer normalization放到残差网络内部 [即为了降低训练难度将post-norm改成了pre-norm:LLM:大模型的正则化],并在最后一个Self-attention后再增加一个layer normalization。
其他细节:增大vocab size,滑动窗口大小,batch size,transformer堆叠层数加到48,隐层维度增至1600,参数数量1.5B
GPT-3: 暴力出奇迹
目前存在的局限:有监督下的数据标注工作量;在微调时表现的很好的模型并不代表泛化性会很好
in-context learning: 通过对输入的上下文的学习理解任务要求,zero-shot, few-shot,不像fine-tuning需要更新权重,这里是不更新权重的。
模型结构上基于GPT-2的架构(pre-norm和可以反转的词元),区别主要在于使用了稀疏的自注意力,具体叫局部带状稀疏注意力locally banded sparse attention。
在训练数据上针对Common Crawl训练了一个分类器,做了去重来提高数据集质量,lsh判断数据集合相似度。
dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)。 sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)。
使用 sparse attention 的好处:
1. 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
2. 具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少。
训练了8个不同大小的模型,最大的参数量达到175B,96层96个头,隐层维度12,888,窗口大小增至2048.
实际训练时采用了良好的模型分割和数据分割;
GPT-3局限:
- 在需要双向性能的任务上表现较差
- 在“常识物理”方面存在困难
- 推理时既昂贵又不方便
- few-shot的真实作用
- 结果缺少可解释性
- 生成敏感内容
- 生成重复内容
- 难以识别任务是否存在意义
参考:GPT-1、GPT-2和GPT-3模型详解及其进化之路_gpt1.0 gpt2.0 gpt3.0-CSDN博客
XLNet(2019)
基于 Transformer Encoder,相对于Bert的三个主要改进点:
- 引入PLM预训练目标
