







前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。来源于哔哩哔哩博主“霹雳吧啦Wz”,博主学习作为笔记记录,欢迎大家一起讨论学习交流。
一、搭建ShuffleNet网络
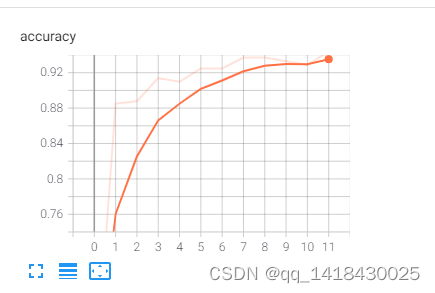
用ShuffleNet v2学习,轮次训练11轮次(代码),个epoch大概7-8分钟。



二、代码部分
1.module.py----定义ShuffleNet的网络结构
代码如下(示例):
from typing import List, Callable
import torch
from torch import Tensor
import torch.nn as nn
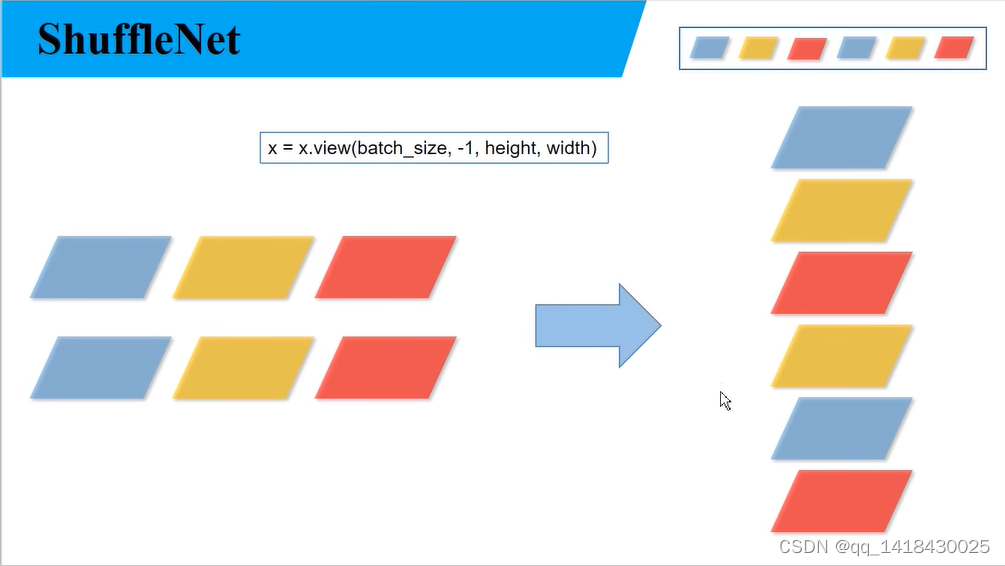
def channel_shuffle(x: Tensor, groups: int) -> Tensor:#这个部分实现channe shuffle思想,见博客图
batch_size, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batch_size, -1, height, width)
return x
class InvertedResidual(nn.Module):#Shuffle Net的block模块inverted residual
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]:#判断步距是否是1和2
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0
branch_features = output_c // 2
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):#构建ShuffleNetV2
def __init__(self,
stages_repeats: List[int],
stages_out_channels: List[int],
num_classes: int = 1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations for mypy
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]# 步距为2
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))# 步距为1
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3]) # global pool 2,3对应高度和宽度两个维度 只剩下batch和channel维度
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def shufflenet_v2_x0_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 0.5x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x0.5-f707e7126e.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 48, 96, 192, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 116, 232, 464, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x1_5(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x1_5-3c479a10.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 176, 352, 704, 1024],
num_classes=num_classes)
return model
def shufflenet_v2_x2_0(num_classes=1000):
"""
Constructs a ShuffleNetV2 with 1.0x output channels, as described in
`"ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design"
<https://arxiv.org/abs/1807.11164>`.
weight: https://download.pytorch.org/models/shufflenetv2_x2_0-8be3c8ee.pth
:param num_classes:
:return:
"""
model = ShuffleNetV2(stages_repeats=[4, 8, 4],
stages_out_channels=[24, 244, 488, 976, 2048],
num_classes=num_classes)
return model
2.train.py----加载数据集并进行训练,训练集计算loss,测试集计算accuracy,保存训练好的网络参数
代码如下(示例):
import os
import math
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torch.optim.lr_scheduler as lr_scheduler
from model import shufflenet_v2_x1_0
