






Kafka学习笔记:
1.什么是Kafka
Apache Kafka 是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和任务关键型应用程序。Kafka具有快速、可扩展并且可持久化的特点,它的分区特性、可复制和可容错都是其不错的特性。在大数据流计算平台中被频繁使用。
Kafka可以对消息进行topic归类,发布消息者成为Producer,接收消息的是Consumer。数据信息可以通过“管道”从Producer到Consumer来进行数据的传递。注意这里出现几个名词:topic、producer、consumer,下面着重介绍一些kafka的几个重要组件。
2.Kafka几个重要组件
- topic
- topic顾名思义是主题的意思,不同的数据信息归纳到不同类型的主题中,将消息数据以topic的方式进行存放。
- 在kafak中可以有无数多个topic。
- 支持多用户订阅。
- producer
producer主要生产消息,可以将消息发布到topic中,供consumer消费。
可以把peoducer比作一个博主,这个博主可以发布博客,供大家阅读。
- consumer
consumer主要消费消息,存在消费者组中。可以订阅不同的消息。
- consumer group
一个消费者组中可以有很多消费者也可能只有一个消费者。每一个消费者都有一个ID号。
注:同一个组中的消费者对于同一条消息只能消费一次。
每一个分区只能由一个消费者组中的一个消费者进行消费,但是可以有很多个不同的消费组进行消费。
例: 一个消费者只能从主题中的一个分区拉取消息,另外2个消费者空闲。