- 更多更高质量的预训练数据:是bert数据量的十倍,batch_size是bert的8倍,training steps是bert的1/2,相当于在预训练阶段看到了bert四倍的序列。
- 采用transformerXL的主要思想解决长文档输入
改进结果是比bert在(1)生成类任务上有明显优势,对于(2)长文档输入的nlp任务也会更有优势。参考:XLNet:运行机制及和Bert的异同比较
自回归语言模型(Autoregressive LM)与自编码语言模型(Autoencoder LM)
自回归语言模型指的是根据上文内容预测下一个可能跟随的单词,就是常说的自左向右的语言模型任务,或者反过来也行,就是根据下文预测前面的单词。
自编码语言模型典型的例子是Bert的训练过程,采用Denoising Autoencoder(DAE,去噪自编码)模式让模型通过学习从部分损坏的输入数据中恢复原始数据,MLM任务就是输入数据(训练数据)被“噪声化”,被替换为[MASK],模型需要学习预测这些被掩码的词。
自编码的优点是适合理解类的NLP任务,能够同时看到待预测单词的上下文,缺点是训练任务和下游任务不匹配。生成任务通常并没有部分信息缺失的情况,模型需要根据上下文生成新的信息。例如,在机器翻译或文本生成任务中,输入是完整的,而输出是新的文本,模型需要在没有噪声的情况下生成完整的句子或段落,除此之外实际任务数据中没有[MASK]标识。
自回归的优点是适合生成类的NLP任务,预训练过程匹配下游任务,缺点是只能利用单向信息。
XLNet的优化1 - 引入PLM预训练目标
permutation language model(PLM):排列语言模型
简单来说就是将句子中的 token 随机排列,然后采用 AR 的方式预测末尾的几个 token。
XLNet 中通过 Attention Mask 实现 PLM,而无需真正修改句子 token 的顺序,其中白色为掩码,原序为[1,2,3,4]。如4能够看到[3,2]因此将下图第四行第一个和第四个掩码。XLNet引入了Two-Stream Self-Attention和Partial Prediction。
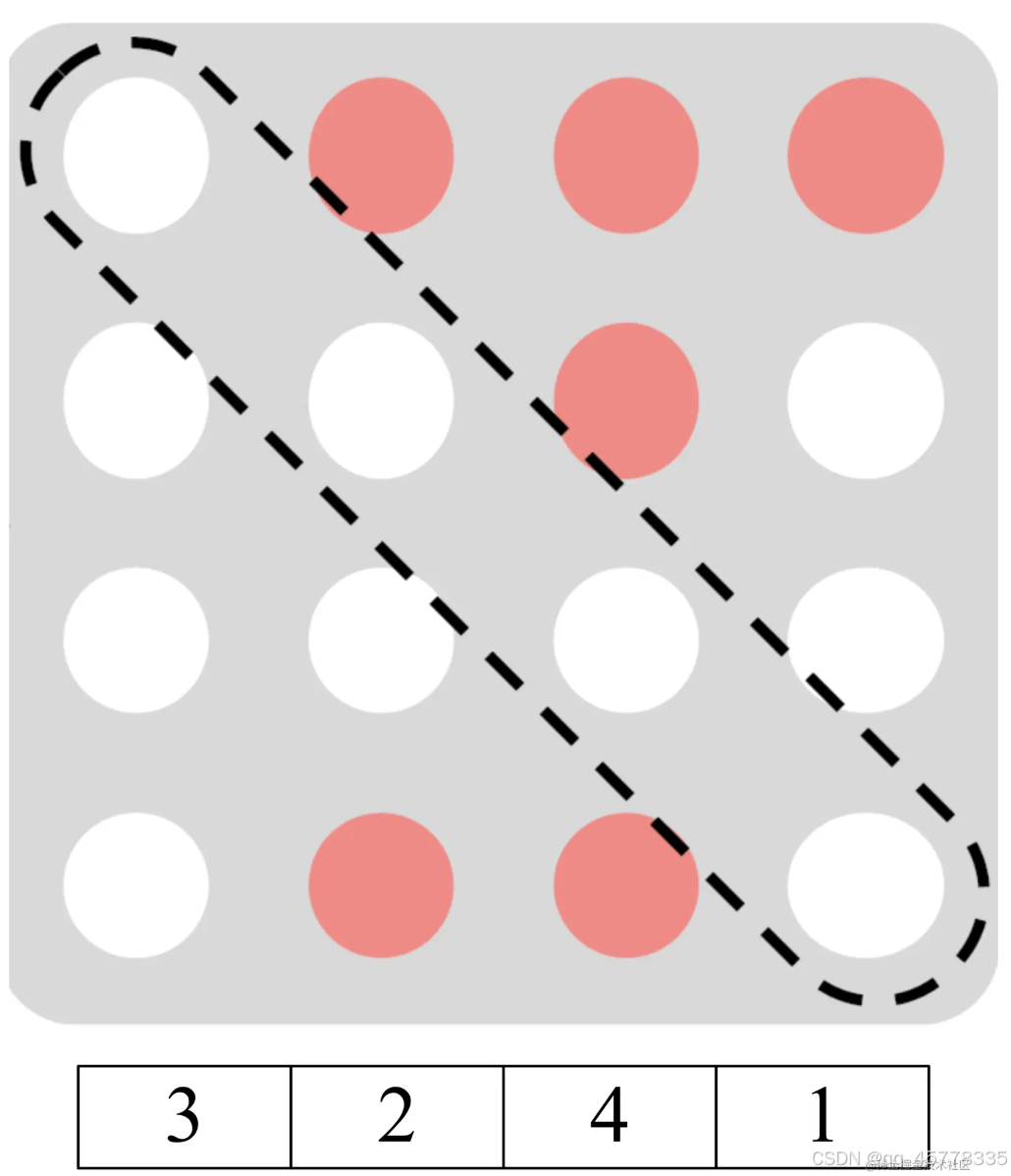
具体原理可视化参考:XLNet 详解
Two-Stream Self-Attention
- Query Stream,对于每一个 token,其对应的 Query Stream 只包含了该 token 的位置信息,注意是 token 在原始句子的位置信息,不是重新排列的位置信息。
- Content Stream,对于每一个 token,其对应的 Content Stream 包含了该 token 的内容信息。
