







Scala
- 编程语言范式
- Scala的介绍
- Scala开发环境安装
- IDEA中Scala插件安装
- 基础语法:变量及常量
- 基础语法:数据类型
- 基础语法:字符串使用及插值表达式
- 基础语法:块表达式与if判断
- 基础语法:for循环
- 基础语法:while循环
- 基础语法:跳出循环Breaks
- 方法的定义及语法规则
- 方法的参数的使用
- 方法的调用形式
- 函数的定义及语法规则
- 函数的分类
- 方法转换成函数
- 数组与集合的分类
- 数组Array与ArrayBuffer
- 列表List与ListBuffer
- List于ListBuffer的常用操作
- Set集合
- Map集合
- 元组Tuple
- 迭代器Iterator
- 集合高阶函数:map
- 集合高阶函数:foreach
- 集合高阶函数:flatMap
- 集合高阶函数:groupBy
- 集合高阶函数:filter/filterNot
- 集合高阶函数:sortWith/sortBy
- 集合聚合函数:reduce
- 集合聚合函数:fold
- 面向对象:类的定义
- 面向对象:Object类的设计
- 面向对象:Object构建工具类
- 面向对象:main方法使用
- 面向对象:访问修饰符
- 面向对象:伴生关系
- 面向对象:回顾Java中的构造器
- 面向对象:Scala中的主构造器
- 面向对象:辅助构造器的使用
- 面向对象:apply语法糖的功能及实现
- 面向对象:类的继承与重写
- 面向对象:类型转换与类型判断
- 面向对象:抽象类的实现
- 面向对象:匿名内部类
- 面向对象:Trait的定义及使用
- 面向对象:Trait实现工具类的封装
- 面向对象:实例混入Trait
- 面向对象:Trait的构造机制及Trait继承Class
- 模式匹配:内容匹配
- 模式匹配:类型匹配及守卫条件
- 模式匹配:数组、集合、元组匹配
- 模式匹配:声明变量匹配取值
- 样例类:功能特点
- 样例类:结合模式匹配
- unapply方法与提取器
- Option类型
- 偏函数partial function的定义及使用
- 正则对象的定义及使用
- 异常的处理
- 泛型、上下界、非变斜变逆变
- 高阶函数:柯里化函数
- 高阶函数:闭包函数
- 隐式转换:功能特点及隐式参数
- 隐式转换:隐式转换方法
编程语言范式
-
目标:了解常见的编程语言范式及优缺点
-
编程范式:Programming paradigm
- 编程范式也称为编程模型
- 用于表述对于程序如何开发实现的设计思想
- 类似于数据存储设计模型:数据库、文件系统、消息队列等
-
主流的三种编程范式
-
面向过程编程范式 / 结构化编程
-
设计思想:将实现过程拆解为数据结构和算法,数据结构用于存储数据,算法用于处理数据,依次根据需求调用来实现
-
代表:C语言
-
优点
- 处理逻辑直观
- 与底层设计更加密切,硬件交互性更好
-
缺点
- 耦合度很高,无法复用逻辑
- 无法抽象化,不适于复杂业务逻辑
-
栗子:老王要开车
c.getKey c.driver 如果a也想开车,必须重新构建一个a这个类,重新定义getkey和driver方法
-
-
面向对象编程范式
-
-
设计思想:将所有逻辑拆解为实体和关系,核心特点是封装、继承和多态
-
代表:Java、C++
-
优点
- 面向对象思想,更容易理解和抽象
- 代码更容易重用
- 开放性更好,也易维护-
缺点
- 所有实现都基于对象的方法,简单需求复杂化
- 性能比面向过程编程要差一些
-
栗子:老王要开车
class Person(name,age,gender,getKey(),driver()) class C extends Person c = new C c.getKey c.driver 如果a也想开车 class A extends Person a = new A a.getKey a.driver -
-
-
函数式编程范式
- 设计思想:将所有操作全部基于数据和函数实现,==函数作为一等公民==,开发者不需要关心底层 - 优点 - 高度抽象,代码简洁高效 - 不可变设计,易于并发编程 - 声明式代码表达,易于理解 - 缺点 - 性能相对比其他两种都较差 - 栗子:老王要开车 ``` c.driver() a.driver() ``` -
小结
- 什么是编程范式?
- 就是编程的设计思想,按照什么样的思想来实现代码的设计和开发
- 有哪些常见的编程范式?
- 面向过程编程 / 面向结构化编程
- 面向对象编程:Java
- 面向函数式编程:Scala
- 什么是编程范式?
Scala的介绍
-
Scala的官网:https://www.scala-lang.org/
-
Scala combines object-oriented and functional programming in one concise, high-level language. Scala's static types help avoid bugs in complex applications, and its JVM and JavaScript runtimes let you build high-performance systems with easy access to huge ecosystems of libraries.-
Scala是一门集成了面向对象编程和面向函数式编程的高级语言
-
Scala通过静态类型避免复杂程序中的bug
-
Scala基于JVM可以实现简单的访问高性能的JVM生态圈
-
Scala的定义
- Scala是一个基于JVM的多范式编程语言
- 多范式:面向对象 + 函数式编程
- 基于JVM:可移植性非常好
- 所写的代码最终也是编译为.class文件放在JVM中运行
- Scala可以无缝的与Java的API库进行衔接访问
- Scala是一个基于JVM的多范式编程语言
-
Scala的特点
-
基于JVM:可移植性非常好
-
支持面向对象:保留了面向对象的优点,兼容面向对象开发
-
支持函数式编程:支持函数式编程的特点:函数是一等公民、惰性赋值、高阶函数、不可变数据等
-
-
Scala的应用场景
- 大数据中用于开发Spark和Flink的分布式数据处理程序
-
-
小结
- Scala是什么?
- 是一个基于JVM的面向对象和面向函数的多范式的高级编程语言
- Scala与Java有什么区别与联系?
- 联系:都基于JVM,都是编译为.class去运行的,Scala可以访问Java的API库
- 区别
- Java:面向对象
- Scala:面向对象 + 函数式编程
- 理解:Scala是将Java中好的地方保留了,将不好的地方重构了
- Scala在大数据中的应用场景是什么?
- 用于开发Spark或者Flink的分布式计算程序
- Scala是什么?
Scala开发环境安装
-
Windows中部署Scala SDK
- step1:解压安装,选择一个无中文无空格的路径解压安装
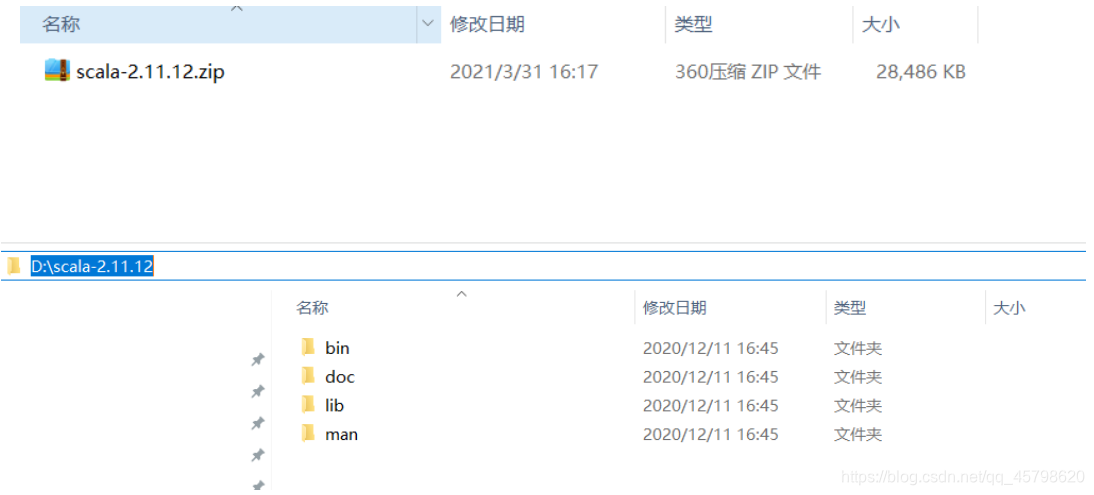
- step1:解压安装,选择一个无中文无空格的路径解压安装
-
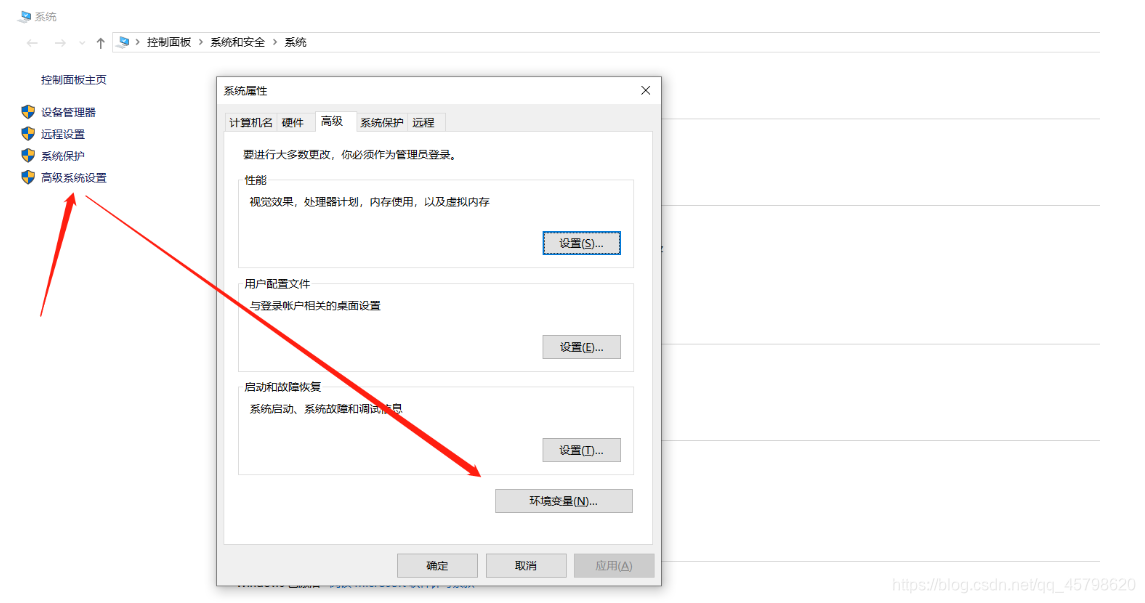
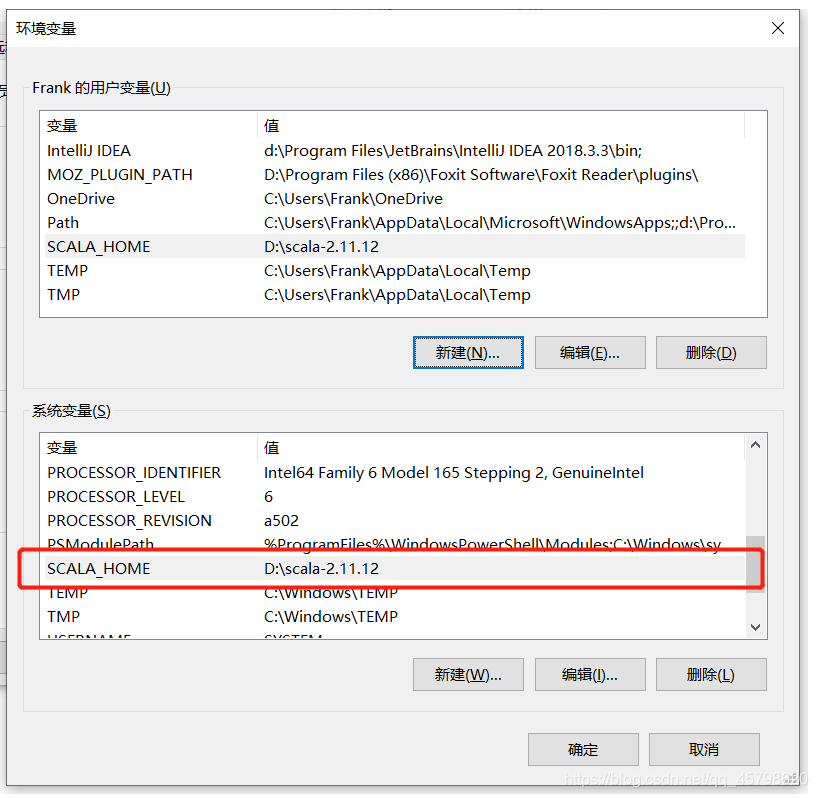
step2:配置环境变量
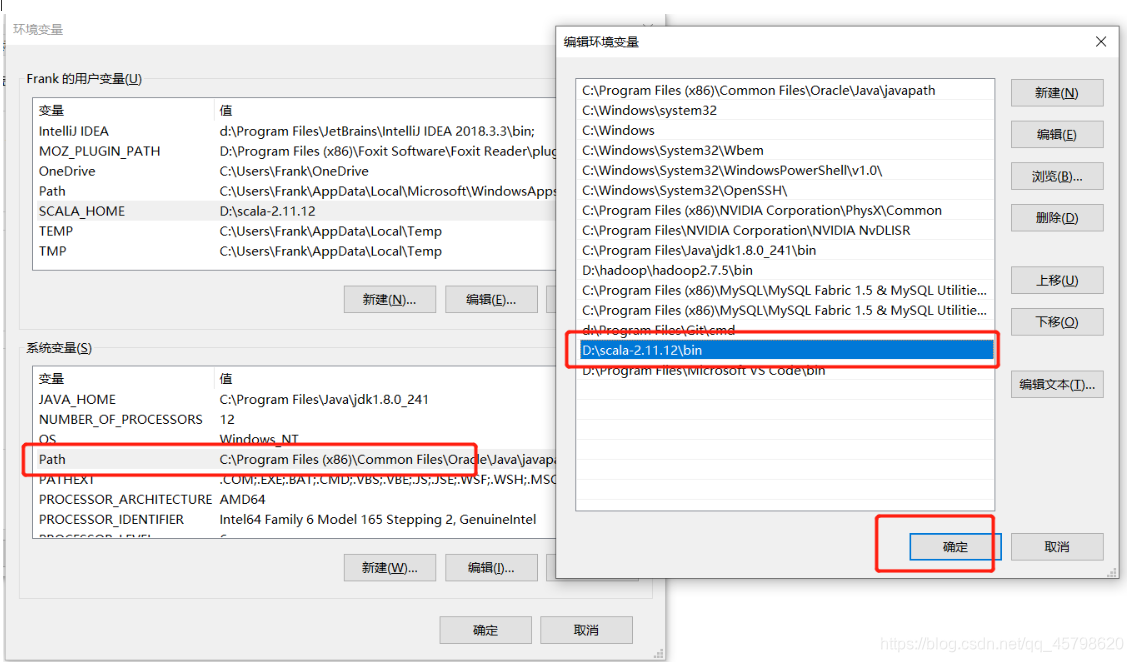
-
step3:开启CMD,测试
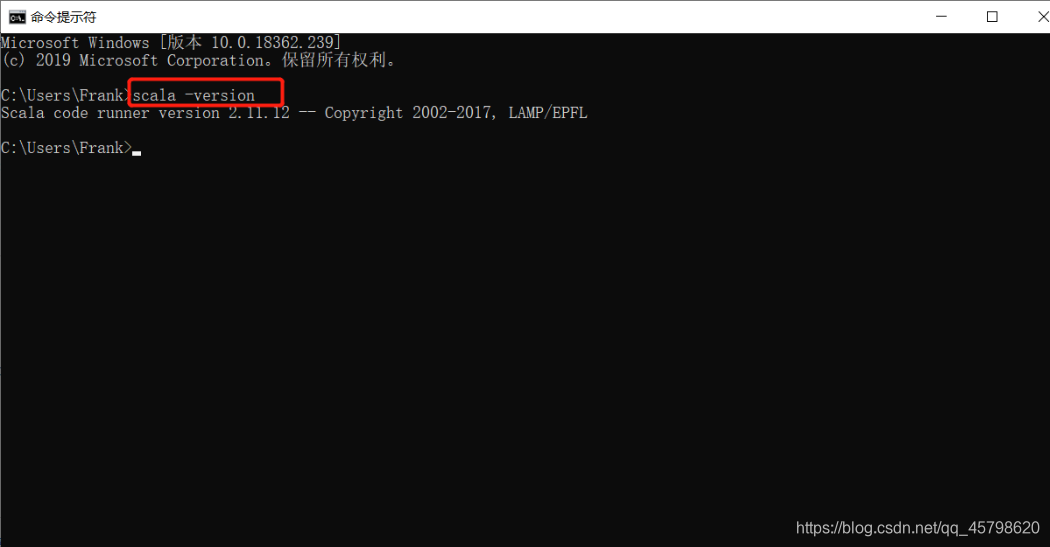
-
Linux中部署Scala SDK
-
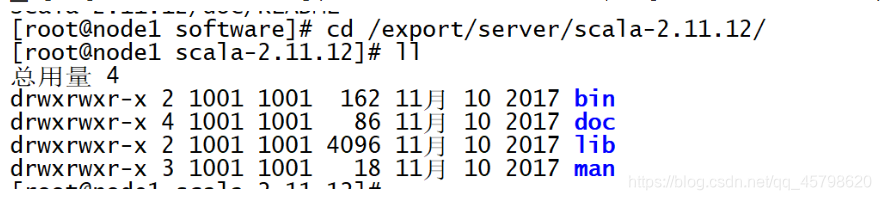
step1:上传解压安装
tar -zxvf scala-2.11.12.tgz -C /export/server/
-
-
step2:修改环境变量
vim /etc/profile#SCALA_HOME export SCALA_HOME=/export/server/scala-2.11.12 export PATH=$PATH:$SCALA_HOME/binsource /etc/profile -
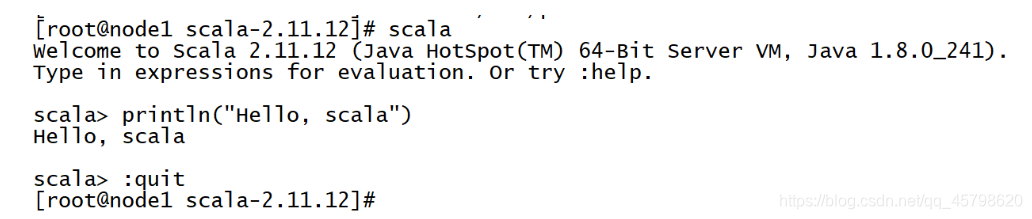
step3:进入scala命令行测试
-
进入命令行
scala -
打印输出
println("Hello,scala") -
退出命令行
:quit
-
IDEA中Scala插件安装
-
IDEA中安装Scala插件的两种方式
- 方式一:离线安装:根据IDEA版本,自己手动下载对应版本的插件,手动安装
- 不推荐
- 方式二:在线安装:直接在线下载插件,IDEA自动选择适合自己的版本
- 推荐
- 方式一:离线安装:根据IDEA版本,自己手动下载对应版本的插件,手动安装
-
IDEA中在线安装Scala插件
- step1:在线安装Scala插件
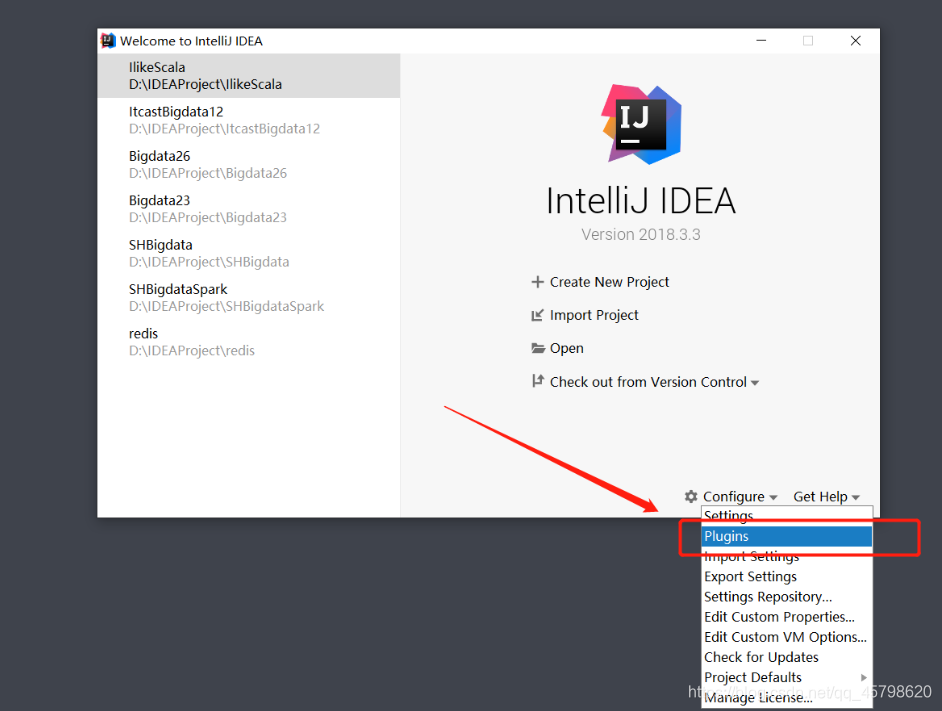
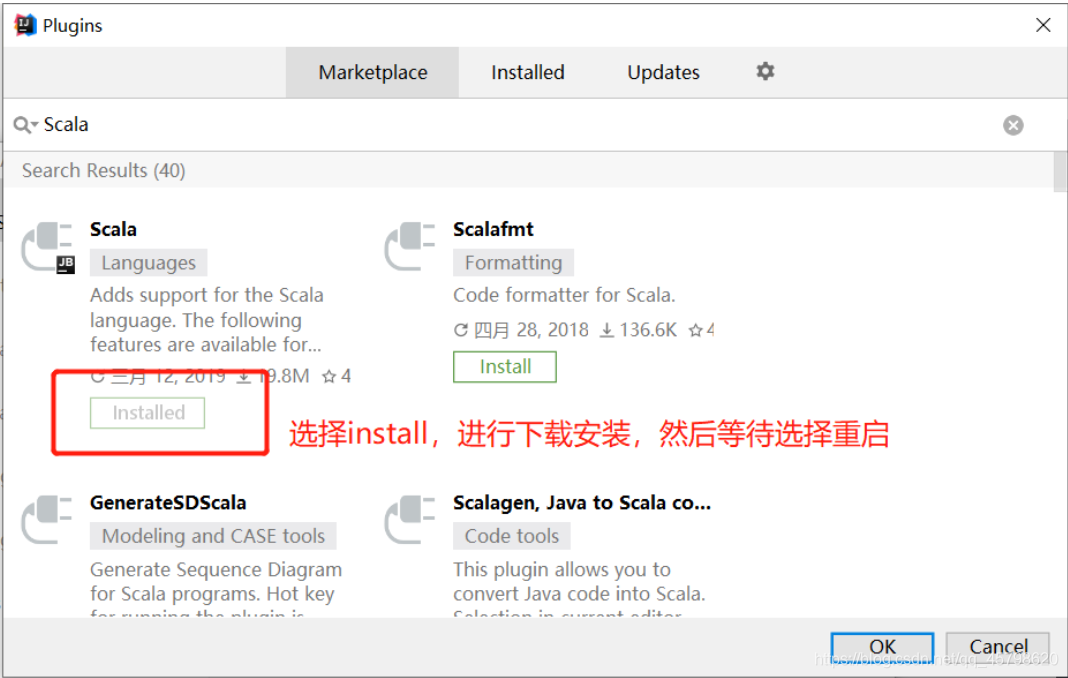
- step1:在线安装Scala插件
-
- step2:重启IDEA即可
-
IDEA中创建Scala工程
- 方式一:纯Scala工程:需要自己手动关联依赖包
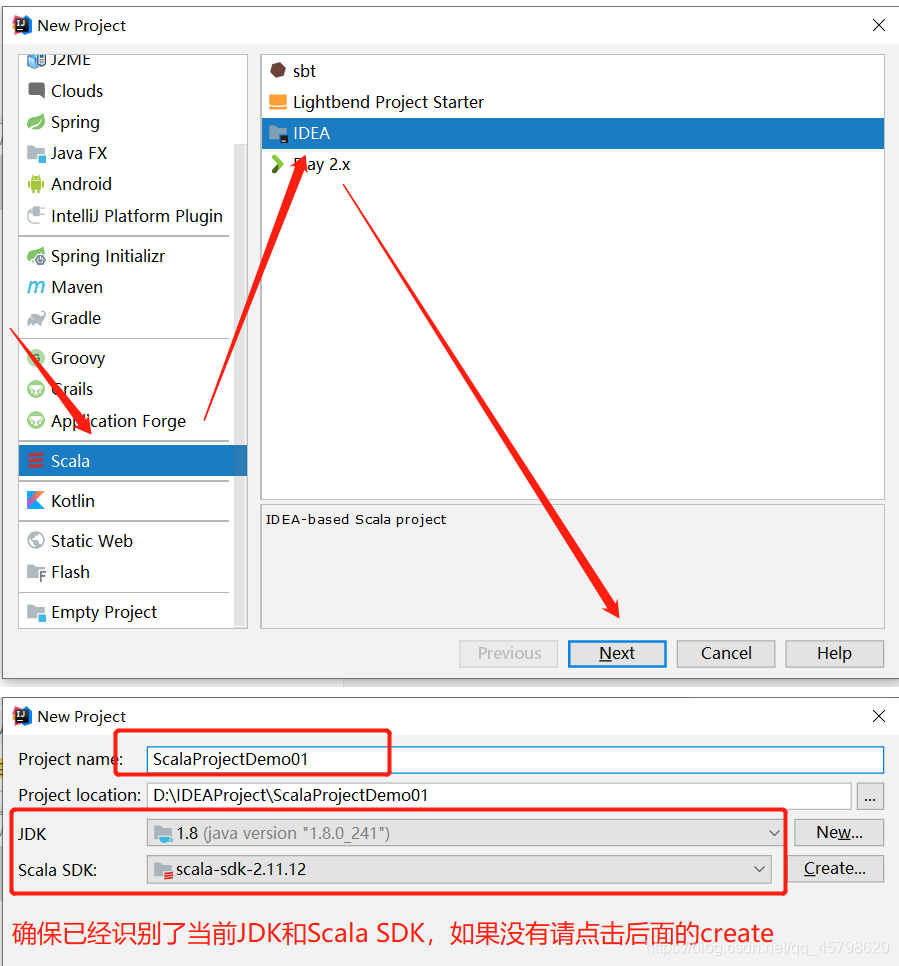

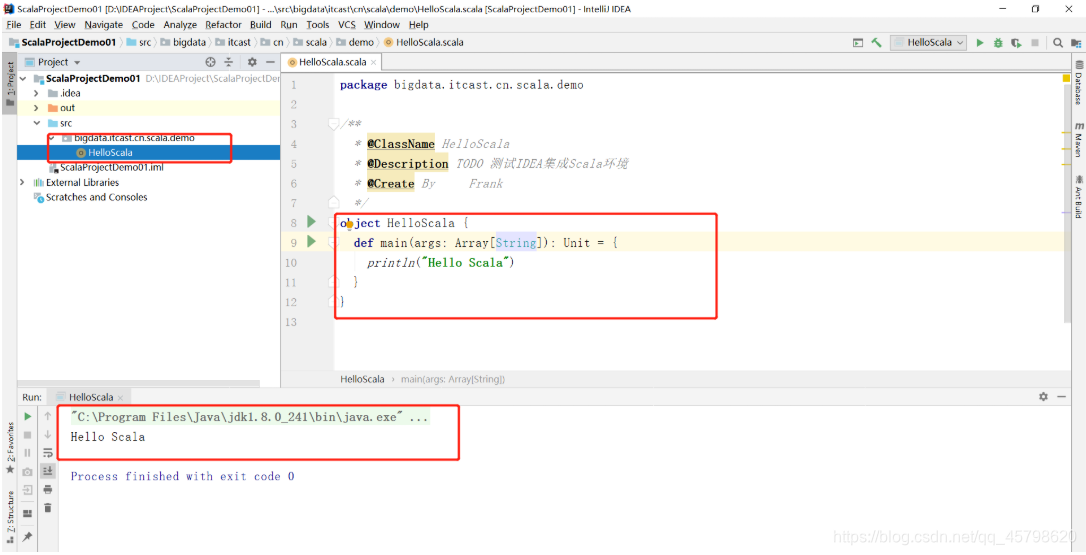
- 方式一:纯Scala工程:需要自己手动关联依赖包
-
方式二:Maven工程:自动管理依赖
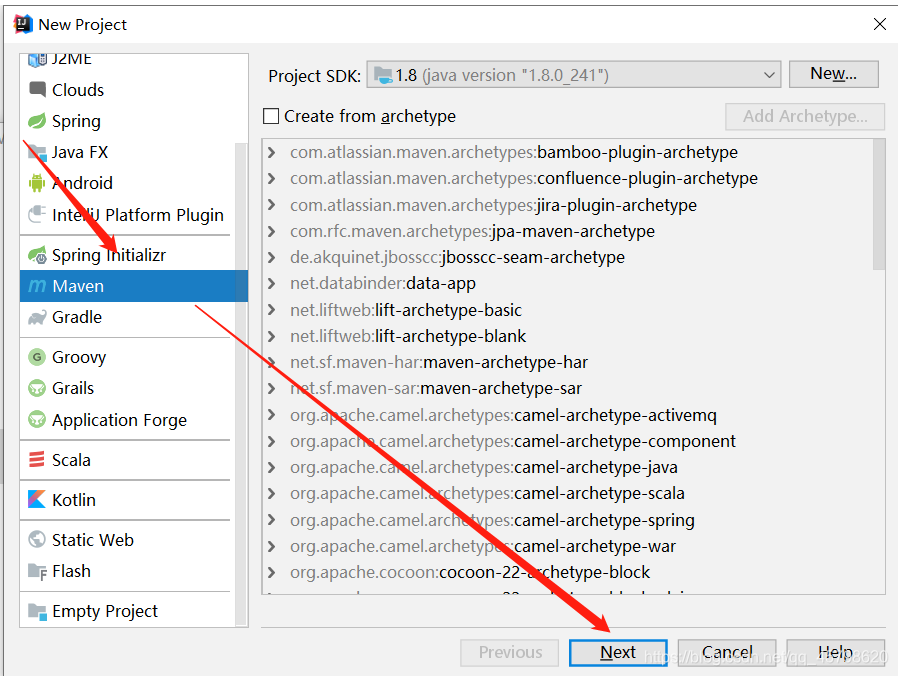
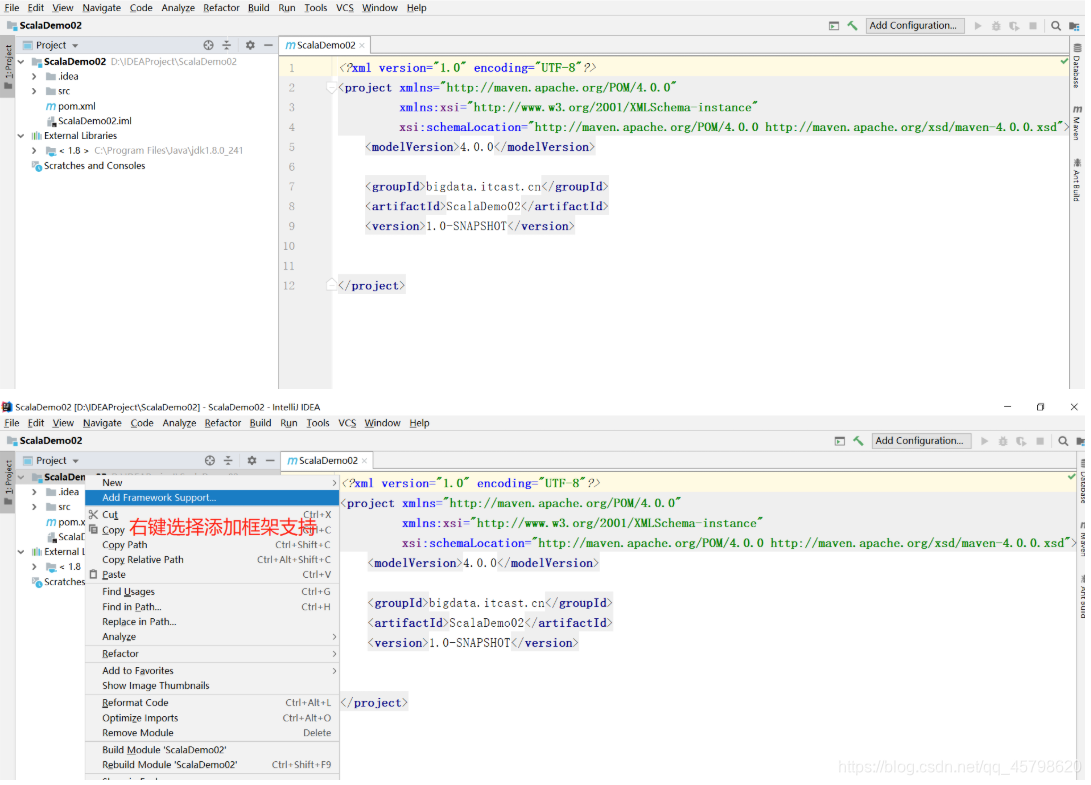
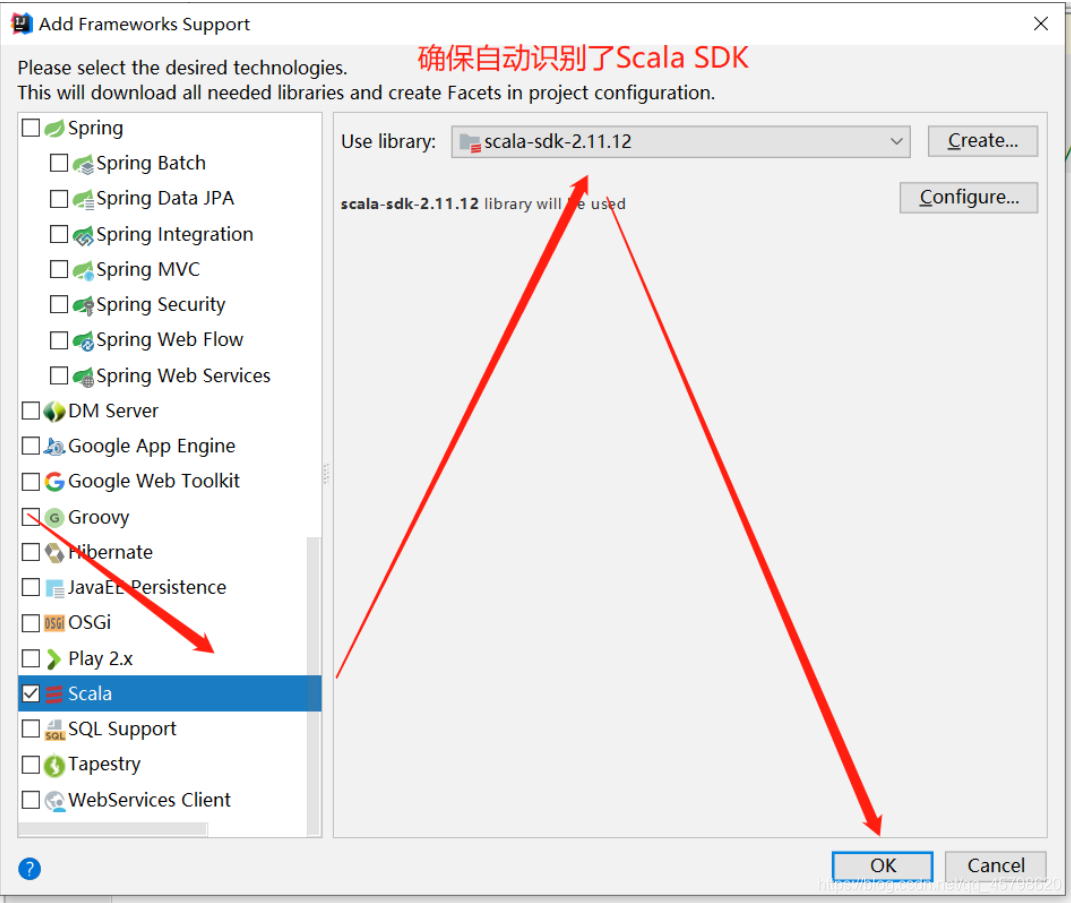
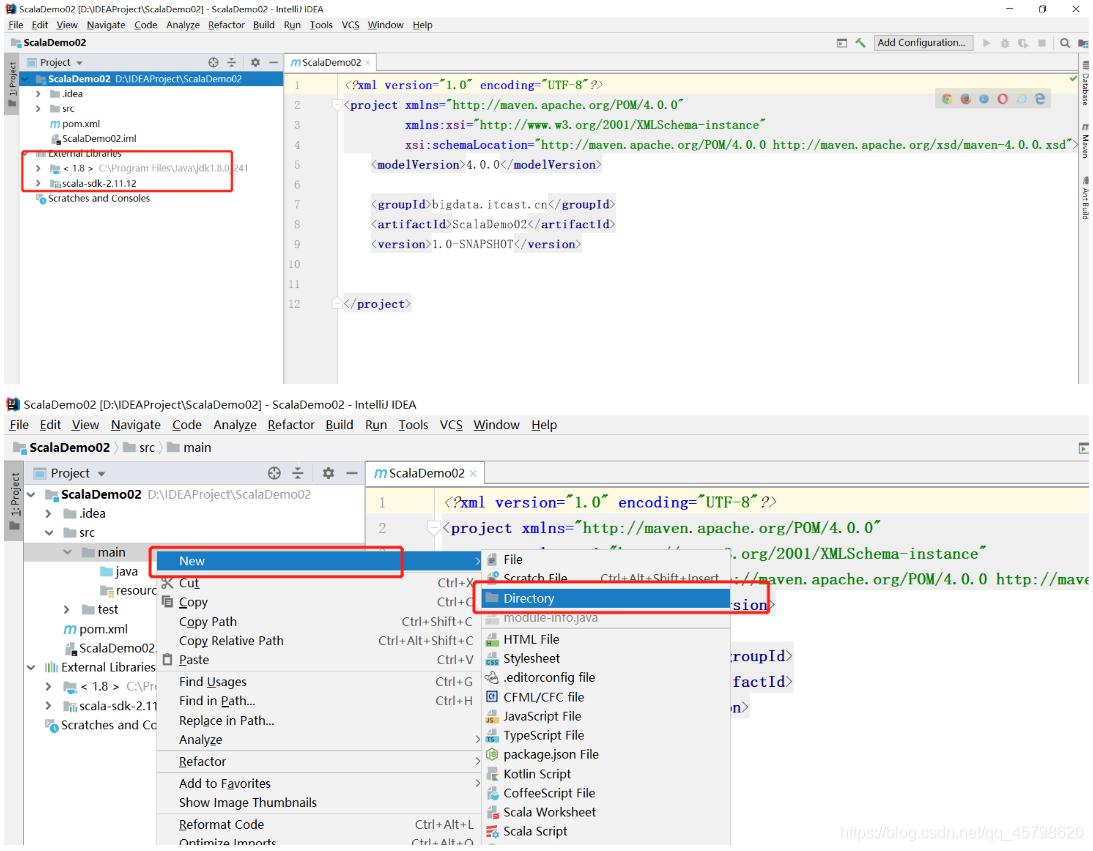
基础语法:变量及常量
-
变量的定义语法及测试
-
功能:定义一个值可变的变量
-
语法
var 变量名称:数据类型 = 值 -
Scala中大多数场景下可以自动推断类型
-
-
常量的定义语法及测试
-
语法
val 常量名称:数据类型 = 值
-
-
初始值
-
语法
var 变量名称:数据类型 = _ -
注意
-
只能用于变量
-
必须指定类型,不能自动推断类型
-
-
-
惰性赋值
-
功能:构建一个常量时不直接赋值,只构建常量对象,当用到数据内容时,再真正赋值
-
设计:避免值初始化以后,如果不被调用,占用内存,通过lazy使用时再进行初始化分配
-
语法
lazy val 常量名称:数据类型 = 值
-
-
特点及注意事项
-
Scala代码不以分号结尾
-
Scala中大多数场景可以自动推断类型
-
Scala中推荐使用常量,不推荐使用变量:val
- 如果需要变量的场景怎么办?可以用多个常量来代替变量的
-
scala中名称在前、类型在后 中间以:分割
- scala中类型首字母大写,大小写敏感
-
大多数场合写可以省去类型不写,编译器可以自动推导
-
初始值不能用于常量,只能用于变量,并且必须指定数据类型
-
惰性赋值只能用于常量,不能用于变量
- 在scala中推荐使用val常量,可以使用函数式编程解决变量的问题
-
基础语法:数据类型
-
Scala中的数据类型
-
基本类型:Int、Double……
- 变量存储的是值
-
引用类型:String、集合、对象……
- 变量存储的是内存地址
-
-
Scala中的数据类型运算
-
运算符:+、-、*、/ 、% ……
-
本质:所有数据类型都是对象,所有数据类型的运算符都是这个对象的方法
-
-
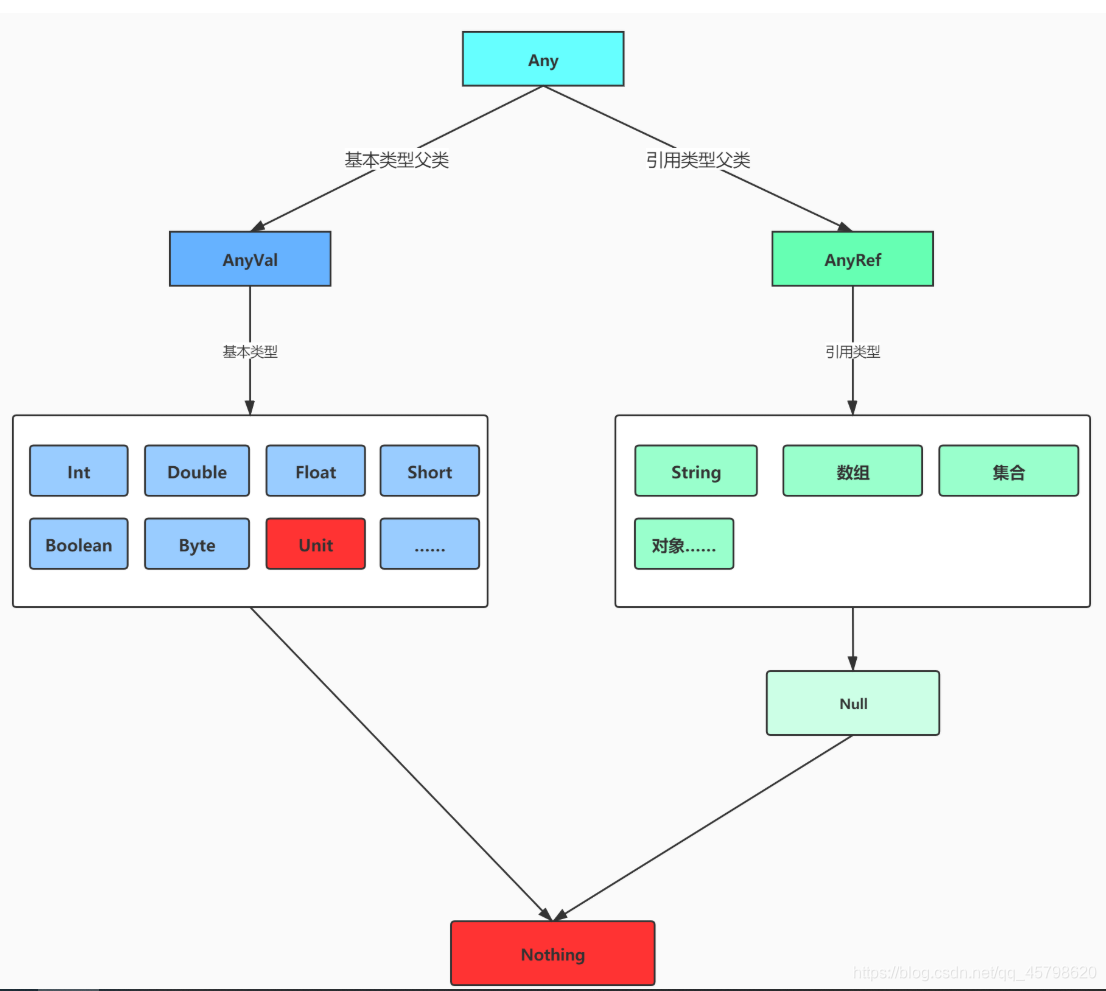
Scala中数据类型的层次结构
-
-
基本类型大体与Java中是一致的
-
Unit类似于Java中的void,没有任何实质性的意义,一般用于作为标识函数无返回值
-
Null类型是所有引用类型的子类
-
Nothing是所有类型的子类,一般用于作为函数返回值,用于明确的标识没有返回值
def name(args):Nothing= { 方法体 Nothing } -
父类:Any
- 基本类型
- unit:类似于void
- 引用类型
- null
- 基本类型
-
子类:Nothing
-
基础语法:字符串使用及插值表达式
-
字符串定义
-
双引号定义
-
三引号定义:用于比较长的字符串定义,可读性比较强
