







参考代码在最低部
一、实验目的
通过分析Bp算法的原理,利用JAVA编程工具(或者其他编程工具)实现Bp算法,并通过对样本数据的监督学习过程,加深对反馈型神经网络算法的理解与应用过程。
二、实验内容
按照下面的要求操作,然后分析不同操作后网络输出结果。
- 可修改学习因子
- 可任意指定隐单元层数
- 可任意指定输入层、隐含层、输出层的单元数
- 可指定最大允许误差ε
- 可输入学习样本(增加样本)
- 可存储训练后的网络各神经元之间的连接权值矩阵;
- 修改训练后的BP神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果 。
三、实验方法
1.前馈型人工神经网络
前馈型人工神经网络是整个神经网络体系中最常见的一种,其结构模型如图4-1所示。网络结构包含输入层、隐层(可能是多层)和输出层,它的连接方式是同层之间不相连接,相邻层之间单元为全连接型。这种网络没有反馈存在,实际运行是单向的,学习方式是一种监督式学习。
前馈型神经网络具有很强的非线性映射能力,寻找其映射是靠学习实践的,只要学习数据足够完备,就能够描述任意未知的复杂系统。因此前馈神经网络为非线性系统的建模和控制提供了有力的工具。
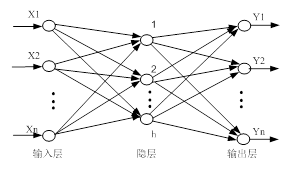
图4-1 前馈型神经网络结构
2.BP算法原理
BP(Back Propagation)神经网络是一种利用误差反向传播训练算法的前馈型网络,BP学习算法实质是求取网络总误差函数的最小值问题[2]。这种算法采用非线性规划中的最速下降方法,按误差函数的负梯度方向修改权系数,它是梯度下降法在多层前馈网络中的应用。具体学习算法包括两大过程,其一是输入信号的正向传播过程,其二是输出误差信号的反向传播过程。
1.正向传播
输入的样本从输入层经过隐层单元一层一层进行处理,通过所有的隐层之后,则传向输出层;在逐层处理的过程中,每一层神经元的状态只对下一层神经元的状态产生影响。在输出层把现行输出和期望输出进行比较,如果现行输出不等于期望输出,则进入反向传播过程。
2.反向传播
反向传播时,把误差信号按原来正向传播的通路反向传回,并对每个隐层的各个神经元的权系数进行修改,以望误差信号趋向最小。网络各层的权值改变量,则由传播到该层的误差大小来决定。
3.BP算法的特点
BP神经网络具有以下三方面的主要优点[3]:第一,只要有足够多的隐含层和隐层节点,BP神经网络可逼近任意的非线性映射关系;第二,BP学习算法是一种全局逼近方法,因而它具有较好的泛化能力。第三,BP神经网络具有一定的容错能力。因为BP神经网络输入输出间的关联信息分布存储于连接权中,由于连接权的个数总多,个别神经元的损坏对输入输出关系只有较小影响。
但在实际应用中也存在一些问题,如:收敛速度慢,极有可能陷入最优陷阱(局部极值),而且典型的BP网络是一个冗余结构,它的结构及隐节点数的确定往往有人为的主观性,而且一旦人工决定之后,不能在学习过程中自主变更。其结果是隐节点数少了,学习过程不收敛;隐节点数多了,则网络的学习及推理的效率较差。
四、实验步骤
4.1 实验数据
请自行下载Iris数据中的一种做为训练样本集,完成实验。
4.2Bp网络定义
class BpDeep {
// private static int LAYER =; //神经网络层数
private static int NodeNum = ; // 每层的最多节点数
private static final int ADJUST = ; // 隐层节点数调节
private static final int MaxTrain = ; // 最大训练次数
private static final double ACCU = ; // 每次迭代允许的误差
private double ETA_W; // 权值学习率
private double ETA_T; // 阈值学习率
// 附加动量项
//private static final double ETA_A = 0.3; // 动量常数0.1
//private double[][] in_hd_last; // 上一次的权值调整量
//private double[][] hd_out_last;
private int in_num; // 输入层节点数
private int hd_num; // 隐层节点数
private int out_num; // 输入出节点数
private ArrayList<ArrayList<Double>> list = new ArrayList<>(); // 输入输出数据
private double[][] in_hd_weight; // BP网络in-hidden突触权值
private double[][] hd_out_weight; // BP网络hidden_out突触权值
private double[] in_hd_th; // BP网络in-hidden阈值
private double[] hd_out_th; // BP网络hidden-out阈值
private double[][] out; // 每个神经元的值经S型函数转化后的输出值,输入层就为原值
private double[][] delta; // delta学习规则中的值
}
4.3 成员函数定义
// 获得网络三层中神经元最多的数量
public int GetMaxNum()
// 设置权值学习率
public void SetEtaW()
// 设置阈值学习率
public void SetEtaT()
// BpDeep训练
public void Train(int in_number, int out_number,
ArrayList<ArrayList<Double>> arraylist) throws IOException
// 获取输入层、隐层、输出层的节点数,in_number、out_number分别为输入层节点数和输出层节点数
public void GetNums(int in_number, int out_number)
// 初始化网络的权值和阈值
public void InitNetWork()
// 计算单个样本的误差
public double GetError(int cnd)
// 计算所有样本的平均精度
public double GetAccu()
// 前向传播
public void Forward()
// 误差反向传播
public void Backward(int cnd)