Partial Prediction
由于句子是随机排列的,会导致优化比较困难且收敛速度慢。因此 XLNet 采用了 Partial Prediction (部分预测) 的方式进行训练,对于排列后的句子,只预测句子末尾的 1/K 个 token。
论文中训练 XLNet-Large 时使用的 K 为 6,大约是预测末尾 14.3% 的 token。
XLNet的优化2 - transformerXL
主要使用了transformerXL的Segment Recurrence Mechanism (段循环) 和 Relative Positional Encoding (相对位置编码) ,即XLNet中的Query Stream包含的是相对位置编码。
XLNet的优化3 - Relative Segment Encodings
这里的相对段落编码和相对位置编码不同,XLNet采用和Bert相同的句子形式:
[A, SEP, B, SEP, CLS]
这种句子形式在引入transformerXL的Segment Recurrence Mechanism后存在问题,即前后两段每一段都会有句子A和句子B,不能像Bert那样使用一个segment embedding表示,因此对每个attention head引入可训练向量s_+, s_-,b(偏置),q_i是query,a_ij是计算得到的 attention score ,会加到原来的 attention score 上。
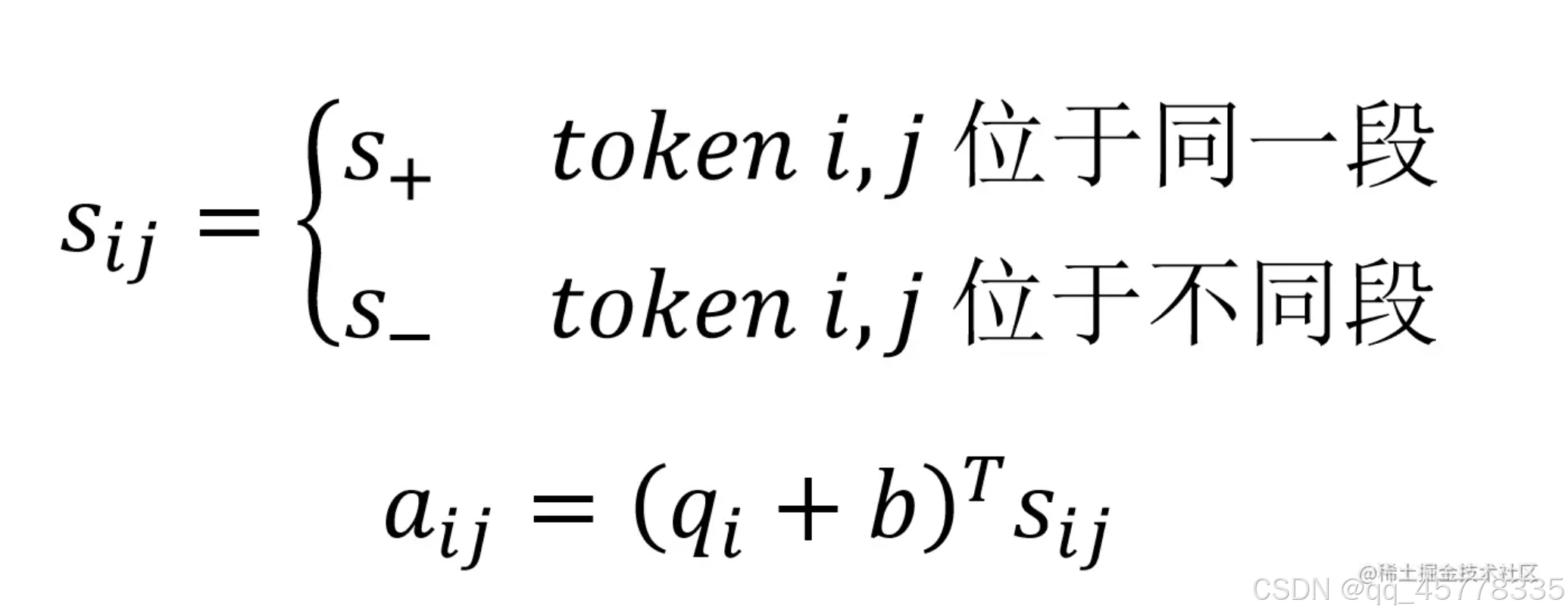
RoBERTa (2019)
基于 Transformer Encoder,相对于Bert的区别:参考:[预训练语言模型专题] RoBERTa: 捍卫BERT的尊严-腾讯云开发者社区-腾讯云
- 用更大的batch_size,更多的数据进行更久的训练:1M steps, 256 batch_size(bert-base) ->125K steps, 2K batch_size(最优)->31K steps, 8K batch_size, 其中学习率需要对应增大
- 移除了next sentence prediction(nsp)任务:尝试了segment-pair+nsp、sentence-pair+nsp、full-sentences(cross documents and add seperate token)、doc-sentences(not cross documents 动态调整较少的tokens下的batch_size),发现在doc-sentences下最优,但是为了使用固定的batch_size和相关工作进行比较,采用次优的full-sentences。