scala> val s2 = """ | select xxxxx | from xxxx | where xxxx | group by xxx | having xxxx | order by xxxx | limit xxx | """
-
-
字符串截取substring
scala> s1.substring(2) res9: String = cast -
字符串替换replaceAll
scala> s3.replaceAll(" ","-") -
字符串拼接
scala> s3.+(s1) res18: String = I likeitcast -
插值表达式的使用
-
功能:用于字符串拼接,可以在字符串中插入变量或者表达式
-
语法
s"${变量 | 表达式}"
-
基础语法:块表达式与if判断
-
块表达式
-
功能:用{}包裹多行代码的表达式,scala中使用最后一行作为表达式的返回值,如果表达式只有一行代码,{}可以省略
-
语法
{ 第一行代码 第二行代码 …… 表达式返回值 }
-
-
if判断
-
功能:用于实现代码中的判断分支逻辑
-
语法
if(表达式1){ 表达式1为true }else if(表达式2){ 表达式2为true }else if(表达式N){ 表达式N为true }else{ 都不满足 }
-
基础语法:for循环
-
Scala中for循环的语法
- Scala语法
for(i <- 集合/数值范围){ 循环逻辑 }
- Scala语法
-
Scala中构建数值范围表达式
scala> 1 to 10 或 1.to(10) res30: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> 1.until(10) res32: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9) -
for循环栗子
scala> for(i <- 1 to 10) {println(i)} -
守卫条件
-
功能:循环过程中实现数据过滤,增加循环条件,符合条件才会执行循环逻辑
-
优点:不是每次循环都会执行循环体,只有符合条件才执行循环体
-
语法
for(x <- 集合/数值范围 守卫条件表达式){ 循环逻辑 } -
栗子
scala> for(i <- 1 to 10 if i%2 == 0) {println(i)} 2 4 6 8 10
-
-
推导式yield
-
功能:在for循环后面加上表达式,针对循环的结果进行表达式的计算 ,计算结果组成一个新的集合
-
关键字:yield
-
语法
for(i <- 集合/数值范围) yield { 循环表达式 //计算表达式 }
- 栗子 ```scala scala> for(i <- 1 to 10) yield i*2 res40: scala.collection.immutable.IndexedSeq[Int] = Vector(2, 4, 6, 8, 10, 12, 14, 16, 18, 20) -
-
基础语法:while循环
-
语法
while(表达式){ 符合条件的循环逻辑 } do { 循环逻辑 } while( 表达式 );
基础语法:跳出循环Breaks
-
Scala中的continue与break
- Scala中的continue与break基于函数式编程的思想通过函数来实现
- 类:Breaks
- 方法:break()
- 语法:当遇到break方法时,跳出当前breakable的代码块
-
栗子
-
实现break
import scala.util.control.Breaks._ breakable{ for(i <- 1 to 10) { if(i >= 5) break() else println(i) } } -
实现continue
import scala.util.control.Breaks._ for(i <- 1 to 10){ breakable{ if(i == 5) break() else println(i) } }
-
方法的定义及语法规则
-
方法与函数的区别
- Java:不区分函数和方法,因为Java是面向对象的
public 返回值 方法名(参数){ 方法体 } -
方法:由方法名、参数、方法体构成,一般指的是类中定义的函数即为方法
-
函数:由函数名、参数、函数体构成,一般指的是可以独立构建的称为函数
-
Scala中定义方法的语法
def funcName(args1:Type1,args2:Type2……):ResultType = { //方法体 } -
栗子:定义一个方法,实现传递两个Int参数,返回两个数值之和
scala> def m1(a:Int,b:Int):Int = { | a + b | } -
规则
-
方法定义的关键字为def
-
如果方法体只有一行,{}可以省略
-
没有return关键字,使用方法体的最后一行【值或者表达式】作为返回值
-
大多数情况下返回值类型也可以自动推断,可以不写,递归方法除外
-
-
小结
-
方法与函数的区别?
- 类中定义的称为方法
- 与类没有关系的函数定义,称为函数
-
Scala中定义方法的语法?
def 方法名(参数):返回值类型 = { 方法体 } -
方法定义的规则?
- 关键字:def
- 没有return,用最后一行作为返回值
- 如果方法体只有一行,可以省略{}
- 大多数情况下,返回值类型可以不写,递归除外
-
方法的参数的使用
-
默认参数的方法定义
-
功能:在方法定义时,给定参数的默认值
-
语法
def funName(args1:Type1 = Value1,args2:Type2 = Value2 ……):ResultType = { //方法体 } -
栗子:定义一个方法,实现传递两个Int参数,返回两个数值之和
def m5(a:Int = 0,b:Int = 2) = a + b
-
-
默认参数的方法调用
scala> def m5(a:Int = 0,b:Int = 2) = a + b m5: (a: Int, b: Int)Int scala> m5(1,1) res15: Int = 2 scala> m5(1,6) --指定所有参数 res16: Int = 7 scala> m5() --使用两个参数的默认值 res17: Int = 2 scala> m5(1) --给第一个参数赋值,第二个参数使用默认值 res18: Int = 3 scala> m5(a=1) res19: Int = 3 scala> m5(b=1) res20: Int = 1 scala> m5(b=4,a=3) --指定参数赋值 res21: Int = 7 -
变长参数的方法定义
-
功能:用于定义方法时传递不定个数的参数
-
语法
def funName(args1:Type1 *):ResultType = { //方法体 } -
本质:将所有参数放入一个数组中,*表示多个
-
栗子:定义一个方法,实现传递1个或者多个Int参数,返回所有参数之和
scala> def m6(x:Int *) = x.sum m6: (x: Int*)Int scala> m6(1) res22: Int = 1 scala> m6(1,2) res23: Int = 3 scala> m6(1,2,4) res24: Int = 7
-
-
小结
- Scala方法中的默认参数的定义?
- 定义方法时,给参数指定默认值
- Scala方法中默认参数的调用?
- 方式一:按照顺序指定参数值
- 方式二:不指定参数值,使用默认值
- 方式三:根据参数名称指定参数的值
- Scala方法中变长参数的使用?
- 语法:*
- 本质:将所有参数放入一个数组中
- Scala方法中的默认参数的定义?
方法的调用形式
-
目标:掌握Scala中方法的三种调用形式
-
路径:Scala中的方法如何实现调用?
- 后缀调用法
- 中缀调用法/中缀表达式
- 花括号调用法
-
实施
-
后缀调用法:最常见的最常用的方式
-
语法
对象.方法(参数) -
栗子
scala> 1.to(10) res25: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> 1.until(10) res26: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
-
-
中缀调用法/中缀表达式
-
语法
对象 方法 参数 -
栗子
scala> 1 to 10 res27: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) scala> 1 until 10 res28: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
-
-
花括号调用法
-
语法
对象.方法{参数} -
栗子
scala> m7{1} res30: Int = 6 -
注意:只能用于单个参数的方法调用
scala> def m8(a:Int,b:Int) = a + b m8: (a: Int, b: Int)Int scala> m8(1,2) res31: Int = 3 scala> m8{1,2} <console>:1: error: ';' expected but ',' found. m8{1,2}
-
-
-
小结
- 后缀调用法?
- 语法:对象.方法(参数)
- 中缀调用法/中缀表达式?
- 语法:对象 方法 参数
- 花括号调用法?
- 语法:对象.方法{参数}
- 只能用于单个参数的方法
- 后缀调用法?
函数的定义及语法规则
-
目标:掌握Scala中函数的定义及其语法规则
-
路径:函数如何定义?函数的本质是什么?
- 函数的定义及语法
- 函数的使用规则
- 函数的本质
-
实施
-
函数的定义及语法
-
语法
(参数) => { //函数体 } -
栗子1:定义一个函数,传递两个Int参数,返回两个参数的和
scala> (x:Int,y:Int) => { x + y } res32: (Int, Int) => Int = <function2> scala> val str1 = "itcast" str1: String = itcast -
栗子2:定义一个函数,传递1个Int参数,返回参数值+5
scala> (x:Int) => x + 5 res33: Int => Int = <function1>
-
-
函数的使用规则
- 函数通过=>进行标记:用于区分方法【def】和函数
- 如果函数体只有一行,可以省略{}
- 没有return关键字,使用函数体的最后一行作为返回值
-
函数的本质
-
Scala中函数的本质就是对象,每个函数就是一个FunctionN类的实例,N表示参数个数
-
调用函数的本质是调用了这个对象的方法实现的
-
所以要定义、调用函数,必须指定参数列表,不然只是定义或者调用了这个对象,而不是这个对象的方法
scala> def m9() = 1 + 2 m9: ()Int scala> m9 --调用方法 res35: Int = 3 scala> m9() --调用方法 res36: Int = 3 scala> () => 1 + 2 res37: () => Int = <function0> scala> res37() --调用函数对象的方法 res38: Int = 3 scala> res37 --调用函数的对象 res39: () => Int = <function0>- 方法如果定义时没有参数,调用时可以不加括号
- 函数不论是否定义了参数,必须加括号
-
-
-
小结
-
函数的定义及语法?
(参数) => { 函数体 } -
函数的使用规则?
- 通过=>定义函数
- 如果函数体只有1行,可以省略{}
- 调用函数必须加上参数
- 没有return关键字,使用函数体的最后一行作为返回值
-
函数的本质?
- 本质是对象
- 构建一个有N个参数的函数,构建了一个FunctionN类的对象
- 调用函数本质调用了这个对象的方法
-
函数的分类
-
目标:掌握Scala中的函数的分类
-
路径:Scala中的函数分为几类?什么是匿名函数?什么是值函数?什么是高阶函数?
- Scala中函数的分类
- 匿名函数的定义及使用
- 值函数的定义及使用
- 高阶函数的定义及使用
-
实施
-
Scala中函数的分类
- 匿名函数、值函数、高阶函数
-
匿名函数的功能及定义
-
定义:定义一个函数,但不指定函数的名称
-
应用:一般用于作为高阶函数的参数