// 计算权重增益
public void CalcDelta(int cnd)
// 更新BP神经网络的权值和阈值
public void UpdateNetWork()
// 符号函数sign
public int Sign(double x)
// 返回最大值
public double Maximum(double x, double y)
// 返回最小值
public double Minimum(double x, double y)
// log-sigmoid函数
public double Sigmoid(double x)
// log-sigmoid函数的倒数
public double SigmoidDerivative(double y)
// tan-sigmoid函数
public double TSigmoid(double x)
// tan-sigmoid函数的倒数
public double TSigmoidDerivative(double y)
// 分类预测函数
public ArrayList<ArrayList<Double>> ForeCast(
ArrayList<ArrayList<Double>> arraylist)
4.4 样本数据归一化
//归一化公式
public double Normalize(double x, double max, double min){
double y = 0.1+0.8*(x-min)/(max-min);
return y;
}
4.5 结果的输出
public class BpTest
{
public static void main(String[] args) throws Exception
{
System.out.println("测试集的数量:"+ (new Double(all_num)).intValue());
System.out.println("分类正确的数量:"+(new Double(right)).intValue());
System.out.println("算法的分类正确率为:"+right/all_num);
System.out.println("分类结果存储在:filepath/file");
}
}
五、注意事项
1.输入样本归一化的重要性:
1)避免数值过大问题:若不进行归一化处理,所得的输出,权值等往往会很大,而偏差也就很大,而权值调节中需要偏差权值输入,及偏差的积分和,这得到的数值将会很大,超出了数量级,也就超出了计算机等处理器的数值范围(我开始就是这样,导致偏差积分根本不能求),权值修正很差。
2)归一化将有单位的量纲转换成无量纲的了,便于BP网络的计算。
3)使网络快速的收敛。
尽量的使尽可能多的输入样本归一化,不完全归一化也能实现效果。
2.归一化方法:
(测量值—最低标度)/(最大标度—最低标度)等(就是求占得百分比)
3.可能陷入局部最优解:
前面针对反向学习算法的二次性能修正函数已经做过介绍,表现出来最明显的现象就是,在神经网络训练过程中,由于初始化权值的随机,可能一开始就走偏了,一直无法满足偏差最小情况。学习时间很长还没有出结果,可能就是陷入了局部凹坑。需要重新初始化BP神经网络。
4.对数据要求较高:
计算机只能处理计算机语言,所以需要处理现实中的问题,就需要转换为计算机能处理的数据。当你训练神经网络时用的是什么特征的数据,那么测试时就也该在这个特征范围内。
参考代码:
package bp;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Random;
class BPNN {
// private static int LAYER = 3; // 三层神经网络
private static int NodeNum = 10; // 每层的最多节点数
private static final int ADJUST = 5; // 隐层节点数调节常数
private static final int MaxTrain = 2000; // 最大训练次数
private static final double ACCU = 0.015; // 每次迭代允许的误差 iris:0.015
private double ETA_W = 0.5; // 权值学习效率0.5
private double ETA_T = 0.5; // 阈值学习效率0.5
private double accu;
// 附加动量项
//private static final double ETA_A = 0.3; // 动量常数0.1
//private double[][] in_hd_last; // 上一次的权值调整量
//private double[][] hd_out_last;
private int in_num; // 输入层节点数
private int hd_num; // 隐层节点数
private int out_num; // 输入出节点数
private ArrayList<ArrayList<Double>> list = new ArrayList<>(); // 输入输出数据
private double[][] in_hd_weight; // BP网络in-hidden突触权值
private double[][] hd_out_weight; // BP网络hidden_out突触权值
private double[] in_hd_th; // BP网络in-hidden阈值
private double[] hd_out_th; // BP网络hidden-out阈值
private double[][] out; // 每个神经元的值经S型函数转化后的输出值,输入层就为原值
private double[][] delta; // delta学习规则中的值
// 获得网络三层中神经元最多的数量
public int GetMaxNum() {
return Math.max(Math.max(in_num, hd_num), out_num);
}
// 设置权值学习率
public void SetEtaW() {
ETA_W = 0.5;
}
// 设置阈值学习率
public void SetEtaT() {
ETA_T = 0.5;
}
// BPNN训练
public void Train(int in_number, int out_number, ArrayList<ArrayList<Double>> arraylist) throws IOException {
