







文章目录
Chap11 Code generation
Introduction
本课程所设计的编译器为类Java的两层编译器,底层是在第7-8章开发的将Virtual Machine语言编译为assembly code
代码的VM编译器,第二层则是基于底层开发的将high-level language编译为Virtual Machine的高级语言编译器。
其中高级语言编译器可以按照功能划分为两个部分:syntax analyzer和code generation,本章讲解code generation。
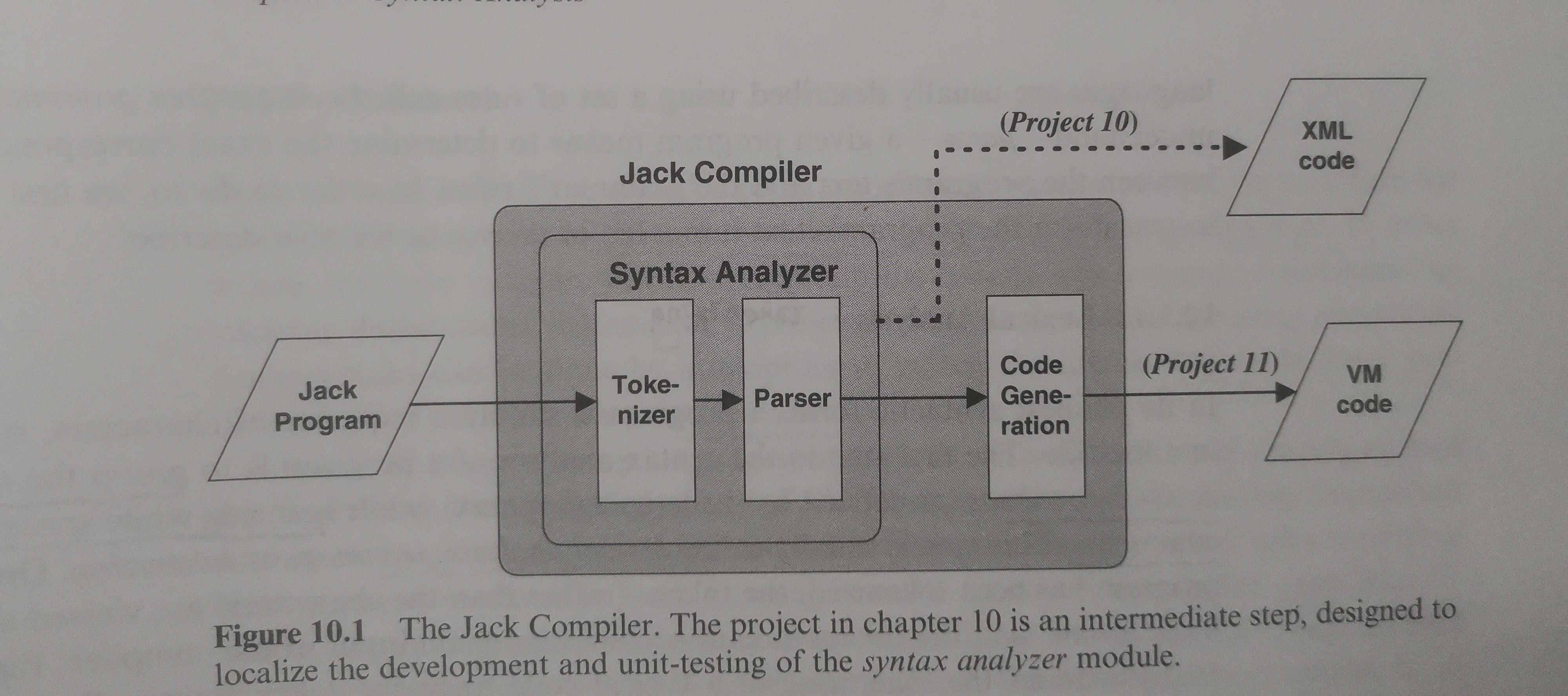
现代的高级语言通常抽象程度比较高,语法丰富,允许用户定义和使用多种类型的变量与数据结构来进行逻辑操作,还可以通过精妙的算法和优雅的控制系统搭建复杂的程序。但是,相对的,位于计算机底层的机器语言或汇编语言所能直接提供给用户的操作指令就比较精简,对于精确到每一个寄存器的数据操作都需要程序员的去考虑。
直接从高级语言到汇编语言这样的低级语言进行编译是一项十分繁重的任务。本课程利用VM的机制,在两个之间构造了一个标准的、以栈结构为操作基础的虚拟平台。这样,仅仅实现从高级语言到VM语言的编译工作会变得轻松很多,也获得了更好的可移植性。
11.1 Background
一个程序通常是一串操作和数据处理的集合,因此编译工作也将重心放在两部分:
- data translation
- command translation
11.1.1 Data Translation
程序通常会关心每个变量的name, type, life cycle 和scope,我们通过维护一个symbol table来实现对变量上述属性的处理。
Symbol Table
高级语言会创造和使用各种identifier,当编译器遇到一个identifier时,需要主动解析它的类型(类名?变量名?函数名?),如果是变量名,还需要知道是属于哪一种变量。编译器通过维护一个Symbol Table解决这个问题,在处理一个identifier之前,首先要明确他的各种属性,才能进行语法和语义上的处理。

对于允许用户在不同的函数中明明相同名字的变量的语言,每个变量还必须隐性的附带一个scope属性,通常是层叠的。对于遇到的identifier,编译器会嵌套的由内到外查询它的定义属性。这样的数据结构通常是一个个hash table,允许编译器由内到外查询变量。
Handing Variables
编译器需要处理的一个比较大的挑战是如何将源程序中的各种类型的变量映射到目标平台的内存中。
- 每个变量需要的内存大小不同;
- 每个变量所拥有的生命周期不同,要处理它何时可用,何时被释放
好消息是,在VM层的编译中,我们已经处理好了变量的内存分配与释放,并且对于高级语言中使用到的static, local, argument和属于对象的fields变量都已经进行了预先的处理。剩下的工作就是将高级语言源代码中的数据类型映射至VM中的各种数据段,再将各种数据操作和指令映射至VM中的指令。
Handing Arrays
数组通常被存储再一段连续的内存中,数组名作为指针指向第一个数据的地址。典型的语言像Pascal在数组声明时就固定分配好内存空间。Java则仅仅创建一个可以指向某一内存空间的指针,这种dynamic memory allocation通过heap结构实现,使用操作系统提供的服务(alloc(size))进行调配。

接下来讨论编译器如何处理bar[k]=19这样的语句。需要使用间接寻址机制,也即是不仅可以直接将数据存储在内存地址y,还可以将数据存储在以地址y中的内容为地址的内存中。下图展示了VM中实现该机制的两种方式:

Handing Objects
某个类的对象实例通常包含各种封装数据和一些类内方法。
- 数据
对于某些OO编程语言,当声明类内变量时只会分配一个指针变量。只有当通过该类的构造函数实例化对象时,才会分配具体的内存。
所以,当编译某个类xxx的构造函数时,编译器通过私有变量的数量和类型计算出表示该类一个实例化对象需要的内存大小n。然后,生成代码为刚刚实例化的对象分配内存this = alloc(n),这一操作将this指针指向表示该对象的内存基地址。下图展示在Java中如何实现类似操作:

既然一个对象通过指向该对象内存地址的指针来表示,也就是说对象内封装好的变量数据可以通过该指针线性获取(基地址偏移)。 - 类内方法
需要注意的是,每一个实例化的对象都会有一份新的封装变量数据存储在不同的内存地址,但是该类封装的方法不会进行复制,对于所有该类的实例化有且仅有一份函数代码。比较好的解决方法是,将对某一对象的引用地址(refference)作为隐形参数传递给需要调用的方法(b.mult(5)可以处理为mult(b, 5))。对于本课程使用的VM语言,每一个基于对象的方法call foo.bar(v1, v2, ...)实现为push foo, push v1, push v2, ..., vall bar。抽象到高级语言可以视为对每一个对象分别封装了一份类内方法。
除此以外,某些语言支持在不同的类中声明名字相同的方法,编译器必须确保正确的方法作用于正确的对象。并且,由于存在子类中方法重载的可能性,OO语言的编译器必须在运行中实时进行决定。本课程讨论的Jack语言允许编译器在编译时进行该决定。指定类似x.m(y)的方法调用,确保方法m属于派生对象x的类。
11.1.2 Commands Translation
Evaluating Expression
进行表达式赋值首先需要“理解”该表达式,我们已经在上一张的Analyzer中将每个表达式解析为如下图的解析树:
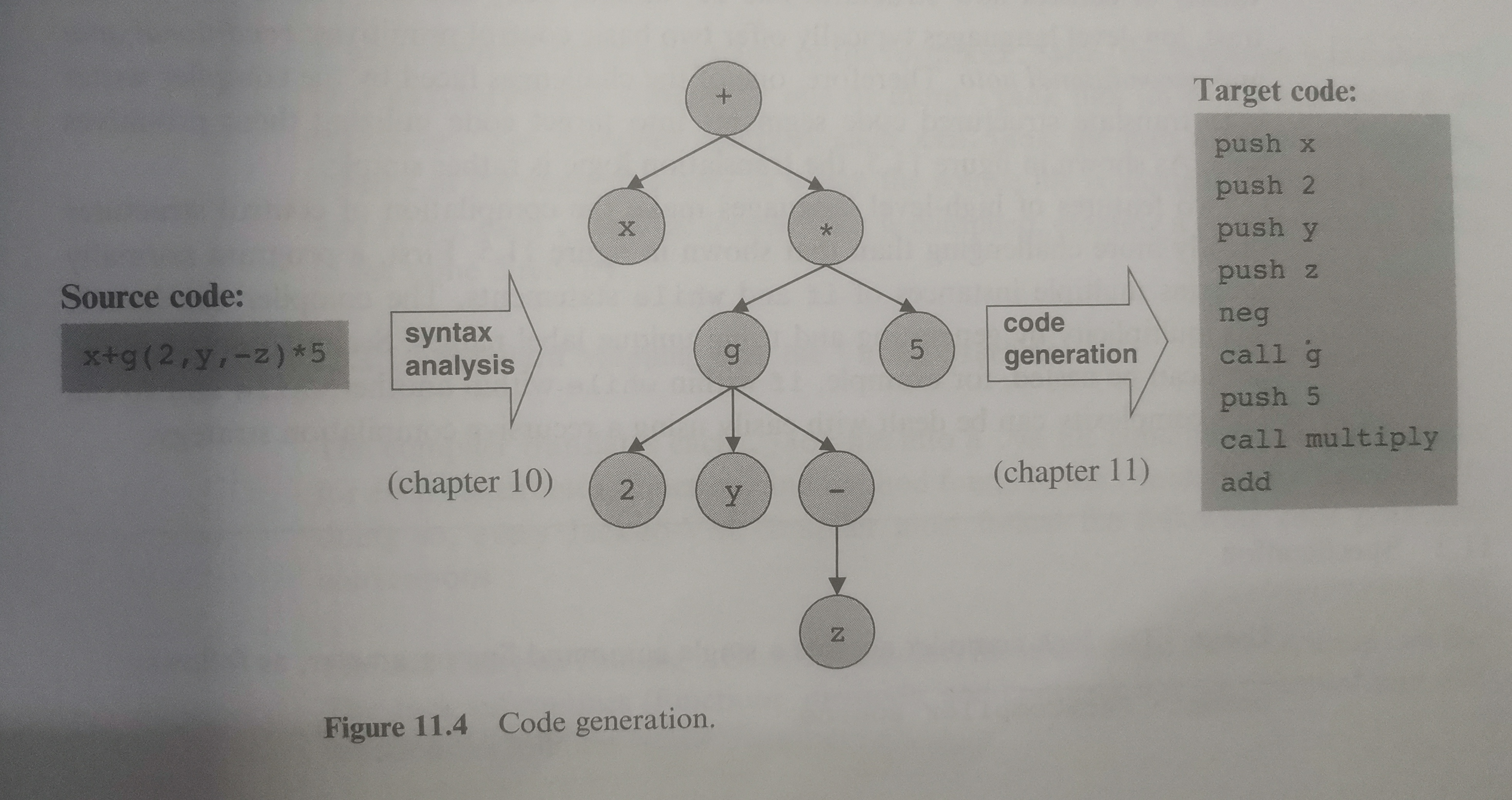
相应的代码生成算法取决于编译的目标代码,我们编译的目标是基于栈结构的VM代码,可以通过后序遍历(postfix)实现解析与代码生成,也被称为Reverse Polish notation(逆波兰式)。我们可以对解析树进行递归的后序遍历直接将解析式编译为对应的stack-basedVM代码。

Translating Flow Control
高级语言中有各种程序控制结构,诸如if, while, for, switch等等,相反的,在大多数低级语言中只提供conditional goto和unconditional goto两种控制指令。编译器的工作就利用低级语言提供的基本指令实现高级语言的各种程序结构。如下图:

值得注意的是,高级语言所特有的一些性质会使得上述工作更加困难:
- 一个程序通常会使用多个
if,while等实例,编译器可以通过添加特殊字符对每个实例进行区分; - 程序中还会出现嵌套的
if,while情况,建议使用递归编译策略。
11.2 Specification
目标编译器程序将输入的每一个xxx.jack代码文件编译为xxx.vm代码文件。
11.2.1 Standard Mapping over the Virtual Machine
编译器将.jack中的每个一构造函数、函数、方法编译为一个.vm函数,注意遵守以下准则。
File and Function Naming
每个.jack文件包含一个单独的.jack类,并且被编译为一个单独的.vm文件:
- 类
yyy中的子进程xxx()编译为VM函数yyy.xxx - 一个带有n个参数的Jack函数、构造函数编译为同样带有n个参数的VM函数
- 一个带有n个参数的Jack类内方法编译为带有n+1个参数的VM函数,第一个参数为指针
this,指向该对象
Memory Allocation and Access
- Jack中的
local,argument变量分别对应VM语言中的local,argument内存段 - Jack中的
static变量对应该源代码文件的static内存段 - 一个对应着Jack中构造函数或方法的VM函数,获取这个对象的
field要首先指向虚拟this内存段(使用指针0),之后通过this index获取每一个单独的field。 - 在一个VM函数内部,想要获取到数组数据首先要将虚拟
that内存段指向数组基地址(使用指针1),然后通过该引用获取数组数据
Subroutine Calling
- 调用VM函数之前,调用者首先需要将传递的参数入栈。如果调用的VM函数对应Jack中的类内方法,那么传递的第一个参数应该指向该方法操作的对象的指针
- 当编译Jack中的类内方法称为VM函数时,编译器应该首先插入相关VM代码以将内存段
this进行设置。例如,编译一个Jack中的构造函数时,首先要为构造的对象分配相应的内存,然后将内存段this的基地址指向分配的内存块地址
Returning from Void Methods and Functions
高级语言的空返回函数不返回数值,遵循以下规则:
- 高级语言中的
void函数和方法对应的VM函数应该返回数值0 - 当编译类似
do sub结构的代码时,并且sub是一个空函数或方法,该调用者应该pop掉返回值,不做任何处理
Constants
null,false映射为数值0,true映射为数值-1(push 1,neg)
Use of Operating System Services
基础的Jack OS实现是通过一系列的VM文件(Math.vm, Array.vm, Output.vm, Screen.vm, Keyboard.vm, Memory.vm, Sys.vm),所有这些文件必须和编译器编译好的文件放在一起。这样,所有的VM文件都可以调用系统服务。特别的,当需要的时候,编译器可以调用一下系统函数:
Multiplication,division在文件Math.multiply(),Math.divide()中- 字符串变量新建可以通过调用系统构造函数
String.new(length)。字符串赋值可以通过连续调用系统进程String.appendChar(nextChar) - 构造函数为新对象分配空间可以调用
Memory.alloc(size)
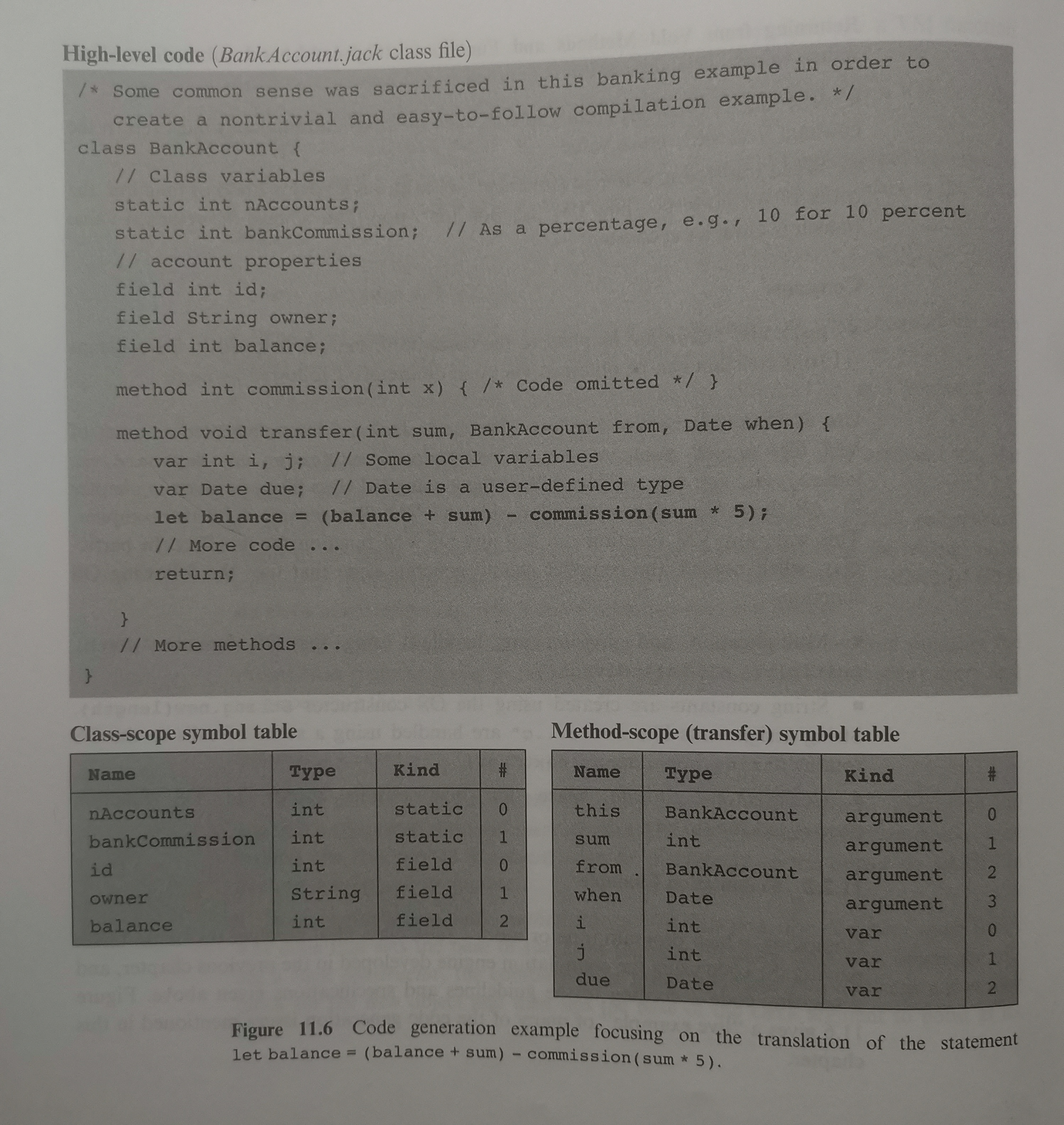
11.2.2 Compilation Example
关于编译实现的细节补充:

Implementation-Compiler.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Description:
compile .jack code into .vm code with 2 stages:
.jack --> .xml
.xml --> .vm
Recommended OS:
Linux
"""
__author__ = 'eric'
import getopt
import os
import sys
from Analyzer import syntax_analyzer
from Code_generation import CompilationEngineToVM
# ----------------------------------------------------------
# Description:
# receive command parameters --> validating input path --> processing each .jack file
def main():
