






二分类(Binary Classification)
例子: 一张图片作为输入,比如这只猫,如果识别这张图片为猫,则输出标签1作为结果;如果识别出不是猫,那么输出标签0作为结果。现在我们可以用字母 y 来表示输出的结果标签。


在二分类问题中,我们的目标就是得一个分类器,它以图片的特征向量作为输入,然后预测输出结果为1还是0,也就是预测图片中是否有猫。
符号定义:

逻辑回归(Logistic Regression)
逻辑回归学习算法,该算法适用于二分类问题。
1.逻辑回归的假设函数(Hypothesis Function)
逻辑回归中,预测值h^=P(y=1 | x)表示为1的概率,取值范围在[0,1]之间。
使用线性模型,引入参数w和b。权重w的维度是(nx,1),b是一个常数项。
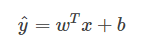
在logistic回归中,我们希望输出一个[0,1]间的概率值,所以将线性函数转换为非线性函数。 得到sigmoid函数 ,输出应该是等于由上面得到的线性函数式子作为自变量的sigmoid函数。
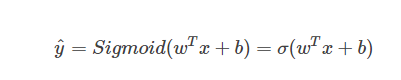
Sigmoid函数是一种非线性的S型函数,输出被限定在[0,1]之间,通常被用在神经网络中当作激活函数(Activation function)使用
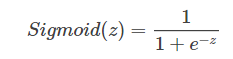
当z值很大时,函数值趋向于1;当z值很小时,函数值趋向于0。
sigmoid函数的一阶导数
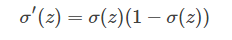

2.逻辑回归的损失(代价)函数(Cost Function)
为什么需要代价函数:为了训练逻辑回归模型的参数w和参数b,需要一个代价函数,通过训练代价函数来得到。
我们通过这个称为L的损失函数,来衡量预测输出值和实际值有多接近。
一般我们用预测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中我们不这么做,因为当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值,虽然平方差是一个不错的损失函数,但是我们在逻辑回归模型中会定义另外一个损失函数。
如下图所示
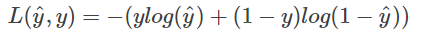
我们来分析一下这个Loss Function:
当y=1时,L(y^ ,y)=−log y^ 。如果想要损失函数L尽可能得小,那么就要y^ 尽可能大,因为sigmoid函数取值[0,1],所以会y^ 无限接近于1。
当y=0时,L(y^ ,y)=−log (1−y ^ )。如果想要损失函数L尽可能得小,那么就要y^ 尽可能小,因为sigmoid函数取值[0,1],所以会y^无限接近于0。
代价函数是对m个样本的损失函数求和然后除以m
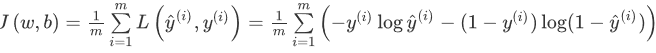
梯度下降法(Gradient Descent)
1.梯度下降法可以做什么
在你试集上,通过最小化代价函数(成本函数)J(w,b)来训练的参数w和b。
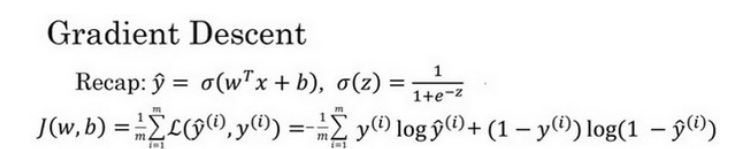
由于逻辑回归的代价函数J(w,b)(成本函数)特性,我们必须定义代价函数J(w,b)(成本函数)为凸函数。
初始化w和b。



朝最陡的下坡方向走一步,不断地迭代
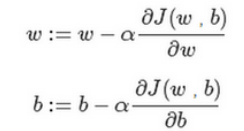
α是学习因子(learning rate),表示梯度下降的步进长度
2.逻辑回归中的梯度下降(Logistic Regression Gradient Descent)
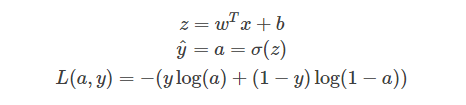
反向传播过程

