






HDFS写数据流程(上传文件)
核心概念--Pipeline管道
HDFS在上传文件写数据过程中采用的一种传输方式。
线性传输:客户端将数据写入第一个数据节点,第一个数据节点保存数据之后再将快复制到第二个节点,第二节点复制给第三节点。
ACK应达响应:确认字符
在数据通信中,接受方发给发送方的一种传输类控制字符。表示发来的数据已经确认接受无误。
在HDFS Pipeline管道传输数据过程中,传输的反方向会进行ACK校验,确保数据传输安全。
默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefualt指定
第一块副本:优先客户端本地,否则随机
第二块副本:不同于第一块副本的不同机柜
第三块副本:第二块副本相同机架不同机器
流程
1.HDFS客户端创建实例对象DistributedFileSystem,该对象中封装了与HDFS文件系统操作的相关方法
2.调用DistributedFileSystem对象的Create()方法,通过RPC请求NameNode创建文件。NameNode执行各种检查判断:目标文件是否存在,父目录是否存在,客户端是否具有创建该文件的权限。检查通过,NameNode就会成为本次请求下一条记录,返回FSDataOutPutStream输入流对象给客户端用于写入数据。
3.客户端通过FSDateOutput输入流开始写入数据
4.客户端写入数据时,将数据分成一个个数据包默认64K,内部组件DataStream请求N阿门哦的挑选出合适的存储数据副本DataNode地址,默认是3副本存储。