list = arraylist;
in_num = in_number;
out_num = out_number;
GetNums(in_num, out_num); // 获取输入层、隐层、输出层的节点数
// SetEtaW(); // 设置学习率
// SetEtaT();
InitNetWork(); // 初始化网络的权值和阈值
int datanum = list.size(); // 训练数据的组数
int createsize = GetMaxNum(); // 比较每一层的节点数,取max
out = new double[3][createsize]; // 创建输出数组 out[3][7]
//训练次数为MaxTrain以内,如果训练次数超过MaxTrain则没有给出判断的条件
for (int iter = 0; iter < MaxTrain; iter++) {
for (int cnd = 0; cnd < datanum; cnd++) {
// 第一层输入节点赋值 out[0][4]
for (int i = 0; i < in_num; i++) {
//list.get(cnd).get(i) 取样本数据的第cnd组中第i个数据放入到out[0][i]中
out[0][i] = list.get(cnd).get(i); // 为输入层节点赋值,其输入与输出相同
}
Forward(); // 前向传播
Backward(cnd); // 误差反向传播
}
System.out.println("This is the " + (iter + 1) + " th trainning NetWork !");
accu = GetAccu();
System.out.println("All Samples Accuracy is " + accu);
if (accu < ACCU)
break;
}
}
// 获取输入层、隐层、输出层的节点数,in_number、out_number分别为输入层节点数和输出层节点数
public void GetNums(int in_number, int out_number) {
in_num = in_number;
out_num = out_number;
hd_num = (int) Math.sqrt(in_num + out_num) + ADJUST;
if (hd_num > NodeNum)
hd_num = NodeNum; // 隐层节点数不能大于最大节点数
}
// 初始化网络的权值和阈值
public void InitNetWork() {
// 初始化上一次权值量,范围为-0.5-0.5之间
//in_hd_last = new double[in_num][hd_num];
//hd_out_last = new double[hd_num][out_num];
in_hd_weight = new double[in_num][hd_num];
for (int i = 0; i < in_num; i++)
for (int j = 0; j < hd_num; j++) {
int flag = 1; // 符号标志位(-1或者1)
if ((new Random().nextInt(2)) == 1)
flag = 1;
else
flag = -1;
// New Random.nextDouble()的取值范围: [0,1.0)
in_hd_weight[i][j] = ( new Random().nextDouble() / 2 ) * flag; // 初始化in-hidden的权值
//in_hd_last[i][j] = 0;
}
hd_out_weight = new double[hd_num][out_num];
for (int i = 0; i < hd_num; i++)
for (int j = 0; j < out_num; j++) {
int flag = 1; // 符号标志位(-1或者1)
if ((new Random().nextInt(2)) == 1)
flag = 1;
else
flag = -1;
hd_out_weight[i][j] = (new Random().nextDouble() / 2) * flag; // 初始化hidden-out的权值
//hd_out_last[i][j] = 0;
}
// 阈值均初始化为0
// 输入层不处理数据,只接收数据,所以不设置阈值
in_hd_th = new double[hd_num];
for (int k = 0; k < hd_num; k++)
in_hd_th[k] = 0;
hd_out_th = new double[out_num];
for (int k = 0; k < out_num; k++)
hd_out_th[k] = 0;
}
/* // 计算单个样本的误差
public double GetError(int cnd) {
double ans = 0;
for (int i = 0; i < out_num; i++)
{
System.out.println(out[2][i]);
ans += 0.5 * (out[2][i] - list.get(cnd).get(in_num + i)) * (out[2][i] - list.get(cnd).get(in_num + i));
}
return ans;
}*/
// 计算所有样本的平均精度
public double GetAccu() {
double ans = 0;
int num = list.size();
for (int i = 0; i < num; i++) {
int m = in_num;
for (int j = 0; j < m; j++)
out[0][j] = list.get(i).get(j);
Forward();
int n = out_num;
for (int k = 0; k < n; k++){
//定义了输入与输出之间的平方误差
//System.out.println(list.get(i).get(in_num + k));
//System.out.println(out[2][k]);
ans += 0.5 * (list.get(i).get(in_num + k) - out[2][k]) * (list.get(i).get(in_num + k) - out[2][k]);