from my_dataset import MyDataSet
from utils import read_split_data, train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(args)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer = SummaryWriter()
if os.path.exists("./weights") is False:
os.makedirs("./weights")
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
# 如果存在预训练权重则载入
model = shufflenet_v2_x1_0(num_classes=args.num_classes).to(device)
if args.weights != "":
if os.path.exists(args.weights):
weights_dict = torch.load(args.weights, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
print(model.load_state_dict(load_weights_dict, strict=False))
else:
raise FileNotFoundError("not found weights file: {}".format(args.weights))
# 是否冻结权重
if args.freeze_layers:
for name, para in model.named_parameters():
# 除最后的全连接层外,其他权重全部冻结
if "fc" not in name:
para.requires_grad_(False)
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=4E-5)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
for epoch in range(args.epochs):
# train
mean_loss = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
scheduler.step()
# validate
acc = evaluate(model=model,
data_loader=val_loader,
device=device)
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
tags = ["loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--lrf', type=float, default=0.1)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="G:/深度学习/deep-learning-for-image-processing-master/data_set/flower_data/flower_photos")
# shufflenetv2_x1.0 官方权重下载地址
# https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pth
parser.add_argument('--weights', type=str, default='./shufflenetv2_x1.pth',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=False)#False训练所有层结构 True训练全连接层
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
3.predict.py——得到训练好的网络参数后,用自己找的图像进行分类测试
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import shufflenet_v2_x1_0
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = shufflenet_v2_x1_0(num_classes=5).to(device)
# load model weights
model_weight_path = "./weights/model-29.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
三、ShuffleNet v1

channel shuffle:用组卷积和DW卷积
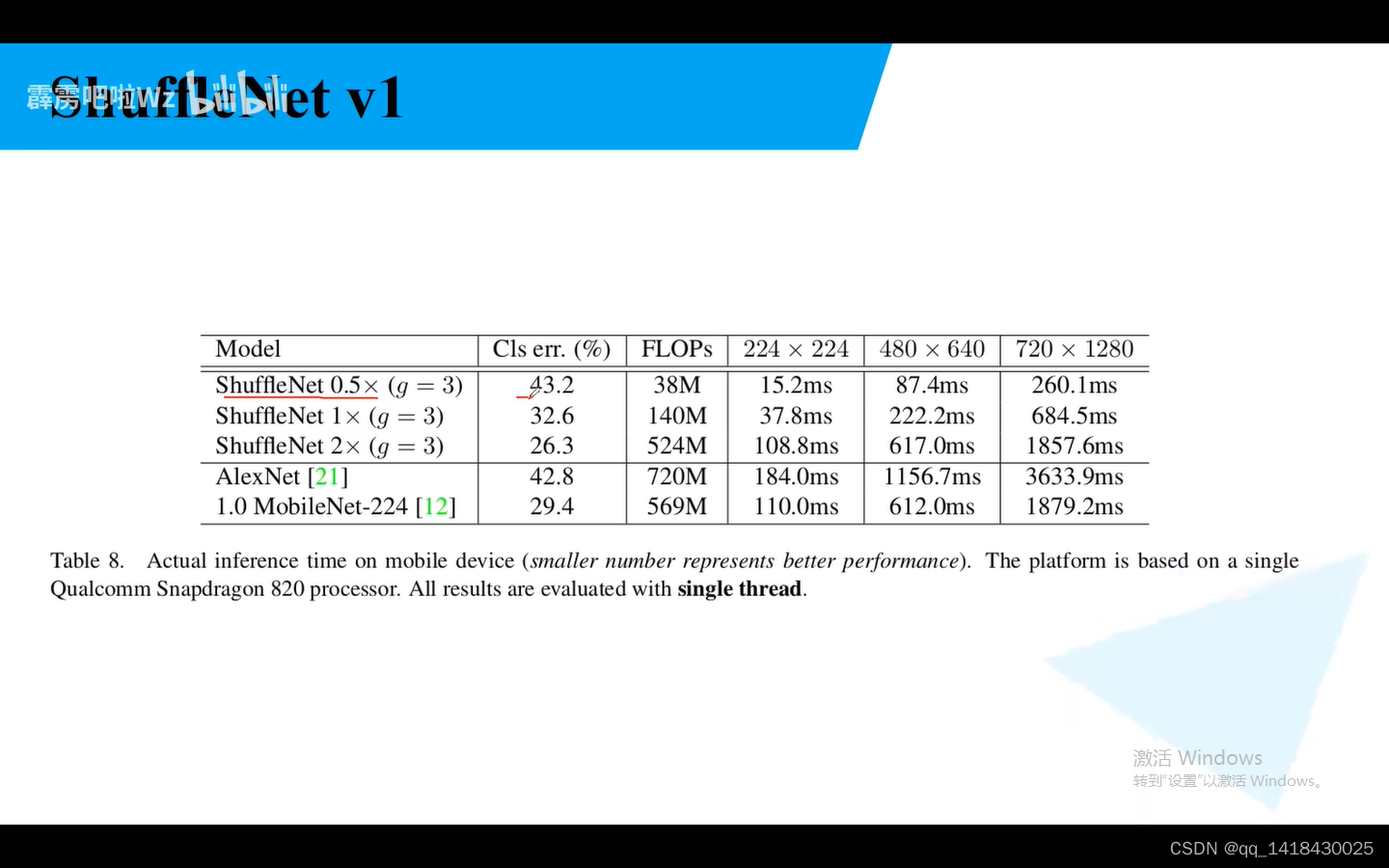
对比AlexNet,ShuffleNet 0.5容错率差不多,推理时间15.2ms,AlexNet是10ms,说明ShffleNet非常的轻量级。
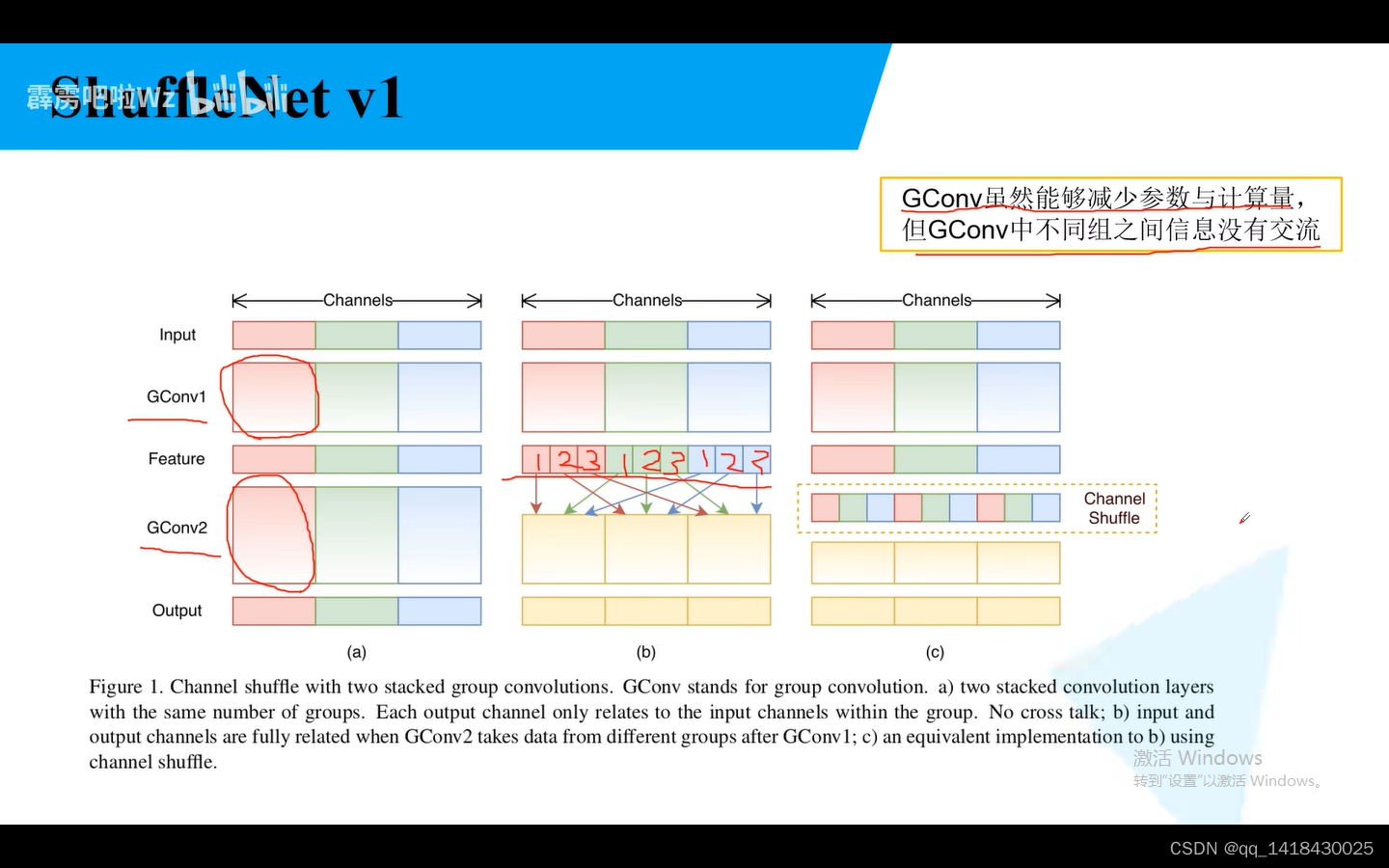
普通的组卷积是可以减少参数,但是不能使不同组卷积之间进行信息交流,所以提出了channel shuffle的概念。对于组卷积分成三组,每一组又分成三小组,把每一组对应位置索引的小组,组合在一起,构成一个新的组,这个组就包含了之前分组卷积没有的的各个组卷积的信息,实现了各组的channnel信息交流。
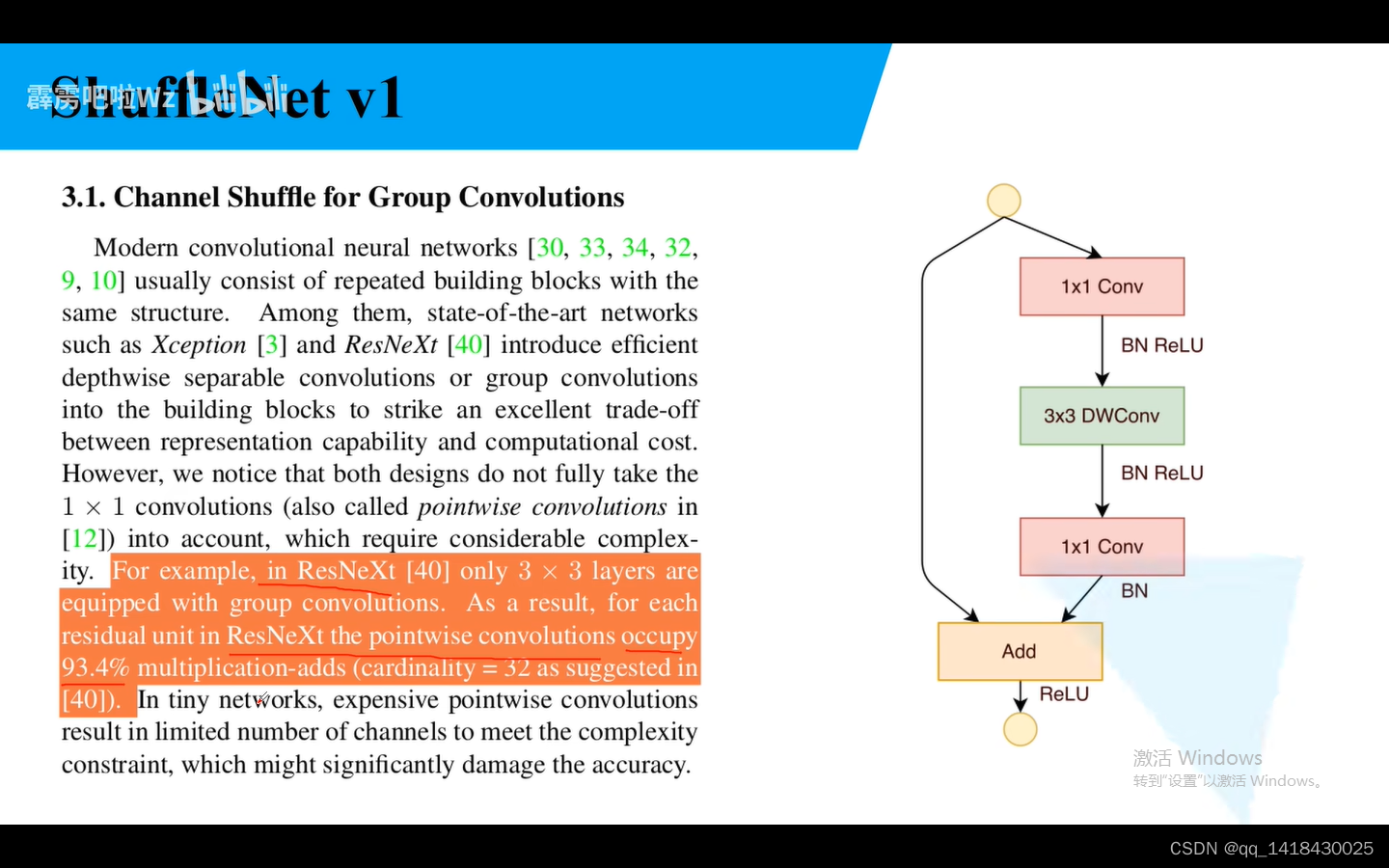
实验表明:ResNeXt的PW1x1的普通卷积理论上占据内存的百分之93.4.