input_path, PROC_MODE = recv_opt_arg(sys.argv)
if os.path.isdir(input_path): # path is a directory
input_path = os.path.abspath(input_path) + '/' # make sure that the last character in input_path is '/'
files = os.listdir(input_path)
for each_file in files:
if each_file[-5:] == '.jack': # only deal with file that end with '.jack'
no_postfix_path = input_path + each_file[0:-5] # full path of .jack file without .jack postfix
# print('in_file_path\t', no_postfix_path + '.jack')
# print('out_file_path\t', no_postfix_path + PROC_MODE)
process_file(no_postfix_path + '.jack', no_postfix_path, PROC_MODE)
elif os.path.isfile(input_path): # path is a file
input_path = os.path.abspath(input_path)
if input_path[-5:] == '.jack': # only deal with file that end with '.jack'
no_postfix_path = input_path[0:-5]
# print('in_file_path\t', input_path)
# print('out_file_path\t', no_postfix_path + PROC_MODE)
process_file(input_path, no_postfix_path, PROC_MODE)
else:
print('[Error]:\tError_invalid_input_path: ' + input_path)
exit(0)
else: # path is neither directory nor file
print('[Error]:\tError_invalid_input_path: ' + input_path)
exit(0)
return
# ----------------------------------------------------------
# Description:
# receive command line input. return input_path or print usage
# Output:
# input_path, proc_mode
def recv_opt_arg(argv):
# print('sys.argv=| ', argv, ' |')
try:
opts, args = getopt.gnu_getopt(argv[1:], 'i:m:h?', ['input_path=', 'proc_mode=', 'help'])
# 'opts' is a list of tuple ('option', 'value'), each option can only be given one value
# 'args' is a list of string containing extra arguments that are not included in list opts
# print('opts=| ', opts, ' |')
# print('args=| ', args, ' |')
except getopt.GetoptError as e: # error control
print(e)
print_usage(argv[0])
sys.exit()
input_path = '' # default input_path is none
proc_mode = '.vm' # default processing mode
for opt, value in opts: # ('option', 'value'), tuple
if opt in ['-h', '-?', '--help']: # print help information
print_usage(argv[0])
exit(0)
elif opt in ['-i', '--input_path']: # input_path
input_path = value
elif opt in ['-m', '--proc_mode']:
if value == 'Txml':
proc_mode = 'T.xml'
elif value == 'xml':
proc_mode = '.xml'
elif value == 'vm':
proc_mode = '.vm'
else:
print('[Log]:\tError_invalid_processing_mode: ' + value)
print_usage(argv[0])
exit(0)
if input_path == '': # if no input_path is specified, print usage
print('[Log]:\tError_no_input_path')
print_usage(argv[0])
exit(0)
return input_path, proc_mode
# ----------------------------------------------------------
# Description:
# print usage information of this script
def print_usage(cmd):
print(('*********************************************************\n' +
' --* This massage gave you some detailed information! *--\n' +
'Usage: {0} [OPTION]... [PATH]...\n' +
'- OPTION:\n' +
' {0} -i | --input_path\tinput path, if not specified, print usage\n' +
' {0} -m | --proc_mode\tspecify the process mode(default in .vm mode)\n' +
'- Acceptable proc_mode:\t\t\tTxml | xml | vm\n' +
' {0} -h | -? | --help\tprint help info and exit script\n' +
'- PATH:\n' +
' Provides name of the file you want to precess or directory that contain those files\n' +
' --* *-- \n' +
'*********************************************************\n').format(cmd))
# ----------------------------------------------------------
# Description:
# Main function for compiling .jack code into .vm code, two stages
# 1.code_analyzer:
# (1) tokenize
# (2) compilation_engine
# 2.code_generation
# (1) CompilationEngineToVM
# (2) SymbolTable
# (3) VMWriter
# Input:
# in_file_path, out_file_path, out_mode
def process_file(in_file_path, no_postfix_path, out_mode):
print('[Log]:\t--* JackCompiler:\t' + in_file_path)
print('[Log]:\t--* Processing mode:\t' + out_mode)
with open(in_file_path, 'r') as f: # import original jack_file into a list
jack_list = f.readlines()
# 1.code_analyzer
# list of str, each element is one line of (T.xml|.xml) file
# if out_mode is .vm, then return only tokenized_list
analyzed_list = syntax_analyzer(jack_list, out_mode)
# write output file
if out_mode in ['T.xml', '.xml']:
write_out_file(no_postfix_path + out_mode, analyzed_list)
print('[Log]:\tanalyzed_list, Length:\t\t' + str(len(analyzed_list)))
elif out_mode == '.vm':
# 2.code_generation
# receive analyzed_list and generate .vm code
compilation_engine_to_vm = CompilationEngineToVM(analyzed_list)
vm_list = compilation_engine_to_vm.get_vm_list() # list of str, each element is one line of .vm file
print('[Log]:\tvm_list, Length:\t\t' + str(len(vm_list)))
write_out_file(no_postfix_path + out_mode, vm_list)
# ----------------------------------------------------------
# Description:
# writing out_list into file named out_file_path
# Input:
# out_file_path, out_list
def write_out_file(out_file_path, out_list):