然后再对a和z进行求导
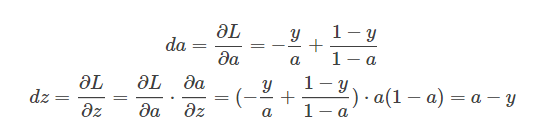
然后再w1,w2和b进行求导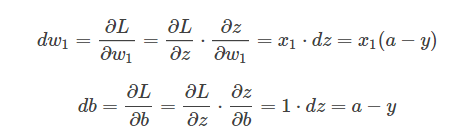
最后梯度下降发法得
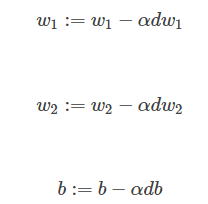
3.m 个样本的梯度下降(Gradient Descent on m Examples)
前面使用了一个训练样本(xi,yi)。 知道带有求和的全局代价函数,实际上是1到m项各个损失的平均。 所以它表明全局代价函数对的w1微分,对的w1微分也同样是各项损失对微分w1的平均。
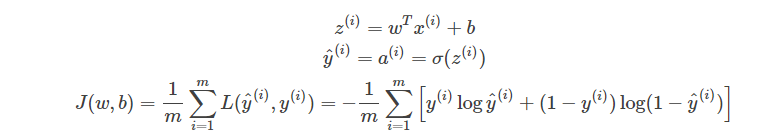
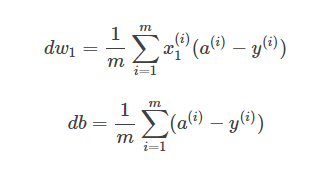
导数(Derivatives)
这个小结是关于一些导数的求解问题,比较简单。如果不懂的同学可以去看看高数书,里面都有很详细的讲解
计算图求导数(Derivatives with a Computation Graph)
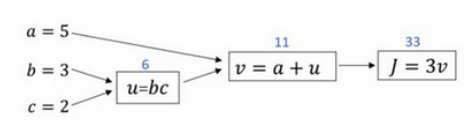
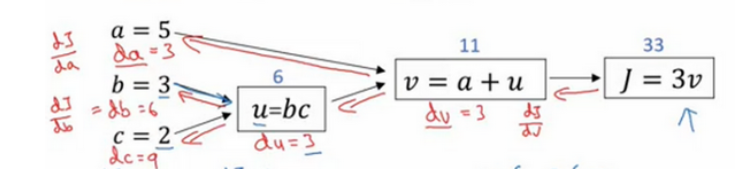
这是一个计算流程图,正向或者说从左到右的计算来计算成本函数J,可能需要优化的函数,然后反向从右到左计算导数。
这其实用到了链式求导法则,如果不懂的同学,可以多看看老师讲的,讲的很详细
向量化(Vectorization)
向量化是非常基础的去除代码中for循环的方法,这就需要用到矩阵,Python是可以直接进行矩阵计算的。在深度学习安全领域、深度学习实践中,会经常发现自己训练大数据集,因为深度学习算法处理大数据集效果很棒,所以在深度学习领域,运行向量化是一个关键的技巧。
例子
非向量化
for i in range(n_x):
z+=w[i]*x[i]向量化
z=np.dot(w,x)+b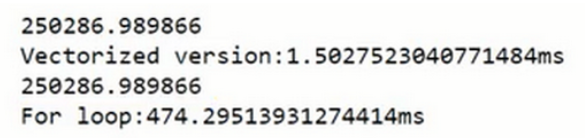
我们可以发现向量化版本花费了1.5毫秒,非向量化版本的for循环花费了大约几乎500毫秒,非向量化版本多花费了300倍时间。
1.向量化逻辑回归(Vectorizing Logistic Regression)
参数ω初始化:ω=np.random.rand((nx,1)),维度为(nx,1)
参数b初始化,b=0,numpy的广播机制将在计算时扩充b的维度为(nx,1)
训练集矩阵:X,大小为(nx,m)
训练集样本标签: Y,大小为(1,m)
m个样本的线性输出Z可以用矩阵表示
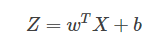
Z = np.dot(w.T,X) + b
A = sigmoid(Z)2.向量化 logistic 回归的梯度输出(Vectorizing Logistic Regression’s Gradient)
算法流程

Python 中的广播(Broadcasting in Python)
向量加上某个实数时,Python自动把这个实数扩展成一个 与原向量相同行数的行向量。所以这种情况下的操作似乎有点不可思议,它在Python中被称作广播(brosdcasting)

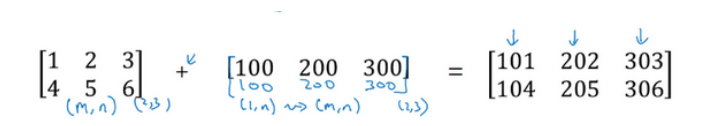
相当于是一个mn 的矩阵加上一个m1 的矩阵。在进行运算时,会先将 m1 矩阵水平复制n 次,变成一个mn 的矩阵,然后再执行逐元素加法。
如果两个数组的后缘维度的轴长度相符或其中一方的轴长度为1,则认为它们是广播兼容的。广播会在缺失维度和轴长度为1的维度上进行
解释:

















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









