







背景
最近产品觉得我们网站在百度收录上排名太靠后了,又不肯花钱,就让我们想办法提升网站的SEO。由于项目是用vue3写的,并且已经迭代多个版本了,用nuxt实在不适宜,当然俺的开发水平也不够,周期也会拉得很长,此时!想偷懒的我看到了puppeteer,可以一试!
原理
实际上就是当普通用户访问我们的网站时,访问的就是单页面应用,但是当爬虫访问我们的网站时就会被转发到puppeteer服务上,传送给爬虫的页面是比较完整的的HTML页面,有利于提升单页面应用的SEO
上流程!
首先将我们开发完的vue项目打包到本地;
将打包后的dist文件夹放在本地nginx的html文件夹下;
正常配置nginx.conf文件;
新建文件夹,执行npm init生成package.json文件;
安装express\puppeteer;
写入流程;
启动服务;
在nginx.config的 location /下配置判定是否为爬虫,是则转发至puppeteer服务。
代码
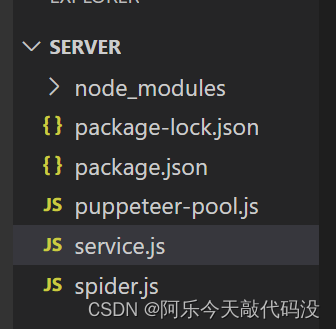
假设puppeteer服务项目名为server,则文件目录为下:
service.js
const express = require('./node_modules/express');
var app = express();
var spider = require("./spider.js")
app.get('*', async (req, res) => {
let url = "你所部署到nginx的完整访问路径,例如http://127.0.0.1:80" + req.originalUrl;
console.log('请求的完整URL:' + url);
let content = await spider(url).catch((error) => {
console.log(error);
res.send('获取html内容失败');
return;
});
res.send(content);
});
app.listen(3000, () => {
console.log('服务已启动!');
});
puppeteer-pool.js
const puppeteer = require('./node_modules/puppeteer');
const MAX_WSE = 2; //启动几个浏览器
let WSE_LIST = []; //存储browserWSEndpoint列表
//负载均衡
(async () => {
for (var i = 0; i < MAX_WSE; i++) {
const browser = await puppeteer.launch({
//无头模式
headless: 'new',
//参数
args: [
'--disable-gpu',
'--disable-dev-shm-usage',
'--disable-setuid-sandbox',
'--no-first-run',
'--no-sandbox',
'--no-zygote',
'--single-process'
],
//一般不需要配置这条,除非启动一直报错找不到谷歌浏览器
executablePath:'chrome.exe在你本机上的路径,例如C:/Program Files/Google/chrome.exe'
});
let browserWSEndpoint = await browser.wsEndpoint();
WSE_LIST.push(browserWSEndpoint);
}
})();
module.exports = WSE_LIST
spider.js
const puppeteer = require('./node_modules/puppeteer');//由于目录不一致,所以使用的是绝对路径