- 对数据进行动态掩码,这样在更大的数据集上或者更多步数的训练上会表现更好。
- text encoding方式:BPE分词方法中如果使用unicode编码,每一个character会占据vocab的大部分,因此使用byte-level BPE,以byte为base subword units,因为byte有固定的排列组合2^8种,可以学习到一个适中的vocab尺寸大概在50K,而且可以编码任何输入而不需要产生任何unknown words,泛化能力强。Bert使用的是WordPiece分词方式,即在BPE的基础上优化了选择高频词组的方式,使用点互信息表示两个子词之间的凝聚程度的高低,在选取待合并的两个单元时就选取点互信息最高的。可参考:几种 tokenize 策略
- RoBERTa所有的训练样本几乎都是全长512的序列,这与BERT先通过小的序列长度进行训练不同。BERT的实现代码中有一个short_seq_prob来设置小序列长度的比例,会取一个2到max_num_tokens的随机数作为target_seq_length。
T5 (2019)
首先需要理解为什么会有T5这样一篇论文,没有很新的idea,但是提出一个通用框架,接着进行了各种比对实验,获得一套建议参数,最后得到一个很强的 baseline。
基础知识:T5将所有的自然语言处理任务都转化为文本到文本的转换任务,以Text-to-Text为预训练任务,通过多种预训练任务(如翻译、问答、摘要等),让模型学会在不同任务间共享知识。和BERT对比时,BERT专注于编码任务,擅长理解文本上下文,可以应用于文本表示领域如文本分类,情感分析,问答系统,命名实体识别等,需要在下游任务上做微调;T5应用于所有可以转化为文本生成的任务,在多任务学习上存在优势,如机器翻译,问答,文本摘要等。
Baseline:
模型架构:具备Transformer Encoder和Decoder的完整架构,220M parameters,大概是 bert-base 的两倍。在模型框架上,和transformer有三点区别:
1.移除了layer norm bias:transformer的源码中layernorm的过程包含缩放因子和偏执项
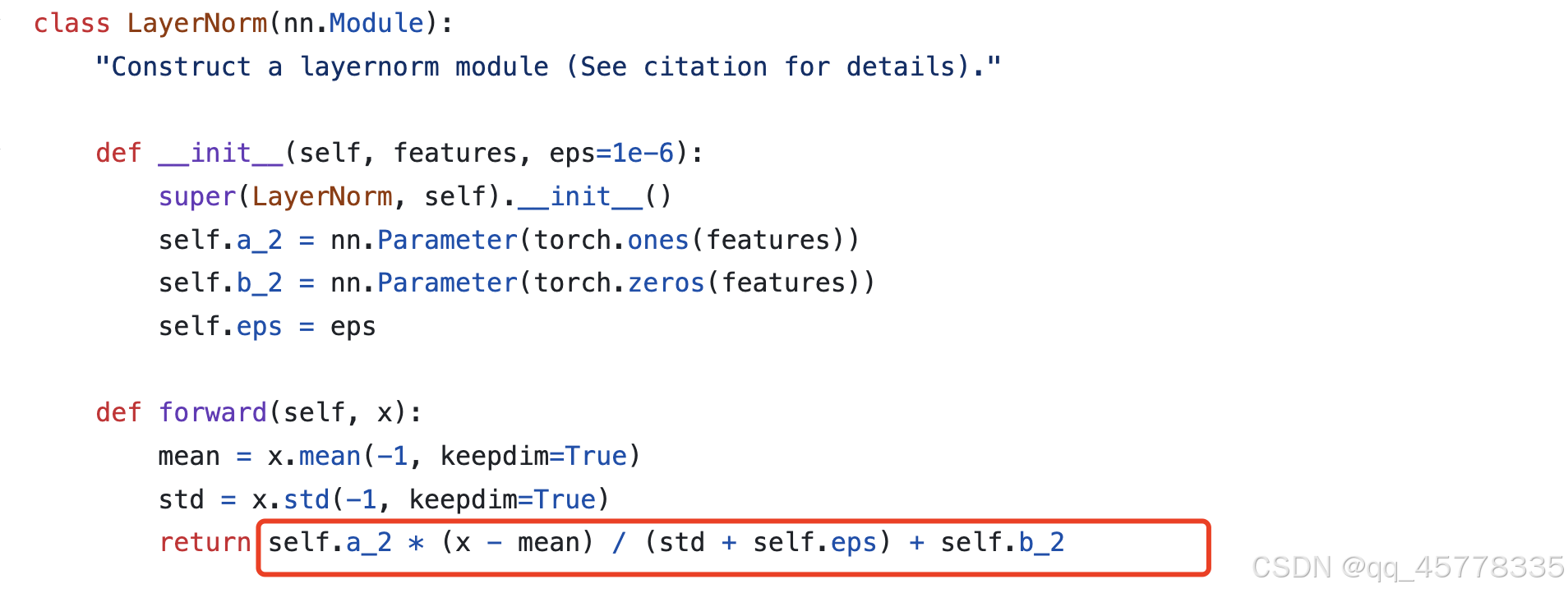
2. 将layernorm放在残差网络之外: transformer源码中layernorm在残差网络内部