}
}
return ans / num;
}
// 前向传播
public void Forward() {
/**
* 计算隐层节点的输出值
* v = 求和( 每个输入层数据 * 每个隐层的权重 ) + 对应 隐层 的阈值
* in_hd_weight[4][7] out[0][4] in_hd_th[7]
*/
for (int j = 0; j < hd_num; j++) {
double v = 0;
for (int i = 0; i < in_num; i++)
v += in_hd_weight[i][j] * out[0][i];
v += in_hd_th[j];
out[1][j] = Sigmoid(v);
}
/**
* 计算输出层节点的输出值
* v = 求和( 每个隐层输出数据 * 每个输出层的权重 ) + 对应 输出层 的阈值
* hd_out_weight[7][3] out[1][3] hd_out_th[3]
*/
for (int j = 0; j < out_num; j++) {
double v = 0;
for (int i = 0; i < hd_num; i++)
v += hd_out_weight[i][j] * out[1][i];
v += hd_out_th[j];
out[2][j] = Sigmoid(v);
}
}
// 误差反向传播 = 计算权值调整量 + 更新BP神经网络的权值和阈值
public void Backward(int cnd) {
CalcDelta(cnd); // 计算权值调整量
UpdateNetWork(); // 更新BP神经网络的权值和阈值
}
// 计算delta调整量
public void CalcDelta(int cnd) {
int createsize = GetMaxNum(); // 比较创建数组
delta = new double[3][createsize];
// 计算输出层的delta值 cnd ( 0 - 119 )
for (int i = 0; i < out_num; i++) {
//System.out.println(list.size());
delta[2][i] = (list.get(cnd).get(in_num + i) - out[2][i]) * SigmoidDerivative(out[2][i]);
}
// 计算隐层的delta值
for (int i = 0; i < hd_num; i++) {
double t = 0;
for (int j = 0; j < out_num; j++)
t += hd_out_weight[i][j] * delta[2][j];
delta[1][i] = t * SigmoidDerivative(out[1][i]);
}
}
// 更新BP神经网络的权值和阈值
public void UpdateNetWork() {
// 隐含层和输出层之间权值和阀值调整
for (int i = 0; i < hd_num; i++) {
for (int j = 0; j < out_num; j++) {
hd_out_weight[i][j] += ETA_W * delta[2][j] * out[1][i]; // 未加权值动量项
/* 动量项
* hd_out_weight[i][j] += (ETA_A * hd_out_last[i][j] + ETA_W
* delta[2][j] * out[1][i]); hd_out_last[i][j] = ETA_A *
* hd_out_last[i][j] + ETA_W delta[2][j] * out[1][i];
*/
}
}
for (int i = 0; i < out_num; i++)
hd_out_th[i] += ETA_T * delta[2][i];
// 输入层和隐含层之间权值和阀值调整
for (int i = 0; i < in_num; i++) {
for (int j = 0; j < hd_num; j++) {
in_hd_weight[i][j] += ETA_W * delta[1][j] * out[0][i]; // 未加权值动量项
/* 动量项
* in_hd_weight[i][j] += (ETA_A * in_hd_last[i][j] + ETA_W
* delta[1][j] * out[0][i]); in_hd_last[i][j] = ETA_A *
* in_hd_last[i][j] + ETA_W delta[1][j] * out[0][i];
*/
}
}
for (int i = 0; i < hd_num; i++)
in_hd_th[i] += ETA_T * delta[1][i];
}
// 符号函数sign
public int Sign(double x) {
if (x > 0)
return 1;
else if (x < 0)
return -1;
else
return 0;
}
// 返回最大值
public double Maximum(double x, double y) {
if (x >= y)
return x;
else
return y;
}
// 返回最小值
public double Minimum(double x, double y) {
if (x <= y)
return x;
else
return y;
}
// log-sigmoid函数
public double Sigmoid(double x) {
return (double) (1 / (1 + Math.exp(-x)));
}
// log-sigmoid函数的倒数
public double SigmoidDerivative(double y) {
return (double) (y * (1 - y));
}
/* // tan-sigmoid函数
public double TSigmoid(double x) {
return (double) ((1 - Math.exp(-x)) / (1 + Math.exp(-x)));
}
// tan-sigmoid函数的倒数
public double TSigmoidDerivative(double y) {
return (double) (1 - (y * y));
}*/
// 分类预测函数