with open(out_file_path, 'w') as f:
for line in out_list:
f.write(line + '\n')
if __name__ == '__main__':
main()
Implementation-Analyzer.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Description:
tokenize .Jack file
Module:
Tokenizer, CompilationEngineToXml
Recommended OS:
Linux
"""
__author__ = 'eric'
import re
# ----------------------------------------------------------
# Description: receive jack list(list of str-line of .jack code)
# (1) remove comments & tokenize jack code - Tokenizer(class)
# (2) parse jack code according to .jack grammar - CompilationEngineToXml(class)
# Input: jack_list, out_mode
# Output: analyzed_list ('T.xml' or '.xml' mode), tokenized_list('.vm' mode)
def syntax_analyzer(jack_list, out_mode):
analyzed_list = []
jack_tokenizer = Tokenizer(jack_list) # instantiate Tokenizer with parameter jack_list
tokenized_list = jack_tokenizer.get_tokenized_list()
# print('tokenized jack_file:\tLine:', len(tokenized_list), '\n', tokenized_list)
if out_mode == 'T.xml': # build list of 'T.xml' file using only tokenized_list
analyzed_list.append('<tokens>')
for each_token in tokenized_list:
if each_token[0] == '<':
analyzed_list.append('<symbol> < </symbol>')
elif each_token[0] == '>':
analyzed_list.append('<symbol> > </symbol>')
elif each_token[0] == '&':
analyzed_list.append('<symbol> & </symbol>')
else:
analyzed_list.append('<' + each_token[1] + '> ' + each_token[0] + ' </' + each_token[1] + '>')
analyzed_list.append('</tokens>')
elif out_mode == '.xml': # build '.xml' file upon parsed_list, which is created using tokenized_list
# instantiate CompilationEngineToXml with tokenized_list
compile_engine = CompilationEngineToXml(tokenized_list)
# parsed_list is list of str, each str is a line of final xml file
parsed_list = compile_engine.get_parsed_list()
# print('parsed list:\tLine:', len(parsed_list), '\n', parsed_list)
# fixed display bug('<' '>' '&') in xml format
num_flag = 0
for each_str in parsed_list:
if ' < ' in each_str:
parsed_list[num_flag] = parsed_list[num_flag].replace(' < ', ' < ')
elif ' > ' in each_str:
parsed_list[num_flag] = parsed_list[num_flag].replace(' > ', ' > ')
elif ' & ' in each_str:
parsed_list[num_flag] = parsed_list[num_flag].replace(' & ', ' & ')
num_flag = num_flag + 1
analyzed_list = analyzed_list + parsed_list
elif out_mode == '.vm': # if out_mode is .vm, then return only tokenized_list
analyzed_list = tokenized_list
return analyzed_list
# ----------------------------------------------------------
# Class Description:
# Instantiate: Tokenizer(jack_list)
class Tokenizer(object):
def __init__(self, jack_list):
self.jack_list = jack_list
self.no_comment_list = [] # list of str, each element is a line of .jack code
self.tokenized_list = [] # tokenized_list is a list of tuple[('token', 'token_type')]
# main tokenizer process
self.remove_comment() # 第一种类内函数调用方法:使用self实例自带的方法
self.jack_tokenizer()
def get_no_comment_list(self):
return self.no_comment_list
def get_tokenized_list(self):
return self.tokenized_list
# ----------------------------------------------------------
# Description: remove white space and comments
# Input: jack_list
# Output: no_comment_list
def remove_comment(self):
multi_l_comm_status = 0
for line in self.jack_list:
line = line.strip() # remove white space in both left and right side
if multi_l_comm_status: # being in multi-line comment
if line[-2:] == '*/':
multi_l_comm_status = 0
continue
elif len(line) == 0: # empty line
continue
elif (line[0:2] == '//') or ((line[0:2] == '/*') and (line[-2:] == '*/')): # single line comment
continue
elif line[0:3] == '/**': # start a multi line comment
multi_l_comm_status = 1
continue
elif '//' in line: # in line comment
line = self.proc_inline_comm(line, r'//')
elif '/*' in line: # in line comment
line = self.proc_inline_comm(line, r'/\*') # r'/\*'作为regex使用,必须使用'\*'转义字符
line = line.strip() # remove white space in both left and right side
self.no_comment_list.append(line)
# ----------------------------------------------------------
# Description: processing and eliminate in-line comment, 可能同时存在字符串和注释,重点处理注释符号出现在字符串中间的情况
# Input: line(str), symbol
# Output: line without comment(str)
# 当我们需要某些功能而不是对象,而需要完整的类时,我们可以使方法静态化,它们通常与对象生命周期无关
@staticmethod # 声明静态方法,不需要传递self变量。
def proc_inline_comm(line, symbol):
if '"' in line: # 该行包含str,需判断注释部分是否属于str内容
symbol_index = index_all(line, symbol) # get all index of symbol in line
for per_index in symbol_index: # 从第一个symbol开始,如果该symbol左边有偶数个引号,代表有完整的str,该symbol为注释
if (line.count('"', 0, per_index) % 2) == 0: # str.count(sub, start= 0,end=len(string))
line = line[0:per_index]
else: # 不含str,直接找到第一个注释符号,移除后面的内容
line = line[0:line.index(symbol)]
return line
