







系列文章目录
前言
贪心选择性质就是从局部最优解可以得到全局最优解。它通常比动态规划更简单,但是其背后设计复杂的数学推理,大部分情况下我们不容易证明,只能通过感觉和尝试判断。
可以使用「贪心算法」的问题需要满足的条件:
1.最优子结构:规模较大的问题的解由规模较小的子问题的解组成,区别于「动态规划」,可以使用「贪心算法」的问题「规模较大的问题的解」只由其中一个「规模较小的子问题的解」决定。
2.无后效性:后面阶段的求解不会修改前面阶段已经计算好的结果。
直接刷题吧!
一、贪心基本问题
1.分发饼干
本题目是贪心算法最基本的问题,充分体现了贪心的思想。尽可能满足越多数量的孩子,那就让胃口大的同学尽量吃大饼干,胃口小的同学尽量吃小饼干即可。排序数组,遍历即可。
注意循环中当a和b有一个不满足条件就跳出,使用与&&。
int findContentChildren(vector<int> &g, vector<int> &s)
{
sort(g.begin(), g.end());
sort(s.begin(), s.end());
int a = 0, b = 0;
int num = 0;
while (a < g.size() && b < s.size())
{
if (g[a] <= s[b])
{
num++;
a++;
b++;
}
else
b++;
}
return num;
}
2.最大子数组和
这道题的巧妙之处在于,为了尽可能求得最大子数组的和,当和为负数时候,直接抛弃,因为加个负数还不如不加。直接以下一个元素为起始位置继续求解即可。
int maxSubArray(vector<int> &nums)
{
int n = nums.size();
int sum = 0;
int maxsum = INT_MIN;
for (int i = 0; i < n; i++)
{
sum += nums[i];
if (sum > maxsum)
maxsum = sum;
if (sum <= 0)
sum = 0;
}
return maxsum;
}
为了尽可能的少发糖果,并且还要满足题意,我们需要进行两次遍历。相当于把约束分为两个部分:
1.当前孩子比左边孩子多
2.当前孩子比右边孩子多
分别求出这两个规则下每个学生分到的最少糖果数量,要同时满足上面两个规则,需要两个规则中的最大值,最后求和即可。
这里使用了一个库函数accumulate,可以更方便求和。
#include <numeric>
// 分发糖果
int candy(vector<int> &ratings)
{
int n = ratings.size();
if (n == 1)
return 1;
vector<int> left(n, 1);
vector<int> right(n, 1);
for (int i = 1; i < n; i++)
{
if (ratings[i] > ratings[i - 1])
left[i] = left[i - 1] + 1;
}
for (int i = n - 2; i >= 0; i--)
{
if (ratings[i] > ratings[i + 1])
right[i] = right[i + 1] + 1;
}
vector<int> ans(n, 0);
for (int i = 0; i < n; i++)
{
ans[i] = max(left[i], right[i]);
cout << ans[i] << " ";
}
cout << endl;
return accumulate(ans.begin(), ans.end(), 0);
}
4.跳跃游戏
本题求解的是能否跳到最后一个下标,直接按照字面意思分析,比较当前元素的下标加上该元素的跳跃长度是否大于最后一个下标即可。前面元素只需要一个比最后一个下标大,就能跳到。
但是跳到最后一个下标之前,你还要保证可以跳到之前的下标才行,加上一个判断即可。
// 跳跃游戏
bool canJump(vector<int> &nums)
{
int sum = 0;
if (nums.size() == 1)
return true;
for (int i = 0; i < nums.size() - 1; i++)
{
if (i <= sum)
{
sum = max(sum, i + nums[i]);
if (sum >= nums.size() - 1)
return true;
}
}
return false;
}
5.跳跃游戏2
本题求解的是能到达终点的最小步数。用动态规划很容易求解,但是时间复杂度太高了,所以我们考虑贪心。
//动态规划解法
int Jump(vector<int> &nums)
{
int n = nums.size();
vector<int> dp(n, INT_MAX);
dp[0] = 0;
for (int i = 1; i < n; i++)
{
int minstep = INT_MAX;