-
栗子
(x:Int,y:Int) => x + y
-
-
值函数的功能及定义
-
定义:定义一个函数,将这个函数赋值给一个变量或者常量,用于构建函数名称,调用函数
-
应用:一般用于定义函数名称
-
栗子
scala> val f1 = (x:Int,y:Int) => x + y f1: (Int, Int) => Int = <function2> scala> f1(1,2) res43: Int = 3
-
-
高阶函数的功能及定义
-
定义:如果使用函数值作为参数,或者返回值为函数值的“函数”和“方法”,均称之为“高阶函数”。
- 如果一个函数/方法A,它的参数是一个函数B,称A为高阶函数
-
应用:用于更加灵活的实现数据的处理
-
栗子:定义一个函数,用于根据需求实现两个数字的加、减、乘、除
-
传统写法
def f2(x:Int,y:Int,flag:Int){ if(flag == 1){ x + y }else if (flag == 2){ x - y } …… } -
高阶函数
def f3(p:(Int,Int) => Int):Int = { p(4,2) } val fa = (x:Int,y:Int) => x+y val fb = (x:Int,y:Int) => x-y val fc = (x:Int,y:Int) => x*y val fd = (x:Int,y:Int) => x/y f3(fa) --使用值函数作为参数 | f3((x:Int,y:Int) => x+y) --使用匿名函数作为参数
-
-
-
-
小结
- Scala中函数的分类?
- 匿名函数
- 值函数
- 高阶函数
- Scala中函数的分类?
-
匿名函数的功能及定义?
- 参数 => 函数体
- 值函数的功能及定义?
- val 名称 = 参数 => 函数体
- 高阶函数的功能及定义?
- 函数(函数) => 函数体
方法转换成函数
-
目标:掌握如何将方法转换为一个函数
-
路径:如何将定义的一个方法转换为一个函数,当做函数来使用呢?
- step1:创建两个方法,一个高阶函数m1,一个普通方法m2
- 希望使用m2作为m1的参数
- 问题:m2是方法,方法不是对象,不能作为参数,只有函数对象才能作为参数
- step2:将普通方法转换为函数f1
- step3:在高阶方法中传递函数f1
- step1:创建两个方法,一个高阶函数m1,一个普通方法m2
-
实施
-
step1:创建两个方法
-
高阶函数m1
scala> def m1(f:(Int,Int) => Int) : Int = { | f(4,2) | } m1: (f: (Int, Int) => Int)Int -
普通方法m2
scala> def m2(a:Int,b:Int) = a + b m2: (a: Int, b: Int)Int
-
-
step2:将m2由方法转换为函数
scala> val f1 = m2 _ f1: (Int, Int) => Int = <function2> -
step3:高阶函数中调用f1
scala> m1(f1) res58: Int = 6 scala> m1(m2) --Scala底层实现了隐式转换:自动转换类型 res50: Int = 6
-
-
小结
-
如何将定义的一个方法转换为一个函数,当做函数来使用呢?
val 函数名 = 方法名 _
-
数组与集合的分类
-
目标:了解Scala中数组与集合的分类以及应用场景
-
路径
- Scala中的集合和数组的分类
- 可变数组和可变集合
- 不可变数组和不可变集合
-
实施
-
Scala中的集合和数组的分类
- 可变:mutable
- 可变指的是元素的值或者长度是可变的
- 可变:mutable
-
不可变:immutable
- 不可变的指的是元素的值或者长度是不可变的
-
推荐使用不可变
- 工作场景经常需要做可变的集合
- 实现的时候
- 初始化:构建一个可变的
- 处理完成以后:转换为一个不可变的
-
可变数组和可变集合
-
可变:mutable,指的是数组或集合中的元素的值可变或者长度可变
-

-
库
scala.collection.mutable._- 数组
scala.collection.mutable.ArrayBuffer -
集合
scala.collection.mutable.ListBuffer scala.collection.mutable.Map scala.collection.mutable.Set -
不可变数组和不可变集合
- 不可变:immutable,指的是数组或集合中的元素的值不可变或者长度不可变

- 不可变:immutable,指的是数组或集合中的元素的值不可变或者长度不可变
-
-
库
scala.collection.immutable._ -
数组
scala.Array -
集合
scala.collection.immutable.List scala.collection.immutable.Map scala.collection.immutable.Set -
应用场景
- Scala中推荐使用不可变类型,所以默认构建的都为不可变类型,如果需要构建可变类型,需要提前手动导包
- 默认已经导入了所有不可变类型
-
如果业务中需要使用可变类型,一般最终也转换为不可变类型
-
-
小结
-
Scala中的集合和数组的分类?
- 可变:mutable
-
一般指的是元素的值或者长度可变
- 不可变:immutable
-
一般指的是元素的值或者长度不可变
-
可变数组和可变集合?
- ArrayBuffer
- ListBuffer
- mutable.Map
- mutable.Set
-
不可变数组和不可变集合?
- Array
- List
- immutable.Map
- immutable.Set
-
数组Array与ArrayBuffer
-
目标:掌握Scala中可变数组ArrayBuffer与不可变数组Array的使用
-
路径:ArrayBuffer与Array的区别是什么?如何使用Array和ArrayBuffer?
- ArrayBuffer与Array的区别
- Array的定义、赋值及取值
- ArrayBuffer的定义、赋值及取值
- 数组中的常用操作
-
实施
-
ArrayBuffer与Array的区别
- Array:数组长度不可变,定长数组
- ArrayBuffer:数组长度可变,变长数组
-
Array的定义、赋值及取值
-
定义
//用于指定数组长度,没有指定初始值,必须加new scala> val a1 = new Array[Int](5) a1: Array[Int] = Array(0, 0, 0, 0, 0) //指定了初始值可以不加new scala> val a2 = Array(1,2,3,4,5) a2: Array[Int] = Array(1, 2, 3, 4, 5) -
赋值
scala> a1(0) = 10 scala> a1 res1: Array[Int] = Array(10, 0, 0, 0, 0)-
Scala中引用下标使用圆括号
-
下标从0开始
-
-
取值
scala> a1(0) res2: Int = 10 scala> println(a1(0)) 10 scala> for(i <- a1 ) println(i) 10 0 0 0 0 scala> for(i <- a2 ) println(i) 1 2 3 4 5 scala> for(i <- 0.to(4) ) println(i) 0 1 2 3 4 scala> for(i <- 0.to(4) ) println(a2(i)) 1 2 3 4 5 scala> for(i <- 0.to(a2.length - 1) ) println(a2(i)) 1 2 3 4 5 scala> for(i <- a2.reverse ) println(i) 5 4 3 2 1 scala> for(i <- (a2.length - 1).to(0) ) println(a2(i)) scala> for(i <- (a2.length - 1).to(0,-1) ) println(a2(i)) 5 4 3 2 1 scala> for(i <- (a2.length - 1).to(0,-2) ) println(a2(i)) 5 3 1
-
-
ArrayBuffer的定义、赋值及取值
-
定义
scala> import scala.collection.mutable.ArrayBuffer import scala.collection.mutable.ArrayBuffer scala> val ab1 = new ArrayBuffer[Int]() ab1: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer() scala> val ab2 = ArrayBuffer(1,2,3) ab2: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3) -
增加:+=、append
scala> ab1 += 10 res13: ab1.type = ArrayBuffer(10) scala> ab1 += 9 res14: ab1.type = ArrayBuffer(10, 9) scala> ab1 += 7 res15: ab1.type = ArrayBuffer(10, 9, 7) scala> ab1.append(8) scala> ab1 res17: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 9, 7, 8) scala> a1 res18: Array[Int] = Array(10, 0, 0, 0, 0) -
赋值
scala> ab1(1) = 8 scala> ab1 res21: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 8, 7, 8) -
取值
scala> for(x <- ab1) println(x) 10 8 7 8 -
删除:-= 、remove
//按照值进行剔除 scala> ab1 -= 8 res23: ab1.type = ArrayBuffer(10, 7, 8) //按照下标剔除 scala> ab1.remove(1) res24: Int = 7 scala> ab1 res25: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 8)
-
-
数组中的常用操作
-
排序:sorted
scala> ab2.sorted res31: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 3, 5, 7, 10)
-
-
反转:reverse
scala> ab2.sorted.reverse res32: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 7, 5, 3, 3, 2, 1)-
求和:sum
scala> ab2.sum res33: Int = 31 -
最大:max
scala> ab2.max res34: Int = 10 -
最小:min
scala> ab2.min res35: Int = 1 -
转换为字符串:mkString
scala> ab2.mkString def mkString(sep: String): String def mkString: String def mkString(start: String,sep: String,end: String): String scala> ab2.mkString res38: String = 12373510 scala> ab2.mkString("-") res39: String = 1-2-3-7-3-5-10 scala> ab2.mkString(",") res40: String = 1,2,3,7,3,5,10 scala> ab2.mkString("<",",",">") res41: String = <1,2,3,7,3,5,10> scala> ab2.mkString("<","-",">") res42: String = <1-2-3-7-3-5-10>
-
-
-
小结
-
ArrayBuffer与Array的区别?
