







什么是spark
定义:Apache Spark是用于大规模数据处理的统一分析引擎。
简单来说spark是一种分布式的计算框架,用于调度成百上千的服务器集群,计算TB,PB,乃至EB级别的海量数据。
spark作为全球顶级的分布式计算机框架,支持众多的编程语言开发,而python 语言,则是spark重点支持的方向。
spark对python语言的支持,重点体现在,python第三方库:PySpark之上。
PySpark是由Spark官方开发的python语言的第三方库。

pyspark库的安装
打开cmd输入命令行:
pip install pyspark

清华大学镜像网站下载:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
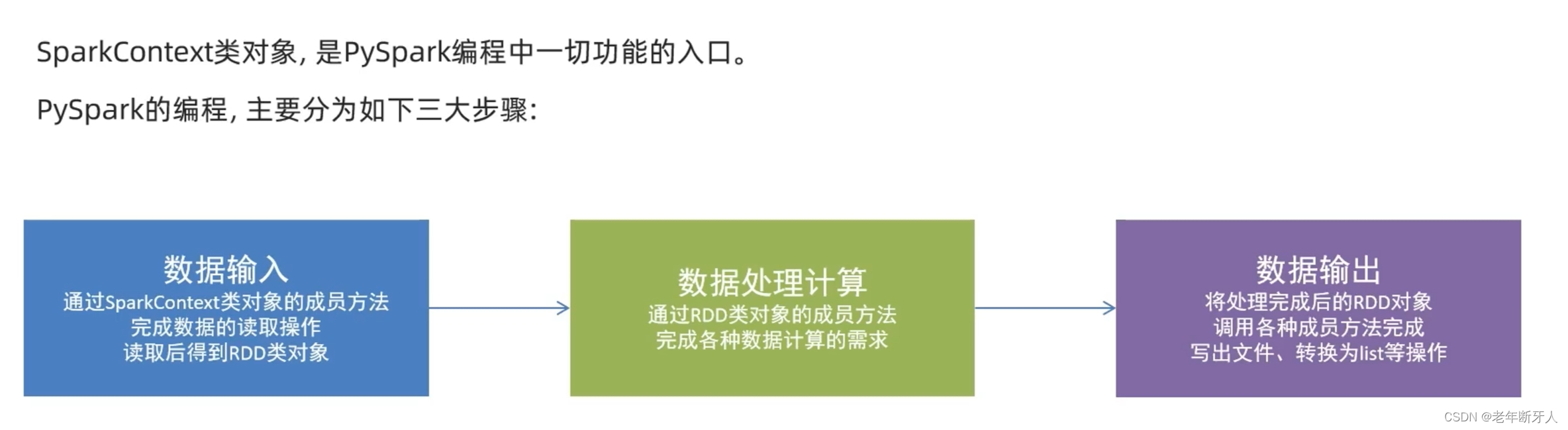
构建pyspark执行环境入口对象
想要使用pyspark库完成数据处理,首先需要构建一个执行环境入口对象。
pyspark的执行环境入口对象是:类SparkContext 的类对象。
# 导包
from pyspark import SparkConf,SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").\
setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
# 打印pyspark的运行版本
print(sc.version)
#停止sparkContext对象的运行(停止PySpark程序)
sc.stop()

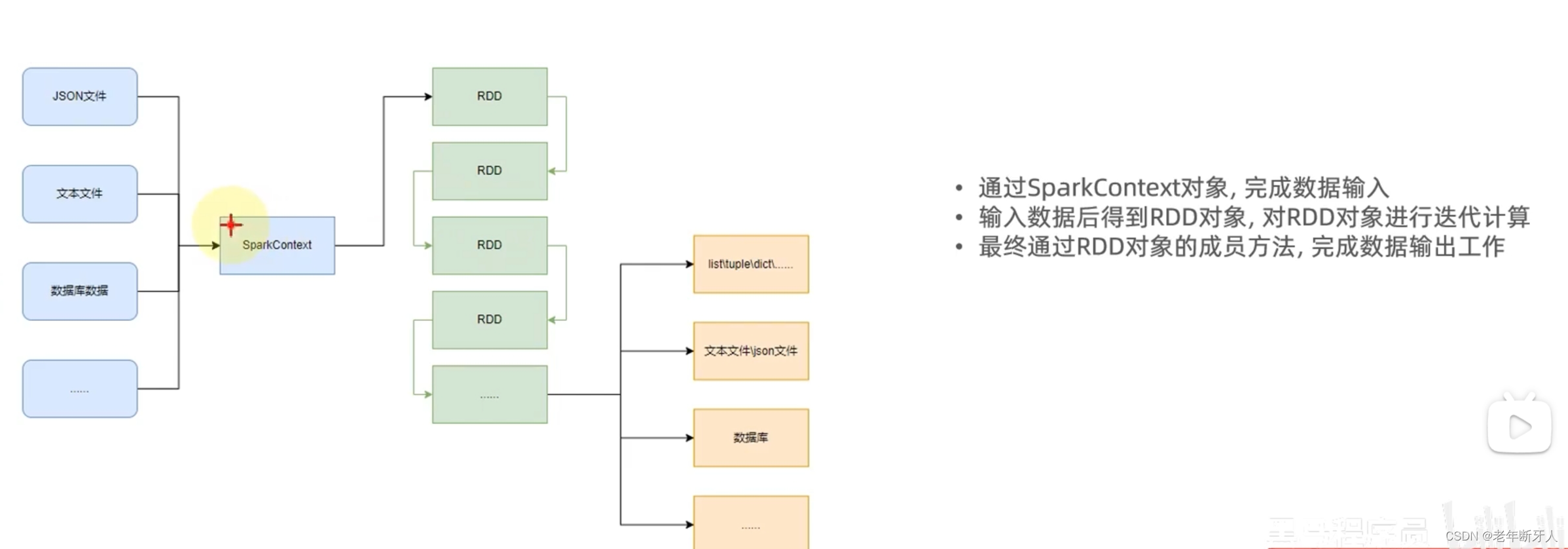
spark编程模型















 1505
1505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