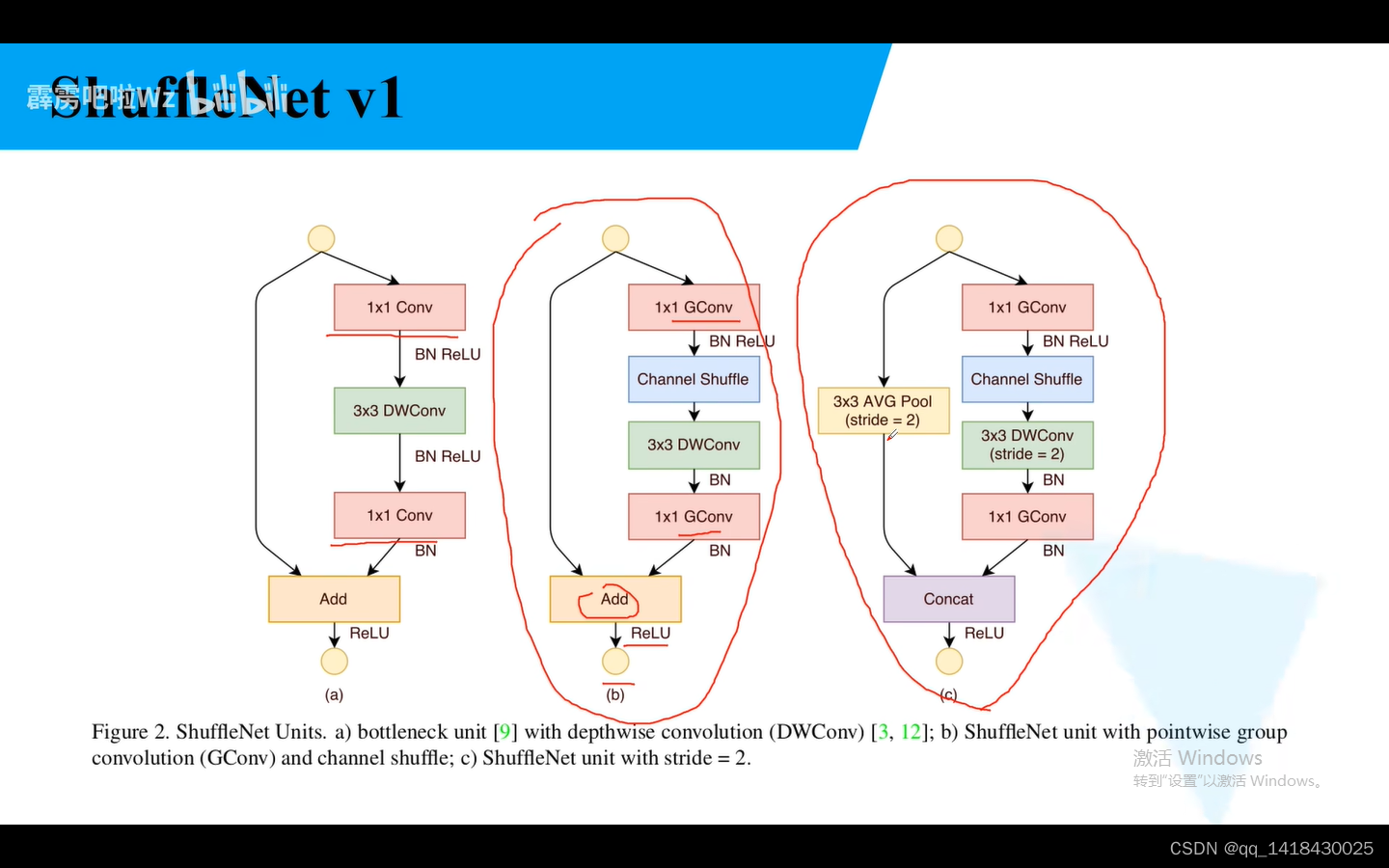
因为前面说了1x1的卷积占据内存比较大,所以将1x1卷积换成了组卷积。中间是针对stride=1的情况,右边是针对stride=2的情况。右图是步距为2,捷径是通过池化进行,之前是卷积,最终再进行concat相加。
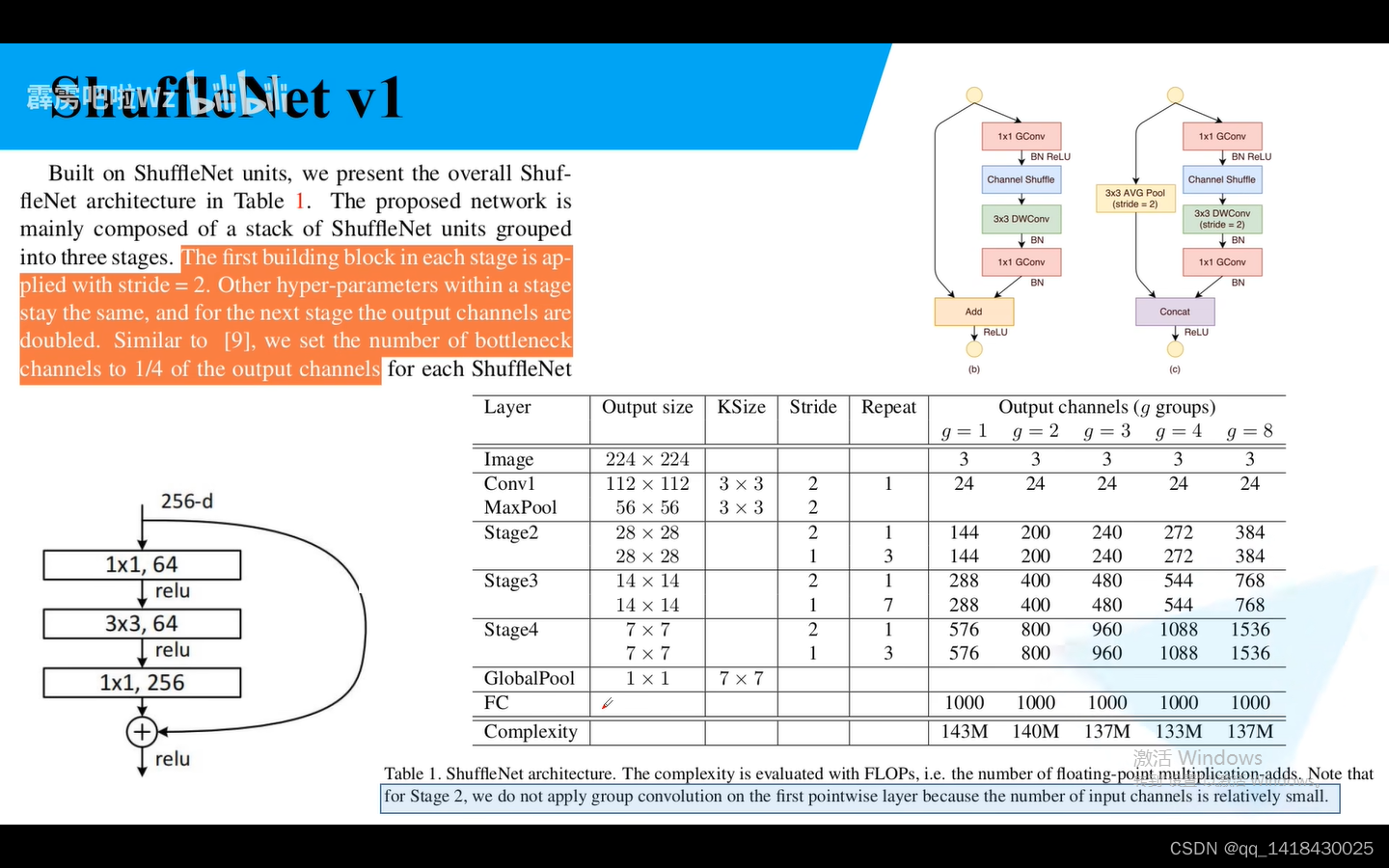
大部分采用g=3的情况,通过输入224x224的图像,经过第一个卷积Conv1,卷积核大小是3x3,步距为2,重复一次,输出特征矩阵channel是24(卷积核1使用24个卷积核),然后再经过stage2,stage3,stage4…经过stage2的时候,对步距为2的block堆叠1次,输出矩阵channel240,对步距为1的block堆叠3次,输出矩阵channel240。

对于每一个stage的第一个block步距都是2.对于下一个stage的输出矩阵的Chanel通道数翻倍。从表格里面也可以看出来。对于Resnet而言,第一个卷积核和第二个卷积核的个数是输出矩阵个数通道数的1/4.