- Array不可变:长度不可变
- ArrayBuffer可变:长度可变
-
Array的定义、赋值及取值?
new Array[类型](长度) Array(给定初始值) array(index) = value for(i <- array) -
ArrayBuffer的定义、赋值及取值?
new ArrayBuffer[类型]() ArrayBuffer(初始值) array +=/append array -=/remove array(index) = value for(i <- array) -
数组中的常用操作?
- 排序:sorted
- 反转:reverse
- 求和:sum
- 最大:max
- 最小:min
- 转换字符串:mkString
-
列表List与ListBuffer
-
目标:掌握Scala中List集合与ListBuffer的区别以及使用
-
路径:List与ListBuffer的区别是什么?List与ListBuffer如何使用?
- List集合的特点
- List与ListBuffer的区别
- List的定义、赋值及取值
- ListBuffer的定义、赋值及取值
-
实施
- List集合的特点
-
有序可重复的集合
-
List与ListBuffer的区别
- List:不可变的集合,长度和元素值都不可变
- ListBuffer:可变的集合,长度和元素值都可变
-
List的定义、赋值及取值
-
定义
scala> val list1 = List(1,2,3,4,5,6,6,1,2) list1: List[Int] = List(1, 2, 3, 4, 5, 6, 6, 1, 2) scala> list1(0) = 10 <console>:14: error: value update is not a member of List[Int] list1(0) = 10 ^-
值不可改变
-
取值
scala> list1(0) res44: Int = 1 scala> for(i <- list1) println(i) 1 2 3 4 5 6 6 1 2
-
-
ListBuffer的定义、赋值及取值
-
定义
scala> val listb1 = new ListBuffer[Int]() listb1: scala.collection.mutable.ListBuffer[Int] = ListBuffer() scala> val listb2 = ListBuffer(1,2,3,4,3,2,1) listb2: scala.collection.mutable.ListBuffer[Int] = ListBuffer(1, 2, 3, 4, 3, 2, 1) -
添加:+=、append
scala> listb1 += 1 res52: listb1.type = ListBuffer(10, 9, 8, 1) scala> listb1.append(3) scala> listb1 res57: scala.collection.mutable.ListBuffer[Int] = ListBuffer(10, 2, 8, 1, 3) -
赋值
scala> listb1(1) = 2 scala> listb1 res55: scala.collection.mutable.ListBuffer[Int] = ListBuffer(10, 2, 8, 1) -
删除:-=、remove
scala> listb1 -= 10 res58: listb1.type = ListBuffer(2, 8, 1, 3) scala> listb1.remove(0) res59: Int = 2 scala> listb1 res60: scala.collection.mutable.ListBuffer[Int] = ListBuffer(8, 1, 3) -
取值
scala> listb1(0) res61: Int = 8 scala> for(x <- listb1) println(x) 8 1 3
-
-
-
小结
-
List与ListBuffer的区别?
- List:不可变,值和长度都不可变
-
List的定义及取值?
val list = List(初始值) -
ListBuffer的定义、赋值及取值?
val listb = new ListBuffer[类型]() val listb = ListBuffer(初始值)
-
List于ListBuffer的常用操作
-
目标:掌握List与ListBuffer的常用操作
-
路径
- List的常用操作
- ListBuffer的常用操作
-
实施
-
List集合常用操作
-
取第1个元素:head
scala> list1.head res64: Int = 1 -
取除了第一个元素以外的元素:tail
scala> list1.tail res65: List[Int] = List(2, 3, 4, 5, 6, 6, 1, 2) -
取前N个元素:take
scala> list1.take(3) res66: List[Int] = List(1, 2, 3) -
取除了前N个元素以外的所有元素:drop
scala> list1.drop(3) res67: List[Int] = List(4, 5, 6, 6, 1, 2) -
定义一个空list集合:Nil
scala> val list2 = Nil list2: scala.collection.immutable.Nil.type = List()- 一般不用于存储数据,一般用于拼接元素构建集合
-
集合头部添加元素返回新的集合:+:、::
scala> list1.+:(10) res69: List[Int] = List(10, 1, 2, 3, 4, 5, 6, 6, 1, 2) scala> list1 res70: List[Int] = List(1, 2, 3, 4, 5, 6, 6, 1, 2) scala> 9::list1 res71: List[Int] = List(9, 1, 2, 3, 4, 5, 6, 6, 1, 2) -
集合尾部添加元素返回新的集合::+
scala> list1.:+(10) res72: List[Int] = List(1, 2, 3, 4, 5, 6, 6, 1, 2, 10) -
拼接两个集合的元素返回新的集合:++、:::
scala> list3:::list4 res73: List[Int] = List(1, 2, 3, 4, 3, 4, 5, 6) scala> list4:::list3 res74: List[Int] = List(3, 4, 5, 6, 1, 2, 3, 4) scala> list3 ++ list4 res75: List[Int] = List(1, 2, 3, 4, 3, 4, 5, 6) scala> list4 ++ list3 res76: List[Int] = List(3, 4, 5, 6, 1, 2, 3, 4) -
扁平化操作:将两层集合转换为一层集合:flatten
scala> val list5 = List(List(1,2),List(3,4),List(5,6)) list5: List[List[Int]] = List(List(1, 2), List(3, 4), List(5, 6)) scala> for(x <- list5) println(x) List(1, 2) List(3, 4) List(5, 6) scala> list5.flat flatMap flatten scala> list5.flatten res78: List[Int] = List(1, 2, 3, 4, 5, 6) -
拉链操作:zip、zipWithIndex
scala> val list6 = List(1,2,3,4) list6: List[Int] = List(1, 2, 3, 4) scala> val list7 = List("a","b","c","d") list7: List[String] = List(a, b, c, d) scala> list6.zip(list7) res79: List[(Int, String)] = List((1,a), (2,b), (3,c), (4,d)) scala> list7.zipWithIndex res80: List[(String, Int)] = List((a,0), (b,1), (c,2), (d,3))- 一般用于将List集合转换为Map集合
-
拉开操作:unzip
scala> val list8 = list6.zip(list7) list8: List[(Int, String)] = List((1,a), (2,b), (3,c), (4,d)) scala> list8.unzip res81: (List[Int], List[String]) = (List(1, 2, 3, 4),List(a, b, c, d)) scala> val list9 = list8.unzip list9: (List[Int], List[String]) = (List(1, 2, 3, 4),List(a, b, c, d)) scala> list9._1 res82: List[Int] = List(1, 2, 3, 4) scala> list9._2 res83: List[String] = List(a, b, c, d) -
并集:union
scala> list3.union(list4) res86: List[Int] = List(1, 2, 3, 4, 3, 4, 5, 6) -
交集:intersect
scala> list3.intersect(list4) res87: List[Int] = List(3, 4) -
差集:diff
scala> list3.diff(list4) res88: List[Int] = List(1, 2) scala> list4.diff(list3) res89: List[Int] = List(5, 6)
-
-
ListBuffer集合常用操作
scala> listb1.to to toBuffer toIterable toList toParArray toSet toString toVector toArray toIndexedSeq toIterator toMap toSeq toStream toTraversable-
转换为List:toList
scala> listb1.toList res91: List[Int] = List(8, 1, 3) -
转换为Array:toArray
scala> listb1.toArray res92: Array[Int] = Array(8, 1, 3)
-
-
-
小结
- List的常用操作?
- head
- tail
- take
- drop
- 合并集合:++,:::
- 添加元素:+:,:+,::
- flatten
- zip/zipWithIndex
- unzip
- union
- diff
- intersect
- ListBuffer的常用操作?
- toList
- toArray
- List的常用操作?
Set集合
-
目标:掌握Scala中Set集合的使用
-
路径:可变的Set与不可变Set的区别?Set集合的使用?
- Set集合的特点
- 可变Set集合与不可变Set的区别
- 不可变Set集合的定义与读取
- 可变Set集合的定义、赋值与读取
-
实施
-
Set集合的特点
- 无序不重复集合,一般用于实现数据的去重功能
-
可变Set集合与不可变Set的区别
- immutable.Set:不可变Set集合,长度不可变
- mutable.Set:可变Set集合,长度可变
-
不可变Set集合的定义与读取
-
定义
scala> val set1 = Set(1,2,3,4,4,2,1,3) set1: scala.collection.immutable.Set[Int] = Set(1, 2, 3, 4) -
取值
scala> for(i <- set1 ) println(i) 1 2 3 4 -
获取集合长度:size
scala> set1.size res100: Int = 4
-
-
可变Set集合的定义、赋值与读取
-
定义
scala> import scala.collection.mutable.Set import scala.collection.mutable.Set scala> val set2 = Set(1,2,3,4,4,2,1,3) set2: scala.collection.mutable.Set[Int] = Set(1, 2, 3, 4) -
添加:+=
scala> set2 += 4 res102: set2.type = Set(1, 5, 2, 3, 4) -
删除:-=
scala> set2 -= 2 res103: set2.type = Set(1, 5, 3, 4) -
读取
scala> for(i <- set2) println(i) 1 5 3 4
-
-
-
小结
-
Set集合的特点?
- 无序、不可重复
-
可变Set集合与不可变Set的区别?
- 不可变的Set集合长度不可变的
-
不可变Set集合的定义与读取?
val set = Set(初始值) -
可变Set集合的定义、赋值与读取?
//先导包 val set = Set(初始值)
-
Map集合
-
目标:掌握Scala中Map集合的使用
-
路径:可变Map与不可变Map的区别?Map集合的使用?
- Map集合的特点
- 可变Map与不可变Map的区别
- 不可变Map集合的定义、读取
- 可变Map集合的定义、添加、读取
-
实施
-
Map集合的特点
- 存储KeyValue格式数据的集合
- 作为大数据工程师:处理最多的数据结构类型:KV结构类型
-
可变Map与不可变Map的区别
- immutable.Map:不可变Map,不可添加、删除、更新元素
- mutable.Map:可变Map,可以添加、删除、更新元素
-
不可变Map集合的定义、读取
-
定义
scala> val map1 = Map("name" -> "laoda","age" -> "20","gender"->"male") map1: scala.collection.immutable.Map[String,String] = Map(name -> laoda, age -> 20, gender -> male) scala> val map2 = Map(("name","laoer"),("age","22"),("gender","female")) map2: scala.collection.immutable.Map[String,String] = Map(name -> laoer, age -> 22, gender -> female) -
读取
-
方式一:直接根据Key读取
scala> map1("name") res105: String = laoda scala> map1("name1") java.util.NoSuchElementException: key not found: name1 at scala.collection.MapLike$class.default(MapLike.scala:228) at scala.collection.AbstractMap.default(Map.scala:59) at scala.collection.MapLike$class.apply(MapLike.scala:141) at scala.collection.AbstractMap.apply(Map.scala:59) ... 32 elided- 一般不用,如果key不存在,会报错
-
方式二:使用get方法
scala> map1.get def get(key: String): Option[String] scala> map1.get("name") res107: Option[String] = Some(laoda) scala> map1.get("name").get res108: String = laoda scala> map1.get("name1") res109: Option[String] = None -
方式三:使用getOrElse方法
scala> map1.getOrElse("name1","null") res112: String = null scala> map1.getOrElse("name","null") res113: String = laoda -
方式四:循环挨个取值
scala> for(x <- map1) println(x) (name,laoda) (age,20) (gender,male) scala> for((key,value) <- map1) println(key+"\t"+value) name laoda age 20 gender male
-
-
-
可变Map集合的定义、添加、读取
-
定义
scala> import scala.collection.mutable.Map import scala.collection.mutable.Map scala> val map3 = Map(("name","laoer"),("age","22"),("gender","female")) map3: scala.collection.mutable.Map[String,String] = Map(age -> 22, name -> laoer, gender -> female) -
添加:+=
scala> map3 += "addr" -> "shanghai" res116: map3.type = Map(addr -> shanghai, age -> 22, name -> laoer, gender -> female) -
更新:=
scala> map3("addr") = "beijing" scala> map3 res120: scala.collection.mutable.Map[String,String] = Map(addr -> beijing, age -> 22, gender -> female) -
删除:remove
scala> map3.remove("name") res117: Option[String] = Some(laoer) scala> map3 res118: scala.collection.mutable.Map[String,String] = Map(addr -> shanghai, age -> 22, gender -> female) -
获取Key:keys
scala> map3.keys res121: Iterable[String] = Set(addr, age, gender) -
获取Value:values
scala> map3.values res122: Iterable[String] = HashMap(beijing, 22, female) -
遍历
for(x <- map3) println(x) for((key,value)<- map3) println(key+"\t"+value) for(key <- map3.keys) println(map3(key))
-
-
-
小结
-
Map集合的特点?
- 存储KeyValue对
-
可变Map与不可变Map的区别?
- 不可变Map不能修改值和不能添加元素
-
不可变Map集合的定义、读取?
val map = Map(key1->value1,key2->value2……) -
可变Map集合的定义、添加、读取?
import scala.collection.mutable.Map val map = Map(key1->value1,key2->value2……)
-
元组Tuple
-
目标:掌握Scala中元组的使用
-
路径:什么是元组?元组的使用方式和场景?
- 元组的功能和特点
- 元组的定义
- 元组的取值
-
实施
-
元组的功能和特点
- 功能:类似于数组,用于存储不同类型的元素的集合
- 区别
- 数组:数组中只能存储一种类型的元素
- 元组:元组中可以存储不同类型的元素
-
元组的语法
val/var tupleName = (元素1,元素2,元素3,元素4……) val/var tupleName = TupleN(元素1,元素2,元素3,元素4……元素N)-
举例
scala> val tuple1 = (1,2,"itcast",14.9,true) tuple1: (Int, Int, String, Double, Boolean) = (1,2,itcast,14.9,true) scala> val tuple2 = new Tuple3(1,2,"heima") tuple2: (Int, Int, String) = (1,2,heima) -
特殊:二元组就是KeyValue对
-
方法:swap:二元组特有的方法
- 将key和value的位置互换
-
元组最多只能有22个元素
-
-
元组的取值
-
通过tuple._N来引用元组中的元素(N从1开始)
-
举例
scala> tuple1._1 res126: Int = 1 scala> tuple1._2 res127: Int = 2 scala> tuple1._3 res128: String = itcast
-
-
-
小结
-
元组的功能和特点?
- 功能:用于存储不同类型的多个元素的值
- 特点:可以存储不同类型,保留对应的类型
-
元组的定义?
val tuple = (e1,e2,e3……) val tuple = new TupleN(N个元素) -
元组的取值?
- 下标从1开始
- 元组._下标
-
迭代器Iterator
-
目标:了解Scala中迭代器的使用
-
路径:
- Scala中如何对迭代器中的数据进行迭代?
-
实施
-
scala针对每一类集合都提供了一个迭代器(iterator)用来迭代访问集合
-
迭代器的两个基本方法
- hasNext:查询容器中是否有下一个元素
- next:返回迭代器的下一个元素,如果没有,抛出NoSuchElementException
-
举例
scala> val array = Array(1,2,3,4,5) array: Array[Int] = Array(1, 2, 3, 4, 5) scala> val itera = array.iterator itera: Iterator[Int] = non-empty iterator scala> while(itera.hasNext) println(itera.next) 1 2 3 4 5
-
-
小结
- Scala中如何对迭代器中的数据进行迭代?
- 基本与Java是一致的
- 通过hasNext判断,通过next方法取值
- 常用方法:toList等,用于实现迭代器的排序操作
集合高阶函数:map
-
目标:掌握集合高阶函数map的功能及用法
-
路径
- map函数的语法
- map函数的功能与应用场景
-
实施
-
map函数的语法
final def map[B](f: (A) ⇒ B): List[B] //map函数只有1个参数,这个参数是一个函数类型 f: (A) ⇒ B:f就是参数函数 //f有1个参数:A:代表集合中的每个元素 //f的返回值:B:B是A处理以后的返回值 List[A].map = List[B] A1 -> B1 A2 -> B2 …… -
map函数的功能
-
map函数用于将集合中的每个元素调用参数函数进行处理,并将每个元素处理的返回值放入一个新的集合中
-
集合中元素一对一的处理
-
处理逻辑:由传递的参数函数来决定了
-
f:A => B
val f = (A) => { //处理A逻辑 B }
-
-
-
一般用于集合数据处理,这是最常用的处理函数
-
栗子
-
需求一:对以下集合进行处理,返回集合中每个元素的平方
val list1 = List(1,2,3,4,5,6,7,8,9,10)scala> list1.map((numb) => { | println(numb) | numb*numb | }) 1 2 3 4 5 6 7 8 9 10 res0: List[Int] = List(1, 4, 9, 16, 25, 36, 49, 64, 81, 100) scala> list1.map(numb => numb*numb) res1: List[Int] = List(1, 4, 9, 16, 25, 36, 49, 64, 81, 100)- 函数中:如果参数只有1个,调用时花括号可以省略
-
需求二:对以下集合进行处理,返回集合中每个字符串并在字符串的后面拼接字符串长度
val list2 = List("hadoop","","hive","hue"," ")scala> list2.map(word => word+"-"+word.length) res3: List[String] = List(hadoop-6, -0, hive-4, hue-3, " -1")
-
-
-
小结
-
map函数的功能与应用场景?
- 功能:对集合中的每个元素调用参数函数来进行处理,将处理的结果放入一个新的集合返回
- 应用:对每个元素进行处理,需要返回值的场景
-
map函数的语法?
list.map(A=>B):List[B]
-
集合高阶函数:foreach
-
目标:掌握集合高阶函数foreach的功能及用法
-
路径
- foreach函数的语法
- foreach函数的功能与应用场景
-
实施
-
foreach函数的语法
final def foreach(f: (A) ⇒ Unit): Unit //foreach有1个参数,是一个函数f //f这个函数有1个参数:A:代表集合中的每个元素 //f这个函数没有返回值
-
-
foreach函数的功能与应用场景
-
用于将集合中的每个元素进行处理,但是没有返回值
-
一般用于将集合的数据进行输出或者保存:将数据结果打印或者写入外部文件系统
-
栗子
-
需求一:对以下集合进行处理,输出集合中的每个元素
val list1 = List(1,2,3,4,5,6,7,8,9,10)scala> list1.foreach(i => println(i)) 1 2 3 4 5 6 7 8 9 10 scala> list1.foreach(println(_)) 1 2 3 4 5 6 7 8 9 10 scala> list1.foreach(println) 1 2 3 4 5 6 7 8 9 10-
需求二:对以下集合进行处理,输出集合中每个字符串并在字符串的后面拼接字符串长度
val list2 = List("hadoop","","hive","hue"," ")scala> val list2 = List("hadoop","","hive","hue"," ") list2: List[String] = List(hadoop, "", hive, hue, " ") scala> list2.foreach(word => println(word+"\t"+word.length)) hadoop 6 0 hive 4 hue 3 1
-
-
-
小结
-
foreach函数的功能与应用场景?
-
功能:对集合中的每个元素进行处理,但是没有返回值
- 应用:一般用于输出或者保存数据
-
foreach函数的语法?
list.foreach(f:A => Unit):Unit
-
集合高阶函数:flatMap
-
目标:掌握集合高阶函数flatMap的功能及用法
-
路径
- flatMap函数的语法
- flatMap函数的功能
-
实施
-
flatMap函数的语法
final def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): List[B] //flatMap有1个参数f,是一个函数 //f这个函数有1个参数:A:集合中的每个元素 //f这个函数有返回值: GenTraversableOnce[B],对每个A处理以后返回的结果,是一个集合,集合中有多个元素B //flatMap返回值是:List[B]:将每个A返回的集合进行合并 基本原理:f:调用每个元素进行map处理,map返回值是List,每个元素放回一个集合,最终每个元素处理的结果:List[List[B]] flatMap会将这个List[List[B]] 变成List[B] -
flatMap函数的功能
- 对集合中的每个元素调用map函数进行处理,根据参数函数的处理逻辑,将返回值中的每个集合进行扁平化
- 只有需要做扁平化处理,才调用flatMap
- map:一对一
- flatMap:多对一
- 每个元素调用一次map,每个map返回一个集合,将所有集合中的元素合并到一个集合中
- 对集合中的每个元素调用map函数进行处理,根据参数函数的处理逻辑,将返回值中的每个集合进行扁平化
-
-
栗子
-
需求一:对以下集合进行处理,将所有数字合并到一个集合中
val m1 = Map("key1"->"1,2,3","key2"->"4,5,6","key3"->"7,8,9")scala> m1.values res11: Iterable[String] = MapLike(1,2,3, 4,5,6, 7,8,9)
scala> m1.values.foreach(println)
1,2,3
4,5,6
7,8,9scala> m1.values.flatMap(x => x.split(",")).foreach(println)
1
2
3
4
5
6
7
8
9
```-
需求二:对以下集合进行处理,将所有单词放入一个集合中
val list5 = List("hadoop spark"," spark","hive hbase ","hue hue spark"," hue ")scala> list5.flatMap(line => line.split(" ")) res14: List[String] = List(hadoop, spark, "", spark, hive, hbase, hue, hue, spark, "", hue) scala> list5.flatMap(line => line.trim.split(" ")) res15: List[String] = List(hadoop, spark, spark, hive, hbase, hue, hue, spark, hue)
-
-
小结
-
flatMap函数的功能?
