







 本文介绍了一种新颖的图像编辑模型InstDiffEdit,它利用扩散模型中的即时注意力掩码生成,实现精确控制的语义编辑,无需额外训练或人工干预。实验结果表明,该方法在保持高质量生成的同时提高了计算效率和背景保持能力。
本文介绍了一种新颖的图像编辑模型InstDiffEdit,它利用扩散模型中的即时注意力掩码生成,实现精确控制的语义编辑,无需额外训练或人工干预。实验结果表明,该方法在保持高质量生成的同时提高了计算效率和背景保持能力。
本文发表于AAAI 2024,主要工作是有关于图像编辑
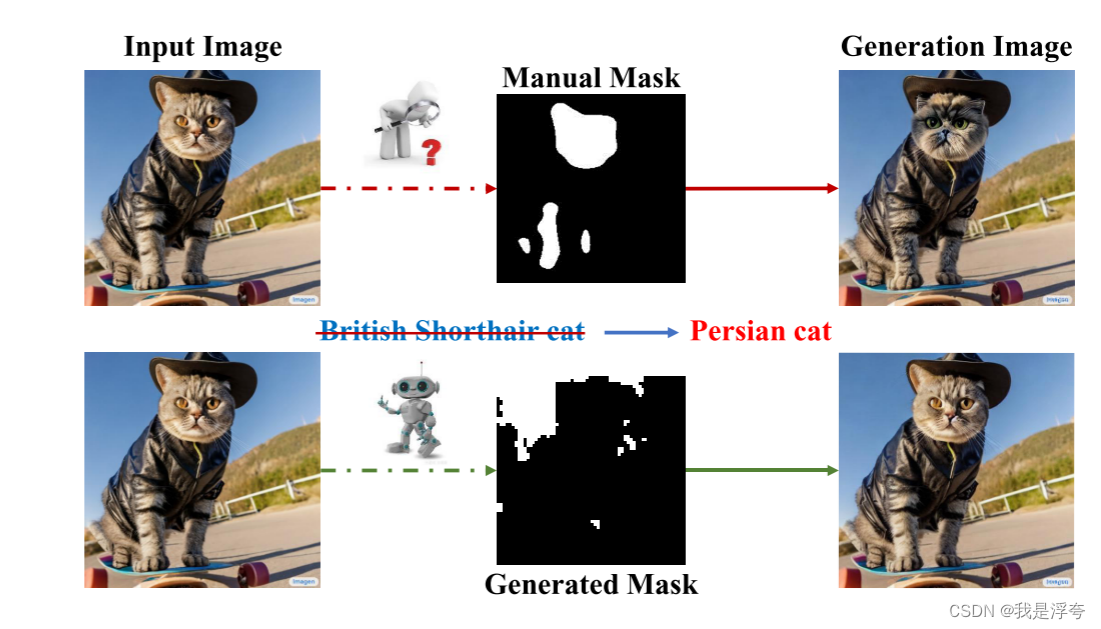
一、Introduction
目前在扩散模型应的语义图像编辑任务中,主要的想法在于根据文本描述修改图像目标实例而保留其余图像信息。虽然现有的扩散模型在生成质量和多样性方面表现出色,但缺乏精确控制。因此,基于扩散的编辑方法引入了额外信息来更好地控制图像操作,例如参考图像或语义掩码。最近的进展旨在自动化编辑过程,如通过半自动或全自动的掩模生成方法。本文提出了一种名为InstDiffEdit的新颖有效的扩散模型图像编辑方法,利用扩散模型中的跨模态注意力实现即时掩模生成。该方法无需额外训练或人工干预,能有效应用于大多数扩散模型进行语义图像编辑,性能达到当前最先进水平。同时,还提出了一个新的图像编辑基准Editing-Mask,用于评估掩模精度和局部编辑能力。实验结果表明,InstDiffEdit在计算效率和生成质量之间取得了最佳折衷,提高了推理速度,并在背景保持方面表现优越。
二、Related Work
在过去几年中,基于扩散的方法在图像生成领域受到广泛关注,相较于传统的生成对抗网络(GAN),这些方法在图像质量和多样性方面展现出更为出色的性能。除了稳定扩散等作品利用CLIP来引导图像生成外,也有一些研究探索了扩散模型与对比图像预训练(CLIP)的结合。在语义图像编辑方面,基于GAN的方法取得了重要进展,尤其是随着大规模GAN网络(例如StyleGAN)的发展,编辑能力得到了很大增强。另外,Transformer在文本驱动的图像编辑任务中也表现出色,例如ManiTrans使用Transformer来预测特定图像区域的内容,从而实现语义编辑。 随着扩散模型的发展,人们开始探索其在语义图像编辑中的应用。例如,一些方法通过保留部分参考图像信息或通过反演模型来提高编辑质量。此外,还有一些方法尝试修改扩散模型中的注意力地图来进行编辑,以提高编辑的准确性和效果。为了避免全局图像编辑带来的不便,一些方法开始使用局部编辑技术,例如混合扩散和RePaint利用手动蒙版实现对真实图像的局部编辑。然而,手动获取掩码是耗时且劳动密集的工作,阻碍了自动语义编辑的发展。因此,一些方法开始探索自动化掩模生成,以提高编辑的效率和质量。尽管这些方法在实现自动编辑方面取得了一定进展,但仍存在一些挑战,例如编辑时间的效率低下和精确度不足。
三、Preliminary
这部分主要讲了扩散模型的基本原理以及扩散模型中交叉注意力层的基本原理以及其作用。
四、Methodology
本文提出了一种新的和有效的图像编辑方法的基础上的文本到图像的扩散模型,称为即时扩散编辑(InstDiffEdit),其结构如图所示。