# ----------------------------------------------------------
# Description: tokenize input jack_list, separate each token and marked it up, compose a tuple[('token', 'token_type')]
# Input: no_comment_list
# Output: tokenized_list
def jack_tokenizer(self):
for line in self.no_comment_list: # line is a string
if '"' in line: # .jack code contains str, separate with white_space firstly
split_with_quote = line.split('"') # split with ",double quote
# str中的字符串应当作为一个整体加入token_list,不能简单用空格分开
num_flag = False
for each_split in split_with_quote:
if not num_flag:
self.tokenized_list = self.tokenized_list + self.split_str(each_split)
else: # string constant
self.tokenized_list.append((each_split, 'stringConstant'))
num_flag = not num_flag
else: # line中不含str,直接进行分隔程序
self.tokenized_list = self.tokenized_list + self.split_str(line)
# ----------------------------------------------------------
# Description: split one str of jack code into tokens and marked it up, compose a tuple[('token', 'token_type')]
# Input: line(string)
# Output: split_token_list, each element is a tuple[('token', 'token_type')]
def split_str(self, line):
split_list = []
keyword_jack = ['class', 'constructor', 'function', 'method', 'field', 'static', 'var', 'int', 'char',
'boolean',
'void', 'true', 'false', 'null', 'this', 'let', 'do', 'if', 'else', 'while', 'return']
symbol_jack = ['++', '<=', '>=', '==', '{', '}', '(', ')', '[', ']', '.', ',', ';', '+', '-', '*', '/',
'&', '|', '<', '>', '=', '~'] # 注意顺序(例:'++'应该在'+'前面)
split_with_space = line.split(' ')
for each in split_with_space: # each is a string with no white space inside
# print('[Log]:\tProcessing each = ' + each)
if len(each) == 0:
continue
elif each.isalpha(): # alpha
if each in keyword_jack: # alpha --> keyword
split_list.append((each, 'keyword'))
else: # alpha --> identifier
split_list.append((each, 'identifier'))
elif each.isdigit(): # digit
split_list.append((each, 'integerConstant'))
elif each.isalnum(): # mixed alpha and digit
if each[0].isdigit():
print('[Warning]:\tidentifier can\'t starts with digit\n' +
'[Processing End]')
exit(0)
else:
split_list.append((each, 'identifier'))
elif each in symbol_jack: # symbol_single
split_list.append((each, 'symbol'))
else: # mixed alpha and digit and symbol
# print('[Log]:\tmixed,each = ' + each)
found_flag = False
for symbol in symbol_jack:
if symbol in each:
found_flag = True
split_list = split_list + self.split_str(each[0:each.index(symbol)]) + [
(symbol, 'symbol')] + self.split_str(each[each.index(symbol) + len(symbol):])
# 可以采用第二种类内函数调用方法:Tokenizer.split_str()
# 若将本函数写作静态函数,即没有self实例,即可采用该方法
break # 当一个str中存在多个symbol时,会处理多遍,导致重复,应退出循环
if not found_flag:
print('[Unfixed]:\t' + each)
return split_list
# ----------------------------------------------------------
# Class Description:
# Instantiate: CompilationEngineToXml(tokens_list)
class CompilationEngineToXml(object):
def __init__(self, tokens_list):
self.tokens_list = tokens_list.copy() # tokenized_list is a list of tuple[('token', 'token_type')]
self.parsed_list = [] # parsed_list is list of str, each str is a line of final xml file
# main compilation engine process
self.compile_class()
if len(self.tokens_list) != 0:
print('[Log]:\tError_unparsered_token:', self.tokens_list)
def get_parsed_list(self):
return self.parsed_list
def head_str(self):
return self.tokens_list[0][0]
def head_type(self):
return self.tokens_list[0][1]
def head_pop(self):
self.tokens_list.pop(0)
def advance_token(self, par_str_list):
if len(self.tokens_list) == 0:
print('[Log]:\tError_advance_token_failed')
if (len(par_str_list) == 0) or (self.head_str() in par_str_list): # 没有指定str,直接按照type解析
self.parsed_list.append('<' + self.head_type() + '> ' + self.head_str() + ' </' + self.head_type() + '>')
self.head_pop()
else:
print('[Log]:\tError in advance_token' + self.head_str())
exit(0)
# class
def compile_class(self):
self.parsed_list.append('<class>')
self.advance_token('class') # 'class'
self.advance_token([]) # className
self.advance_token('{') # '{'
while self.head_str() in ['static', 'field', 'constructor', 'function', 'method']:
if self.head_str() in ['static', 'field']: # classVar_dec*
self.compile_class_var_dec()
elif self.head_str() in ['constructor', 'function', 'method']: # subroutineDec*
self.compile_subroutine()
self.advance_token('}') # '}'
self.parsed_list.append('</class>')
# classVarDec
def compile_class_var_dec(self):
self.parsed_list.append('<classVarDec>')
self.advance_token(['static', 'field']) # 'static' | 'field'
self.advance_token([]) # type
self.advance_token([]) # varName
while self.head_str() == ',': # (',' varName)*
self.advance_token(',') # ','
self.advance_token([]) # varName
self.advance_token(';') # ';'
self.parsed_list.append('</classVarDec>')
# subroutineDec
def compile_subroutine(self):
self.parsed_list.append('<subroutineDec>')
self.advance_token(['constructor', 'function', 'method']) # ('constructor'|'function'|'method')