const WSE_LIST = require('./puppeteer-pool.js') //这里注意文件的路径和文件名
const spider = async (url) => {
let tmp = Math.floor(Math.random() * WSE_LIST.length);
//随机获取浏览器
let browserWSEndpoint = WSE_LIST[tmp];
//连接
const browser = await puppeteer.connect({
browserWSEndpoint
});
//打开一个标签页
var page = await browser.newPage();
//打开网页
await page.goto(url, {
timeout: 0, //连接超时时间,单位ms
waitUntil: 'networkidle0' //网络空闲说明已加载完毕
})
//获取渲染好的页面源码。不建议使用await page.content();获取页面,因为在我测试中发现,页面还没有完全加载。就获取到了。页面源码不完整。也就是动态路由没有加载。vue路由也配置了history模式
let html = await page.evaluate(() => {
return document.getElementsByTagName('html')[0].outerHTML;
});
await page.close();
return html;
}
执行node service,即可在终端看到服务已启动字样
nginx部分配置
server {
listen 80;
server_name 127.0.0.1;
location /api {
你的后端转发配置。。。。。
}
location / {
set $prerender 0;
set $prerender_url 'http://120.0.0.1:3000'
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
if ($http_user_agent ~* "Sogou Pic Spider|Baiduspider|Baiduspider-render|YisouSpider|Sogou web spider|Bytespider|360Spider|Googlebot|YodaoBot") {
set $prerender 1;
}
if($prerender = 1){
proxy_pass $prerender_url;
}
root html/dist;
index index.html /index.htm;
try_files $uri $uri/ /index.html;
}
}
测试
1.打开postman,将默认的User-Agent取消勾选,新建User-Agent,值为Bingbot,向你所部署到nginx的完整访问路径发送请求,server项目终端有输出即成功。
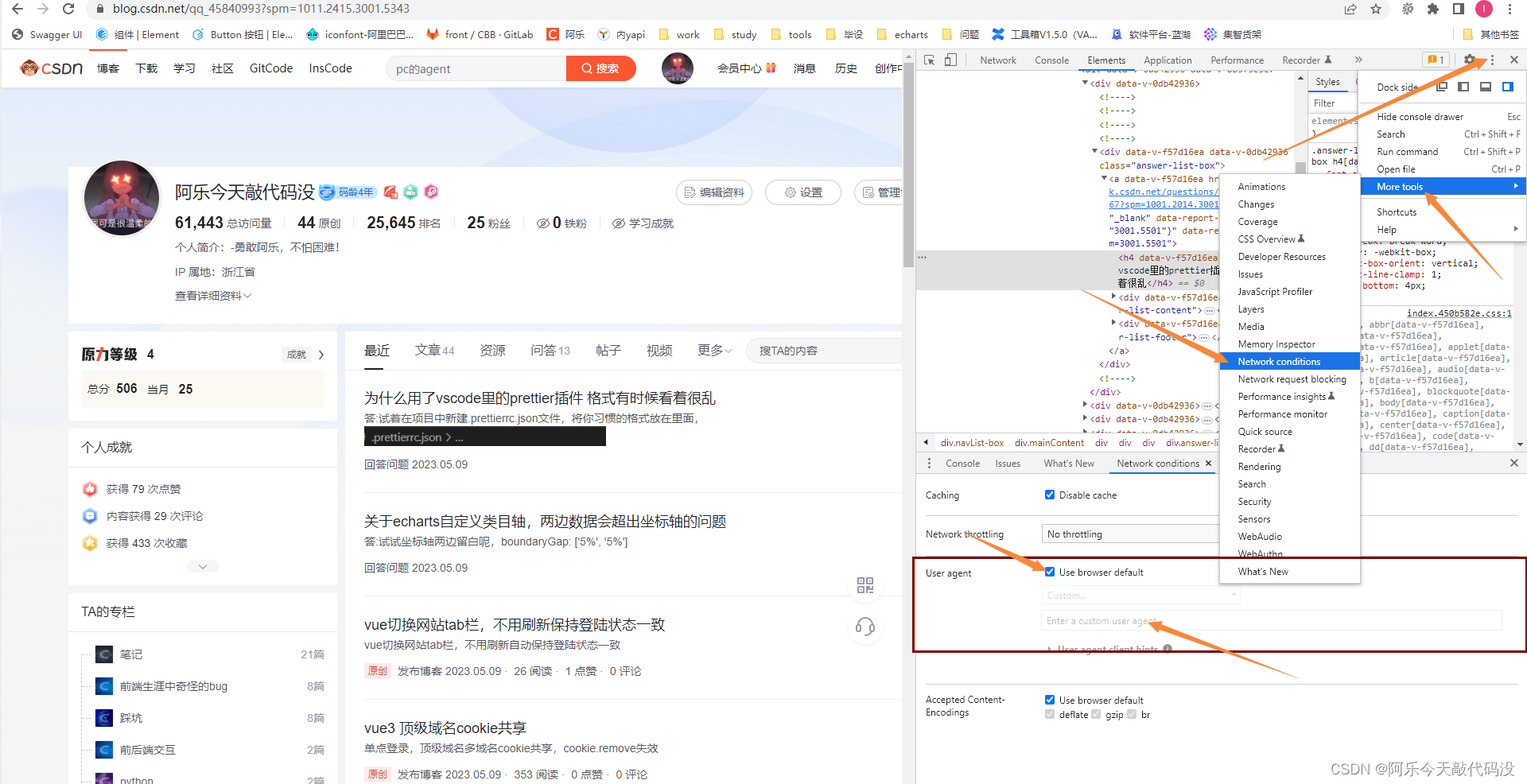
2.在谷歌浏览器打开开发者工具,点击右上方三个点,选择更多工具,选择网络情况,取消user-agent默认勾选,设置值为Bingbot,刷新所在页面,server项目终端有输出即成功。
关于linux环境下的按照部署可以看这篇文章 linux下express+puppeteer安装部署并用PM2守护进程
可能会遇到的报错
- 新建文件夹无法安装express\puppeteer?
在此文件夹内执行npm init,生成package.json文件即可安装包 - puppeteer安装一直失败?
执行npm install puppeteer --ignore-scripts - 其他问题请在评论区留言
















 1016
1016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