for (int j = 0; j < i; j++)
{
if (j + nums[j] >= i)
{
minstep = min(minstep, dp[j]);
dp[i] = minstep + 1;
}
}
}
return dp[n - 1];
}
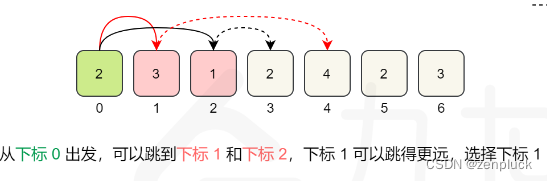
从当前路径出发,作为一个贪心的人,我会 判断能跳到的下标哪个更远,找到能跳到最远的下标,一直执行这个步骤即可。
创建一个变量end,用来表示当前能到达的最大下标,当走到end时候,步数加一,直到到达终点。
//贪心解法
int jump(vector<int> &nums)
{
int maxPos = 0, n = nums.size(), end = 0, step = 0;
for (int i = 0; i < n - 1; ++i)
{
if (maxPos >= i)
{
maxPos = max(maxPos, i + nums[i]);
if (i == end)
{
end = maxPos;
++step;
}
}
}
return step;
}
6.加油站
本道题目最容易想到的方法就是暴力了,,分别以每个元素为起点,看能否环绕一周。但这种方法太麻烦啦,而且这种小白解法肯定不是这个题目要考察的东西,本题肯定还有一些可以挖掘的关系或策略,使我们可以更方便的解答问题。那这个就是所谓的贪心策略啦!
由于走完一圈要保证每个点油剩余量都要大于等于0,关键在于设置一个当前和和累加和,遍历数组,若当前和小于0,就说明这个点不可能作为起点,直接下一个。这样就可以节省时间了。
简单来讲,就是如果X到不了Y,那么中间任何一点都不可能到达X到不了的Y,直接把Y当作新的起点即可。
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int n = gas.size();
int curcost = 0;
int sumcost = 0;
int a = 0;
for (int i = 0; i < n; i++)
{
curcost += gas[i]-cost[i];
sumcost += gas[i]-cost[i];
if (curcost < 0)
{
a = (i + 1) % n;
curcost = 0;
}
}
if (sumcost >= 0) return a;
else return -1;
}
二、区间问题
对于区间问题来说,这类题目基本上有一个类似的做法。通常输入是一个二维数组,不过每个元素有两个元素,通常是区间的起始位置。我们为了使得区间更加清晰明了。第一步要做的就是将这个二维数组排序。排序的方法有两个:
1.按照起始位置排序
2.按照结束位置排序。
对应的排序代码也很简单。
//按照起始位置排序
sort(intervals.begin(), intervals.end(), [](vector<int> &a, vector<int> &b) { return a[0] < b[0]; });
//按照结束位置排序
sort(intervals.begin(), intervals.end(), [](vector<int> &a, vector<int> &b) { return a[1] < b[1]; });
通常情况下,两种排序方式都可以使用,看哪种方法更为简便,择优取之。之后对排序后的数组进行遍历,比较当前元素的结束位置与下一个元素的起始位置的大小,之后便需要具体问题具体分析了!下面看几道相关题目。
1.合并区间
这道题目便是最经典的合并区间问题了。将所有区间进行排序,之后看是否有重叠,没有的话不处理,有重叠区间就进行合并处理,这样就可以解决问题了。不过这道题目有两个处理结果的方法。
1.新建一个result数组,用来保存结果。需要使用新的空间,但是代码更为简便。
2.直接在原区间数组上进行修改。虽然原地修改,但是区间数组大小一直在变,不太好处理。
这里为了熟悉合并区间这道题目,把两种做法都写出来,可以比较一下哪个更方便。
// 合并区间
vector<vector<int>> merge(vector<vector<int>> &intervals)
{
sort(intervals.begin(), intervals.end());
vector<vector<int>> result;
result.push_back(intervals[0]);
int j = 0;
for (int i = j + 1; i < intervals.size(); i++)
{
if (intervals[i][0] <= result[j][1])
result[j][1] = max(result[j][1], intervals[i][1]);
else
{
result.push_back(intervals[i]);
j++;
}
}
return result;
}
//原地处理