5.传输的反方向上,会通过ACK机制校验数据数据包传输是否成功;
6.客户端完成写入后,在FSDDataOutPutStream输出流上调用close()方法关闭
7.DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。
MapReduce的核心思想(先分后合,分而治之)
1.Map表示第一个阶段,负责拆分“拆分”,即把复杂的任务分解成若干个“简单的子任务”来并行处理。可以进行拆分的前提是这些小任务可以进行并行计算,彼此间没有依赖关系。
2.reduce是第二阶段,负责合并:即对map阶段的结果进行全局汇总
3.这两个阶段合起来正是MapReduce的思想
Hadoop MapReduce 的设置构思
Map:对一组数据元素进行某种重复式的处理
Reduce:对Map的中间结果进行某种进一步的结果整理
分布式式计算是一种方法,和集中计算是相对的。
分布式计算是将应用分解成许多晓得部分,分配给多个多台计算机进行处理
MapReduce实例进程
一个完整的MapReduce程序在分布式运行时有三类
1.MRAppMaster:负责整个MR程序的过程调度及状态协调
2.MapTask:负责map阶段的整个数据;流程
3.ReduceTask:负责reduce阶段的整个数据处理流程
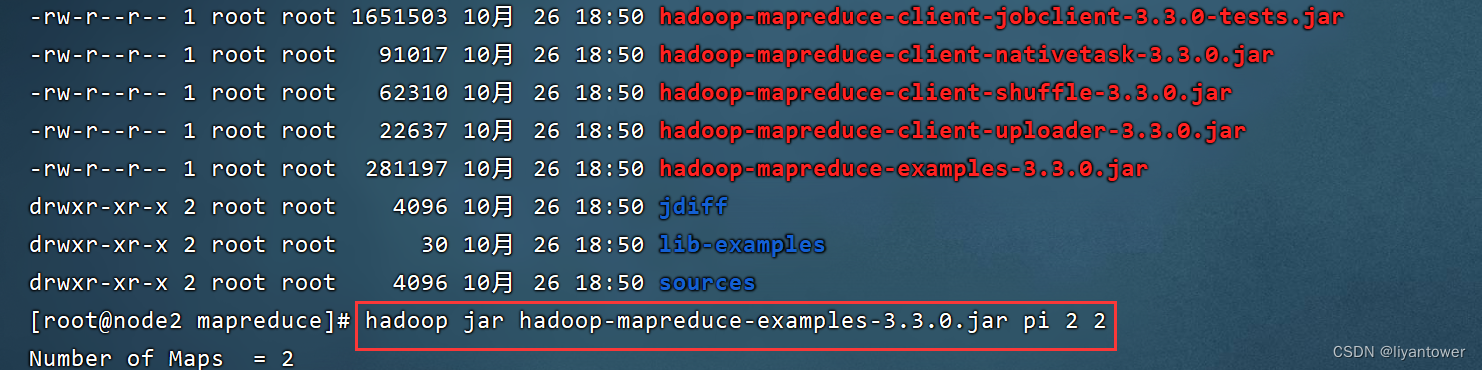
Hadoop MapReduce官方示例--圆周率PI评估
1.运行MapReduce程序评估一下圆周率的值,执行中可以去Yarn页面上观察程序的执行情况。
第一个参数:pi表示MapReduce执行圆周率计算任务