这是整个方法论的框架,正如文中所说一样,(a)是表示了整个图像编辑过程中的加噪过程,这部分主要是对原始的图像添加噪声,以及对输入的编辑文本提示处理成文本嵌入。
(b)这里就是即时注意力掩码生成的过程,它主要的想法就是利用到去噪时间步的第一个时间步的注意力图以及输入的文本嵌入来对注意力图进行一个改进,并且得到一个位置向量。这个位置向量会在后续的每个时间步对注意力图进行指导以改进注意力图并生成掩码。
(c)这部分就是利用即时掩码来指导图像去噪过程的步骤。
(d)最后这里它将最后得到的掩码输入到预训练的修复模型中,然后对图像进一步修复。
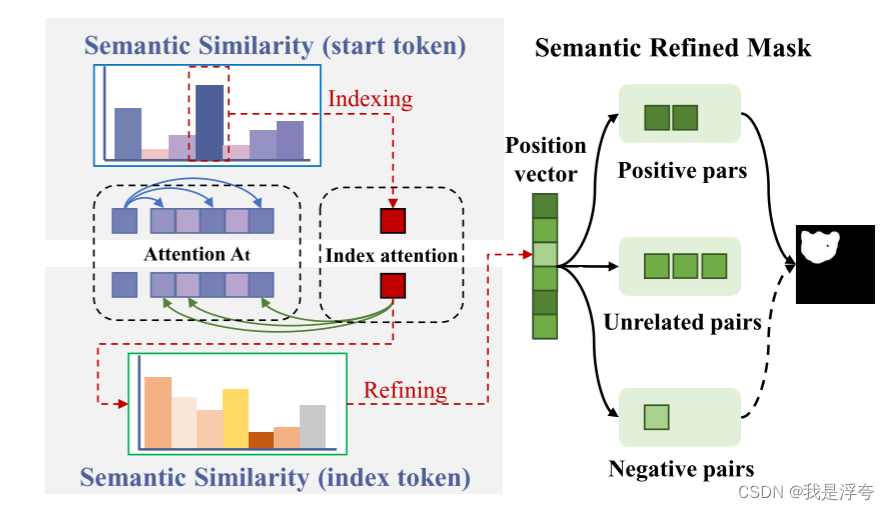
上图是即时掩码生成的主要原理图,我个人的理解是首先利用起始标记的注意力图作为基础信息,基于起始标记与其他标记之间的语义相似性进行索引处理。这一步骤通过计算起始标记与其他标记之间的语义相似性,建立索引关系(左上图),主要是通过计算注意力图与对应标记的余弦相似度实现。
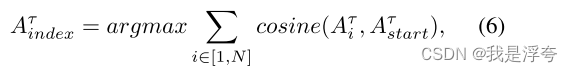
在索引处理后,对索引和其余标记之间进行细化处理。这一步骤通过进一步计算索引标记与其他标记之间的语义相似性(计算余弦相似度),对注意力图进行细化并得到位置向量。
![]()
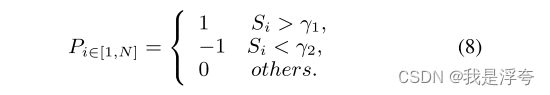
最后,我们得到了细化的注意力图,然后使用高斯滤波对其进行处理,并用阈值Φ进行二值化,以获得最终掩模Mt生成最终的掩码。