self.advance_token([]) # ('void'|type) type: 'int'|'char'|'boolean'|className
self.advance_token([]) # subroutineName
self.advance_token('(') # '('
self.compile_parameter_list() # parameterList
self.advance_token(')')
# compile subroutineBody
self.parsed_list.append('<subroutineBody>')
self.advance_token('{') # '{'
while self.head_str() == 'var': # varDec*
self.compile_var_dec()
self.compile_statements() # statements
self.advance_token('}') # '}'
self.parsed_list.append('</subroutineBody>')
self.parsed_list.append('</subroutineDec>')
# parameterList
def compile_parameter_list(self):
self.parsed_list.append('<parameterList>')
if self.head_str() != ')': # ((type varName) (',' type varName)*)?
self.advance_token([]) # type
self.advance_token([]) # varName
while self.head_str() == ',':
self.advance_token(',') # ','
self.advance_token([]) # type
self.advance_token([]) # varName
self.parsed_list.append('</parameterList>')
# varDec
def compile_var_dec(self):
self.parsed_list.append('<varDec>')
self.advance_token('var') # 'var'
self.advance_token([]) # ()type: 'int'|'char'|'boolean'|className
self.advance_token([]) # varName
while self.head_str() == ',': # (',' varName)*
self.advance_token(',') # ','
self.advance_token([]) # varName
self.advance_token(';') # ';'
self.parsed_list.append('</varDec>')
# statements
def compile_statements(self):
self.parsed_list.append('<statements>') # statements
while self.head_str() in ['let', 'if', 'while', 'do', 'return']: # statements: statement
if self.head_str() == 'let': # letStatement
self.compile_let()
elif self.head_str() == 'if': # ifStatement
self.compile_if()
elif self.head_str() == 'while': # whileStatement
self.compile_while()
elif self.head_str() == 'do': # doStatement
self.compile_do()
elif self.head_str() == 'return': # returnStatement
self.compile_return()
self.parsed_list.append('</statements>')
# doStatement
def compile_do(self):
self.parsed_list.append('<doStatement>')
self.advance_token('do') # 'do'
# subroutineCall
if self.tokens_list[1][0] == '(':
self.advance_token([]) # subroutineName
elif self.tokens_list[1][0] == '.':
self.advance_token([]) # (className|varName)
self.advance_token('.') # '.'
self.advance_token([]) # subroutineName
self.advance_token('(') # '('
self.compile_expression_list() # expressionList
self.advance_token(')') #
self.advance_token(';') # ';'
self.parsed_list.append('</doStatement>')
# letStatement
def compile_let(self):
self.parsed_list.append('<letStatement>')
self.advance_token('let') # 'let'
self.advance_token([]) # varName
if self.head_str() == '[': # ('[' expression ']')?
self.advance_token('[') # '['
self.compile_expression() # expression
self.advance_token(']') # ']'
self.advance_token('=') # '='
self.compile_expression() # expression
self.advance_token(';') # ';'
self.parsed_list.append('</letStatement>')
# whileStatement
def compile_while(self):
self.parsed_list.append('<whileStatement>')
self.advance_token('while') # 'while'
self.advance_token('(') # '('
self.compile_expression() # expression
self.advance_token(')') # ')'
self.advance_token('{') # '{'
self.compile_statements() # statements
self.advance_token('}') # '}'
self.parsed_list.append('</whileStatement>')
# returnStatement
def compile_return(self):
self.parsed_list.append('<returnStatement>')
self.advance_token('return') # 'return'
if self.head_str() != ';': # expression?
self.compile_expression()
self.advance_token(';') # ';'
self.parsed_list.append('</returnStatement>')
# ifStatement
def compile_if(self):
self.parsed_list.append('<ifStatement>')
self.advance_token('if') # 'if'
self.advance_token('(') # '('
self.compile_expression() # expression
self.advance_token(')') # ')'
self.advance_token('{') # '{'
self.compile_statements() # statements
self.advance_token('}') # '}'
if self.head_str() == 'else':
self.advance_token('else')
self.advance_token('{') # '{'
self.compile_statements() # statements
self.advance_token('}') # '}'
self.parsed_list.append('</ifStatement>')
def compile_expression(self):
self.parsed_list.append('<expression>')
op_jack = ['+', '-', '*', '/', '&', '|', '<', '>', '=']
self.compile_term() # term
while self.head_str() in op_jack: # (op term)*
self.advance_token(op_jack) # op
self.compile_term() # term
self.parsed_list.append('</expression>')
def compile_term(self):
self.parsed_list.append('<term>')
unaryOp_jack = ['-', '~']
if self.head_str() in unaryOp_jack: # unary term
self.advance_token(unaryOp_jack)
self.compile_term()
elif self.head_str() == '(': # '(' expression ')'
self.advance_token('(') # '('
self.compile_expression() # expression
self.advance_token(')') # ')'
elif self.tokens_list[1][0] in ['(', '.']: # subroutineCall
# subroutineCall
if self.tokens_list[1][0] == '(':
self.advance_token([]) # subroutineName
elif self.tokens_list[1][0] == '.':
self.advance_token([]) # (className|varName)
self.advance_token('.') # '.'