vector<vector<int>> merge1(vector<vector<int>> &intervals)
{
sort(intervals.begin(), intervals.end());
for (int i = 1; i < intervals.size(); i++)
{
if (intervals[i][0] <= intervals[i - 1][1])
{
intervals[i - 1][1] = max(intervals[i][1], intervals[i - 1][1]);
intervals.erase(intervals.begin() + i);
i--;
}
}
return intervals;
}
直接原地修改虽然空间复杂度很低,但是时间复杂度真慢!虽然就一个循环,但是问题出现在erase函数上了,让我们简要介绍一下这个函数。
vector::erase():从指定容器删除指定位置的元素或某段范围内的元素,vector::erase()方法有两种重载形式如下:
iterator erase( iterator _Where);
删除指定位置的元素,返回值是一个迭代器,指向删除元素的下一个元素;
iterator erase( iterator _First,iterator _Last);
删除从_First开始到_Lsat位置的元素,返回值也是一个迭代器,指向最后一个删除元素的下一个位置。
需要注意的是,调用erase()函数后,vector后面的元素会向前移位,形成新的容器,这样原来指向删除元素的迭代器(_Where)就失效了。
删除指定元素的时间复杂度为O(n),删除多个元素时间复杂度为O(n2)! 这是因为在删除某个元素之后,需要将其后的元素依次向前移动一个位置,以保持vector中元素在内存空间中的连续性。所以erase函数还是要慎用啊!
这道题的思想几乎和上一题一模一样了,合并区间的目的就是找出所有重叠区间,进行合并,这道题只需要找出无重叠区间的个数即可,相对来讲更简单了,记录每次选择区间的结束时间,进行比较即可。
// 无重叠区间
int eraseOverlapIntervals(vector<vector<int>> &intervals)
{
sort(intervals.begin(), intervals.end());
int count = 0;
int end = intervals[0][1]; // 当前所选区间的结束时间
for (int i = 1; i < intervals.size(); ++i)
{
if (intervals[i][0] < end)
{
// 当前区间与前一个区间重叠,需要移除一个区间
count++;
// 选取更小的结束时间
end = min(end, intervals[i][1]);
}
else
{
// 当前区间与前一个区间不重叠,更新结束时间
end = intervals[i][1];
}
}
return count;
}
这道题目和上面两道有些许不同,不过还是比较有意思的,我们只需要使用一个哈希表,然后结合贪心,即可完成任务。
使用哈希表表示26个字母的最后出现下标。 进行遍历,如果当前字母的下标等于最后一次出现的下标的话,就可以按照这个标准划分区间了!简直是妙极了。当然,一个区间不止有一个字母,我们需要找到出现的字母中的最大下标,才能划分区间。
这里参考一下代码随想录的图片,更加直观:
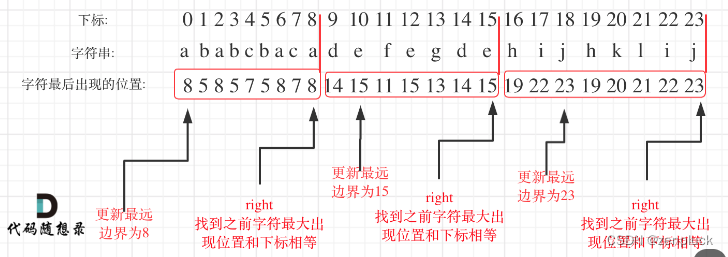
这道题目又让我感受到了哈希表的强大之处,佩服佩服。具体代码如下:
// 划分字母区间
vector<int> partitionLabels(string s)
{
unordered_map<char, int> map;
for (int i = 0; i < s.size(); i++)
{
map[s[i]] = i;
}
vector<int> ans;
int start = 0, end = 0;
for (int i = 0; i < s.size(); i++)
{
end = max(end, map[s[i]]);
if (i == end)
{
ans.push_back(end - start + 1);
start = end + 1;
}
}
return ans;
}
4.用最少数量的箭引爆气球
这道题目又是一个典型的区间问题。要想使用最少的箭,那就尽量刚好引爆气球吧! 我们的贪心策略是考虑所有气球中右边界位置最靠左的那一个,那么一定有一支箭的射出位置就是它的右边界(否则就没有箭可以将其引爆了)。
简单点来说,就是,我引爆当前气球必须要一支箭,那我从该气球的右边界引爆,说不定还能引爆其他气球,这样就血赚了,哈哈哈。不过首先需要对数组按照右边界大小进行排序。
// 用最少的箭引爆气球
int findMinArrowShots(vector<vector<int>> &points)
{