对于ShffleNet,GConv和DConv是同样的道理,也是输出矩阵的通道数的1/4。
对于stage2,第一个卷积不是使用组卷积。
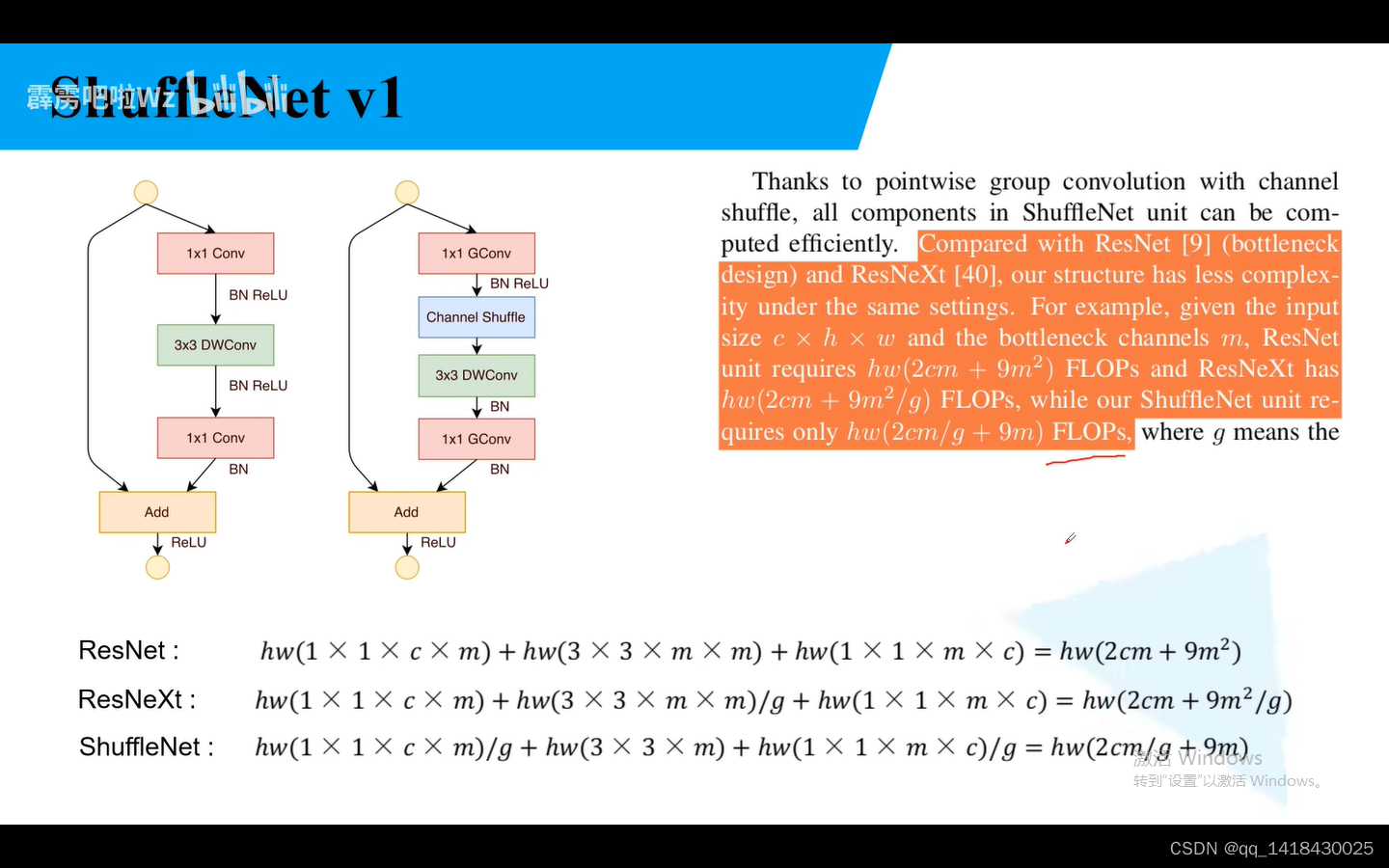
ResNeXt在ResNet基础上,在第二个3x3卷积上采用了组卷积。DW卷积是组卷积的一个特殊情况:当组卷积的分组数g=输入特征矩阵的深度Cin,输出矩阵深度=输入矩阵深度时候,分组卷积变成了DW卷积。
总结:ShuffleNet参数理论上计算量最小。主要思想是在Group 卷积后面加上一个channel shuffle模块,对于block而言,我们将1x1卷积替换成1x1组卷积。
四、ShuffleNet v2
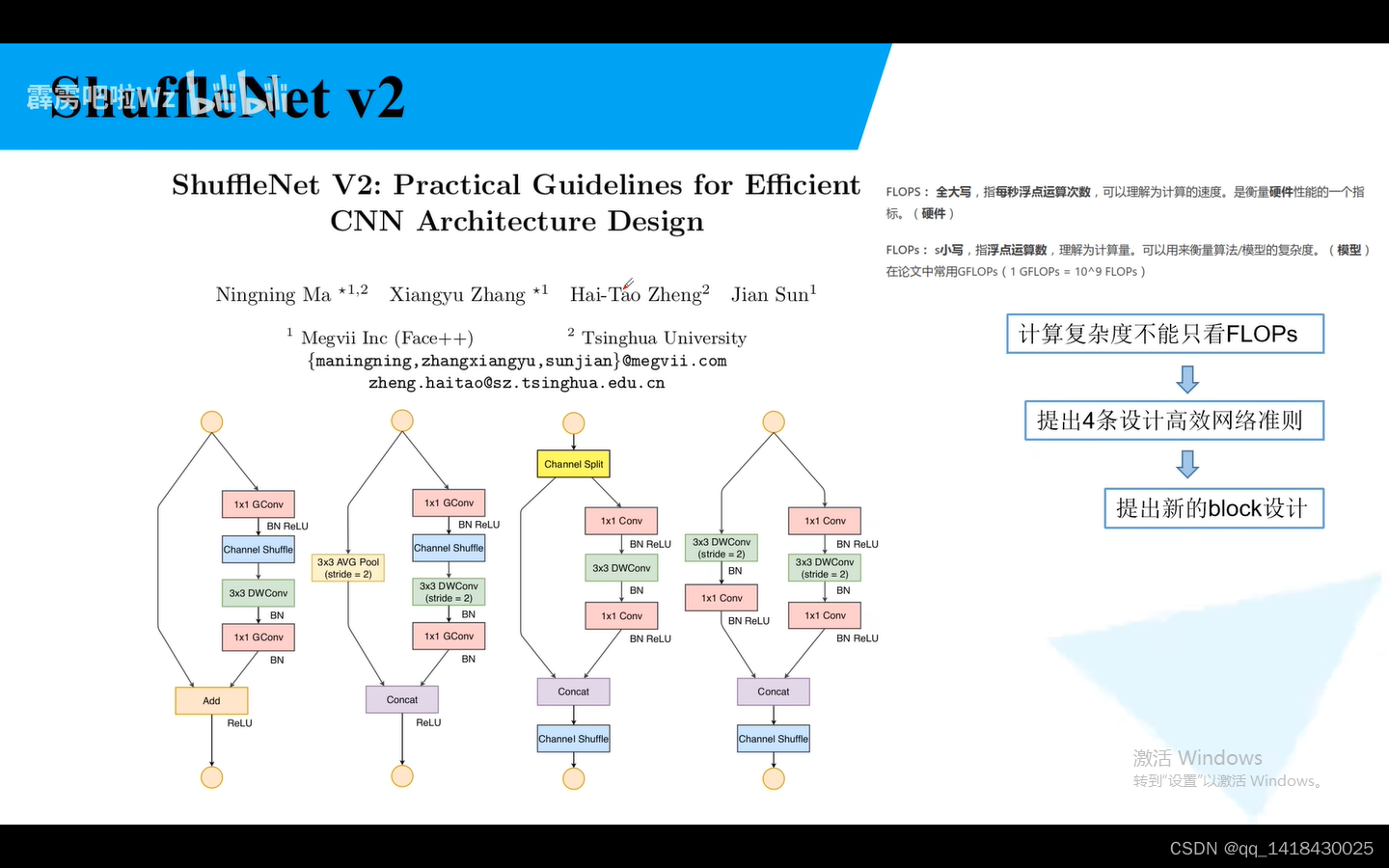
Flops:浮点运算数