self.advance_token([]) # subroutineName
self.advance_token('(') # '('
self.compile_expression_list() # expressionList
self.advance_token(')') #
elif self.tokens_list[1][0] == '[': # varName '[' expression ']'
self.advance_token([]) # varName
self.advance_token('[') # '['
self.compile_expression() # expression
self.advance_token(']') # ']'
else:
self.advance_token([]) # integerConstant | stringConstant | keywordConstant | varName
self.parsed_list.append('</term>')
def compile_expression_list(self):
self.parsed_list.append('<expressionList>')
if self.head_str() != ')': # (expression (',' expression)*)?
self.compile_expression() # expression
while self.head_str() == ',': # (',' expression)*
self.advance_token(',') # ','
self.compile_expression() # expression
self.parsed_list.append('</expressionList>')
# ----------------------------------------------------------
# Description:
# return all start index of sub_string in main_string
# Output:
# main_string sub_string
# Caution:
# this function use Regex to processing string, be sure your sub_string is a valid Regex
# ----------------------------------------------------------
def index_all(main_str, sub_str):
return [each.start() for each in re.finditer(sub_str, main_str)]
# ----------------------------------------------------------
# Description:
# return all end index of sub_string in main_string
# Output:
# main_string sub_string
# Caution:
# this function use Regex to processing string, be sure your sub_string is a valid Regex
# ----------------------------------------------------------
def index_all_end(main_str, sub_str):
starts = index_all(main_str, sub_str)
return [start + len(sub_str) - 1 for start in starts]
if __name__ == '__main__':
print('[Warning]:\tthis script is not mean to used separately, use Compiler.py instead.\n')
Implementation-Code_generation.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Description:
generate .vm code using the parsing tree build by syntax_analyzer
Module:
SymbolTable, VMWriter
Recommended OS:
Linux
"""
__author__ = 'eric'
# # ----------------------------------------------------------
# # Description:
# # generating vm code
# # Output:
# # vm_list
# def code_generation():
# vm_list = []
# return vm_list
# ----------------------------------------------------------
# Class Description:
# Instantiate: CompilationEngineToVM(tokens_list)
class CompilationEngineToVM(object):
def __init__(self, tokens_list):
# create a new list by using copy() explicitly, or your operation will be done on original tokens_list[]
self.tokens_list = tokens_list.copy() # tokenized_list is a list of tuple[('token', 'token_type')]
# symbol_table
self.global_table = SymbolTable() # symbol_table for class scope
self.sub_table = SymbolTable() # symbol_table for each subroutine scope
# vm_writer
self.vm_write = VMWriter() # write vm_file
# more info used for compiling class
self.class_name = ''
self.subroutine_type = ''
self.func_name = ''
self.while_index = 0 # maintain the index of the label used in while_statement and if_statement
self.if_index = 0
# ---* main compilation engine process *---
self.compile_class()
if len(self.tokens_list) != 0:
print('[Log]:\tError_unparsered_token:', self.tokens_list)
# ----------------------------------------------------------
# Description: return the vm_list
def get_vm_list(self):
return self.vm_write.get_vm_list()
# ----------------------------------------------------------
# Description: return the first token of the tokens_list
def head_str(self):
return self.tokens_list[0][0]
# ----------------------------------------------------------
# Description: return the first token's type of the tokens_list
def head_type(self): # keyword | symbol | integerConstant | stringConstant | identifier
return self.tokens_list[0][1]
# ----------------------------------------------------------
# Description: pop out the first token
def head_pop(self):
self.tokens_list.pop(0)
# ----------------------------------------------------------
# Description: validating this token using str_list and type_list, pop the first token
# Input:
# str_list - specify a list of valid str
# type_list - specify a list of valid type
def advance_token(self, str_list, type_list):
if len(self.tokens_list) == 0:
print('[Log]:\tError_advance_token_failed')
# no specified str_list or the first token conforms the requirements given by str_list,
if (len(str_list) == 0) or (self.head_str() in str_list):
# no specified type_list or the first token's type conforms the requirements given by type_list,
# do nothing and execute pop() directly
if (len(type_list) == 0) or (self.head_type() in type_list):
self.head_pop()
else:
print('[Log]:\tError_in_advance_token_type, valid type: ', type_list,
'\ntoken: ' + self.head_str() + ' type: ' + self.head_type())
exit(0)
else:
print('[Log]:\tError_in_advance_token_str, valid str: ', str_list,
'\ntoken: ' + self.head_str() + ' type: ' + self.head_type())
exit(0)
# ----------------------------------------------------------
# class
def compile_class(self):
self.advance_token(['class'], ['keyword']) # 'class'
self.class_name = self.head_str() # record class_name
self.advance_token([], ['identifier']) # className
self.advance_token(['{'], ['symbol']) # '{'
while self.head_str() in ['static', 'field', 'constructor', 'function', 'method']:
if self.head_str() in ['static', 'field']: # classVar_dec*
self.compile_class_var_dec()
elif self.head_str() in ['constructor', 'function', 'method']: # subroutineDec*
self.compile_subroutine_dec()
self.advance_token(['}'], ['symbol']) # '}'
# ----------------------------------------------------------
# classVarDec
def compile_class_var_dec(self):
_kind = self.head_str()
if _kind == 'field':
_kind = 'this'
self.advance_token(['static', 'field'], ['keyword']) # 'static' | 'field'
_type = self.head_str()
self.advance_token([], ['keyword', 'identifier']) # type
_name = self.head_str()
self.advance_token([], ['identifier']) # varName
self.global_table.define(_name, _type, _kind)
while self.head_str() == ',': # (',' varName)*
self.advance_token([','], ['symbol']) # ','
_name = self.head_str()
self.advance_token([], ['identifier']) # varName
self.global_table.define(_name, _type, _kind)
self.advance_token([';'], ['symbol']) # ';'
# ----------------------------------------------------------
# subroutineDec
def compile_subroutine_dec(self):
self.sub_table.start_subroutine() # reset sub_table for this subroutine
local_var_cnt = 0 # reset the count of local variables for this subroutine
self.subroutine_type = self.head_str() # record the type of this subroutine
self.advance_token(['constructor', 'function', 'method'], ['keyword']) # ('constructor'|'function'|'method')
# ('void'|type) type: 'int'|'char'|'boolean'|className
self.advance_token([], ['keyword', 'identifier']) # ('void'|type)
# if subroutine type is constructor, this func_name has to be new
self.func_name = self.class_name + '.' + self.head_str() # record function name
self.advance_token([], ['identifier']) # subroutineName
self.advance_token(['('], ['symbol']) # '('
self.compile_parameter_list() # parameterList
self.advance_token([')'], ['symbol'])
# compile subroutineBody
self.advance_token(['{'], ['symbol']) # '{'
# varDec has to on ahead of statements
while self.head_str() == 'var': # varDec*
local_var_cnt += self.compile_var_dec()
self.vm_write.write_function(self.func_name, local_var_cnt) # function f n
if self.subroutine_type == 'constructor':
# as a callee, the constructor need to allocate a memory block for the new object,
# and set the base of 'this' segment to point at base of block memory that just allocated
field_num = self.global_table.kind_count['this'] # only consider the number of field variables
# all build-in type in .jack language can be represented by a 16-bit word,
# if type of this field variable is object, the value of that field variable is the base addr of that obj,
# which can also be represented by a 16-bit word
self.vm_write.write_push('constant', field_num)
self.vm_write.write_call('Memory.alloc', 1)
self.vm_write.write_pop('pointer', 0)
elif self.subroutine_type == 'method':
# as a callee, the method is supposed to set the base of 'this' segment to argument 0
self.vm_write.write_push('argument', 0)
self.vm_write.write_pop('pointer', 0)
self.compile_statements() # statements
self.advance_token(['}'], ['symbol']) # '}'
# ----------------------------------------------------------
# parameterList
# the variables in parameterList should be count on subroutine symbol_table
def compile_parameter_list(self):
if self.subroutine_type == 'method': # first parameter of method has to be a 'this' pointer
# first parameter should be an implicit 'this'
self.sub_table.define('this', self.class_name, 'argument')
# even if there is no parameter given to this method
if self.head_str() != ')': # ((type varName) (',' type varName)*)?