- 对多层集合结构,进行降维处理,实现扁平化的操作
- 应用:扁平化
-
flatMap函数的语法?
def flatMap(A => List[B]):List[B]
-
集合高阶函数:groupBy
-
目标:掌握集合高阶函数groupBy的功能及用法
-
路径
- groupBy函数的语法
- groupBy函数的功能
-
实施
-
groupBy函数的语法
def groupBy[K](f: (A) ⇒ K): Map[K, List[A]] //groupBy传递一个参数f:函数参数 //f有一个参数:A:每个元素 5 (key,value) (tup1,tup2,tupe3) //f有一个返回值:K:按照谁分组 //groupBy返回值:Map[K, List[A]],每个KV代表一组 K:分组的那个组 V:List[A],符合K的所有A的集合 -
groupBy函数的功能
- 对集合中的元素按照指定的条件进行分组
-
栗子
-
需求一:对以下集合进行处理,按照奇偶数进行分组
val list3 = List(2,4,6,8,9,7,5,3,1)scala> list3.groupBy( x => x%2==0).foreach(println) (false,List(9, 7, 5, 3, 1)) (true,List(2, 4, 6, 8)) -
需求二:对以下集合进行处理,按照地区进行分组
val m2 = Map(1->"shanghai",2->"beijing",3->"jiangsu",4->"anhui",5->"beijing",6->"anhui",7->"anhui",8->"shanghai",9->"beijing",10->"beijing")scala> m2.groupBy(tuple => tuple._2).foreach(println) (jiangsu,Map(3 -> jiangsu)) (shanghai,Map(1 -> shanghai, 8 -> shanghai)) (anhui,Map(6 -> anhui, 7 -> anhui, 4 -> anhui)) (beijing,Map(5 -> beijing, 10 -> beijing, 9 -> beijing, 2 -> beijing))
-
-
-
小结
-
groupBy函数的功能?
- 功能:指定按照对应的值进行分组
- 应用:分组
-
groupBy函数的语法?
def groupBy(A => K):Map[(K,List[A])]
-
集合高阶函数:filter/filterNot
-
目标:掌握集合高阶函数filter和filterNot的功能及用法
-
路径
- filter函数的语法
- filter函数的功能
- filterNot函数的语法
- filterNot函数的功能
-
实施
-
filter函数的语法
def filter(p: (A) ⇒ Boolean): List[A] //filter函数传递1个参数:p:函数 //p的参数:A:每个元素 //p的返回值:Boolean,一般是表达式的结果 //filter的返回值:List[A] :所有符合表达式的元素的集合 -
filter函数的功能
- 用于实现对集合中的数据进行过滤,将符合条件表达式的数据放入一个新的集合返回
-
filterNot函数的语法
def filterNot(p: (A) ⇒ Boolean): List[A] -
filterNot函数的功能
- 用于实现对集合中的数据进行过滤,将不符合条件表达式的数据放入一个新的集合返回
-
栗子
-
需求一:对以下集合进行处理,返回集合中所有的偶数
val list1 = List(1,2,3,4,5,6,7,8,9,10)scala> list1.filter( x => x % 2 == 0) res20: List[Int] = List(2, 4, 6, 8, 10)
scala> list1.filterNot(x => x % 2 != 0)
res21: List[Int] = List(2, 4, 6, 8, 10) -
-
需求二:对以下集合进行处理,过滤掉所有不是单词的元素
val list2 = List("hadoop","","hive","hue"," ")scala> list2.filter(word => word.trim.length > 0) res22: List[String] = List(hadoop, hive, hue) scala> list2.filter(_.trim.length > 0) res23: List[String] = List(hadoop, hive, hue)
-
-
小结
-
filter函数的功能?
- 用于对集合元素的过滤,将符合条件的数据放入一个新的集合中
-
filter函数的语法?
def filter(A => 条件表达式):List[A] -
filterNot函数的功能?
- 用于对集合元素的过滤,将不符合条件的数据放入一个新的集合中
-
filterNot函数的语法?
def filterNot(A => 条件表达式):List[A]
-
集合高阶函数:sortWith/sortBy
-
目标:掌握集合高阶函数sortWith/sortBy的功能及用法
-
路径
- Scala中排序的函数
- sortWith函数的语法
- sortWith函数的功能
- sortBy函数的语法
- sortBy函数的功能
-
实施
-
Scala中的排序函数
- sorted:只能对数据进行整体升序排序
- sortWith:高阶函数
- sortBy:高阶函数,常用
-
sortWith函数的语法
def sortWith(lt: (A, A) ⇒ Boolean): List[A] //sortWith有一个参数:lt:函数 //lt传递两个参数:(A,A):每次取集合中两个元素来处理 //lt返回值:表达式的Boolean值:判断大小的条件 //sortWith的返回值:List[A]:根据判断构建有序的结果 -
sortWith函数的功能
- 对集合中的元素进行两两比较,实现排序
-
栗子
-
集合
val list3 = List(2,4,6,8,9,7,5,3,1) -
需求一:对集合进行升序排序
scala> list3.sortWith((a,b) => a < b ) res24: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9) -
需求二:对集合进行降序排序
scala> list3.sortWith((a,b) => a > b ) res25: List[Int] = List(9, 8, 7, 6, 5, 4, 3, 2, 1)
-
-
sortBy函数的语法
def sortBy[B](f: (A) ⇒ B)(implicit ord: math.Ordering[B]): List[A] //sortBy传递一个参数f:函数 //f的参数:A:集合中的每个元素 //f的返回值:B:按照A中的什么进行排序 //sortBy返回的是排序好的结果 -
sortBy函数的功能
- 对集合中的元素进行排序,按照参数函数的返回值进行排序
-
栗子
-
集合
val list3 = List(2,4,6,8,9,7,5,3,1) val list4 = List(("zhangsan",20,"male"),("lisi",30,"female"),("wangwu",19,"male"))-
需求一:对list3集合进行升序排序
scala> list3.sortBy(x => x) res26: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9) -
需求二:对list3集合进行降序排序
scala> list3.sortBy(x => -x) res27: List[Int] = List(9, 8, 7, 6, 5, 4, 3, 2, 1) -
需求三:对list4集合按照年龄进行升序排序
scala> list4.sortBy(tuple => tuple._2) res28: List[(String, Int, String)] = List((wangwu,19,male), (zhangsan,20,male), (lisi,30,female)) -
需求四:对list4集合按照年龄进行降序排序
scala> list4.sortBy(tuple => -tuple._2) res29: List[(String, Int, String)] = List((lisi,30,female), (zhangsan,20,male), (wangwu,19,male))
-
-
-
-
小结
-
Scala中排序的函数?
- sorted
- sortWith
- sortBy
-
sortWith函数的功能?
- 每次取集合中的两个元素进行比较排序
-
sortWith函数的语法?
def sortWith((A1,A2) => A1 < A2) -
sortBy函数的功能?
- 对所有元素按照指定的参数函数的返回值进行排序,默认只能升序,降序通过-来实现
-
sortBy函数的语法?
def sortBy(A => -A):List[A] -
排序只有List和Array才有的方法:如果是iterator或者Map集合要进行排序,先转换为List
-
集合聚合函数:reduce
-
目标:掌握集合聚合函数reduce的功能及用法
-
路径
- reduce函数的语法
- reduce函数的功能
- reduceLeft、reduceRight的功能与用法
-
实施
-
reduce函数的语法
def reduce(op: (A1, A1) ⇒ A1): A1 //reduce传递1个:op //op传递2个参数:(T, A) T:临时变量,用于存储中间结果,tmp的初始值为第一个元素 A:集合中的每个元素 //op返回值:A1:聚合的结果 //reduce返回值:A1:聚合的结果 -
reduce函数的功能
- 对集合中的元素进行聚合计算
-
栗子
-
需求一:对以下集合进行处理,计算所有元素之和
val list3 = List(2,4,6,8,9,7,5,3,1) -
需求二:对list3集合进行处理,计算所有元素的乘积
list3.reduce((tmp,item) => tmp*item) -
需求三:对list3集合进行处理,计算所有偶数之和
list3.reduce((tmp,item) => tmp+item) scala> list3.reduce((tmp,item) => { | println(s"tmp = ${tmp} item = ${item}") | tmp+item | }) tmp = 2 item = 4 tmp = 6 item = 6 tmp = 12 item = 8 tmp = 20 item = 9 tmp = 29 item = 7 tmp = 36 item = 5 tmp = 41 item = 3 tmp = 44 item = 1 res32: Int = 45 scala> list3.reduce(_+_) res35: Int = 45
-
-
reduceLeft、reduceRight的功能与用法
-
语法
def reduce(op: (A1, A1) ⇒ A1): A1 def reduceLeft(f: (B, A) ⇒ B): B def reduceRight(op: (A, B) ⇒ B): B
-
-
功能
- reduceLeft的功能与reduce是一致的:左边参数代表tmp临时值,右边参数代表元素,从左聚合到右
- reduceRight:右边参数代表tmp临时值,左边参数代表元素,从右聚合到左
-
栗子
list3.reduceLeft((tmp,item) => { println(s"tmp = ${tmp} item = ${item}") tmp+item }) list3.reduceRight((item,tmp) => { println(s"tmp = ${tmp} item = ${item}") tmp+item })
-
-
小结
-
reduce函数的功能
- 实现对集合中元素的自定义聚合
-
reduce函数的语法
def reduce(f:(T,A) => B):B T:临时变量,存储中间结果,第一次初始值为第一个元素 A:每个元素,从第二个元素开始取 B:所有A聚合的结果 -
reduceLeft、reduceRight的功能与用法
- reduceLeft:与reduce一致,第一个参数是tmp,第二个参数是item,从左往右聚合
- reduceRight:第一个参数是item,第二个参数是tmp,从右往左进行聚合
-
集合聚合函数:fold
-
目标:掌握集合聚合函数fold的功能及用法
-
路径
- fold函数的语法
- fold函数的功能
- fold函数与reduce函数的区别
-
实施
-
fold函数的语法
def fold(z: A1)(op: (A1, A1) ⇒ A1): A1 //fold:两个参数 //z:临时变量的初始值 //op:函数:聚合逻辑 (T,A) => B T:临时变量 A:集合中的每个元素 B:聚合的结果 -
fold函数的功能
- 对集合中的元素进行聚合计算,需要指定初始值
-
-
栗子
-
需求一:对以下集合进行处理
val list3 = List(2,4,6,8,9,7,5,3,1) -
需求二:对list3集合进行处理,计算所有元素的乘积
list3.fold(1)((tmp,item) => tmp*item) list3.fold(1)((tmp,item) => { println(s"tmp = ${tmp} item = ${item}") tmp*item }) -
需求三:对list3集合进行处理,计算所有元素之和/计算所有偶数之和
list3.fold(0)((tmp,item) => tmp+item) list3.fold(0)((tmp,item) => { if(item % 2 == 0) tmp+item else tmp }) -
fold函数与reduce函数的区别
- 比reduce多了一个初始值
-
-
小结
-
fold函数的功能?
- 实现集合中数据的聚合
-
fold函数的语法?
fold(Zero)((T,A) => T):T Zero:T的初始值 T:临时变量,存储计算的结果 A:每个元素 -
fold函数与reduce函数的区别?
- fold可以指定临时变量的初始值
- reduce中临时变量的初始值为第一个元素的值
-
面向对象:类的定义
-
目标:掌握Scala中类的声明及定义
-
路径:如何定义一个类?
- 类的定义
- 定义成员属性
- 定义成员方法
-
实施
-
类的定义
- 关键字:class
- 普通的类,通过new来构建类的实例
- 全局多例的:在一个程序中可以构建多个实例
-
成员属性的定义
- 直接在类的内部声明每个成员属性,可以为var类型也可以为val类型
- 注意:Scala中会自动为每个成员属性构建getter and setter方法,不用自己申明
- var有get and set
- val只有get,因为val不可变
-
成员方法的定义
- 与Java中定义普通的方法时一致的
- 只需要根据语法定义即可
-
构建模块
-
step1:先添加Scala模块支持
-
step2:创建一个scala目录,设置为root source
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9XxxwbJr-1618468616224)(20210412_Scala(五).assets/image-20210412092532808.png)]
-
-
代码实现
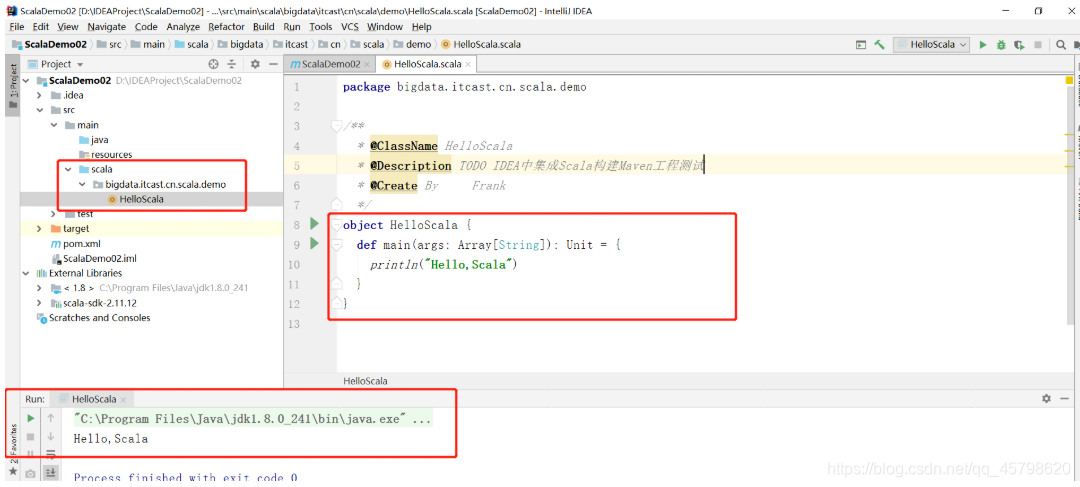
/** * @ClassName Person * @Description TODO 构建一个Scala Class,定义成员属性和成员方法 * @Date 2021/4/12 9:26 * @Create By Frank */ class Person { //定义成员属性 var name:String = "itcast" var age:Int = 20 var gender:String = _ val country:String = "China" //定义成员方法 def sayWhat() = println("What the hell ?") }
-
-
小结
- 如何定义一个类?
- 基本与Java一致
- 关键字:class
- 成员属性:所有成员属性会自动构建get and set方法,val只有get方法
- 成员方法:只要正常定义即可
面向对象:Object类的设计
-
目标:掌握Scala中Object类的设计
-
路径:为什么Class类中的main方法不能运行?Scala中Object是什么?
- JVM中类运行的规则
- Scala中Object的设计
-
实施
-
JVM中类运行的规则
-
从类的main方法开始运行
-
如果一个方法要被调用:必须通过类进行调用
-
普通类调用方法:new Class().method
-
静态的调用:Class.method
-
Java中怎么实现main方法的运行
public static void main(String[] args)- 当类被加载时,静态的方法也会被加载,所以可以直接从main方法开始运行
-
问题:Scala中没有static关键字
-
解决:Scala中通过特殊的类Object来实现
-
-
Scala中Object的设计
- Scala中一种特殊的类
- 全局只有唯一实例:单例类
- Object中定义所有属性和方法都是类似于静态的属性和方法
- main方法是程序运行的入口,必须被定义在object类中的
-
代码测试
/** * @ClassName Person * @Description TODO 构建一个Scala Class,定义成员属性和成员方法 * @Date 2021/4/12 9:26 * @Create By Frank */ class Person { //定义成员属性 var name:String = "itcast" var age:Int = 20 var gender:String = _ val country:String = "China" //定义成员方法 def sayWhat() = println("What the hell ?") } object TestPerson{ def main(args: Array[String]): Unit = { //构建Person类的实例 val person = new Person //给属性赋值 person.gender = "male" //调用对象的属性 println(person.name+"\t"+person.gender+"\t"+person.country) //调用对象的方法 person.sayWhat() } }
-
-
小结
- 为什么Class类中的main方法不能运行?
- 因为Scala中没有static关键字,定义的main方法不是静态的,不能运行
- 为什么Class类中的main方法不能运行?
-
Scala中Object是什么?
- 特殊类
- 全局唯一实例
- 所有定义的属性和方法都是静态的
- 运行程序的main方法必须定义在object中
- 特殊类
面向对象:Object构建工具类
-
目标:掌握Scala中利用Object的静态特性构建工具类实现
-
路径:如何调用类中的方法?如何使用Object构建工具类?
- 调用类中方法的两种方式
- 使用Object构建工具类
-
实施
-
调用类中方法的两种方式
- 静态类:ClassName.methodName
- 非静态:new ClassName().methodName
-
工具类
- 目的:用于将一些通用的方法定义在一个类中
- 字符串处理的工具类:StringUtils
- 截取
- 拼接
- 替换
- 反转
- 去除空白符:空格、空、制表符
- 查找
- ……
- 日期处理的工具类:SimpleDateFormat/FastDateFormat
- 格式转换
- 标准格式:yyyy-MM-dd HH:mm:ss:用于表示时间
- 时间戳:Long类型的值:用于时间计算
- 时间取值
- 取当前日期的前N天
- 取当前日期的后N天
- 取当前日期的属于哪一周
- 取当前日期的属于哪一季度
- 格式转换
- 字符串处理的工具类:StringUtils
- 实现
- 调用:xxxUtils.方法名
- 要求:方法必须为静态的
- 目的:用于将一些通用的方法定义在一个类中
-
使用Object构建工具类
/** * @ClassName Session * @Description TODO 实现Object构建工具类 * @Date 2021/4/12 10:20 * @Create By Frank */ class Session { } object SessionUtil{ //定义静态成员属性 var session = new Session //定义静态成员方法 def getSesssion() = this.session } object TestSession{ def main(args: Array[String]): Unit = { //todo:1-正常构建一个Session val s1 = new Session //todo:2-构建一个工具类来实现 val s2 = SessionUtil.session //Util.属性 val s3 = SessionUtil.getSesssion() //Util.方法 } }
-
-
小结
- Scala中通过Object来实现静态属性和静态方法的定义实现
- Object的应用?
- 运行main方法,作为程序入口
- 用于定义封装工具类的实现
面向对象:main方法使用
-
目标:掌握Scala中main方法的使用
-
路径:main方法的功能?main方法是如何定义的?
- main方法的功能
- main方法的定义及使用
-
实施
-
main方法的功能
- 作为整个程序的运行入口
-
main方法的定义及使用
-
方式一:显示定义
object TestMain01 { def main(args: Array[String]): Unit = { println(args(0)) println(args(1)) } } -
方式二:继承APP Trait
/** * @ClassName TestMain02 * @Description TODO 继承APP的特质来实现main方法的定义运行 * @Date 2021/4/12 10:29 * @Create By Frank */ object TestMain02 extends App { println("itcast") println("2021-05-01") }
-
-
-
小结
-
main方法的功能?
- 作为程序入口,程序从main开始运行
-
main方法的定义?
-
方式一:显示定义main方法
def main(args:Array[String]){ 方法体 } -
方式二:继承APP这个特质
-
-
面向对象:访问修饰符
-
目标:了解Scala中的访问修饰符规则
-
路径
- Scala中访问修饰符的规则
-
实施
-
修饰符类型
- public:所有类都可以看见
- protected:子类可见
- privite:自己可见
-
Scala中的规则
- 如果不显示的指定修饰符,默认所有的都为public
- 可以自己显示指定权限修饰符
-
修饰符的使用规则
修饰符 / 修饰符[访问域]-
访问域:包名或者this
-
栗子
private[cn] val name = "itcast"- 除访问域cn包以外的地方都是private的
-
-
代码测试
/** * @ClassName Dog * @Description TODO 实现权限的测试,指定修饰符和修饰符的作用域 * @Date 2021/4/12 10:38 * @Create By Frank */ class Dog { //属性 var name:String = "wangcai" private[this] val age:Int = 20 //方法 private[cn] def sayHello () = println("旺旺 ~ ") } object TestDog{ def main(args: Array[String]): Unit = { val dog = new Dog //访问属性 // println(dog.name+"\t"+dog.age) //访问方法 dog.sayHello() }
-
-
小结
- 基本与Java一致,默认不写全部为public类型,代码更加简洁
- 使用修饰符:指定作用域
- 作用域:this或者包名称
- 除了作用域以外的区域都是不可访问的
面向对象:伴生关系
-
目标:掌握Scala中伴生关系的概念及特点
-
路径:什么是伴生关系?