第二个参数:用于指定map阶段运行任务task次数,并发度,这里是0;
第三个参数:用于指定每个map任务取样的个数。这里是50。
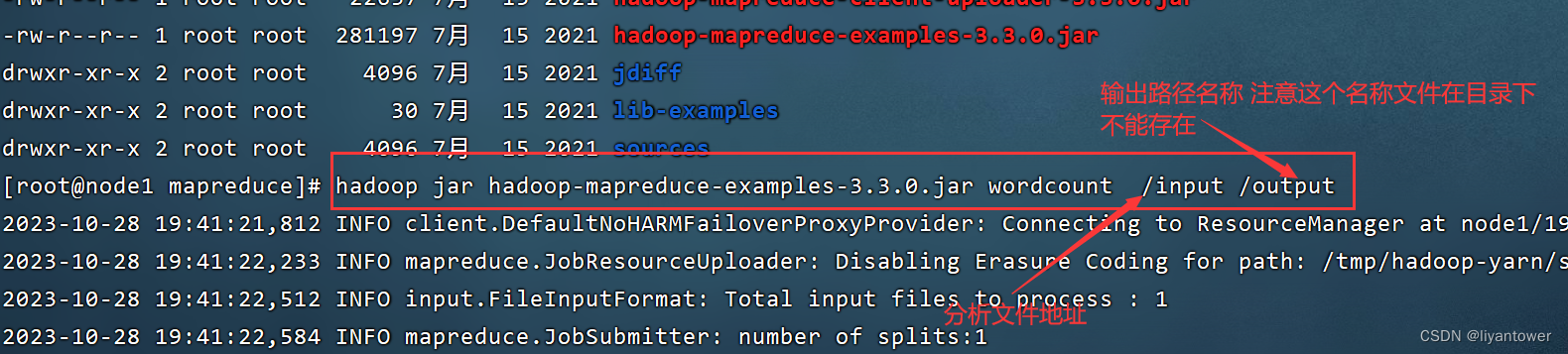
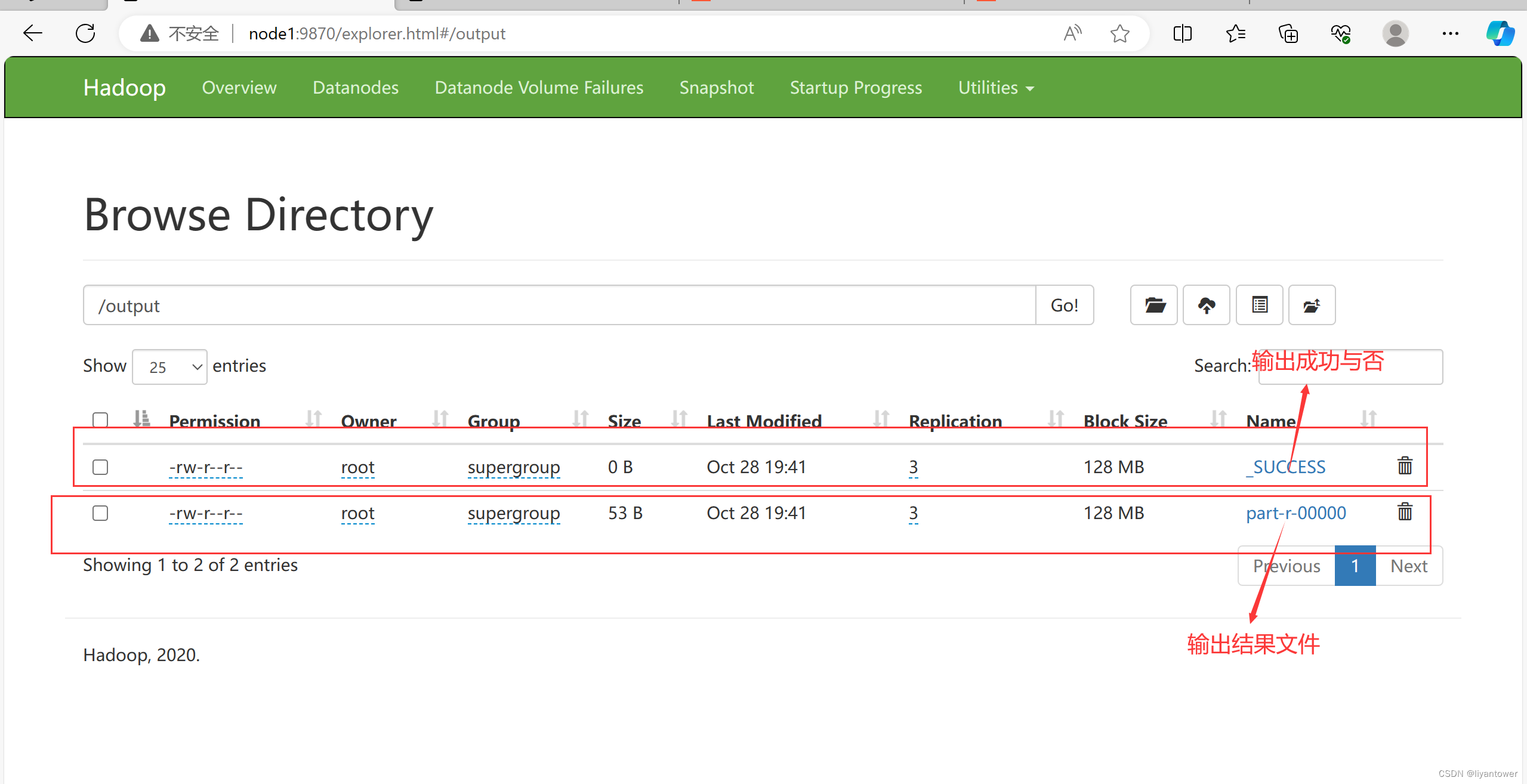
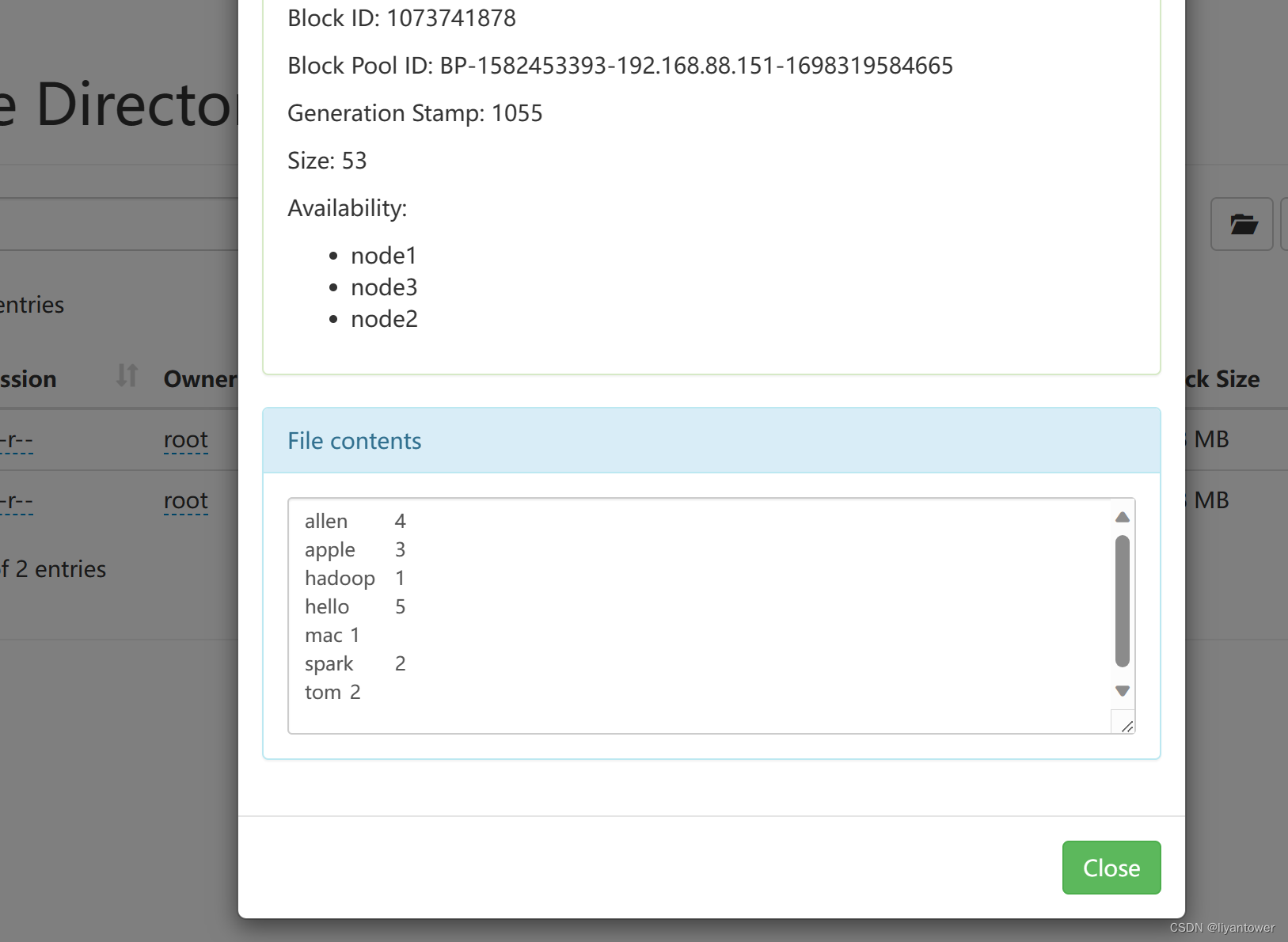
第二个实例wordcount单词词频统计
wordcount算是大数据计算领域经典的入门案列,相当于Helloworld
map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是单词《单词,1》
shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的kv对
reduce阶段核心:处理shuffle完的一组数据,该数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总词数。
map阶段执行过程
第一个阶段:把输入目录下文件按照一定的标准逐个逻辑切片,形成逻辑切片。默认是128MB,每一个切片由一个MapTask处理。
第二阶段:对切片中的数据按照一定的规则读取解析返回《key,Value》默认的是按行读取数据
第三阶段:调用Mapper中类中的map方法处理数据,调用一次map方法处理数据
第四个阶段:按照一定的规则对Map输出的键值进行分区parting。默认不分区,因为只有一个reducetask分区的数量就是reducetask运行的数量。