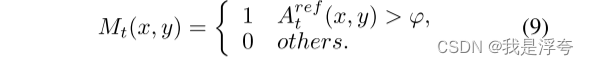
五、Experiments
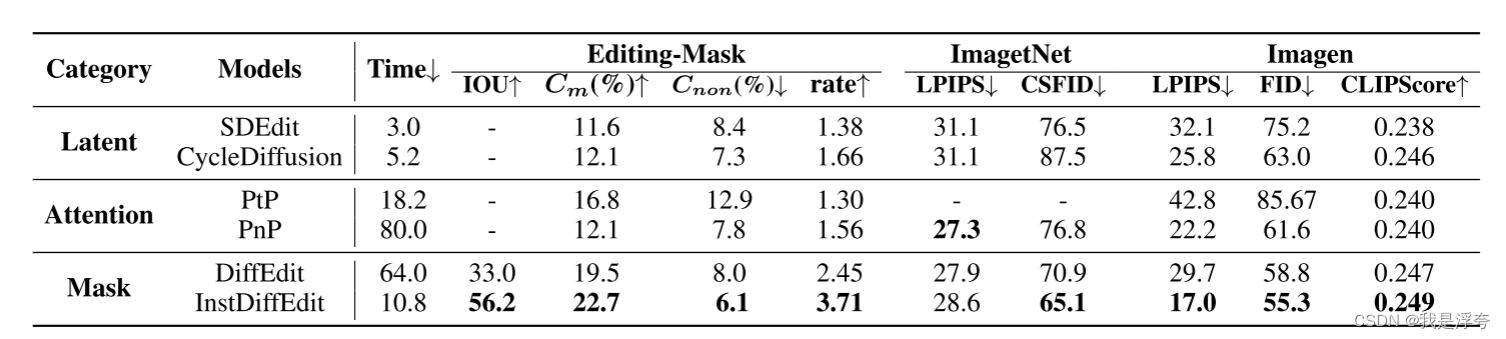
上表将论文所提出的方法与其他的方法在三个数据集上做了比较,所用的指标具体含义如下:
IOU: 表示预测的区域与真实区域之间的交集与并集之比,用于衡量生成的掩模与手动标记掩模之间的相似度,即掩模的准确性。
Cm: 表示掩模区域中像素变化的比率,用于衡量掩模区域的修改程度。
Cnon: 表示非掩模区域中像素变化的比率,用于衡量非掩模区域的修改程度。
rate :表示修改率,即掩模区域像素变化率与非掩模区域像素变化率的比值,用于综合评估图像编辑的效果。
LPIPS: 表示学习的感知图像块相似度,用于量化生成图像与原始图像之间的差异,反映编辑方法所做修改的程度。
CSFID: 另一种类别FID度量,用于衡量生成图像与原始图像之间的距离,特别是在类别匹配方面的表现。
FID: 用于衡量生成图像与原始图像之间的距离,反映生成图像的质量。
CLIPScore: 用于衡量编辑后的图像与相应编辑文本之间的语义相似性。

这三个图像主要是在指标之间进行了一个权衡,相较于其他的方法,本文提出的InstDiffEdit具有最佳的权衡。

上表主要是对编辑模板上噪声强度r和二值化阈值φ的消融研究 。

















 2288
2288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