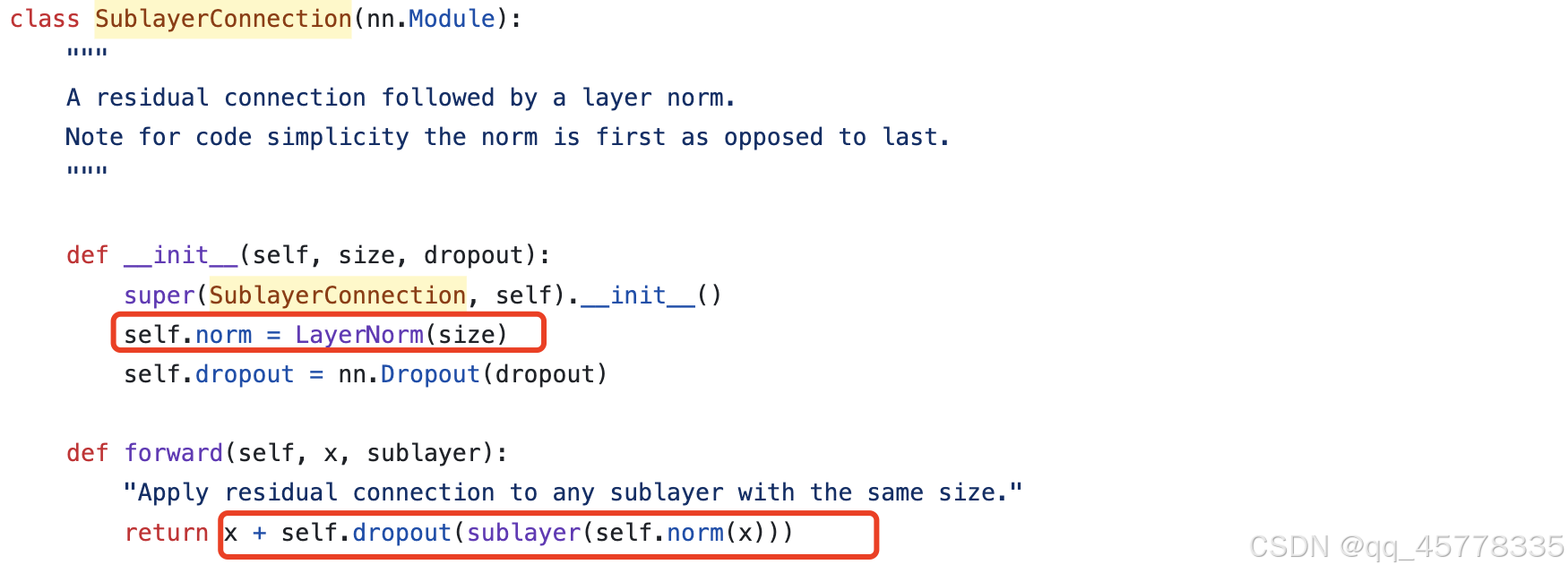
3. 使用不同的position embedding:分桶形式的可学习的相对位置编码,将位置嵌入直接加到KQ计算的注意力logits上,相对位置信息只在Encoder和Decoder的第一层Self-attention计算中起作用,并且所有head之间不共享;对比transformer使用正余弦绝对位置编码,将位置嵌入加到词嵌入上(BERT的位置嵌入是可学习的绝对位置编码)
预训练:
- 使用标准的最大似然目标函数来训练(teacher forcing【将当前时刻的真实标签作为下一个时间步的输入】自回归, cross-entropy loss ),预测时,采用gready decoding【贪婪解码,选择概率分布中概率最大的词作为当前的输出 token,循环直到遇到结束标记[EOS]】。
- 优化器AdaFactor,训练阶段在搜索的C4数据集(750GB)上,epoch 524,288。batch size 128, 最大序列长度512。
- 训练一共能见到约 ≈34B 个token,少于BERT和RoBERTa。这个训练轮数没有覆盖到所有C4数据集,也即没有一个样本会重复训练。
- 预训练目标:类似于 BERT 的 掩码预测任务,不过 T5 并不是直接使用 BERT 的 “掩码” 标记,而是引入了 哨兵标记 来指示模型需要预测哪些位置的词,连续的词只用一个哨兵表示,最终的输出形式是“哨兵+所预测的单词或短语+....+结尾哨兵词。
微调:利用在输入中添加prefix 前缀提示词来指示模型完成不同的学习任务。对每个下游任务训练 218 个step,输入最大长度为512,batch size为128,学习率为0.001,每5000个step计算验证集的分数,最后展示验证集上的最佳分数。
词表:采用WordPiece,大概有32000个token。由于部分下游任务有德文、法文和罗马尼亚文,所以把这些非英语的词也加进了词表。
实验具体流程:
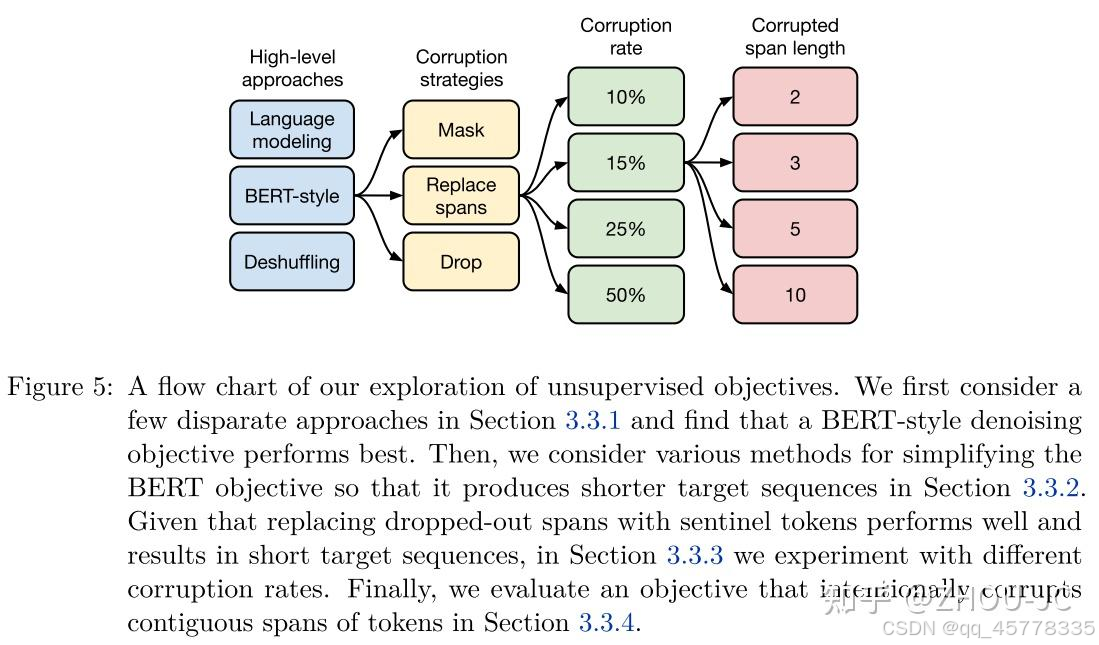
一些最终结果和可以参考的策略:
- Text-to-text:把所有NLP任务都转换成text-to-text范式,实验证明,跟传统的task-specific结构效果相差不大;
- Architectures:原生Transformer的encoder-decoder结构最好,虽然跟原生BERT只采用encoder相比,参数翻倍,但可以令编码层和解码层共享参数使参数减半,但计算变慢是无可避免的。