- 伴生关系的定义
- 伴生关系的特点
-
实施
-
伴生关系的定义
- 如果在一个Scala文件中,有一个Class和一个Object同名,那么这个Class和这个Object就互为伴生关系
- 称这个Class为这个Object的伴生类
- 称这个Object为这个Class的伴生对象
-
伴生关系的特点
- 可以彼此访问各自的私有域
-
代码测试
-
普通类访问对象的私有属性
class Cat { private var name:String = "Tom" var country:String = "China" private def sayHello() = println("Hello ~") def eatFish() = println("eating ………") } object TestCat{ def main(args: Array[String]): Unit = { val cat = new Cat println(cat.name + "\t"+cat.country) cat.eatFish() cat.sayHello() } } -
伴生对象访问类的私有属性
/** * @ClassName Cat * @Description TODO 测试伴生关系 * @Date 2021/4/12 10:50 * @Create By Frank */ class Cat { private var name:String = "Tom" var country:String = "China" private def sayHello() = println("Hello ~") def eatFish() = println(s"eating ${Cat.fishName}………") } object Cat{ private var fishName:String = "shark" def main(args: Array[String]): Unit = { val cat = new Cat println(cat.name + "\t"+cat.country) cat.eatFish() cat.sayHello() } }
-
-
-
小结
- 什么是伴生关系?
- 同一个Scala文件中,如果有一个Class与一个Object同名,互为伴生关系
- Class为Object的伴生类
- Object为Class伴生对象
- 伴生关系的特点是什么?
- 彼此可以访问对方的私有域
- 什么是伴生关系?
面向对象:回顾Java中的构造器
-
目标:回顾Java中如何定义构造器及其特点
-
路径
- Java中如何定义构造器?
- Java中构造器的分为几类?
- Java中构造器的特点是什么?
-
实施
-
Java中构造器的定义
- Java中的构造器是通过构造方法来实现的
- 可以定义多个构造方法来重载不同的构造
-
Java中构造器的分类?
- 无参构造:Java类的默认提供了一个午无参构造器,用于构造实例化对象
- 有参构造:在实例化构造时,可以通过参数传递给属性赋值
-
Java中构造器的特点
- 默认提供了无参构造
- 如果定义了有参构造会覆盖无参构造,如果需要无参构造,必须显示的定义无参构造
-
代码测试
package bigdata.itcast.cn.java.constructDemo; /** * @ClassName Pig * @Description TODO 回顾Java中的构造方式 * @Date 2021/4/12 11:15 * @Create By Frank */ public class Pig { //定义成员属性 private String name = "peiqi"; private int age = 5; public Pig() { } public Pig(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } class TestPig{ public static void main(String[] args) { Pig p1 = new Pig(); //赋值和取值 p1.setAge(10); System.out.println(p1.getName()+"\t"+p1.getAge()); //有参构造给属性赋值 Pig qiaozhi = new Pig("qiaozhi", 8); System.out.println(qiaozhi.getName()+"\t"+qiaozhi.getAge()); } }
-
-
小结
- Java中如何定义构造器?
- 通过构造方法来实现
- Java中构造器的分为几类?
- 无参构造
- 有参构造
- Java中构造器的特点是什么?
- 默认提供了无参构造
- 如果定义了有参构造就会覆盖无参构造,必须显示的定义无参构造
- Java中如何定义构造器?
面向对象:Scala中的主构造器
-
目标:掌握Scala中的主构造器定义及使用
-
路径
- Scala中构造器的分类
- Scala中主构造器的定义
-
实施
-
Scala中构造器的分类
- 主构造器:在类中嵌入的一个构造器,最基本的一个构造器
- 只有1个
- 辅助构造器:为了方便实现构造器的重载而设计的
- 根据重载,可以定义多个
- 主构造器:在类中嵌入的一个构造器,最基本的一个构造器
-
Scala中主构造器的定义
- 规则:放在类名后面使用圆括号定义构造器中传递的参数,并且参数自动作为类的成员变量,不需要在类中定义
- 特点
- 主构造器与类交织在一起,主构造器的参数列表写在类名的后面
- 在类的内部除了成员变量和成员方法,其他所有代码都属于主构造器的一部分
-
代码实现
class Person01(var name:String = "itcast",var age:Int ) { //成员属性 // var name:String = "itcast" //该属性在构造中被定义了,不需要重复定义 var country:String = "China" var gender:String = "male" // var age:Int = 19 //成员方法 def sayHello ()= println("Hello,Person ~") } object TestPerson01{ def main(args: Array[String]): Unit = { //在类名的后面定义传递的构造参数 val p1 = new Person01("heima",18) println(s"${p1.name} ${p1.country} ${p1.gender} ${p1.age}") p1.sayHello() //可以通过在主构造中指定默认值来实现无参构造实现 val p2 = new Person01(age = 18) println(s"${p2.name} ${p2.country} ${p2.gender} ${p2.age}") p2.sayHello() } }
-
-
小结
- Scala中构造器的分类?
- 主构造器
- 辅助构造器
- Scala中主构造器的定义?
- 将构造参数放在类名的后面通过圆括号进行定义
- 一旦在构造中定义,就不需要在类中进行定义,自动成为成员属性
- 构造中的参数可以有默认值
- Scala中构造器的分类?
面向对象:辅助构造器的使用
-
目标:掌握Scala中的辅助构造器定义及使用
-
路径
- 辅助构造器的规则是什么?
- 辅助构造器如何实现定义?
-
实施
-
辅助构造器的规则
- 所有辅助构造器由方法来实现的,名称固定为this,可以进行重载多个,用于不同成员属性的构造
- 所有辅助构造器的方法体的第一行必须调用主构造器或者已存在的辅助构造器
-
辅助构造器的定义
def this(参数列表){ //第一行必须调用主构造器或者已存在的辅助构造器 } -
代码实现
/** * @ClassName Person01 * @Description TODO 实现辅助构造器的定义 * @Date 2021/4/13 8:18 * @Create By Frank */ class Person01(var name:String = "itcast" ) { //成员属性 // var name:String = "itcast" //该属性在构造中被定义了,不需要重复定义 var country: String = "China" var gender: String = "male" var age: Int = 19 //成员方法 def sayHello() = println("Hello,Person ~") //定义辅助构造器:this方法 def this(name: String, country: String) { this(name) this.country = country } def this(name:String,country:String,age:Int){ this(name,country) this.age = age } } object TestPerson01{ def main(args: Array[String]): Unit = { //在类名的后面定义传递的构造参数 val p1 = new Person01("heima") println(s"${p1.name} ${p1.country} ${p1.gender} ${p1.age}") p1.sayHello() //可以通过在主构造中指定默认值来实现无参构造实现 val p2 = new Person01 println(s"${p2.name} ${p2.country} ${p2.gender} ${p2.age}") p2.sayHello() //调用辅助构造器进行构造 val p3 = new Person01("bigdata","巴基斯坦") println(s"${p3.name} ${p3.country} ${p3.gender} ${p3.age}") p3.sayHello() val p4 = new Person01("bigdata","巴基斯坦",100) println(s"${p4.name} ${p4.country} ${p4.gender} ${p4.age}") p4.sayHello() } }
-
-
小结
-
辅助构造器的规则是什么?
- 所有辅助构造器的名称必须叫this,通过定义方法来实现,可以通过重载多个辅助构造器
- 代码第一行必须调用主构造或者已经存在的辅助构造
-
辅助构造器如何实现定义?
def this(构造参数列表){ this(主构造或者辅助构造) }
-
面向对象:apply语法糖的功能及实现
-
目标:apply方法的功能及实现
-
路径
- apply方法的功能是什么?
- apply方法如何实现定义?
-
实施
-
问题
val a1 = Array(1,2,3,4,5,6) val a2 = new Array[Int](6)- 到底new不new?
-
apply方法的功能
- 可以在实现构建Class的实例的时候,不用写new关键字
-
apply方法的实现
- 在伴生对象Object中定义apply方法,支持重载,必须返回Class的实例
- 当不写new时,编译器会自动判断,在伴生对象中寻找对应的apply方法,通过apply方法new对象来实现
- 设计思想:缩短函数与对象的距离,让函数成为对象,让对象可以像函数一样使用
-
代码实现
class Person02(var name:String) { var age:Int = 20 //辅助构造 def this(name:String,age:Int){ this(name) this.age = age } } object Person02{ //传递一个参数,进行构造返回 def apply(name: String): Person02 = new Person02(name) //传递两个个参数,进行构造返回 def apply(name: String,age:Int): Person02 = new Person02(name,age) } object TestPerson02{ def main(args: Array[String]): Unit = { //通过正常的构造来实现对象构建 val p1 = new Person02("itcast") val p2 = new Person02("itcast",30) //通过语法糖来实现构造 val p3 = Person02("heima") val p4 = Person02("heima",40) } }
-
-
小结
- apply方法的功能?
- 在实例化Class的时候不用new关键字
- apply方法的实现?
- 在伴生对象中定义apply方法,可以重载实现,apply中实现new一个对象进行返回
- apply方法的功能?
面向对象:类的继承与重写
-
目标:掌握Scala中类的继承与重写
- 为什么要实现继承?
- Scala中如何实现类的继承?
- 如果要实现方法或者属性重写怎么办?
- 如何实现不允许子类重写或者访问?
-
路径
- 面向对象实现继承的设计
- Scala中实现类的继承
- Scala中实现方法和属性的重写
- Scala中实现不允许子类重写或者访问
-
实施
-
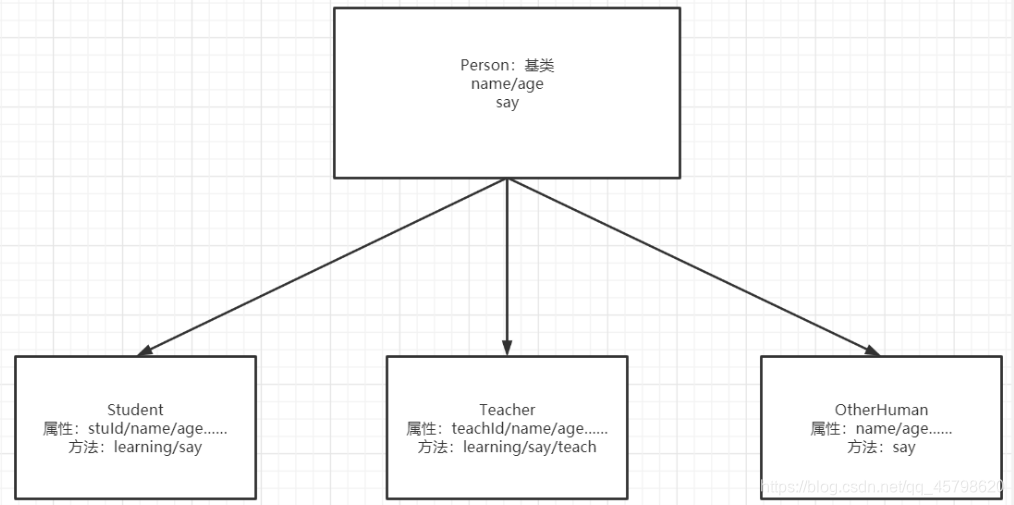
面向对象实现继承的设计
-
-
-
继承本质:决定了这类是什么
-
Scala中实现类的继承
-
关键字:extends
class Person03 { //共同的属性 var name:String = "itcast" val age:Int = 18 //共同的方法 def sayWhat = println("I am a Human") } class Student03 extends Person03{ //定义自己的属性 val stuid:String = "001" //定义自己的方法 def learning = println("I am Learning") } object TestPerson03{ def main(args: Array[String]): Unit = { val s1 = new Student03 println(s1.stuid)//自己的属性 s1.learning//自己的方法 println(s1.name+"\t"+s1.age) //父类的属性 s1.sayWhat //父类的方法 } } -
如果子类觉得父类的属性或者方法不好怎么办?
-
-
Scala中实现方法和属性的重写
class Student03 extends Person03{ //定义自己的属性 val stuid:String = "001" //定义自己的方法 def learning = println("I am Learning") //重写父类的属性 override val age: Int = 19 //重写父类的方法 override def sayWhat: Unit = println("I am a Student") }- 关键字:override
- super:表示调用父类的方法,不能调用父类的属性
- 注意:重写属性时,只能重写val常量,var变量不需要重写,直接修改即可
-
Scala中实现不允许子类重写或者访问
- 不允许重写:看的见,摸不着
- final:能看到以及调用,不允许重写
- 不允许访问:看不见
- private:不可以访问
- 不允许重写:看的见,摸不着
-
-
小结
- 为什么要实现继承?
- 为了定义类的自身的属性,实现通用属性的封装
- 将公共的属性和方法抽取成一个公共的父类,避免在所有的类中都重复定义
- Scala中如何实现类的继承?
- 继承关键字:extends
- 如果要实现方法或者属性重写怎么办?
- 关键字:override
- 重写属性只能重写val常量
- 如何实现不允许子类重写或者访问?
- final:可以访问,不可以重写
- private:不可以访问
- 为什么要实现继承?
面向对象:类型转换与类型判断
-
目标:掌握Scala中的类型转换与类型判断的方法及实现
- 如何实现子类转父类?
- 如何实现父类转子类?
-
路径
- 子类转父类的实现
- 父类转子类的问题
- 粗略类型判断与转换
- 精准类型判断与转换
-
实施
-
子类转父类的实现
-
定义一个子类,用一个父类对象指向即可
-
子类中包含了父类中所有的方法和属性,可以直接转换
//构建一个子类的实例,使用父类指向,只能调用父类的属性和方法 val s2: Person04 = new Student04 println(s2.name+"\t"+s2.age) s2.sayHello
-
-
父类转子类的问题
-
父类不能转换为子类,除非本身指向的就是一个子类的对象才可以实现
-
必须提前判断,如果不判断,会出现类型转换异常
//例如s2的情况:可以实现将s2转换为一个Student04的对象 s2.asInstanceOf[Student04] //类似于Java中 :Student04 s3 = (Student04)s2 //上面这种写法的前提是:明确的知道s2本质是一个Student04的对象
-
-
粗略类型判断与转换
-
isInstanceOf:用于判断是否是对应的类型
-
asInstanceOf:用于转换为对应的类型
-
-
判断与转换
//实际工作中进行强制类型转换时,先判断后转换,避免程序出错 if(s2.isInstanceOf[Student04]) { s2.asInstanceOf[Student04] } -
不精准
-
精准类型判断与转换
-
getClass:获取对象的类型
-
ClassOf:获取类的类型
-
判断与转换
if(s2.getClass == classOf[Student04]){ s2.asInstanceOf[Student04] } -
精准
-
-
完整代码
package bigdata.itcast.cn.scala.transDemo /** * @ClassName Person04 * @Description TODO * @Date 2021/4/13 9:34 * @Create By Frank */ class Person04 { var name:String = "itcast" var age:Int = 20 def sayHello = println("Hello,Person") } class Student04 extends Person04 { var stuId:String = "001" def sayBye = println("Bye ,Person") } object TestPerson04{ def main(args: Array[String]): Unit = { //构建一个子类的实例,使用子类指向,标准的student类型的对象 val s1: Student04 = new Student04 // println(s1.name+"\t"+s1.age) //父类的 // s1.sayHello // println(s1.stuId) //子类的 // s1.sayBye //构建一个子类的实例,使用父类指向,只能调用父类的属性和方法 val s2: Person04 = new Student04 // println(s2.name+"\t"+s2.age) // s2.sayHello //如何将一个父类转换为一个子类?:如果一个父类指向的是一个子类的对象才可以实现转换 //例如s2的情况:可以实现将s2转换为一个Student04的对象 // s2.asInstanceOf[Student04] //类似于Java中 :Student04 s3 = (Student04)s2 //上面这种写法的前提是:明确的知道s2本质是一个Student04的对象 //实际工作中进行强制类型转换时,先判断后转换,避免程序出错 // if(s2.isInstanceOf[Student04]) { // s2.asInstanceOf[Student04] // } //这种判断属于粗略的类型判断,不精确 // println(s2.isInstanceOf[Person04]) // println(s2.isInstanceOf[Student04]) // if(s2.getClass == classOf[Student04]){ // s2.asInstanceOf[Student04] // } println(s2.getClass == classOf[Person04]) println(s2.getClass == classOf[Student04]) } }
-
-
小结
- 如何实现子类转父类?
- 只要定义一个父类对象接收一个子类实例
- 如何实现父类转子类?
- 父类不能转子类,除非这个父类的对象指向的是一个子类的实例
- 模糊的判断方法?
- isInstanceOf
- 精准的判断方法?
- getClass == ClassOf【T】
- 强转
- asIntanceOf
- 如何实现子类转父类?
面向对象:抽象类的实现
-
目标:掌握Scala中抽象类的使用规则及实现
- 什么是抽象类?
- Scala中如何定义一个抽象类?
- Scala中如何实现抽象类的继承?
-
路径
- 抽象类的设计
- 抽象类的定义
- 抽象类的实现
-
实施
-
抽象类的设计
- 类的继承设计:从类的根源设计,封装所有共同的特性,提高代码的复用能力
- 普通的类:定义属性并赋值,定义方法并实现逻辑【给定方法体】,用于构建实例
- 抽象类:属性和方法只定义,不实现具体的值和逻辑
- 区别:不定义具体的内容就是抽象
- 具体的方法的处理逻辑和属性的值由子类自己根据需求来实现
-
抽象类的定义
- 关键字:abstract
- 如果只定义属性名称,不赋值,该属性叫做抽象字段
- 如果只定义方法名,不定义方法逻辑,该方法叫做抽象方法
- 包含抽象字段或者抽象方法的类叫做抽象类
abstract class Person05 { //具体的属性 // var name:String = "itcast" // var age:Int = 20 //抽象的属性 var name:String var age:Int //具体的方法 // def sayHello = println("Hello,Person ~") //抽象的方法 def sayHello } -
抽象类的实现
-
继承抽象类的子类要么实现所有抽象字段和抽象方法,要么自己本身也是抽象的
-
实现抽象属性和方法
class Stduent extends Person05 { override var name: String = "student" override var age: Int = 18 override def sayHello: Unit = println("Hello,Student ~") } -
继续抽象
abstract class Teacher extends Person05
-
-
-
小结
-
什么是抽象类?
- 抽象属性:只定义名称,不赋值
- 抽象方法:只定义方法名称,不定义逻辑
- 类中包含了抽象属性或者抽象的方法的类,称为抽象类
- 关键字:abstract
-
Scala中如何定义一个抽象类?
abstract class Name{ //抽象字段 //抽象方法 } -
Scala中如何实现抽象类的继承?
- 方式一:继承抽象类并实现所有抽象属性和方法
- 方式二:继承抽象类继续抽象
-
面向对象:匿名内部类
-
目标:了解Scala中匿名内部类的使用
-
路径
- 匿名内部类的本质
- 匿名内部类的定义语法
- 匿名内部类的实现
-
实施
-
匿名内部类的本质
- 一个没有名字的类,自动构建一个类继承抽象类或者接口,实现可以new一个抽象类或者接口
-
匿名内部类的定义语法
val 变量名称 = new 抽象类/Trait{ //重写属性或者方法 }- 直接new一个抽象类或者Trait的子类,重写方法后将对象赋值给一个变量
-
匿名内部类的实现
abstract class Person05 { //具体的属性 // var name:String = "itcast" // var age:Int = 20 //抽象的属性 var name:String var age:Int //具体的方法 // def sayHello = println("Hello,Person ~") //抽象的方法 def sayHello } //如果多次构建这个类的实例 class Stduent05 extends Person05 { override var name: String = "student" override var age: Int = 18 override def sayHello: Unit = println("Hello,Student ~") } object TestStudent05{ def main(args: Array[String]): Unit = { //正常通过构建子类的实例,来实现对抽象类的使用 val student = new Stduent05 student.sayHello //通过匿名内部类实现new 抽象类:一般用于临时的使用一次抽象类或者接口的方法 val person = new Person05 { override var name: String = "heima" override var age: Int = 10 override def sayHello: Unit = println("Hello, Person ~") } person.sayHello } }
-
-
小结
-
匿名内部类的本质?
- 没有名字的类,用于在构建抽象类或者接口时,构建类实现继承,重写方法即可
-
匿名内部类的语法?
val 变量名 = new 抽象类/Trait{ 重写方法 } -
Java中排序时:遇到的匿名内部类
list = 1,2,3,4,9,8,7 Collection.sort(list) //升序 Collection.sort(list,new Comparator{ public int compareTo(int a,int b){ } })
-
面向对象:Trait的定义及使用
-
目标:掌握Scala中Trait的定义及使用
- 什么是Trait?
- Trait如何定义?
- Trait如何使用?
-
路径
- Trait的设计及功能
- Trait的定义语法
- Trait的使用
-
实施
-
Trait的设计及功能
- Trait的设计类似于Java中Interface的设计,可以当做Java中的Interface来使用,但是比接口的功能更加强大
- 当Trait当做Interface来使用时,基本与Interface没有区别
-
Trait的定义语法
-
关键字:trait
-
定义
trait HelloTrait { //抽象方法 def sayHello } trait ByeTrait { def sayBye }
-
-
Trait的使用
-
关键字:extends
- Scala中类的继承和Trait的实现都使用extends来表示
-
实现多个关键字:with
class Person06 extends HelloTrait with ByeTrait with Serializable { //实现接口中的抽象方法 override def sayHello: Unit = println("Hello ~ Person") override def sayBye: Unit = println("Bye ~ Person") } object Person06{ def main(args: Array[String]): Unit = { val p1 = new Person06 p1.sayHello p1.sayBye } }
-
-
-
小结
-
什么是Trait?
- 特质,类似于Java中的接口的设计,用于代替java中的接口,但是功能比Java中的接口更加强大
-
Trait如何定义?
trait Name{ //抽象方法 } -
Trait如何使用?