第五个阶段:Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候进行key进行排序sort
第六阶段:对所有溢出文件进行最终的merge合并,成为一个文件。
reduce阶段执行流程
第一阶段:reducetask会主动从MapTask复制拉取属于自己处理的数据
第二阶段:把拉取来的数据,全部进行合并merge,即把分散的数据合并成一个大的数据,在对合并后的数据进行拍讯
第三阶段:对排序后的键值对调用reduce方法,键排序的键值对调用一次的reduce方法。最后把这些输出的键值,写入到HDFS文件中。
Shuffle阶段执行流程
map产生的输出开始到Reduce取得的数据作为输入之前的过程称为shuffle
1.Mapshuffle:MapReduce任务中的Map输出进行分区、排序和合并。Mapshuffle将Map输出按照键进行划分,然后将每个键分配给某个Reducer任务处理。同时,Mapshuffle还可以对Map输出进行排序,可以按照键或值进行排序。排序可以使得Reducer任务更容易合并相同键的记录,减少网络传输和磁盘I/O开销。最终,Mapshuffle将分好组、排序好的Map输出传递给Reducer任务进行处理。
2.Reduceshuffle:Copy阶段-Merge阶段-Sort阶段
shuffle中频繁涉及到数据在内存、磁盘之间的多次往复。














 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