_type = self.head_str()
self.advance_token([], ['keyword', 'identifier']) # type
_name = self.head_str()
self.advance_token([], ['identifier']) # varName
self.sub_table.define(_name, _type, 'argument')
while self.head_str() == ',':
self.advance_token([','], ['symbol']) # ','
_type = self.head_str()
self.advance_token([], ['keyword', 'identifier']) # type
_name = self.head_str()
self.advance_token([], ['identifier']) # varName
self.sub_table.define(_name, _type, 'argument')
# ----------------------------------------------------------
# varDec
# the variables in varDec should be count on subroutine symbol_table
def compile_var_dec(self):
local_var_cnt = 0
self.advance_token(['var'], ['keyword']) # 'var'
_type = self.head_str()
self.advance_token([], ['keyword', 'identifier']) # ()type: 'int'|'char'|'boolean'|className
_name = self.head_str()
self.advance_token([], ['identifier']) # varName
self.sub_table.define(_name, _type, 'local')
local_var_cnt += 1
while self.head_str() == ',': # (',' varName)*
self.advance_token([','], ['symbol']) # ','
_name = self.head_str()
self.advance_token([], ['identifier']) # varName
self.sub_table.define(_name, _type, 'local')
local_var_cnt += 1
self.advance_token([';'], ['symbol']) # ';'
return local_var_cnt
# ----------------------------------------------------------
# statements
def compile_statements(self):
while self.head_str() in ['let', 'if', 'while', 'do', 'return']: # statements: statement
if self.head_str() == 'let': # letStatement
self.compile_let()
elif self.head_str() == 'if': # ifStatement
self.compile_if()
elif self.head_str() == 'while': # whileStatement
self.compile_while()
elif self.head_str() == 'do': # doStatement
self.compile_do()
elif self.head_str() == 'return': # returnStatement
self.compile_return()
# ----------------------------------------------------------
# doStatement
def compile_do(self):
self.advance_token(['do'], ['keyword']) # 'do'
self.compile_subroutine_call() # subroutineCall
self.advance_token([';'], ['symbol']) # ';'
self.vm_write.write_pop('temp', 0) # pop a useless value after void function return
# ----------------------------------------------------------
# subroutineCall
# situations of calling subroutine:
# subroutineName() - method of this class
# varName.subroutineName() - method of other class
# className.subroutineName() - function of whatever class(including constructor, if subroutineName is new)
# Notice:
# when calling subroutine, there is no need to distinguish function and constructor,
# since you already insert the vm.code that allocate memory in the vm.code part that belong to this constructor
def compile_subroutine_call(self):
expression_num = 0
if self.tokens_list[1][0] == '(': # subroutineName(expressionList)
# 1. as a caller of a method, you are supposed to push the obj as the first and implicit argument.
# 2. as the syntax specified, the only situation when you can call a subroutine like subroutineName(expressionList)
# is when this subroutine is a method in this class
# you are supposed to push this(pointer 0) as the first and implicit argument
self.vm_write.write_push('pointer', 0)
expression_num += 1
self.subroutine_type = 'method'
self.func_name = self.class_name + '.' + self.head_str()
self.advance_token([], ['identifier']) # subroutineName
elif self.tokens_list[1][0] == '.': # (className|varName).subroutineName(expressionList)
_type, _kind, _index, if_exist = self.info_of_identifier(self.head_str())
if if_exist: # identifier in symbol_table, str is a variable, means this subroutine is a method
# _type have been confirmed
# as a caller of a method, you are supposed to push the obj as the first and implicit argument
self.vm_write.write_push(_kind, _index)
expression_num += 1
self.subroutine_type = 'method'
else: # identifier not in symbol_table, str is className
_type = self.head_str()
# as a caller of a function or constructor,
# you treat function and constructor with no difference
# the only thing for sure is that a constructor return the addr of obj it just created
self.subroutine_type = 'function' # function or constructor
self.advance_token([], ['identifier']) # (className|varName)
self.advance_token(['.'], ['symbol']) # '.'
if self.head_str() == 'new':
self.subroutine_type = 'constructor'
self.func_name = _type + '.' + self.head_str()
self.advance_token([], ['identifier']) # subroutineName
self.advance_token(['('], ['symbol']) # '('
expression_num += self.compile_expression_list() # expressionList
self.advance_token([')'], ['symbol']) # ')'
self.vm_write.write_call(self.func_name, expression_num)
# ----------------------------------------------------------
# check if identifier is in symbol table, return specified info if it does
# Return: _type, _kind, _index, if_exist
def info_of_identifier(self, identifier):
if identifier in self.sub_table.table: # identifier found in sub_table
return [self.sub_table.which_type(identifier), self.sub_table.which_kind(identifier),
self.sub_table.which_index(identifier), True]
elif identifier in self.global_table.table: # identifier found in global_table
return [self.global_table.which_type(identifier), self.global_table.which_kind(identifier),
self.global_table.which_index(identifier), True]
else: # identifier not found
return [None, None, None, False]
# ----------------------------------------------------------
# letStatement
def compile_let(self):
arr_manipulation = 0
self.advance_token(['let'], ['keyword']) # 'let'
temp_var_name = self.head_str() # record variable that is given value to
self.advance_token([], ['identifier']) # varName
_type, _kind, _index, if_exist = self.info_of_identifier(temp_var_name)
if not if_exist:
print('[Log]:\tError_invalid_variable_' + temp_var_name)
exit(0)
if self.head_str() == '[': # ('[' expression ']')?
# notice: when the code you are about to compile is something like: 'let arr[exp1] = exp2'
# you are not allowed to use 'pointer 1' before calculating the value of exp2
# since you might use 'pointer 1' in your calculation of exp2 either, which will definitely cause a crash
arr_manipulation = 1
self.vm_write.write_push(_kind, _index)
self.advance_token(['['], ['symbol']) # '['
self.compile_expression() # expression
self.advance_token([']'], ['symbol']) # ']'
self.vm_write.write_arithmetic('add')
self.advance_token(['='], ['symbol']) # '='
self.compile_expression() # expression
if arr_manipulation:
self.vm_write.write_pop('temp', 0)
self.vm_write.write_pop('pointer', 1)
self.vm_write.write_push('temp', 0)
self.vm_write.write_pop('that', 0)
else:
self.vm_write.write_pop(_kind, _index)
self.advance_token([';'], ['symbol']) # ';'
# ----------------------------------------------------------
# whileStatement
def compile_while(self):
while_cnt = self.while_index
self.while_index += 1
label_start = 'label_while_start_' + str(while_cnt)
label_end = 'label_while_end_' + str(while_cnt)
self.vm_write.write_label(label_start) # label label_start
self.advance_token(['while'], ['keyword']) # 'while'
self.advance_token(['('], ['symbol']) # '('
self.compile_expression() # expression
self.advance_token([')'], ['symbol']) # ')'
self.vm_write.write_arithmetic('not') # not, (bit-wise operation)
self.vm_write.write_if(label_end) # if-goto label_end, (jump if top value of stack is not zero-False)
self.advance_token(['{'], ['symbol']) # '{'
self.compile_statements() # statements
self.advance_token(['}'], ['symbol']) # '}'
self.vm_write.write_goto(label_start) # goto label_start, (jump with no condition)
self.vm_write.write_label(label_end) # label label_end
# ----------------------------------------------------------
# returnStatement
def compile_return(self):
self.advance_token(['return'], ['keyword']) # 'return'
if self.head_str() != ';': # expression?