- 第一个:extends
- 多个:extends Trait1 with Trait2……
-
面向对象:Trait实现工具类的封装
-
目标:实现用Trait封装工具类
- 为什么可以Trait封装工具类?
- Trait如何实现封装工具类?
-
路径
- Trait中的方法定义
- Trait实现封装工具类
-
实施
-
Trait中的方法定义
- 抽象方法:只定义方法名,没有方法体,没有实现逻辑
- 具体方法:定义了方法名和方法体,包含了实现逻辑
- Trait中既可以定义抽象方法,也可以定义具体方法
-
Trait实现封装工具类
-
在Trait中定义具体的方法,所有继承了该Trait的类都具有了该方法
- 构建一个工具类的父类:包含通用的工具方法
-
-
TimeUtils:时间字符串的剪切和拼接
-
URLUtils:剪切和拼接url
-
需求:构建一个Trait,实现切分字符串和拼接字符串
-
测试
trait StringUtilsTrait { //可以定义抽象方法和属性,当做接口来实现 //可以定义具体的方法和属性 def subStr(str:String,start:Int,len:Int):String = { str.substring(start,start+len) } def concatStr(sep:String,str:String *):String = { str.mkString(sep) } } object TimeUtils extends StringUtilsTrait {} object URLUtils extends StringUtilsTrait{} object TestTrait{ def main(args: Array[String]): Unit = { val str1 = "I" val str2 = "like" val str3 = "learning" println(TimeUtils.subStr(str3,0,5)) println(TimeUtils.concatStr("-",str1,str2,str3)) } }
-
-
-
小结
- 为什么可以Trait封装工具类?
- Trait包含了类和接口共同的特性,Trait中可以实现具体的方法和属性的定义
- Trait如何实现封装工具类?
- 只要工具类中的公共方法放入triat中具体定义即可
- 为什么可以Trait封装工具类?
面向对象:实例混入Trait
-
目标:掌握Scala中如何在实例中混入Trait的方法
- 什么是实例混入Trait?
- 实现的语法规则是什么?
- 如何实现将实例混入Trait?
-
路径
- 实例混入Trait的介绍
- 实例混入Trait的语法
- 实例混入Trait的实现
-
实施
-
实例混入Trait的介绍
-
实例混入Trait指的是为了解决相同类的不同实例继承不同Trait的问题
-
在构建同一个类的实例时,可以指定当前实例化的对象继承哪些Trait
-
正常的trait的继承:定义类的实现继承
class Person extends Trait class Person01 extends HelloTrait { override def sayHello: Unit = println("Hello Person") } object TestPerson01{ def main(args: Array[String]): Unit = { val p1 = new Person01 p1.sayHello val p2 = new Person01 p2.sayHello } } -
实例混入trait:指的是可以在构建对象的时候来实现继承Trait
-
-
实例混入Trait的语法
val 对象名称 = new 类 with Trait1 with Trait2 …… -
实例混入Trait的实现
-
需求1:对象1能sayHello,对象2不能
class Person01 {
}
object TestPerson01{
def main(args: Array[String]): Unit = {
val p1 = new Person01 with HelloTrait {
override def sayHello: Unit = println(“Hello”)
}
p1.sayHelloval p2 = new Person01 p2.sayHello //报错 }}
- 需求2:对象1能sayHello,对象2能sayBye ```scala class Person01 { } object TestPerson01{ def main(args: Array[String]): Unit = { val p1 = new Person01 with HelloTrait { override def sayHello: Unit = println("Hello") } p1.sayHello val p2 = new Person01 with ByeTrait { override def sayBye: Unit = println("Bye") } p2.sayBye } }-
需求3:对象1能sayHello,对象1和对象2都能sayBye,对象2能拼接字符串
class Person01 { } object TestPerson01{ def main(args: Array[String]): Unit = { val p1 = new Person01 with HelloTrait with ByeTrait { override def sayHello: Unit = println("Hello") override def sayBye: Unit = println("Bye") } p1.sayHello p1.sayBye val p2 = new Person01 with ByeTrait with StringUtilsTrait { override def sayBye: Unit = println("Bye") } p2.sayBye p2.concatStr("-","I","like") } } class Person01 extends ByeTrait { override def sayBye: Unit = println("Bye") } object TestPerson01{ def main(args: Array[String]): Unit = { val p1 = new Person01 with HelloTrait { override def sayHello: Unit = println("Hello") } p1.sayHello p1.sayBye val p2 = new Person01 with StringUtilsTrait p2.sayBye p2.concatStr("-","I","like") } }
-
-
-
小结
-
什么是实例混入Trait?
- 类中不指定trait的继承
- 在构建实例对象的时候指定不同的实例对象继承不同的Trait
-
实现的语法规则是什么?
val p1 = new Person with Trait1 with Trait2 ……
-
面向对象:Trait的构造机制及Trait继承Class
-
目标:掌握Scala中Trait的构造机制以及了解Trait继承Class的实现
- 当一个类继承多个Trait时,构造的顺序是什么样的?
- 如何实现让Trait继承Class?
-
路径
- Trait的构造器
- 类的基本构造顺序
- 复杂继承的构造顺序
- Trait继承Class的实现
-
实施
-
Trait的构造器
-
Trait不支持构造参数,但是每个Trait都有一个无参构造器
-
类中:除了成员属性和成员方法外,其他的所有代码都属于主构造器
class Person02(var name:String,var age:Int) { println("Start ……………………") //成员属性 var country :String = "China" //成员方法 def sayHello = println("Hello") println("End ……………………") } object Person02{ def main(args: Array[String]): Unit = { val itcast = new Person02("itcast",18) itcast.sayHello } }
-
-
类的基本构造顺序
-
从左到右依次执行继承的父类或者Trait的构造,再执行自身的构造
-
继承一个类
class Person02() { println("Start Person ……………………") println("End Person ……………………") } class Student02 extends Person02{ println("Start Student ……………………") println("End Student ……………………") } object Person02{ def main(args: Array[String]): Unit = { val student = new Student02 } } -
继承一个类和两个Trait
class Person02() { println("Start Person ……………………") } trait HelloTrait1 { println("Start HelloTrait ……") } trait ByeTrait1 { println("Start ByeTrait ……") } class Student02 extends Person02 with HelloTrait1 with ByeTrait1 { println("Start Student ……………………") } object Person02{ def main(args: Array[String]): Unit = { val student = new Student02 } }
-
-
复杂继承的构造顺序
-
如果一个类继承多个Trait,而Trait又继承父Trait,先构造父Trait,再构造子Trait
-
如果多个子Trait的父Trait相同,则父Trait只构造一次
-
继承关系
-
-
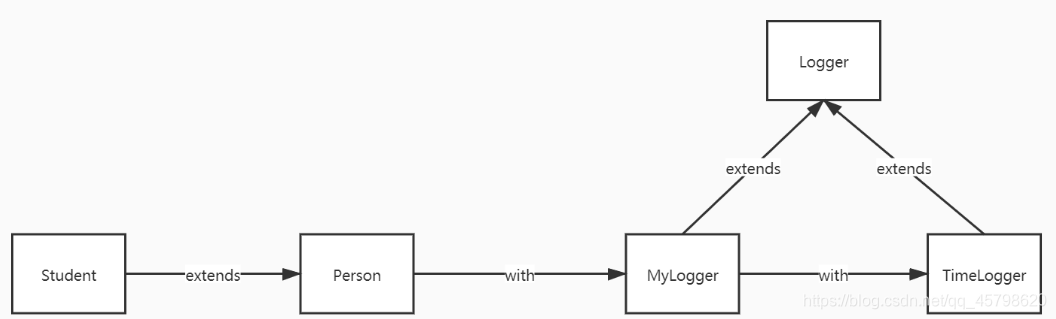
```scala
class Student extends Person with MyLogger with TimeLogger
Trait MyLogger extends Logger
Trait TimeLogger extends Logger
```
- 构造顺序
```scala
class Person02() {
println("Start Person ……………………")
}
trait Logger{
println("Strat Logger ……")
}
trait MyLogger extends Logger {
println("Start MyLogger ……")
}
trait TimeLogger extends Logger {
println("Start TimeLogger ……")
}
class Student02 extends Person02 with MyLogger with TimeLogger {
println("Start Student ……………………")
}
object Person02{
def main(args: Array[String]): Unit = {
val student = new Student02
}
}
```
-
Trait继承Class的实现
-
class extends Trait:类继承Trait
-
trait extends Class:Trait继承类
class Person03 { def sayWhat = println("I like leanring") } trait PersonTrait extends Person03{ def sayBye } class Student extends PersonTrait{ override def sayBye: Unit = println("bye") } object Stduent{ def main(args: Array[String]): Unit = { val student = new Student student.sayBye student.sayWhat } }- 如果一个类的实例调用了一个方法
- 这个方法不在这个类中,也不在实现的接口中,可能在接口的父类中
-
-
小结
- 当一个类继承多个Trait时,构造的顺序是什么样的?
- 基本:从左往右依次构造,最后构造自己
- 特殊:如果继承的Trait有父Trait,先构造父Trait,再构造子Trait
- 如果子Trait的父Trait是同一个,父Trait只构造一次
- 如何实现让Trait继承Class?
- 与正常的继承是一致的
- 当一个类继承多个Trait时,构造的顺序是什么样的?
模式匹配:内容匹配
-
目标:掌握Scala中的模式匹配的功能及语法
- 什么是模式匹配?
- 如何实现模式匹配?
-
路径
- 模式匹配的功能
- 模式匹配的语法
-
实施
-
模式匹配的功能
-
类似于Java中的switch case,对代码中的内容进行判断,根据判断匹配对应的结果
-
但是功能比Java中的switch case的功能更加强大,可以匹配内容、类型等多种条件
-
Java中的switch case的语法
switch (变量) { case value1: op1 break; case value2 op2 break; …… default opN; }package bigdata.itcast.cn.java.swithCaseDemo; import java.util.Scanner; /** * @ClassName SwitchDemo * @Description TODO 测试 Java 中的 switch case * @Date 2021/4/13 12:51 * @Create By Frank */ public class SwitchDemo { public static void main(String[] args) { System.out.println("问:你正在打游戏,队友正喊你团一波,这时候你女朋友掉水里的,请问你怎么选?"); System.out.println(" A:继续跟团,不能坑队友"); System.out.println(" B:救女朋友,对象不好找"); System.out.println(" C:不选择,换个游戏也换个女朋友"); System.out.print("请输入你的选项【A/B/C】:"); //构建输入器 Scanner scanner = new Scanner(System.in); //读取用户输入 String input = scanner.next(); //判断输入 switch (input){ case "A": System.out.println("U r a bad man"); break; case "B": System.out.println("U r a good man"); break; case "C": System.out.println("U r a not man"); break; default: System.out.println("U hava no choice"); } } }
-
-
模式匹配的语法
- 功能比switch case功能要强大,当做switch case来使用
- 语法:match case
变量 match { case value1 => operater1 case value2 => operater2 …… case valueN => operaterN [case _ => default Operator] } -
匹配内容实现
object MatchCaseDemo1 { def main(args: Array[String]): Unit = { //输出问题 println("问:你正在打游戏,队友正喊你团一波,这时候你女朋友掉水里的,请问你怎么选?"); println(" A:继续跟团,不能坑队友"); println(" B:救女朋友,对象不好找"); println(" C:不选择,换个游戏也换个女朋友"); print("请输入你的选项【A/B/C】:"); //读取用户输入 val input = StdIn.readLine() //匹配input的值 input match { case "A" => println("U r a bad man") case "B" => println("U r a good man") case "C" => println("U r a not man") case _ => println("U have not a choice") } } }- 与Java中switchcase的区别
- match case可以实现匹配内容,但不局限于匹配内容
- 每个case中,没有break,一旦匹配成功,自动跳出
- 没有default选项,一般通过 _ 来表示任意内容,代替default,下划线放到最后
-
-
小结
-
什么是模式匹配?
-
类似于Java中的switch case,但是功能更加强大
-
如何实现模式匹配?
变量 match { case v1 => op1 case v2 => op2 …… case _ => opN }
-
模式匹配:类型匹配及守卫条件
-
目标:掌握Scala中模式匹配类型及守卫条件的实现
-
路径
- 模式匹配类型实现
- 守卫条件的实现
-
实施
-
模式匹配类型实现
-
功能:判断变量的类型,根据不同类型实现不同的操作
-
应用:一般用于实现异常捕获
object MatchCaseDemo2 { def main(args: Array[String]): Unit = { //定义一个数组 val arr = Array(1,2,true,14.98,"itcast") //取出元素,输出对应的元素的值和类型 val input = arr(Random.nextInt(arr.length)) input match{ case x:Int => println(s"type:Int,value:${x}") case y:Double => println(s"type:Double,value:${y}") case m:String => println(s"type:String,value:${m}") case n:Boolean => println(s"type:Boolean,value:${n}") case _ => println("这是其他类型") } } }
-
-
守卫条件的实现
-
在匹配时,可以指定匹配条件,如果不满足匹配的守卫条件,依旧不会匹配成功
object MatchCaseDemo2 { def main(args: Array[String]): Unit = { //定义一个数组 val arr = Array(1,2,true,14.98,"itcast") //取出元素,输出对应的元素的值和类型 val input = arr(0) input match{ case x:Int if (x > 1) => println(s"type:Int,value:${x}") case y:Double => println(s"type:Double,value:${y}") case m:String => println(s"type:String,value:${m}") case n:Boolean => println(s"type:Boolean,value:${n}") case _ => println("这是其他类型") } } }
-
-
-
小结
- 如何实现类型的匹配?
- 在case的时候指定传递的元素的类型,如果符合类型就会匹配
- 什么是守卫条件?
- 如果符合类型,在实现处理之前可以做过滤,如果不符合条件,将匹配不成功
- 如何实现类型的匹配?
模式匹配:数组、集合、元组匹配
-
目标:了解如何对数组、集合、元组进行模式匹配
-
路径
- 模拟匹配数组
- 模式匹配集合
- 模式匹配元组
-
实施
-
模拟匹配数组
object MatchCaseDemo3 { def main(args: Array[String]): Unit = { //定义一个数组 val arr: Array[Int] = Array(1,4,7) //匹配数组 arr match{ case Array(0) => println(s"这个数组中只有一个元素,为0") case Array(1,2,3) => println(s"这个数组中有三个个元素,为1,2,3") case Array(1,x,y) => println(s"这个数组中有三个个元素,第一个元素肯定为1") case Array(0,_*) => println(s"这个数组中有多个元素,第一个元素肯定是0") case _ => println("这是其他类型数组") } } } -
模式匹配集合
object MatchCaseDemo3 { def main(args: Array[String]): Unit = { //定义一个数组 val list = List(
-
1,2)
//匹配数组
list match{
case List(1,2) => println(s"只有两个元素,为1,2")
case x::y::Nil => println(s"只有两个元素,元素值任意")
case 1::Nil => println(s"只有1个元素,元素值1")
case 1::tail => println(s"第一个元素是1,其他的元素是任意的")
case _ => println(“这是其他类型”)
}
}
}
```
-
模式匹配元组
object MatchCaseDemo3 { def main(args: Array[String]): Unit = { //定义一个数组 val tuple = (3,3,3) //匹配数组 tuple match{ case (1,2,x) => println(s"元素的值为1,2和任意一个") case (x,3,z) => println(s"第二个元素值必须为3") case (x,y,z)=> println(s"元素值任意") case _ => println("这是其他类型") } } } -
小结
- 只需要对数组、集合、元组中的值按照顺序进行匹配即可
模式匹配:声明变量匹配取值
-
目标:掌握Scala中如何在申明变量时进行匹配取值
- 什么是声明变量匹配取值?
- 如何实现声明变量匹配取值?
-
路径
- 数据处理时的常见问题
- 声明变量取值的设计
- 声明变量取值的实现
-
实施
-
数据处理时的常见问题
-
如果有一个Array数组,总共4个元素,我们需要取出数组中的每个元素,单独处理,怎么取?
val array = Array(100,20,40,30) //sum,avg,max,minsum = array(0) avg = array(1) max = array(2) min = array(3) for(i <- array) -
如果有一个List集合,每个元素都由4个字段构成,我想取出每个元素中的第二列和第三列,怎么取?
val list = List("1 zhangsan 18 male","2 lisi 20 female","3 wangwu 22 male")list.map(line => { val arr = line.split(" ") val name = arr(1) val age = arr(2) (name,age) }) -
如果有一个Map集合,每个元素的Value是二元组类型,格式为:(id,(name,age)) 要取出三列,怎么取?
val map = Map((1,("zhangsan",18)),(2,("lisi",20)),(3,("wangwu",22)))map.foreach(tuple => { val id = tuple._1 val name = tuple._2._1 val age = tuple._2._2 println(id+"\t"+name+"\t"+age) })
-
-
声明变量取值的设计
- 可以通过申明变量的形式与数据进行匹配,将匹配的结果直接赋值给对应的变量
-
声明变量取值的实现
-
如果有一个Array数组,总共4个元素,我们需要取出数组中的每个元素,单独处理,怎么取?
val array = Array(100,20,40,30)val Array(sum,avg,max,min) = array -
如果有一个List集合,每个元素都由4个字段构成,我想取出每个元素中的第二列和第三列,怎么取?
val list = List("1 zhangsan 18 male","2 lisi 20 female","3 wangwu 22 male")list.map(line => { val Array(_,name,age,_) = line.split(" ") (name,age) }) -
如果有一个Map集合,每个元素的Value是二元组类型,格式为:(id,(name,age)) 要取出三列,怎么取?
val map = Map((1,("zhangsan",18)),(2,("lisi",20)),(3,("wangwu",22)))map.foreach{ case (id,(name,age)) => println(id+"\t"+name+"\t"+age) }
-
-
-
小结
- 在集合中取值时,需要将每个元素赋值给变量时,可以在声明变量时按照数据的格式进行匹配直接赋值
样例类:功能特点
-
目标:掌握Scala中样例类的设计、功能与特点
- 什么是样例类?
- 与普通的类有什么区别?
-
路径
- 样例类的设计
- 样例类的功能与特点
-
实施
-
样例类的设计
-
Scala中一种特殊的类,通过关键字标识:case
-
正常的类
class Name -
样例类
case class Name
-
-
可以用封装数据,类似于Java中构建的JavaBean或者POJO类设计
- JavaBean
- 成员属性
- construct
- get and set
- toString
- hashCode and equals
- Scala:叫做Scala Bean
- Scala中Tuple的设计就是利用样例类来实现存储数据
- 优点在于:自动实现Bean中的常用方法
- JavaBean
-
一般也用于模式匹配
- 样例类在模式匹配的时候是可以直接匹配元素的值
-
-
样例类的功能与特点
-
普通类:所有的方法需要自己手动显示的定义
class Person06(var name:String){ // override def toString: String = this.name //重写hashcode进行比较,以name实现,只要name对应的hashcode一样,认为是一样的 //注意:name如果不一样,但是hash是可能一样的 override def hashCode(): Int = super.hashCode() //如果hashcode一样,通过equals来比较值 override def equals(obj: Any): Boolean = super.equals(obj) } object TestPerson06{ def main(args: Array[String]): Unit = { val p1 = new Person06("itcast") //没有定义apply,必须给new关键字 val p2 = new Person06("itcast") //打印:调用toString println(p1) println(p2) //实现两个对象的比较 println(p1 == p2) } } -
样例类:自动构建伴生对象,自动实现重写了以下方法
case class Person08(var name:String) { } object TestPerson08{ def main(args: Array[String]): Unit = { //构建实例:自动生成伴生对象,实现apply方法 val p1 = Person08("itcast") val p2 = Person08("itcast") //打印:调用toString,自动实现了toString // println(p1) //比较:只要name相同,就认为相同,自动实现了hashcode和equals println(p1 == p2) } }-
apply:样例类自动构建伴生对象,自动生成apply
- 普通类,必须自己定义伴生对象和实现apply
- 将传递的属性给你返回对象
-
toString:样例类自动重写
- 普通类:手动重写
-
hashCode and equals:样例类自动重写
- 普通类:手动重写
-
copy:直接复制一个样例类的对象
val p3 = p2.copy("heima") -
unapply:提取器
- 用于将样例类实现模式匹配
- 从传递的对象中提取属性
-
-
-
-
小结
- 什么是样例类?
- Scala一种特殊的类
- 关键字:case
- 应用
- 用于封装数据:Scala Bean
- 用于实现类的模式匹配
- 与普通的类有什么区别?
- 通过case关键字修饰
- 自动实现了一些方法
- apply
- unapply
- toString
- hashCode and equals
- copy
- 什么是样例类?
样例类:结合模式匹配
-
目标:掌握样例类如何实现模式匹配
- 样例类如何实现模式匹配呢?
- 样例类的模式匹配与普通类有什么区别?