就是不能仅仅看Flops,速度才是最直接的因素。MAC:内存访问时间成本。还需要考虑。并行等级。相同Flops时候,要看并行等级的高低。另外,相同的Flops在不同的平台也不一样
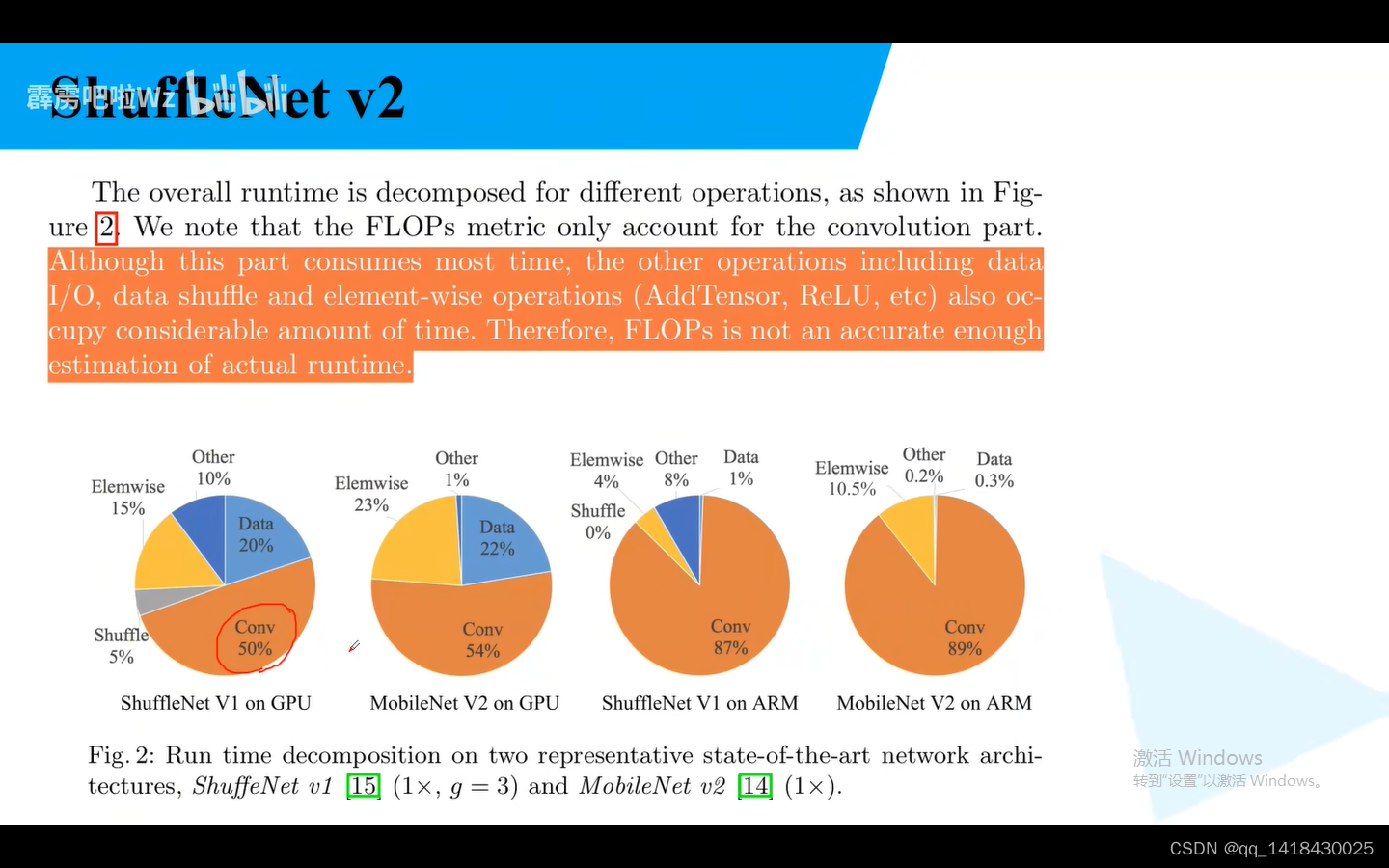
基于这个观点 作者提出了一些措施。


G1:当卷积层的输入特征矩阵与输出矩阵的channel相等时候MAC最小(Flops不变)
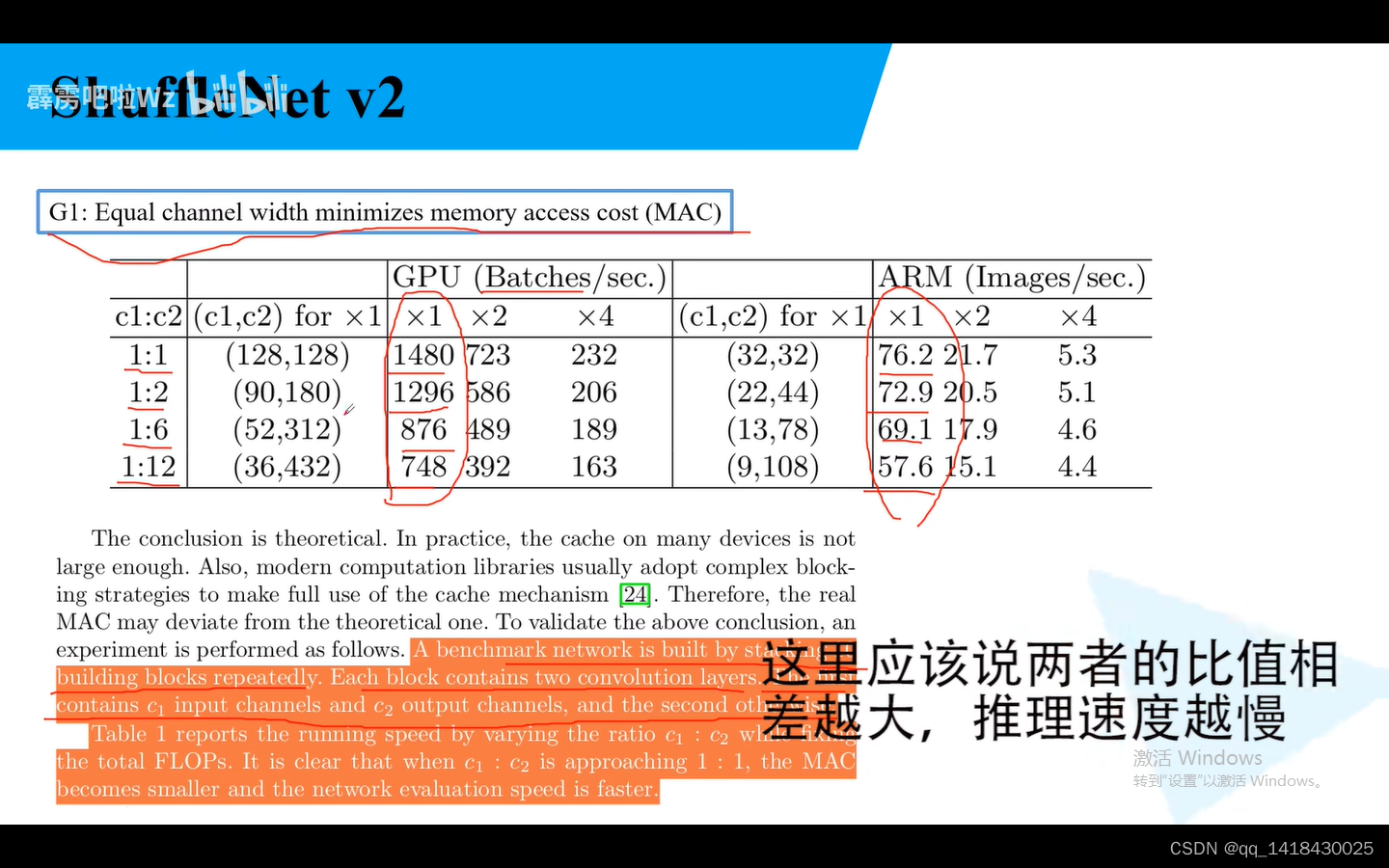
随着比值的增加,推理速度越来越慢。

G2:当GConv的groups增大时候(保持Flos不变),MAC也会增大。
hwc1:输入 hwc2:输出

随着g的增加,cpu和gpu都下降了。

G3:网络设计的碎片化程度(分支)越高,速度越慢。(右上角实验也可以说明)
碎片化结构能够提高模型的准确率,但是会降低效率。
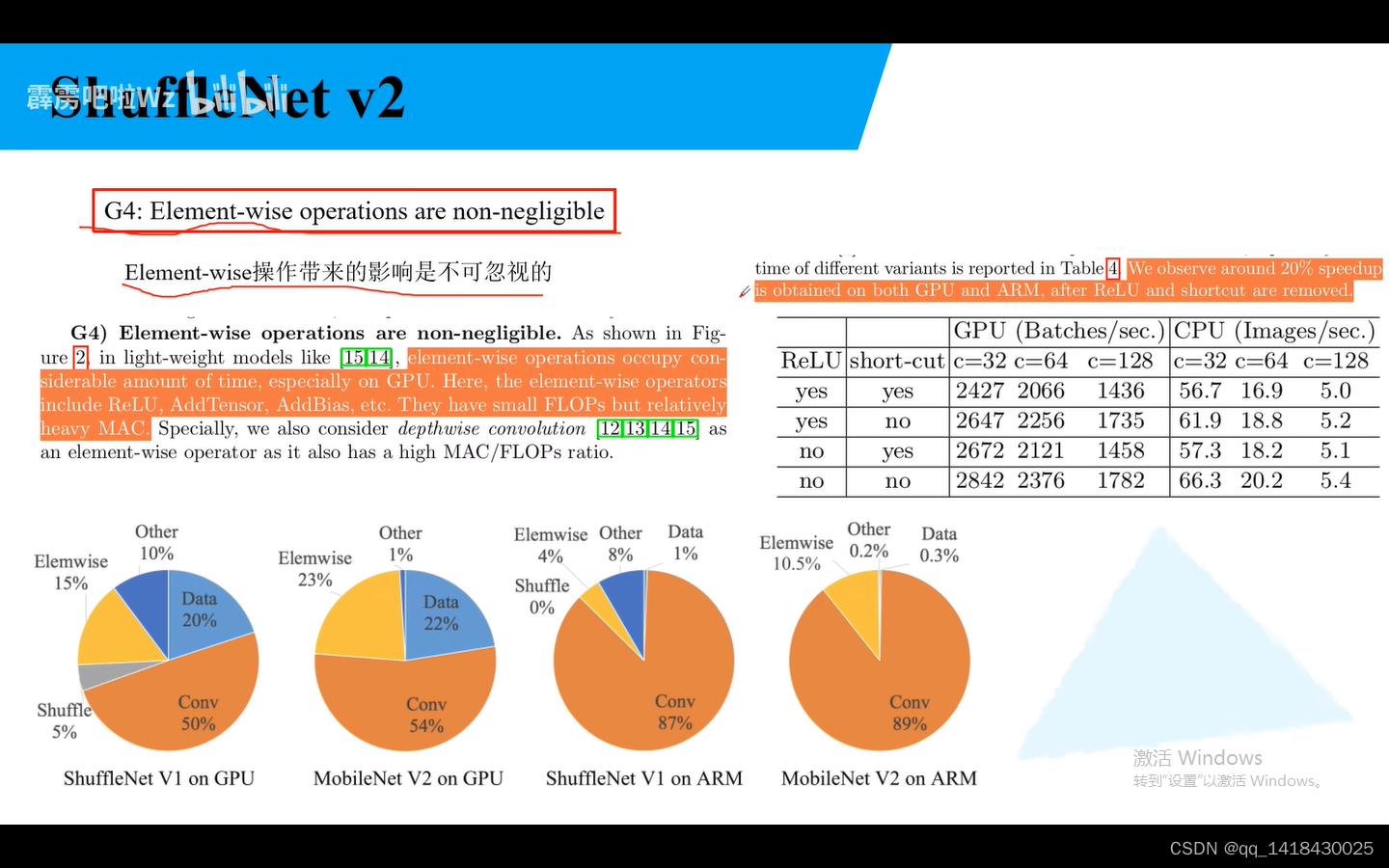
