










原理可以看这里
首先来看二维情况
这个在原理篇已经讲过了:

代码怎么实现呢?最简单的思路当然是,和原论文一样,使用一个矩阵乘法实现。但是当维度很大时,稀疏矩阵的计算效率很低,我们可以采用一些更加高效的计算方法。
只关注
q
0
q_0
q0和
q
1
q_1
q1,会发现,两个维度中的
q
0
q_0
q0都是正的,而
q
1
q_1
q1都是负的,那么如果我们定义
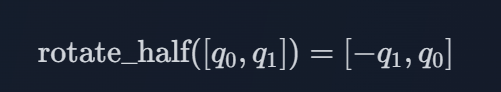
则有:

这就是二维时的计算思路了!
多维时,应该怎么做呢?
这里同样用简单的四维来举例。先说说按照原始论文,应该怎么计算。
假设有:

那么,
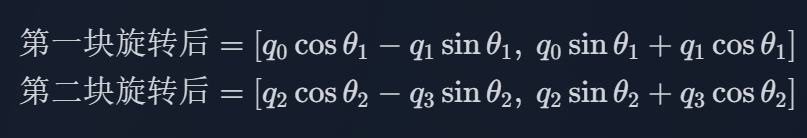
最终旋转后的向量为:

到这里为止,一切顺利。接下来进入
代码环节:
首先给出Qwen2中的rotate_half函数实现:
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
这个函数的功能就不解释了。但也许有读者和我一样,第一眼看上去感觉怪怪的:因为数学公式中,是对每两个相邻维度进行前乘旋转矩阵,但这里是对最后一个维度“整块”进行操作。它们之间的区别有一点像这篇文章提到的整块/逐行的分别。
但实际上,embedding维度上的每一个分量都是平等的,并不存在顺序关系,因此我们依然可以对它们两两进行操作:
我们现在得到了rotate_half的输出:

只需要对维度0和维度2虚使用同样的角度,再对维度1和维度3使用同样的角度就可以了。
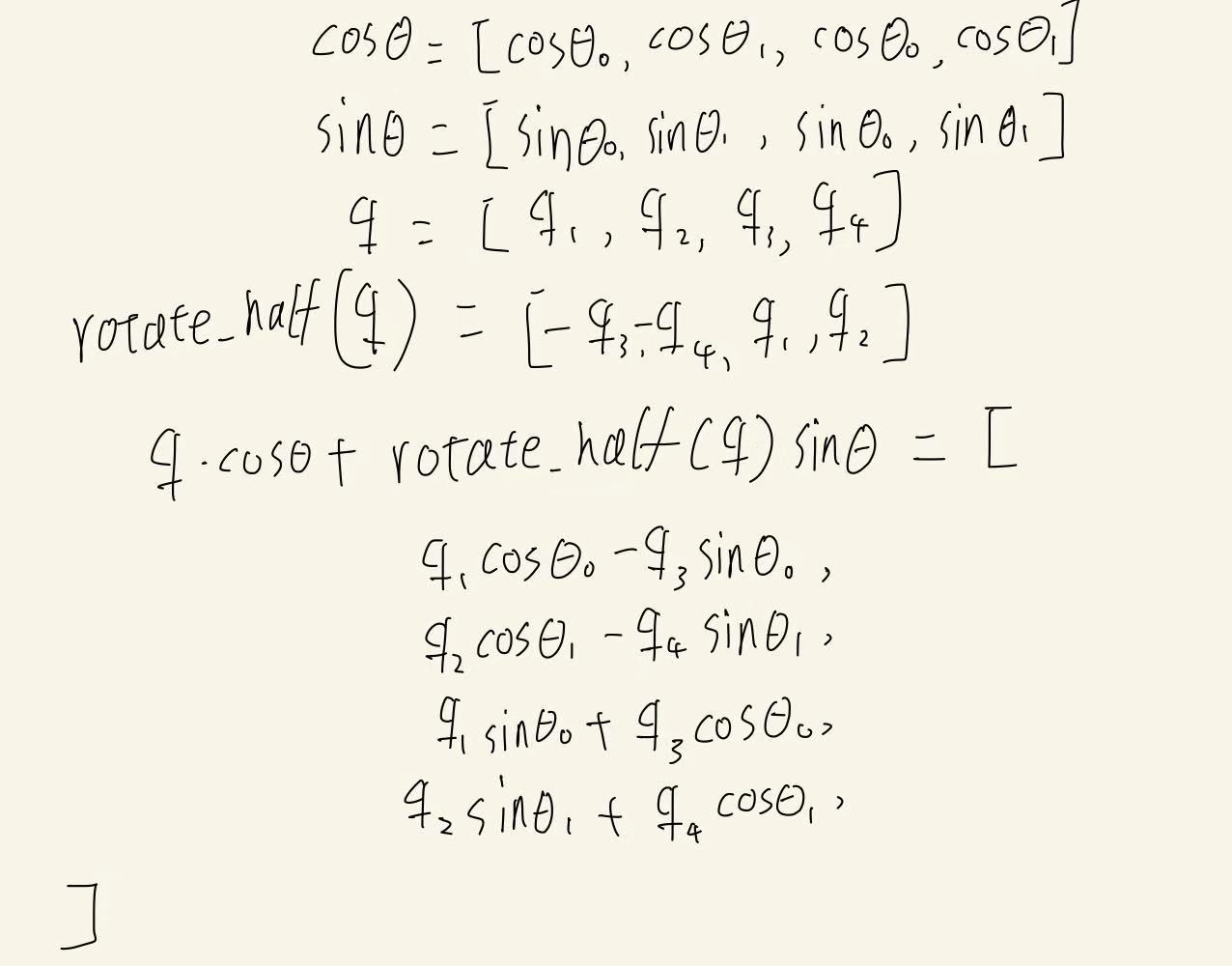
(这里发现我手写的q的下标是从1,而不是从0开始的,就懒得重写啦)
也就是说,我们分组的方式变了,从原来的依次两两一组,变成了前d//2维度中,每一个维度i与维度i+d//2分为一组了。
class Qwen2RotaryEmbedding(nn.Module):
def __init__(self, config: Qwen2Config, device=None):
super().__init__()
# BC: "rope_type" was originally "type"
if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
else:
self.rope_type = "default"
self.max_seq_len_cached = config.max_position_embeddings
self.original_max_seq_len = config.max_position_embeddings
self.config = config
self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
self.register_buffer("inv_freq", inv_freq, persistent=False)
self.original_inv_freq = self.inv_freq
@torch.no_grad()
@dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
def forward(self, x, position_ids):
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
position_ids_expanded = position_ids[:, None, :].float()
device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
with torch.autocast(device_type=device_type, enabled=False): # Force float32
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos() * self.attention_scaling
sin = emb.sin() * self.attention_scaling
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
这里可以看下qwen2源码中,forward函数的返回值就分别对应了之前提到的cos向量和sin向量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