sort(points.begin(), points.end(), [](vector<int> &a, vector<int> &b)
{ return a[1] < b[1]; });
int end = points[0][1];
int cnt = 1;
for (int i = 1; i < points.size(); i++)
{
if (end >= points[i][0])
continue;
else
{
end = points[i][1];
cnt++;
}
}
return cnt;
}
这道题看着很难,其实也不是很简单。。贪心的难点就在于难想,这道题就是例子。我们如果知道将人按照身高从大到小排序,再按照前面有多少人进行插入,就可以很简单的处理问题。原因在于,身高从高到低的排序后,按照高个子先插入的方法,就可以保证之后的插入都是有效益的,因为前面的节点都比本节点要高!
// 根据身高重建队列
vector<vector<int>> reconstructQueue(vector<vector<int>> &people)
{
int n = people.size();
sort(people.begin(), people.end(), [](const vector<int> &u, const vector<int> &v)
{ return u[0] > v[0] || (u[0] == v[0] && u[1] < v[1]); });
vector<vector<int>>ans;
for (int i = 0; i < people.size(); i++)
{
ans.insert(ans.begin() + people[i][1], people[i]);
}
return ans;
}
三、与数学结合问题
贪心最烦人的还是与数学结合的问题,通常包括推导公式,还有一个更烦人的博弈论,博弈论就不说了,太麻烦啦。本节简要介绍一些让人可以接受的数学问题。
首先需要读明白这个题意,简单来讲就是每次将数组中某个元素减一,但不能连续减去同一个元素。直到不能减,求最多能减去多少次。
本题的贪心思路是:考虑耗时最长的工作。假设我们需要 longest 周完成该工作,其余工作共计需要 rest 周完成。那么可以完成所有工作的充要条件是:
longest≤rest+1.
可以完成所有工作,直接返回数组总和了!
如果不满足上述条件,说明无法完成耗时最长的工作,此时最大工作量是
rest * 2 + 1;
这个证明比较麻烦,但是还是可以想到的。思路有了,代码就很简单了。
// 可以工作的最大周数
long long numberOfWeeks(vector<int> &milestones)
{
// 耗时最长工作所需周数
long long longest = *max_element(milestones.begin(), milestones.end());
// 其余工作共计所需周数
long long rest = accumulate(milestones.begin(), milestones.end(), 0LL) - longest;
if (longest > rest + 1)
{
// 此时无法完成所耗时最长的工作
return rest * 2 + 1;
}
else
{
// 此时可以完成所有工作
return longest + rest;
}
}
这道题思考一下,其实和上面的基本上一模一样,不多解释了。。
// 移除石子的最大的得分
int maximumScore(int a, int b, int c)
{
int maxnum = max(max(a, b), c);
int sum = a + b + c;
int rest = sum - maxnum;
if (maxnum > rest + 1)
return rest;
else
return sum / 2;
}
对于这道题我刚开始的做法是,让所有元素都变到数组中的最大值。如果2 * cost1 <= cost2,那么就都用cost1进行操作。否则应该尽可能使用cost2操作。cost的操作步骤和工作的最大周数思路是一样的。
int minCostToEqualizeArray(vector<int> &nums, int cost1, int cost2)
{
int max_num = *max_element(nums.begin(), nums.end());
for (auto &num : nums)
{
num -= max_num;
num = -num;
}
int sum = accumulate(nums.begin(), nums.end(), 0LL);
const int MOD = 1e9 + 7;
// 这两种情况直接求解
if (nums.size() <= 2 || 2 * cost1 <= cost2)
return sum * cost1 % MOD;
//剩余的情况
int max2 = *max_element(nums.begin(), nums.end());