-
路径
- 实现样例类的模式匹配
- 样例类与普通类模式匹配的区别
-
实施
-
实现样例类的模式匹配
//样例类 case class Person01(var name:String,var age:Int) //样例对象:全局唯一实例,静态的 case object Dog01 //普通类 class Cat(var name:String,var age:Int) object matchCaseClassDemo { def main(args: Array[String]): Unit = { //构建一个数组:放三种类型 val arr = Array(Person01("itcast",20),new Cat("Tom",19),Dog01) //随机取一个元素 val input = arr(Random.nextInt(arr.length)) //对元素模式匹配 input match{ // case x:Cat => println(s"this type is Cat name = ${x.name} age = ${x.age}") case Cat(name,age) => println(s"this type is Cat name = ${x.name} age = ${x.age}") // case y:Person01 => println(s"this type is Person name = ${y.name} age = ${y.age}") case Person01(name,age) => println(s"this type is Person name = ${name} age = ${age}") case Dog01 => println("this is a Dog") } } } -
样例类与普通类模式匹配的区别
-
普通类:匹配类的类型,然后传递给对象,通过对象获取类的属性
-
样例类:直接匹配类的属性,然后复制给属性变量
-
-
-
小结
- 样例类如何实现模式匹配呢?
- 直接通过匹配的属性值来进行匹配
- 样例类如何实现模式匹配呢?
-
样例类的模式匹配与普通类有什么区别?
- 普通类:先匹配类型,赋值给一个对象,通过对象调用属性的
unapply方法与提取器
-
目标:掌握Scala中的unapply方法与提取器的使用
-
路径
- unapply的功能
- unapply的定义及使用
-
实施
-
unapply的功能
- apply的功能:传递属性,返回实例对象,当构建实例的时候,可以不写new

- apply的功能:传递属性,返回实例对象,当构建实例的时候,可以不写new
-
-
unapply的功能:传递对象,返回对象中的属性,实现模式匹配的时候,直接匹配属性的值
-
-
unapply的定义及使用
case class Dog(var name:String,var age:Int) class Cat(var name:String,var age:Int) object UnapplyDemo { def main(args: Array[String]): Unit = { val arr = Array(Dog("wangwang",5),new Cat("tom",8)) val input = arr(Random.nextInt(arr.length)) input match { case Dog(name,age) => println(s"this is a dog name =${name} age = ${age}" ) case cat:Cat => println(s"this is a cat name =${cat.name} age = ${cat.age}" ) } } }- 如果实现可以不写new关键字?
- 如何实现可以进行样例匹配?
case class Dog(var name:String,var age:Int) class Cat(var name:String,var age:Int) object Cat{ //传递参数,返回对象 def apply(name:String,age:Int) = new Cat(name,age) //传递对象,返回参数 def unapply(cat: Cat): Option[(String, Int)] = { //判断对象是否为空 if(cat != null){ Some((cat.name,cat.age)) }else{ None } } } object UnapplyDemo { def main(args: Array[String]): Unit = { //问题1:如何能让Cat在构建实例的时候,不写new val arr = Array(Dog("wangwang",5),Cat("tom",8)) val input = arr(Random.nextInt(arr.length)) input match { case Dog(name,age) => println(s"this is a dog name =${name} age = ${age}" ) //问题2:如何能让Cat在模式匹配时直接匹配属性 case Cat(name,age) => println(s"this is a cat name =${name} age = ${age}" ) } } }
-
-
小结
-
unapply的功能?
- 传递一个对象,解析对象中所有属性返回
-
unapply的定义及使用?
def unapply(类的对象) = Option[(属性的值)]
-
Option类型
-
目标:掌握Scala中Option类型的定义及使用
- 什么是Option类型?
- Option类型如何定义?
- Option类型如何使用?
-
路径
- Option类型的设计
- Option类型的定义
- Option类型的使用
-
实施
-
Option类型的设计
- 当我们操作数据时,经常会出现返回的结果不确定的问题,无法确定返回的内容
- 如果返回值有值,就可以正常的接受对应的值
- 但如果返回值没有值,就会出现读取异常,程序异常退出
- Scala中可以使用Option类型来表示两种不同的状态,我们根据不同的状态来实现后续处理
- 当我们操作数据时,经常会出现返回的结果不确定的问题,无法确定返回的内容
-
Option类型的定义
- 两个子类
- Some:表示结果有值,并且会将值放入Some对象中
- None:表示结果没有值,为空
-
Option类型的使用
object OptionDemo { def main(args: Array[String]): Unit = { val map = Map("1" -> "zhangsan","2"->"lisi") //根据Key取值 //方式一 // println(map("11")) //方式二 // val x: Option[String] = map.get("11") //方式三 println(map.getOrElse("11","null")) } }
-
-
-
小结
- 什么是Option类型?
- 用于返回的值不确定的场景下
- Option类型如何定义?
- Option【数据的类型】
- Some(value):有值
- None:没有值
- Option类型如何使用?
- 用于作为方法的返回值
- 什么是Option类型?
偏函数partial function的定义及使用
-
目标:了解偏函数的功能及使用
-
路径
- 偏函数的功能
- 偏函数的使用
-
实施
-
偏函数的功能
- 偏函数不是一种函数
- 方法:def
- 函数:=>
- 偏函数是一种特殊的数据公式,用于实现对代码进行简化处理
- 偏函数不是一种函数
-
偏函数的定义
-
偏函数是指代码块中没有match的一组case语句就是偏函数
-
偏函数本质是PartialFunction[A, B]的一个实例
- A:输入参数类型
- B:返回值类型
-
定义
val pf = { case 语句 }
-
-
偏函数的使用
-
方式一:直接定义调用:定义一个方法,传递int类型数字,返回对应的汉字
//普通方法定义 def m1(numb:Int):String = { numb match{ case 1 => "一" case 2 => "二" case 3 => "三" case _ => "其他" } } println(m1(2))object PfDemo { def main(args: Array[String]): Unit = { //直接定义一个偏函数 val pf:PartialFunction[Int,String] = { case 1 => "一" case 2 => "二" case 3 => "三" case _ => "其他" } println(pf(1)) } }
-
-
方式二:搭配collect函数使用,collect类似于map函数,传递参数为偏函数
//将所有的数值元素乘以10 val array = Array(1,2,3,9,"itcast",true)//正常的写法 array.filter(x => x.isInstanceOf[Int]).map(x => x.asInstanceOf[Int] * 10).foreach(println)val pf2:PartialFunction[Any,Int] = { case i:Int => i * 10 } //collect方法,类似于map方法,collect方法只能传递偏函数 array.collect(pf2).foreach(println)
-
-
小结
- 什么是偏函数?
- ParticalFunction【A,B】类的实例对象
- A 输入类型
- B返回类型
- 做模式匹配时候,不用写match
- 偏函数的使用?
- 方式一:直接定义,直接调用
- 方式二:对集合使用,搭配collect方法使用
- 什么是偏函数?
正则对象的定义及使用
-
目标:了解Scala中如何使用正则表达式
-
路径
- 正则类Regex的功能及定义
- 正则表达式的使用方式
-
实施
-
正则类Regex的功能
- 类:Regex
- 用于实现正则表达式的定义及匹配
- 方法
- r:用于将三冒号中的字符串转换为正则表达式对象
- findAllMatchIn:用于匹配所有符合正则的结果
- 类:Regex
-
正则表达式的使用方式
object RegexDemo { def main(args: Array[String]): Unit = { //对邮箱格式的正则匹配 val str1 = "heima@itcast.cn" val str2 = "12345@qq" //构建邮箱格式正则 val regex: Regex = """.+@.+\..+""".r //匹配 val matches: Iterator[Regex.Match] = regex.findAllMatchIn(str2) matches.foreach(println) } }
-
-
小结
- 核心学习的还是正则表达式,类及方法的使用不同语言中都有区别,了解即可
异常的处理
-
目标:掌握Scala中如何实现异常的处理
-
路径
- 捕获异常
- 抛出异常
-
实施
-
捕获异常try catch的使用
-
关键字:try catch finally
- try:要执行的有风险的代码
- catch:捕获异常
- finally:不论你是否异常,都执行的代码
-
实现
object ExceptionDemo { def main(args: Array[String]): Unit = { //定义一个数值的字符串 val i = "0" try{ //实现数据计算 println(1 / i.toInt) }catch { case e1:NumberFormatException => println("数字转换异常:"+ e1.getMessage) case e2:ArithmeticException => println("数学规则异常:"+e2.getMessage) case e3:Exception => println("其他异常") }finally { println("不论你是否有异常,我都会执行") } } }
-
-
抛出异常throw Exception
throw new Exception("就是想抛一个异常")
-
-
小结
- 基本与Java中的异常处理是一致
泛型、上下界、非变斜变逆变
-
目标:了解Scala中泛型、上下界及斜变逆变的使用
-
路径
- 泛型的概念及使用
- 上下界的概念及使用
- 非变斜变逆变的概念及使用
-
实施
-
泛型的概念及使用
-
泛型的概念:用于定义不确定的数据类型,实现可以使用不同类型进行传递
-
泛型的使用
-
规则:
- 泛型方法:在方法的后面使用中括号标记任意大写字母的泛型,在定义时使用该泛型即可
- 泛型类:在类的定义后面使用中括号标记任意大写字母的泛型,定义属性时指定对应泛型即可
-
需求1:定义一个方法,传递任意类型的数组,输出数组中的每个元素
object FanXingDemo { def main(args: Array[String]): Unit = { val a1: Array[Int] = Array(1,2,3) val a2: Array[String] = Array("a","b","c") //普通的方法 def m1(array:Array[Int]) = array.foreach(println) // m1(a1) // m1(a2) //传递一个任意类型的数组 def m2[A](array:Array[A]) = array.foreach(println) m2(a1) m2(a2) } } -
需求2:定义一个类,允许传递两个泛型属性
case class PersonFanxing[B](var name:B,var age:B) object FanXingDemo { def main(args: Array[String]): Unit = { //构建PersonFanxing的实例 PersonFanxing("itcast",18) PersonFanxing(19,18) PersonFanxing("itcast","heima") } }
-
-
-
上下界的概念及使用
-
上界:指定泛型的范围只能是该类或者该类的子类,不能超过这个类的范围
-
语法
[T <: B] //T为泛型,B为上界类型,T必须是B类型或者B的子类类型
-
-
下界:指定泛型的范围只能是该类或者该类的父类,不能低于这个类的范围
-
语法
[T >: B] //T为泛型,B为下界类型,T必须是B类型或者B的父类类型
-
-
测试
-
正常的调用
class Things class Persons extends Things class Students extends Persons object UpAndDownDemo { def main(args: Array[String]): Unit = { def demo[T](a:Array[T]) = a.foreach(println) demo(Array(new Things,new Things)) demo(Array(new Persons,new Persons)) demo(Array(new Students,new Students)) } } -
限制上界
def main(args: Array[String]): Unit = { def demo[T <: Persons](a:Array[T]) = a.foreach(println) demo(Array(new Things,new Things)) //报错 demo(Array(new Persons,new Persons)) demo(Array(new Students,new Students)) } -
限制下界
object UpAndDownDemo { def main(args: Array[String]): Unit = { def demo[T >: Persons](a:Array[T]) = a.foreach(println) demo(Array(new Things,new Things)) demo(Array(new Persons,new Persons)) demo(Array(new Students,new Students)) //编译时报错 } }
-
-
-
非变斜变逆变的概念及使用
-
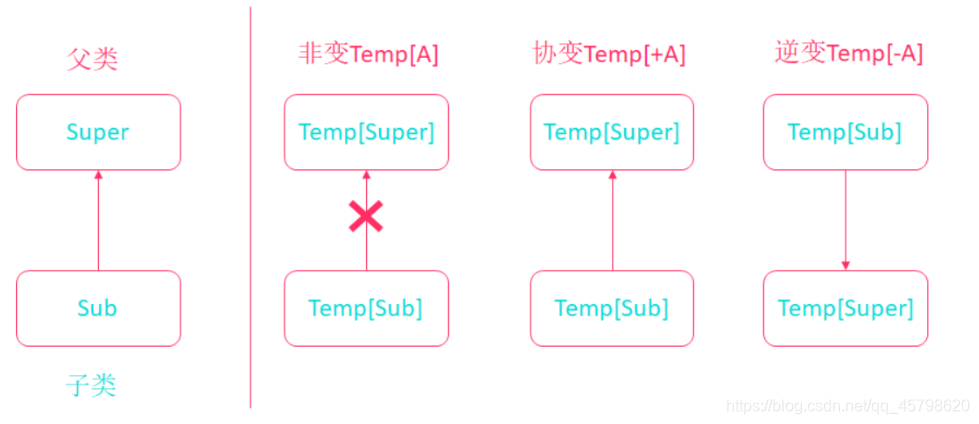
-
-
非变【A】:两个类之间的关系不可延伸,就是非变
- Java:String extends Object
- String是Object的子类,Object是String的父类
- list 1 = List[String]
- list2 = List[Object]
-
斜变【+A】:两个类之间的关系可以延伸且不变,就是斜变
-
tmp1 = Temp[String]
-
tmp2 :Temp[Object]
-
tmp2 = tmp1
-
逆变【-A】:两个类之间的关系延伸以后转换了,就是逆变
-
tmp1:Temp[String]
-
tmp2 = Temp[Object]
-
tmp1 = tmp2
-
-
例子
class Super class Sub extends Super class Temp1[T] class Temp2[+T] class Temp3[-T] def main(args: Array[String]): Unit = { val a:Temp1[Sub] = new Temp1[Sub] // 编译报错 // 非变 val b:Temp1[Super] = a // 协变 val c: Temp2[Sub] = new Temp2[Sub] val d: Temp2[Super] = c // 逆变 val e: Temp3[Super] = new Temp3[Super] val f: Temp3[Sub] = e }
-
-
-
小结
- 泛型的概念:不明确定义传递哪种类型,可以传递任意类型
- 上下界的概念:限制泛型中类型传递的类型
- 上界:<:
- 上界:>:
- 非变斜变逆变的概念:是否允许实现类型的关系的延伸以及延伸的方式
- 非变:不允许传递
- 斜变:允许,不变
- 逆变:允许,关系倒过来
高阶函数:柯里化函数
-
目标:了解Scala中的柯里化函数的实现
-
路径
- Scala中常用的函数类型
- 柯里化函数的功能及特点
- 柯里化函数的定义及实现
-
实施
-
Scala中常用的函数类型
-
匿名函数:没有名字的函数,只有参数列表和函数体
(x:Int,y:Int) => {函数体} -
值函数:将匿名函数赋值给一个变量,取个名字
val fname = (x:Int,y:Int) => {函数体} -
高阶函数:函数A的参数是一个函数,A就为高阶函数
f1(f:A => B)
-
-
柯里化函数的功能及特点
- 定义:柯里化(Currying)是指将原先接受多个参数的方法转换为多个只有一个参数的参数列表的过程。
- 理解:如果一个函数中使用多个圆括号传递多个参数列表,那么这个函数就是柯里化函数
- 正常函数多个参数:(x:Int,y:Int,z:Int)
- 柯里化函数拆分为多个一个参数的函数:fun(x:Int)(y:Int)(z:Int)
- 本质
- 函数的参数列表只有1个
- fun1(x:Int)
- 参数:x
- 返回值:fun2(y)(z)
- fun(2)
- 参数:y
- 返回值:fun3(z)
- fun3
- 参数:z
- 返回值:处理逻辑
- 目的:优化函数调用过程,提高灵活性,实现分步调用
- 例如:fold(初始值)(参数函数)
-
柯里化函数的定义及实现
-
需求:传递两个参数,实现求和
-
实现1:正常函数定义
scala> def m1(x:Int,y:Int) = x + y m1: (x: Int, y: Int)Int 方法名:(参数列表)返回值
scala> m1(1,3)
res1: Int = 4- 实现2:柯里化函数定义 ```scala scala> def m2(x:Int)(y:Int) = x + y m2: (x: Int) (y: Int)Int 方法名:(参数列表) 返回值 scala> m2(1,3) <console>:13: error: too many arguments for method m2: (x: Int)(y: Int)Int m2(1,3) ^ scala> m2(1)(3) res3: Int = 4 scala>-
基本原理:实现函数的分步调用
scala> m2(1)_ res4: Int => Int = <function1> scala> res4(3) res5: Int = 4 -
自己写这个函数代替柯里化函数
def m3(x:Int) = (y:Int) => x + y def m3(x:Int) = { //返回值是一个函数 (y:Int) => x + y } scala> def m3(x:Int) = (y:Int) => x + y m3: (x: Int)Int => Int scala> m3(1) res6: Int => Int = <function1> scala> res6(3)
-
-
-
小结
- Scala中常用的函数类型:匿名函数、值函数、高阶函数
- 柯里化函数的功能及特点:多个参数列表,实现分步调用
高阶函数:闭包函数
-
目标:了解高阶函数闭包函数的概念及用法
-
路径
- 闭包函数的概念及特点
- 闭包函数的定义及实现
-
实施
-
闭包函数的概念及特点
- 官方:函数的返回值依赖于声明在函数外部的变量
- 理解:函数体中调用了函数体外部的一个变量
-
闭包函数的定义及实现
-
需求:传递两个参数,实现求和
-
方式1:普通函数
def m1(x:Int,y:Int) = x + y- x和y都是方法内部的变量
-
方式2:闭包函数
val y = 10 def m2(x:Int) = x + y- x是方法内部的变量
- y是方法外部的变量
-
-
-
小结
- 闭包函数就是函数实现逻辑需要依赖于外部的变量来实现
隐式转换:功能特点及隐式参数
-
目标:了解Scala中隐式转换的功能及特点
-
路径
- 问题:Int类没有to方法,但是为什么可以调用?
- 隐式转换的功能与特点
- 隐式参数的使用
- 隐式转换的原则
-
实施
-
问题:Int类没有to方法,但是为什么可以调用?
1.to(10)- 1是Int类型,Int类型没有to方法,如何实现的?
- to方法时RichInt类型的方法
- Int没有to方法,但是Scala中定了一个允许Int类型转换为RichInt 类型,RichInt有to方法
- 所有Int在调用时,自动被转换为RichInt类型
- 实现了隐式转换:Scala在Perdef中自动将Int类型转换为了RichInt类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vcqinBDa-1618468925526)(20210415_Scala(八).assets/image-20210415103734958.png)]
-
隐式转换的功能与特点
- 关键字:implicit
- 参数:隐式参数,用于进行无参调用,调用默认参数
- 方法:隐式转换方法,用于实现类型的隐式转换
- 功能:实现隐式参数或者隐式转换
- 设计:为了避免程序出错,实现纠错功能
- 关键字:implicit
-
隐式参数的使用
-
通过implicit标识参数
-
当遇到错误需要使用隐式参数时,会自动调用填充
-
-
正常参数调用
scala> def m1(x:Int) = println(x) m1: (x: Int)Unit scala> m1(1) 1 scala> m1(2) 2 scala> m1 <console>:13: error: missing argument list for method m1 Unapplied methods are only converted to functions when a function type is expected. You can make this conversion explicit by writing `m1 _` or `m1(_)` instead of `m1`. m1-
隐式参数调用
scala> implicit var i:Int = 8 i: Int = 8 scala> scala> def m2(implicit x:Int) = println(x) m2: (implicit x: Int)Unit scala> m2(9) 9 scala> m2 8
-
-
-
小结
- 问题:Int类没有to方法,但是为什么可以调用?
- Scala中默认实现了隐式转换,将Int类型转换为RichInt类型
- 隐式转换的功能与特点?
- 隐式参数:默认提供一个隐式参数,允许不给定参数调用
- 隐式转换方法
- 隐式参数的使用?
- 定义一个隐式变量:implicit修饰变量
- 定义方法的时候指定隐式参数:implicit修饰参数
- 问题:Int类没有to方法,但是为什么可以调用?
隐式转换:隐式转换方法
-
目标:掌握Scala中隐式转换方法的使用
-
路径
- 隐式转换的规则
- 隐式转换方法的定义及使用
-
实施
-
隐式转换的原则
-
无歧义
-
在使用隐式参数的时候 编译器是通过类型进行填充的
-
当作用域中有多个同类型的隐式参数 在进行填充的就会有歧义 报错
scala> implicit var i:Int = 8 i: Int = 8 scala> scala> def m2(implicit x:Int) = println(x) m2: (implicit x: Int)Unit scala> m2(9) 9 scala> m2 8 scala> implicit var u:Int = 10 u: Int = 10 scala> m2 <console>:15: error: ambiguous implicit values: both method i of type => Int and method u of type => Int match expected type Int m2
-
-
显示操作先行
-
隐式转换是编译期间程序出错的时候才会尝试进行的机制
-
如果正常编译程序不出错 没有问题 即使定义隐式参数或者隐式方法 也不会生效
-
-
集中定义原则
-
为了避免冲突,隐式转换方法或者参数要求定义在object中, 静态特性
-
哪里需要隐式转换哪里手动导入
-
-
-
隐式转换方法的实现
- 通过implicit标识转换的方法
-
当遇到需要转换的情况时,底层自动调用转换方法实现
class SuperMan(var name:String){ def fly = println("I can fly") } class Man(var name:String){ def eat = println("I can eat") } object ImplicitDemo { def main(args: Array[String]): Unit = { implicit def manToSuperMan(man:Man):SuperMan = { new SuperMan(man.name) } val man = new Man("itcast") man.eat man.fly } }
-
-
小结
- 隐式转换的规则?
- 避免歧义性
- 显示操作现行:只有出现错误才会调用隐式转换
- 集中定义原则:将不同的隐式转换封装在object中
- 隐式转换方法的实现?
- 定义了隐式转换方法
- 当实现调用时,会自动进行隐式转换
- 隐式转换的规则?















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