public ArrayList<ArrayList<Double>> ForeCast(
ArrayList<ArrayList<Double>> arraylist) {
ArrayList<ArrayList<Double>> alloutlist = new ArrayList<>();
ArrayList<Double> outlist = new ArrayList<Double>();
int datanum = arraylist.size();
for (int cnd = 0; cnd < datanum; cnd++) {
for (int i = 0; i < in_num; i++)
out[0][i] = arraylist.get(cnd).get(i); // 为输入节点赋值
Forward();
for (int i = 0; i < out_num; i++) {
if (out[2][i] > 0 && out[2][i] < 0.5)
out[2][i] = 0;
else if (out[2][i] > 0.5 && out[2][i] < 1) {
out[2][i] = 1;
}
outlist.add(out[2][i]);
//System.out.println( out[2][i] );
}
alloutlist.add(outlist);
outlist = new ArrayList<Double>();
outlist.clear();
}
return alloutlist;
}
}
package bp;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
class DataUtil {
private ArrayList<ArrayList<Double>> alllist = new ArrayList<ArrayList<Double>>(); // 存放所有数据
private ArrayList<String> outlist = new ArrayList<String>(); // 存放输出数据,索引对应每个everylist的输出
private ArrayList<String> checklist = new ArrayList<String>(); //存放测试集的真实输出字符串
private int in_num = 0;
private int out_num = 0; // 输入输出数据的个数
private int type_num = 0; // 输出的类型数量
private double[][] nom_data; //归一化输入数据中的最大值和最小值
private int in_data_num = 0; //提前获得输入数据的个数
// 获取输出类型的个数
public int GetTypeNum() {
return type_num;
}
// 设置输出类型的个数
public void SetTypeNum(int type_num) {
this.type_num = type_num;
}
// 获取输入数据的个数
public int GetInNum() {
return in_num;
}
// 获取输出数据的个数
public int GetOutNum() {
return out_num;
}
// 获取所有数据的数组
public ArrayList<ArrayList<Double>> GetList() {
return alllist;
}
// 获取输出为字符串形式的数据
public ArrayList<String> GetOutList() {
return outlist;
}
// 获取输出为字符串形式的数据
public ArrayList<String> GetCheckList() {
return checklist;
}
//返回归一化数据所需最大最小值
public double[][] GetMaxMin(){
return nom_data;
}
// 读取文件初始化数据
public void ReadFile( String filepath, String sep, int flag ) throws Exception {
ArrayList<Double> everylist = new ArrayList<Double>(); // 存放每一组输入输出数据
int readflag = flag; // flag=0,train;flag=1,test
String encoding = "GBK"; //编码格式"GBK"
File file = new File(filepath);
if (file.isFile() && file.exists()) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader(new FileInputStream( file ), encoding);// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
int in_number = 0;
//将每一行的数据按','截取字符串
String splits[] = lineTxt.split(sep);
if (readflag == 0) {
for (int i = 0; i < splits.length; i++)
try {
//对数据进行归一化处理
everylist.add(Normalize(Double.valueOf(splits[i]),nom_data[i][0],nom_data[i][1]));
in_number++;
} catch (Exception e) {
//outlist:存放输出数据的类型
if (!outlist.contains(splits[i]))
outlist.add(splits[i]); // 存放字符串形式的输出数据
//初始化[-,-,-,-,0.0,0.0,0.0]
for (int k = 0; k < type_num; k++) {
everylist.add(0.0);
}
// 0-3:四个属性 4-6:输出节点处理,进行one-hot编程
// outlist.indexOf(splits[i]):获取第几位的不为空
// everylist 存放着[ 0 - 6 ] 位
everylist.set(in_number + outlist.indexOf(splits[i]),1.0);