G4:Eliment-wise操作带来的影响不可忽视
Relu、AddTensor、AddBias等,Flops小,但是MAC较大。

总结:
1.平衡的convolutions:输入与输出特征矩阵channel尽可能为1
2.注意组卷积的groups:过多增加计算成本
3.减少分支
4.减少使用element-wise operations
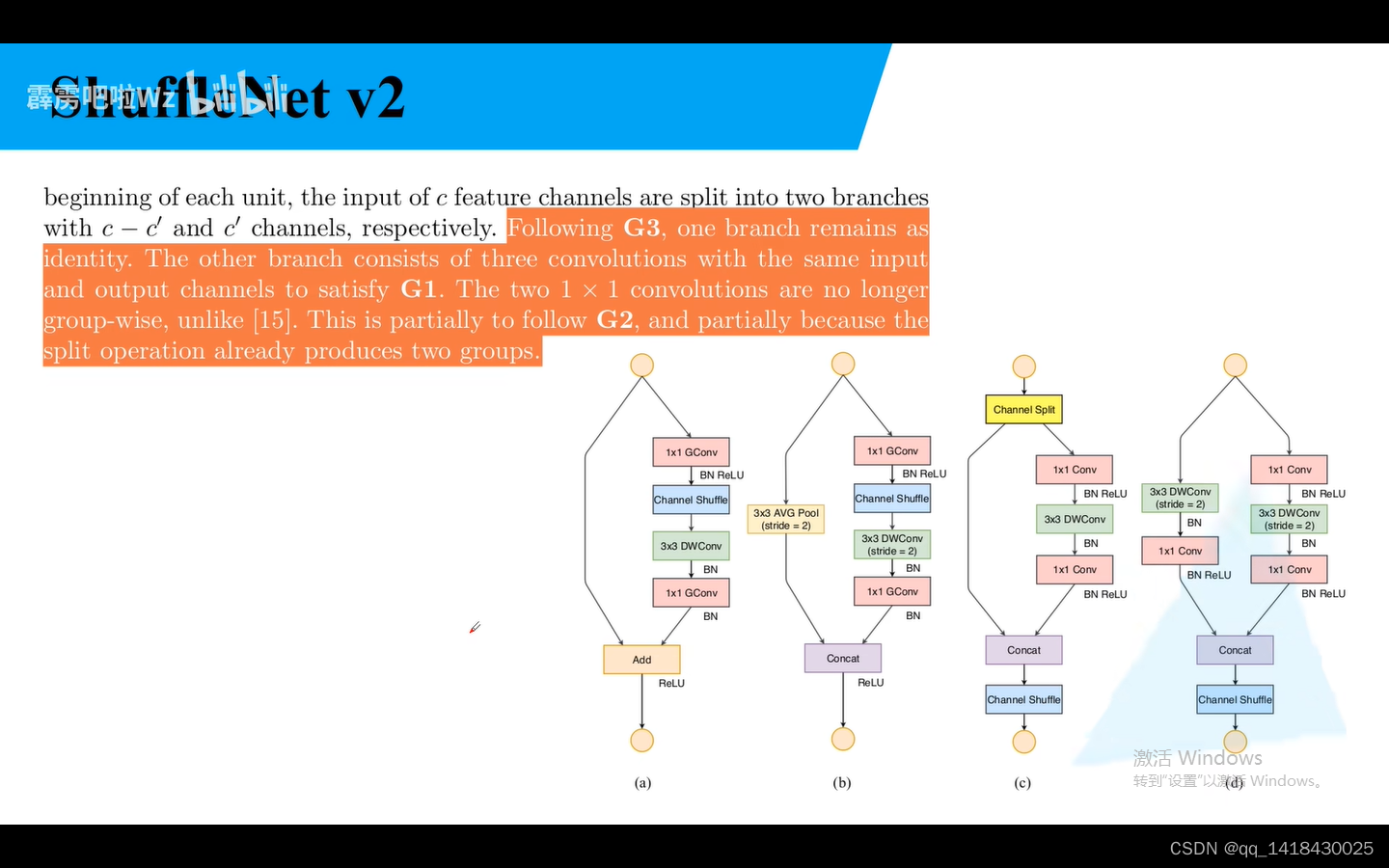
a是步距为1,b是步距为2的ShuffleNet的网络结构。
G3:减少分支
G1:平衡的convolutions:输入与输出特征矩阵channel尽可能为1
G2:注意组卷积的groups:过多增加计算成本
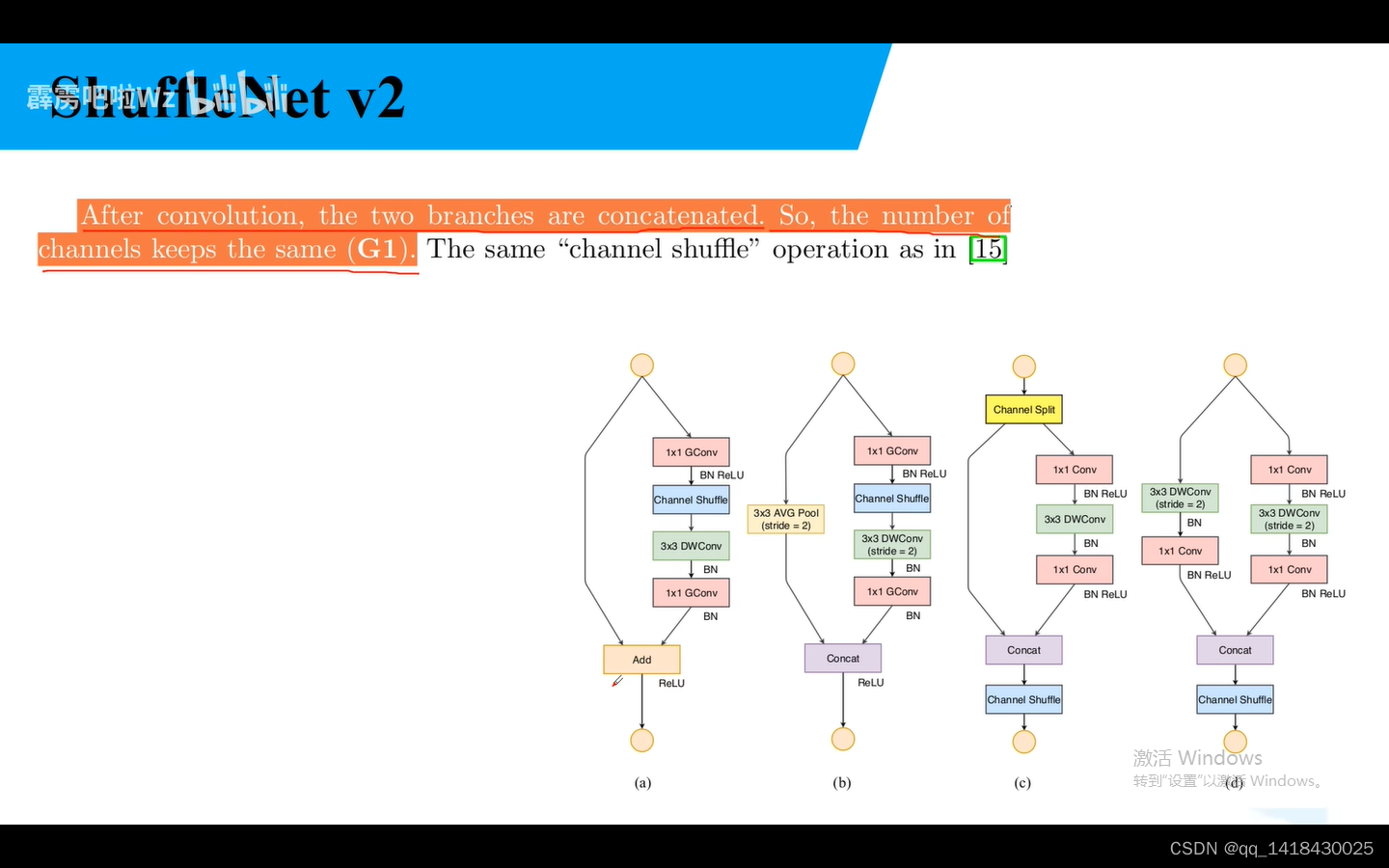
G1:平衡的convolutions:输入与输出特征矩阵channel尽可能为1
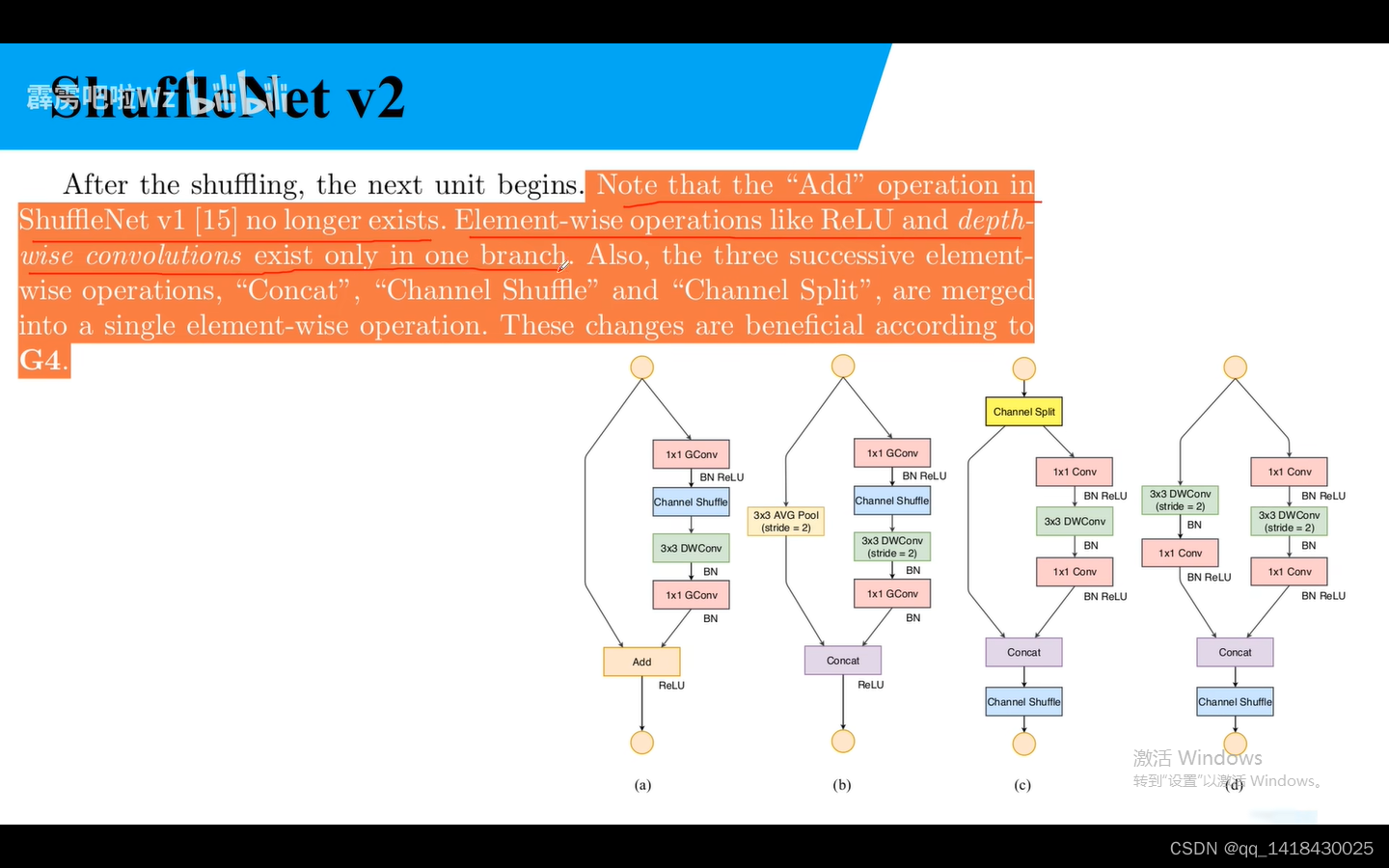