- Unsupervised objectives Overall:"denoising"预训练目标(即BERT-style)是最好的,还做了让连续的corrupted token span用一个哨兵token代替的策略,预测目标从预测原序列变成预测这些corrupted token,目的是让输入序列变短、预测目标序列变短,提高计算效率;
- Data sets: 虽然用任务领域相关的数据进行预训练效果最好,但会使得预训练模型的适用范围有限,此外,数据量不够大,会使得预训练模型过拟合,损害下游任务性能,所以还是推荐使用大的、丰富的数据集;
- Training strategies:fine-tuning时所有参数一起更新是最好的,但计算代价大;此外,text-to-text范式使得多任务预训练很简单,但怎么进行数据采样是个待解决的问题,多任务预训练再fine tuning能有效缓解这个问题,此外,性能和传统的unsupervised pre-training接fine tuning效果差不多。
- Scaling:使用更多的数据、训练更大的模型、模型融合都能提高性能;
- Pushing the limits:提出了在各个任务上取得SOTA的T5系列模型。
参考:
大模型/NLP/算法3——BERT和T5的区别?_bert t5-CSDN博客
Transformer T5 模型慢慢读_t5 transformer-CSDN博客
关于Baseline具体得到的过程可以参考以下链接:
NLP系列之预训练模型(五):谷歌T5,Text-To-Text范式统一NLP任务
BART (2020)
BART是基于标准transformer架构,提出的一种符合生成任务的预训练方法。
BART是一个encoder-decoder的结构,其encoder端的输入是加了噪音的序列,decoder端的输入是right-shifted的序列,decoder端的目标是原序列。模型设计的目的很明确,就是在利用encoder端的双向建模能力的同时,保留自回归的特性,以适用于生成任务。

可以认为是一个BERT+GPT的架构,重点在于BERT部分尝试了多种noise方式,可以单独使用也可以组合:
- Token Masking: 就是BERT的方法----随机将token替换成[MASK]
- Token Deletion: 随机删去token
- Text Infilling: (corrupted token span)随机将一段连续的token(称作span)替换成一个[MASK],span的长度服从 λ=3 的泊松分布。注意span长度为0就相当于插入一个[MASK]。