int rest = sum - max2;
if (max2 > rest + 1)
return cost2 * rest + cost1 * (max2 - rest);
else
return cost2 * rest;
}
但是这个代码是有问题的,我的做法没办法完成{1, 14, 14, 15}这个例子,只能算出等于26,但是结果是20.究其原因在于未必把所有数变成原数组中最大的数就可以实现要求,也许变成更大的数M会更好。举一个简单的例子:
nums = [1,3,4,4],下面有两种改变情况:
1.全部变为4,总开销为 2cost1+cost2。
2.全部变为5,总开销为 4cost2。
这表明如果cost2比cost1小很多,那么把数组都变成更大的数会花销更少。这样的话,我们要确定变到哪个数,可以通过枚举来实现。
假设都变成 x (x≥M),那么所有数都需要在 M 的基础上额外增加 x−M,总共要增加
s=base+(x−M)*n
按照上述讨论,计算都变成 xxx 的总开销 f(x):
如果 2d≤s,那么先执行 s/2 次操作二,然后执行 s mod 2次操作一,总开销为
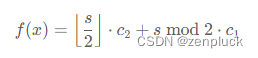
如果 2d>s,那么先执行 s−d次操作二,然后执行 2d−s 次操作一,总开销为
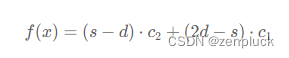
枚举 x,取 f(x)的最小值,即为最小总开销。
具体的边界取值没怎么看懂,,先贴个代码吧:
int minCostToEqualizeArray(vector<int>& nums, int c1, int c2) {
const int MOD = 1'000'000'007;
long long n = nums.size();
auto [m, M] = ranges::minmax(nums);
long long base = n * M - reduce(nums.begin(), nums.end(), 0LL);
if (n <= 2 || c1 * 2 <= c2) {
return base * c1 % MOD;
}
auto f = [&](int x) -> long long {
long long s = base + (x - M) * n;
int d = x - m;
if (d * 2 <= s) {
return s / 2 * c2 + s % 2 * c1;
}
return (s - d) * c2 + (d * 2 - s) * c1;
};
int i = (n * M - m * 2 - base + n - 3) / (n - 2);
return i <= M ? min(f(M), f(M + 1)) % MOD :
min({f(M), f(i - 1), f(i), f(i + 1)}) % MOD;
}
在成对的数字中,因为是从0-1开始的,所以每对情侣中奇数是大于偶数的。此外,如果想要进行配对,更改某一对的第一个数字和第二个数字都是可以的。
所以我们只需要看每一对的第一个数,如果是奇数x,那么与他配对的就是x-1;反之,如果是偶数x,那么与他配对的就是x+1。
要完成这么目的,我们需要事先直到与当前配对的元素在哪个位置,这就需要 一个数据结构储存数字下标和元素大小,哈希表再合适不过了。需要注意的是,我们每次会对原数组进行交换修改,所以每次循环需要重新创建哈希表,不然对应关系会乱。
int minSwapsCouples(vector<int> &row)
{
int n = row.size();
int count = 0;
// unordered_map<int, int> map;
// for (int i = 0; i < n; i++)
// {
// map[row[i]] = i;
// }
for (int i = 0; i < n; i += 2)
{
unordered_map<int, int> map;
for (int j = 0; j < n; j++)
{
map[row[j]] = j;
}
if (abs(row[i + 1] - row[i]) > 1 || (row[i] % 2 != 0 && row[i] + 1 == row[i + 1]))
{
count++;
if (row[i] % 2 == 0)
swap(row[i + 1], row[map[row[i] + 1]]);
else
swap(row[i + 1], row[map[row[i] - 1]]);
}
}
return count;
}
总结
贪心相关的问题有些难以总结,我就先按照自己入门贪心的相关题目进行了复习,之后在做题中也许会遇到更多复杂的类型,希望可以慢慢积累。















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