}
} else if (readflag == 1) {
for (int i = 0; i < splits.length; i++)
try {
everylist.add(Normalize(Double.valueOf(splits[i]),nom_data[i][0],nom_data[i][1]));
in_number++;
} catch (Exception e) {
checklist.add(splits[i]); // 存放字符串形式的输出数据
}
}
alllist.add(everylist); // 存放所有数据
in_num = in_number;
out_num = type_num;
everylist = new ArrayList<Double>();
everylist.clear();
}
bufferedReader.close();
}
}
//向文件写入分类结果
public void WriteFile(String filepath, ArrayList<ArrayList<Double>> list, int in_number, ArrayList<String> resultlist) throws IOException{
File file = new File(filepath);
FileWriter fw = null;
BufferedWriter writer = null;
try {
fw = new FileWriter(file);
writer = new BufferedWriter(fw);
for(int i=0;i<list.size();i++){
for(int j=0;j<in_number;j++){
writer.write(list.get(i).get(j)+",");
}
writer.write(resultlist.get(i));
writer.newLine();
}
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}finally{
writer.close();
fw.close();
}
}
//学习样本归一化,找到输入样本数据的最大值和最小值
public void NormalizeData(String filepath) throws IOException{
//提前获得输入数据的个数
GetBeforIn(filepath);
int flag=1;
//nom_data存放输入节点的max和min in_data_num:4
nom_data = new double[in_data_num][2];
String encoding = "GBK";
File file = new File(filepath);
if ( file.isFile() && file.exists() ) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader( new FileInputStream(file), encoding );// 考虑到编码格式
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
String splits[] = lineTxt.split(","); // 按','截取字符串
for (int i = 0; i < splits.length-1; i++){
if(flag==1){
nom_data[i][0]=Double.valueOf(splits[i]);
nom_data[i][1]=Double.valueOf(splits[i]);
}
else{
if(Double.valueOf(splits[i])>nom_data[i][0])
nom_data[i][0]=Double.valueOf(splits[i]);
if(Double.valueOf(splits[i])<nom_data[i][1])
nom_data[i][1]=Double.valueOf(splits[i]);
}
}
flag=0;
}
bufferedReader.close();
}
}
//归一化前获得输入数据的个数
public void GetBeforIn(String filepath) throws IOException{
String encoding = "GBK";
File file = new File(filepath);
if (file.isFile() && file.exists()) { // 判断文件是否存在
InputStreamReader read = new InputStreamReader(new FileInputStream(
file), encoding);// 考虑到编码格式
//提前获得输入数据的个数
BufferedReader beforeReader = new BufferedReader(read);
String beforetext = beforeReader.readLine();
String splits[] = beforetext.split(",");
in_data_num = splits.length-1;
beforeReader.close();
}
}
//归一化公式 -- 用于读取文件中
public double Normalize(double x, double max, double min){
double y = 0.1+0.8*(x-min)/(max-min);
return y;
}
}
package bp;
import java.util.ArrayList;
public class Test {
public static void main(String args[]) throws Exception {
//alllist = 4 + 3 即输入和输出
ArrayList<ArrayList<Double>> alllist = new ArrayList<ArrayList<Double>>(); // 存放所有数据
ArrayList<String> outlist = new ArrayList<String>(); // 存放分类的字符串
int in_num = 0, out_num = 0; // 输入输出数据的个数
DataUtil dataUtil = new DataUtil(); // 初始化数据