- Sentence Permutation: 将一个document的句子打乱
- Document Rotation: 从document序列中随机选择一个token,然后使得该token作为document的开头
BART在下游任务上的微调
Sequence Classification Task:取decoder最后一个token的hidden_states输入给一个线性分类器,由于decoder是right-shifted,需要在原序列后增加一个token,保证decoder最后一个token对应的输出包含原序列中每一个token的信息。
Token Classification Task:取decoder的输出final_hidden_states输入分类器,给每一个token分类
Machine Translation:具体的做法是将BART的encoder端的embedding层替换成randomly initialized encoder,新的encoder也可以用和预训练阶段不同的vocabulary。
- 第一步只更新randomly initialized encoder + BART positional embedding + BART的encoder第一层的self-attention 输入映射矩阵。
- 第二步更新全部参数,但是只训练很少的几轮。
文章的一些发现:
Left-to-Right Pretraining会提升生成任务的效果:和Masked Language Model(BERT)和Permuted Language Model(XLNet)相比,包含Left-to-Right预训练的模型在生成任务上表现更好。
BART在生成类任务上效果拔群,在discriminative任务(NLU)上和RoBERTa/XLNet效果持平。
DeBERTa(2021)
DeBERTa相对于Bert的改进点:参考Deberta代码详解-CSDN博客
- 解耦注意力
- EMD
- 虚拟对抗训练
DeBERTa v1,v2,v3的区别:
v2与v1相比是出了词汇表和模型size的更新,主要一个是在相对位置编码上应用了bucket,另一个是在注意力层中将位置投影矩阵与内容投影矩阵共享。
v3和v1,v2的差别较大,后续再讨论。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