一个主题,4个分区,4个消费者,一个消费者消费一个分区。

1个主题,4个分区,2个消费组(消费组1,每个消费者消费2个分区,消费组2,每个消费者消费一个分区)
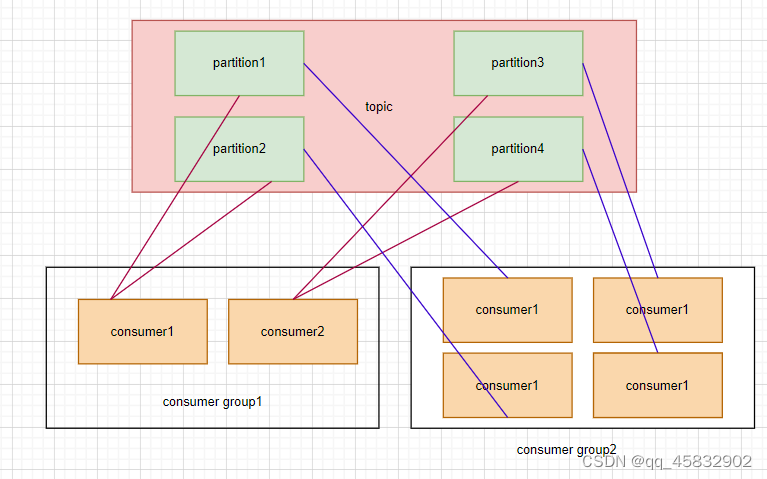
结论:一个主题下的分区数应该是一个消费组中消费者个数的偶数倍。
- partition
在kafka中,topic是消息的存放介质,消息保存在分区中,所有的分区中的消息连接在一起就是该topic中所有数据。
- partition replicas
分区副本 ,为了保证数据不丢失,采取副本机制。一般情况下副本数等于机器数量,尽量小于等于机器数量。
分区副本工作是以主副本(leader)和副副本(follower),前者只能有一个,后者可以有很多个,处于同步状态的副本叫做ISR,两者副本同步延时过多的叫做OSR。
AR = ISR + OSR
关于分区副本的几个问题:
leader和follower的选举问题:
如果leader和follower存在30S没有进行联络,则会进行新的leader的选举
优先会按照AR中的顺序进行选举leader。不是按照isr的顺序来进行选举。
follower故障处理细节:
LEO(Log End Offset):每个副本的最后一个offset,即最新的offset+1
HW(High Watermark):所有副本中最小的LEO
follower会将高于HW的数据进行删除,然后重新像leader进行同步数据。
leader故障处理细节:
所有follower必须向leader看齐,将LEO变为leader的HW,只能保证副本之间
数据的一致性,并不能保障数据不丢失或不重复。
3.Kafka的API接口
3.1生产者API
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 1; i <= 100; i++) {
// 发送数据
ProducerRecord<String, String> records = new ProducerRecord<String, String>("order",
"第"+i+"订单已完成!");
kafkaProducer.send(records, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println("主题为:"+recordMetadata.topic()+"\t"+
"分区为:"+recordMetadata.partition()+"\t"+
"当前数据位移量为:"+recordMetadata.offset()+"\t"+
"数据为:"+records.value());
}
});
Thread.sleep(500);
}
}
- 自定义分区
1. 继承Partitioner接口,重写partition的方法
2. 生产者配置信息中添加:
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,
"kafka.fivebigdata.produceMethod.KafkaCustomPartitioner");
详细如下:
自定义分区,让消息随机发布到随机分区中。
public class KafkaCustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object agr1, byte[] keyBytes, Object arg3, byte[] agr4, Cluster cluster) {
// 定义随机分区,重写partition方法
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int partition = partitions.size();
Random random = new Random();
return random.nextInt(partition);
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
然后编写主分区类,共有4种分区策略:
- 第一种分区策略: 如果没有指定分区,也没有指定数据key,那么就会使用轮询的方式将数据均匀的分给不同的分区中
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 100; i++) {
ProducerRecord<String, String> produceRecord1 = new ProducerRecord<>("mypartition", "mymessage");
kafkaProducer.send(produceRecord1);
Thread.sleep(500);
}
kafkaProducer.close();
}
2.第二种分区策略: 如果没有指定分区号,指定了数据key,通过key.hashCode % numPatitions 来计算数据究竟会保存在哪一个分区中
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 100; i++) {
ProducerRecord<String, String> producerRecord2= new ProducerRecord<>("mypartition", "mykey", "myssage"
+ i);
kafkaProducer.send(producerRecord2);
}
kafkaProducer.close();
}
3.第三种分区策略: 如果指定了分区号,那么就会将数据写入到对应的分区中
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 100; i++) {
ProducerRecord<String, String> producerRecord3 = new ProducerRecord<>("mypartition", 0, "mykey",
"message" + i);
kafkaProducer.send(producerRecord3);
Thread.sleep(500);
}
kafkaProducer.close();
}
}
4.第四种分区策略: 自定义分区 如果不自定义分区,则采用轮询的方式发送数据
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
// 自定义分区
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"kafka.fivebigdata.produceMethod.KafkaCustomPartitioner");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 100; i++) {
// 第四种分区策略: 自定义分区 如果不自定义分区,则采用轮询的方式发送数据
ProducerRecord<String, String> producerRecord4 = new ProducerRecord<>("order","订单" + i);
kafkaProducer.send(producerRecord4, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e == null){
System.out.println("主题为:"+recordMetadata.topic()+"\t"+
"分区为:"+recordMetadata.partition()+"\t"+
"当前数据位移量为:"+recordMetadata.offset()+"\t"+
"数据为:"+producerRecord4.value()+"\t");
}
}
});
Thread.sleep(500);
}
kafkaProducer.close();
}
3.2消费者API(消费者共有4种消费方式)
1.自动提交offset(消息偏移量)
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
// 消费者自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 订阅数据
kafkaConsumer.subscribe(Arrays.asList("order"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("消费的数据: " + consumerRecord.value() + "\t" +
"消费当前的偏移量为: " + consumerRecord.offset() + "\t" +
"分区为: " + consumerRecord.partition());
}
}
}
2.手动提交offset
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 如果需要在获取数据后加入一些处理,我们需要进行手动提交offset,通过以下配置进行控制
// 并且手动提交offset的值 kafkaConsumer.commitSync();
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Arrays.asList("order"));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
if (consumerRecord.partition() == 2) {
// 手动提交offset
System.out.println(consumerRecord.toString());
}
kafkaConsumer.commitSync();
}
}
}
3.消费完每个分区之后再提交
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Arrays.asList("order"));
try {
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : consumerRecords.partitions()) {
List<ConsumerRecord<String, String>> records = consumerRecords.records(partition);
for (ConsumerRecord<String, String> record : records) {
System.out.println("偏移量:"+record.offset() + "值为: " + record.value()+" 分区:"+record.partition());
}
// 注意消费完之后需要提交offset+1
long lastOffset = records.get(records.size() - 1).offset();
kafkaConsumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
4.指定分区数据进行消费
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "bigdata101:9092,bigdata102:9092,bigdata103:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 要使用此分区,只需要调用分区的完整列表调用assign(Collection),而不是使用subscribe订阅主题,二者选一
// 手动指定消费的分区---start
String topic = "order";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
kafkaConsumer.assign(Arrays.asList(partition0, partition1));
// 手动消费指定的数据---end
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(1000);
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("offset = " + consumerRecord.offset() +
"\tpar:" + consumerRecord.partition() +
"\tvalue:" + consumerRecord.value());
}
}
}
4.怎么保证数据不丢失
4.1 生产者生产数据不丢失
生产者发送消息,可采用同步或者异步
同步:生产者发送消息,等待服务器返回结果:
- 生产者等待10S,如果服务器没有给出ack响应,则认为失败。
- 生产者重复3次,如果还没有响应,则认为失败。
异步:生产者发送消息然后提供一个返回函数
% 先将数据保存在生产者端的buffer中。
% 满足数据阈值或者数量阈值其中的一个条件就可以发送数据
% 发送一批数据
ACK:
ACK有3个状态(0,1,-1)
0:生产者只负责发送数据,不关心数据是否丢失,丢失的数据需要再次发送。容易导致数据丢失。持久性好 延迟性最低。
1:partition中leader收到数据后才能发送下一条消息。持久性较好的 延迟性较低。
-1:producer得到follower的确定后才能发送下一条数据。持久性最好 延时性最差。
4.2broker(机器)中的数据不丢失
有副本因子的存在,保障数据不会随意丢失。
4.3消费者消费的数据不丢失
消费者消费数据都会有记录,都会保存好offset的位置,一般保存在redis中。















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