dataUtil.NormalizeData("C:\\Users\\Administrator\\Downloads\\input.txt"); //对数据进行归一化处理
dataUtil.SetTypeNum(3); // 设置输出类型的数量
dataUtil.ReadFile("C:\\Users\\Administrator\\Downloads\\input.txt", ",", 0);
in_num = dataUtil.GetInNum(); // 获得输入数据的个数
out_num = dataUtil.GetOutNum(); // 获得输出数据的个数(个数代表类型个数)
alllist = dataUtil.GetList(); // 获得初始化后的数据
outlist = dataUtil.GetOutList();
//System.out.println(outlist);
System.out.print("分类的类型:");
for(int i =0 ;i<outlist.size();i++)
System.out.print(outlist.get(i)+" ");
System.out.println();
System.out.println("训练集的数量:"+alllist.size());
BPNN bpnn = new BPNN();
// 训练
System.out.println("Train Start!");
System.out.println(".............");
bpnn.Train(in_num, out_num, alllist);
System.out.println("Train End!");
// 测试
DataUtil testUtil = new DataUtil();
testUtil.NormalizeData("C:\\Users\\Administrator\\Downloads\\test.txt");
testUtil.SetTypeNum(3); // 设置输出类型的数量
testUtil.ReadFile("C:\\Users\\Administrator\\Downloads\\test.txt", ",", 1);
ArrayList<ArrayList<Double>> testList = new ArrayList<ArrayList<Double>>();
ArrayList<ArrayList<Double>> resultList = new ArrayList<ArrayList<Double>>();
ArrayList<String> normallist = new ArrayList<String>(); // 存放测试集标准的输出字符串
ArrayList<String> resultlist = new ArrayList<String>(); // 存放测试集计算后的输出字符串
int right = 0; // 分类正确的数量
int type_num = 0; // 类型的数量
int all_num = 0; //测试集的数量
type_num = outlist.size();
testList = testUtil.GetList(); // 获取测试数据
normallist = testUtil.GetCheckList();
//int errorcount = 0; // 分类错误的数量
resultList = bpnn.ForeCast(testList); // 测试
all_num = resultList.size();
//resultList:[-,-,-] normallist:[-] outlist:[-,-,-]
//System.out.println(resultList);
//System.out.println(normallist);
//System.out.println(outlist);
//临时存放结果
ArrayList<String> Temp = new ArrayList<String>();
//resultList=[30][3] 这里的输出有问题???解决方式:增加一个临时存放结果的数组
for (int i = 0; i < resultList.size(); i++) {
String checkString = "unknow";
for (int j = 0; j < type_num; j++) {
//System.out.println(resultList.get(i).get(j));
if( resultList.get(i).get(j) == 1.0 ){
//System.out.println(outlist.get(j));
checkString = outlist.get(j);
Temp.add(checkString);
}
else{
resultlist.add(checkString);
}
}
/* if(checkString.equals("unknow"))
errorcount++;*/
//normallist.get(i)为实际的判定值
if(checkString.equals(normallist.get(i)))
right++;
}
//System.out.println(Temp);
testUtil.WriteFile("C:\\Users\\Administrator\\Downloads\\result.txt",testList,in_num,Temp);
System.out.println("测试集的数量:"+ all_num );
System.out.println("分类正确的数量:"+ right );
//System.out.println("分类正确的数量:"+(new Double(right)).intValue());
System.out.println("算法的分类正确率为:"+ (new Double( (double) right/all_num )));
System.out.println("分类结果存储在:C:\\Users\\Administrator\\Downloads\\result.txt");
//bpnn.GetError(1);
}
}















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