add在Shuffle NetV2中不存在,Relu仅仅在一个分支进行。也可以将Concat、Channel Shuffle、Channel Split合并。
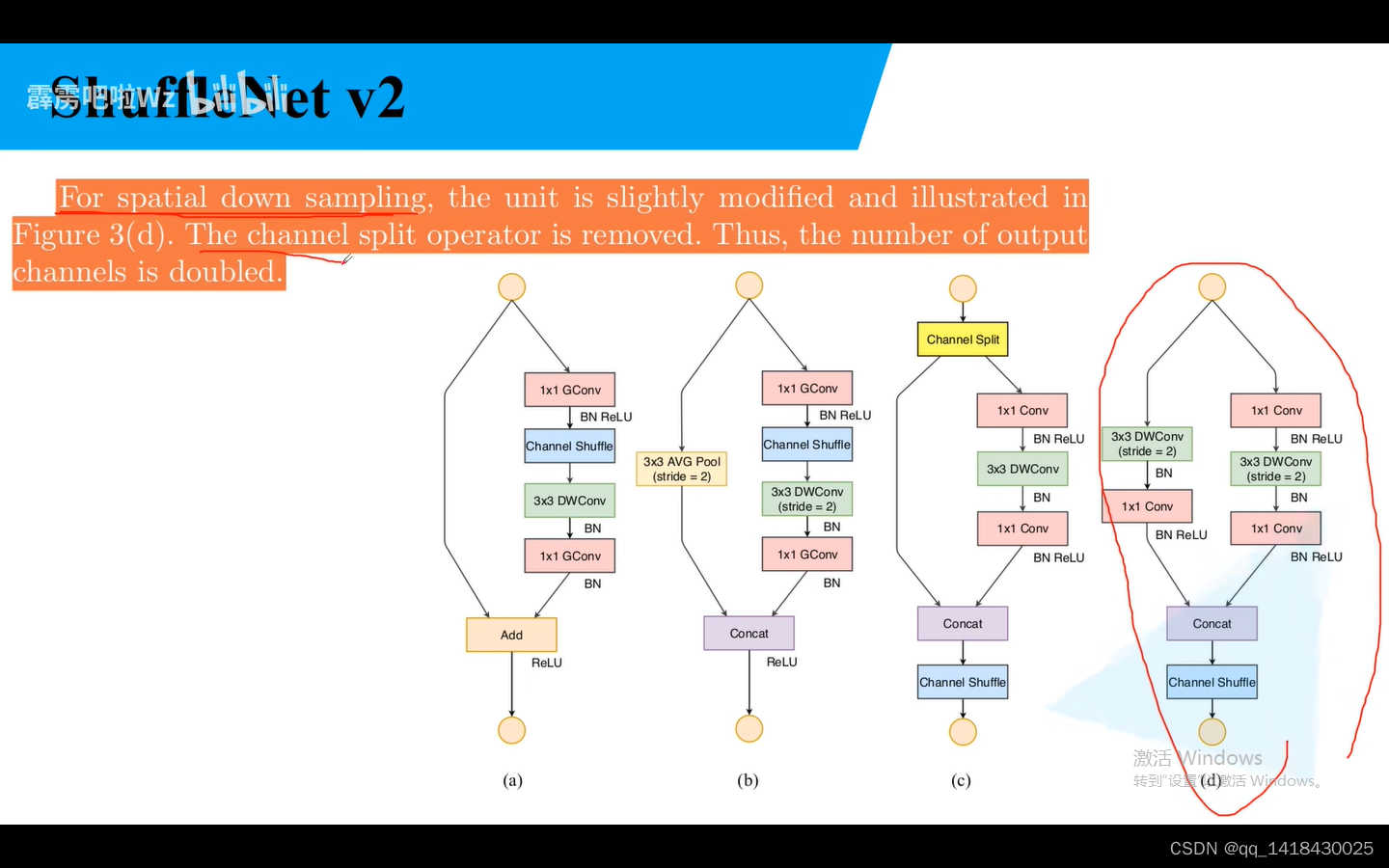
对于步距为2,channel split不存在,深度翻倍。
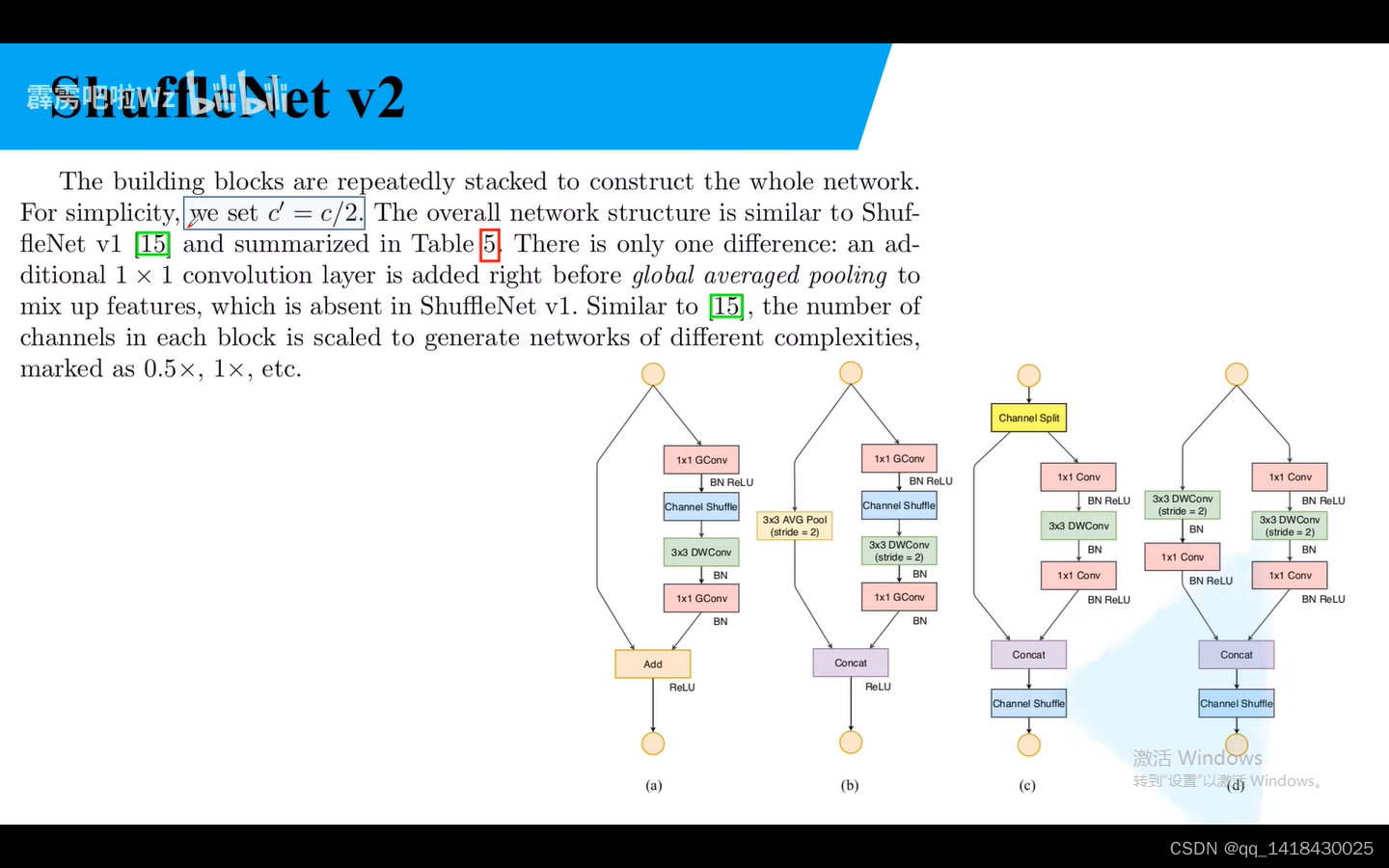
c=c/2
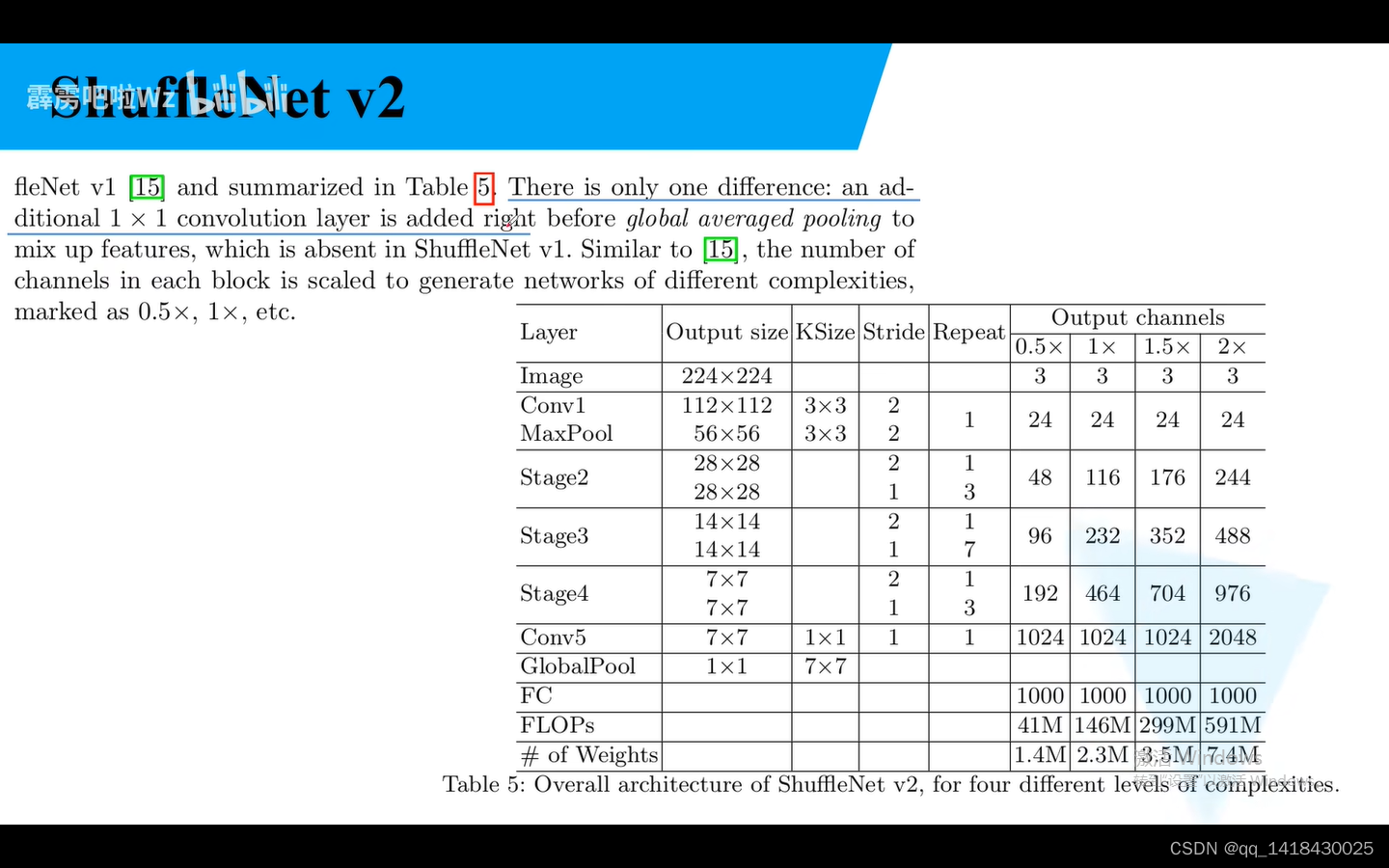
和Shuffle Netv1 唯一不同,多了一个1x1卷积层,即Conv5.(对比Shuffle Netv1)

总结:
1.stride=1进行channel Split,分成两个分支,主分支由原来的1x1组卷积变成普通1x1卷积,Relu变成主分支。Add换成Concat操作。以及channel shuffle
2.stride=2,捷径分支由池化变成DW+Conv。
最后看看ShuffleNetV2的一些指标:

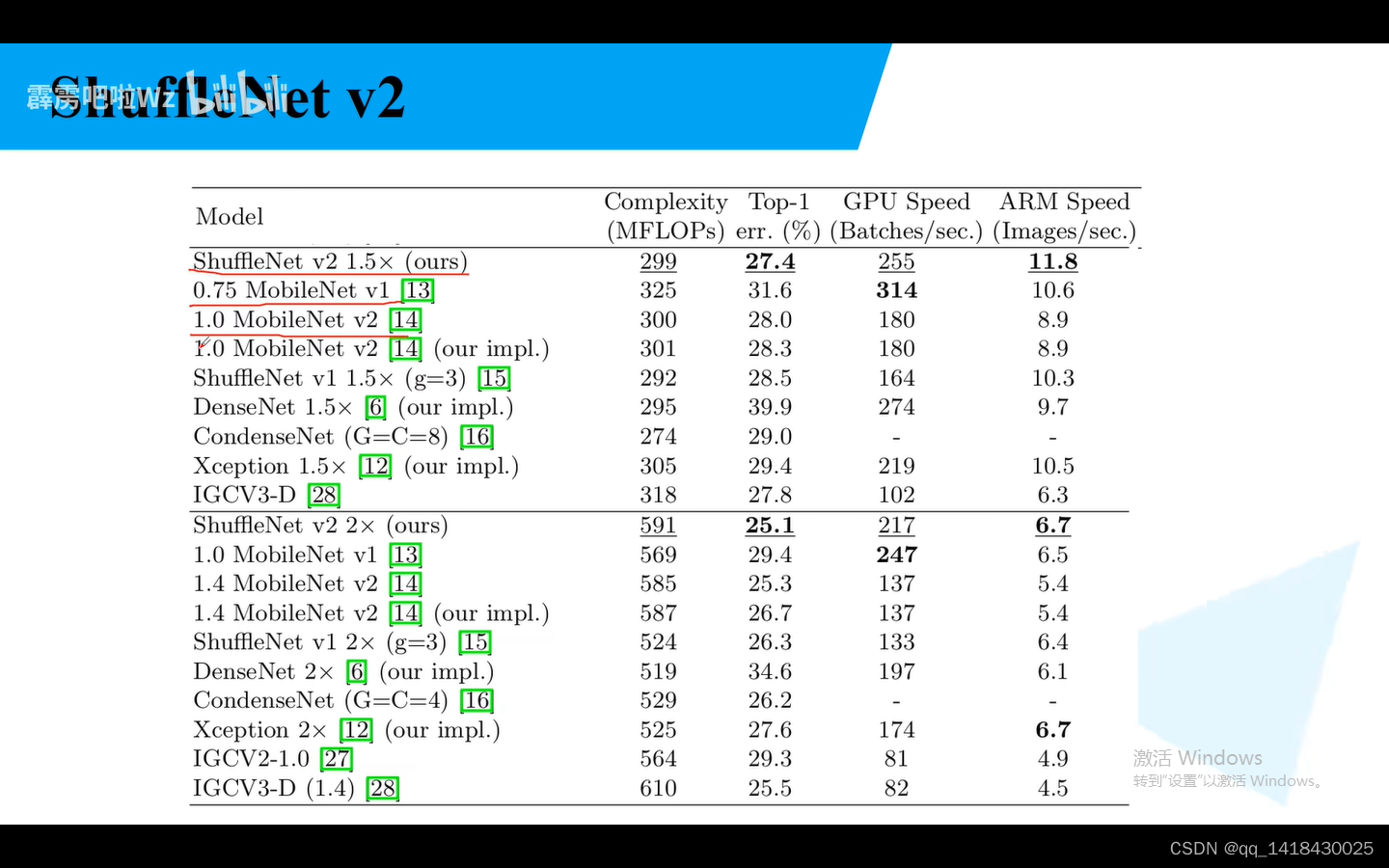

错误率比较低。
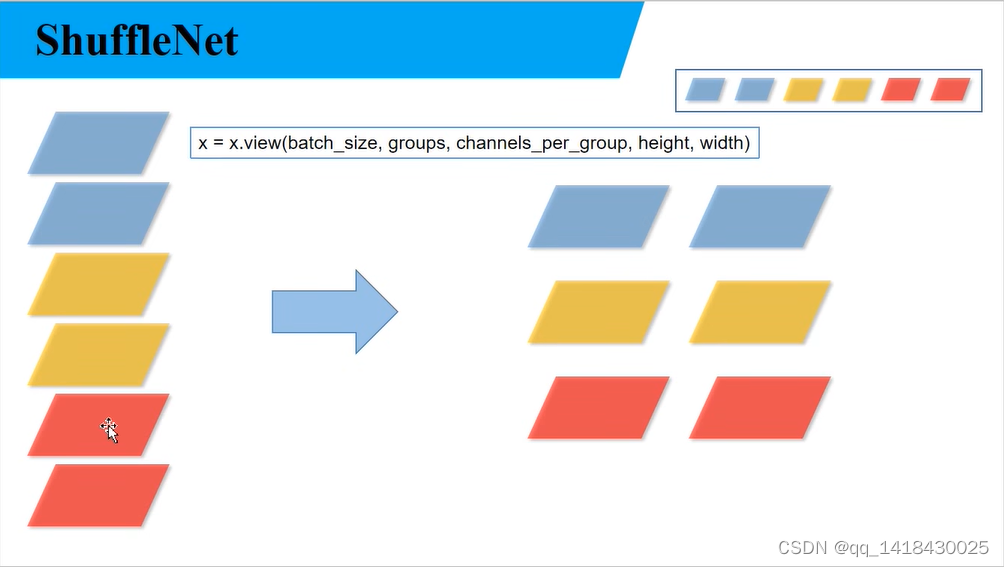
关于代码部分 def channel_shuffle部分:输入图片格式是batch_size,channels,height,width.这里假设上图输入是6个channel,把它分成三个组groups,每组就有两个channels_groups。通过x.view函数即可实现从左图到右图的方式。
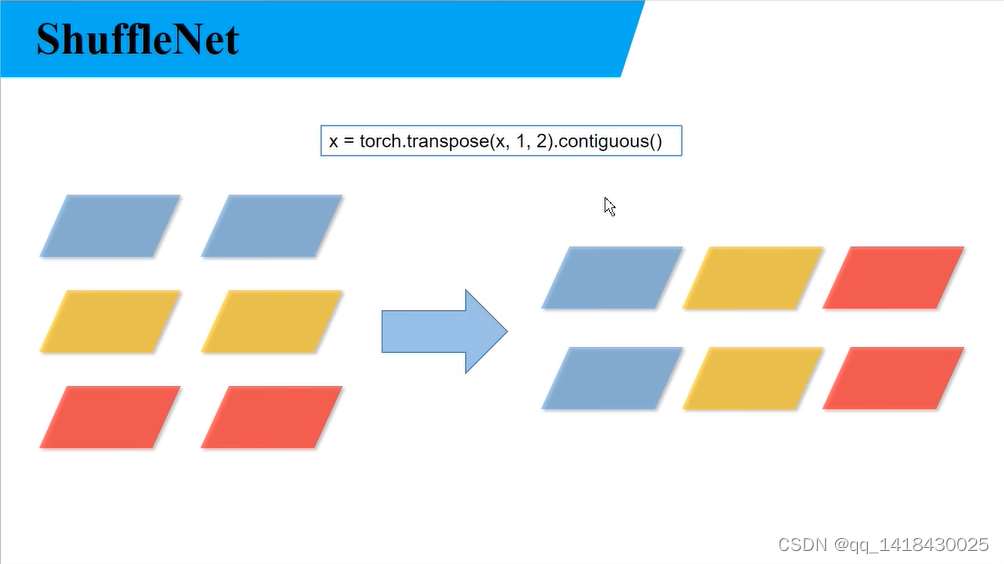
通过torch.transpose函数将维度1(groups=3)和维度2(channels_groups=2)进行对调.

















 5474
5474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