self.compile_expression()
else:
self.vm_write.write_push('constant', 0)
self.advance_token([';'], ['symbol']) # ';'
self.vm_write.write_return() # return
# ----------------------------------------------------------
# ifStatement
def compile_if(self):
if_cnt = self.if_index
self.if_index += 1
label_if = 'label_if_' + str(if_cnt)
label_else = 'label_else_' + str(if_cnt)
self.advance_token(['if'], ['keyword']) # 'if'
self.advance_token(['('], ['symbol']) # '('
self.compile_expression() # expression
self.advance_token([')'], ['symbol']) # ')'
self.vm_write.write_arithmetic('not') # not
self.vm_write.write_if(label_if)
self.advance_token(['{'], ['symbol']) # '{'
self.compile_statements() # statements
self.advance_token(['}'], ['symbol']) # '}'
self.vm_write.write_goto(label_else)
self.vm_write.write_label(label_if)
if self.head_str() == 'else':
self.advance_token(['else'], ['keyword'])
self.advance_token(['{'], ['symbol']) # '{'
self.compile_statements() # statements
self.advance_token(['}'], ['symbol']) # '}'
self.vm_write.write_label(label_else)
# ----------------------------------------------------------
# compile expression, leave the result of this expression on the stack
def compile_expression(self):
op_jack = {'+': 'add',
'-': 'sub',
'*': 'call Math.multiply 2',
'/': 'call Math.divide 2',
'&': 'and',
'|': 'or',
'<': 'lt',
'>': 'gt',
'=': 'eq'}
self.compile_term() # term
while self.head_str() in op_jack: # (op term)*
temp_op = self.head_str()
self.advance_token(op_jack, ['symbol']) # op
self.compile_term() # term
self.vm_write.write_arithmetic(op_jack[temp_op]) # write arithmetic command
def compile_term(self):
unaryOp_jack = {'-': 'neg', '~': 'not'}
key_word_constant = ['true', 'false', 'null', 'this']
if self.head_str() in unaryOp_jack: # unaryOp term
temp_cmd = unaryOp_jack[self.head_str()]
self.advance_token(unaryOp_jack, ['symbol'])
self.compile_term()
self.vm_write.write_arithmetic(temp_cmd)
elif self.head_str() == '(': # '(' expression ')'
self.advance_token(['('], ['symbol']) # '('
self.compile_expression() # expression
self.advance_token([')'], ['symbol']) # ')'
elif self.tokens_list[1][0] in ['(', '.']: # subroutineCall
self.compile_subroutine_call()
elif self.tokens_list[1][0] == '[': # varName '[' expression ']'
_type, _kind, _index, if_exist = self.info_of_identifier(self.head_str())
if not if_exist:
print('[Log]:\tError_no_such_varName_' + self.head_str())
exit(0)
self.vm_write.write_push(_kind, _index)
self.advance_token([], ['identifier']) # varName
self.advance_token(['['], ['symbol']) # '['
self.compile_expression() # expression
self.advance_token([']'], ['symbol']) # ']'
self.vm_write.write_arithmetic('add')
self.vm_write.write_pop('pointer', 1)
self.vm_write.write_push('that', 0)
elif self.head_type() == 'identifier': # varName
_type, _kind, _index, if_exist = self.info_of_identifier(self.head_str())
if if_exist:
self.vm_write.write_push(_kind, _index)
self.advance_token([], ['identifier'])
else:
print('[Log]:\tError_invalid_variable')
exit(0)
elif self.head_type() == 'keyword': # keywordConstant
if self.head_str() == 'true': # push 1111111111111111
self.vm_write.write_push('constant', 0)
self.vm_write.write_arithmetic('not')
elif self.head_str() in ['false', 'null']: # push 0000000000000000
self.vm_write.write_push('constant', 0)
elif self.head_str() == 'this': # push pointer 0
self.vm_write.write_push('pointer', 0)
self.advance_token(key_word_constant, ['keyword'])
elif self.head_type() == 'stringConstant': # stringConstant
length = len(self.head_str())
self.vm_write.write_push('constant', length) # push constant length
self.vm_write.write_call('String.new', 1) # call String.new 1
for each_alpha in self.head_str():
self.vm_write.write_push('constant', ord(each_alpha)) # push constant ascii
self.vm_write.write_call('String.appendChar', 2) # call String.appendChar 2
self.advance_token([], ['stringConstant'])
elif self.head_type() == 'integerConstant': # integerConstant
self.vm_write.write_push('constant', self.head_str())
self.advance_token([], ['integerConstant'])
# ----------------------------------------------------------
# expressionList
# Return: expression_num(the number of expression in this list)
def compile_expression_list(self):
expression_num = 0
if self.head_str() != ')': # (expression (',' expression)*)?
self.compile_expression() # expression
expression_num += 1
while self.head_str() == ',': # (',' expression)*
self.advance_token([','], ['symbol']) # ','
self.compile_expression() # expression
expression_num += 1
return expression_num
# ----------------------------------------------------------
# Class Description:
# Instantiate: SymbolTable()
class SymbolTable(object):
def __init__(self):
self.table = {} # {name : [type, kind, index]}
# kind: ( static | field | argument | var)
# Notice: in order to facilitate compile, count the 'field' and 'var' variable as 'this' and 'local',
# since it would be easier to access that variable in VM segment using its _kind directly
self.kind_count = {'static': 0, # stands for - static variable
'this': 0, # stands for - field variable
'argument': 0, # stands for - argument variable
'local': 0} # stands for - var variable
# ----------------------------------------------------------
# Description: start compiling a new subroutine, reset this symbol table(only sub table)
def start_subroutine(self):
self.table.clear()
for each_key in self.kind_count.keys():
self.kind_count[each_key] = 0
# ----------------------------------------------------------
# Description: add a new variable into symbol_table, autonomously increase index according to its kind
def define(self, _name, _type, _kind): # using _ as prefix, or it will cause conflict with build-in identifiers
self.table[_name] = [_type, _kind, self.kind_count[_kind]]
self.kind_count[_kind] += 1
# ----------------------------------------------------------
def which_kind(self, name):
_kind = None
if name in self.table:
_kind = self.table.get(name)[1]
else:
print('[Log]:\tError_no_such_identifier')
exit(0)
return _kind
# ----------------------------------------------------------
def which_type(self, name):
_type = None
if name in self.table:
_type = self.table.get(name)[0]
else:
print('[Log]:\tError_no_such_identifier')
exit(0)
return _type
# ----------------------------------------------------------
def which_index(self, name):
_index = None
if name in self.table:
_index = self.table.get(name)[2]
else:
print('[Log]:\tError_no_such_identifier')
exit(0)
return _index
# ----------------------------------------------------------
# Class Description:
# Instantiate: VMWriter()
class VMWriter(object):
def __init__(self):
self.vm_list = [] # vm_list is list of str, each str is a line of final vm file
def get_vm_list(self):
return self.vm_list
def write_push(self, segment, index):
self.vm_list.append('push {0} {1}'.format(segment, str(index)))
def write_pop(self, segment, index):
self.vm_list.append('pop {0} {1}'.format(segment, str(index)))
def write_arithmetic(self, cmd):
self.vm_list.append(cmd)
def write_label(self, label):
self.vm_list.append('label {0}'.format(label))
def write_goto(self, label):
self.vm_list.append('goto {0}'.format(label))
def write_if(self, label):
self.vm_list.append('if-goto {0}'.format(label))
def write_call(self, name, n_args):
self.vm_list.append('call {0} {1}'.format(name, str(n_args)))
def write_function(self, name, n_vars):
self.vm_list.append('function {0} {1}'.format(name, str(n_vars)))
def write_return(self):
self.vm_list.append('return')
if __name__ == '__main__':
print('[Warning]:\tthis script is not mean to used separately, use Compiler.py instead.\n')















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









