







Sorl学习笔记
- 1.Solr简介
- 2.Solr的安装(Windows)
- 3.Solr基础
- 3.1 SolrCore
- 3.2 Solr后台管理系统的使用
- 3.2.0后台管理界面介绍
- 3.2.1 Doucments
- 3.2.2Analyse
- 3.2.3 Solr的配置-Field
- 3.2.5 Solr的配置-FieldType
- 3.2.6Solr的配置-DynamicField 动态域
- 3.2.7Solr的配置-复制域
- 3.2.8 Solr的配置-主键域
- 3.2.9 Solr的配置-中文分词器
- 3.2.10 Solr的数据导入(DataImport)
- 3.2.11 solrconfig.xml
- 3.2.12后台管理界面其他操作
- 4.Solr查询
- 5.SolrJ(重要)
- 6.Spring Data Solr(开发)
1.Solr简介
1.Solr 是什么?
基于Lucene开发的全文检索的服务,用户可以通过http请求,想Solr服务器提交一定格式的数据,完成索引库的索引,也可以通过http请求查询索引库获取返回结果
客户端发送请求给Web服务器,Web服务器在通过http请求发送给Solr,
2.Solr的安装(Windows)
2.1 Jetty部署Solr
下载Solr安装包
下载地址:solr7.7.3下载地址

解压安装包
进入到bin目录中,cmd,打开窗口,输入
solr start

打开浏览器,输入
http://localhost:8983/solr
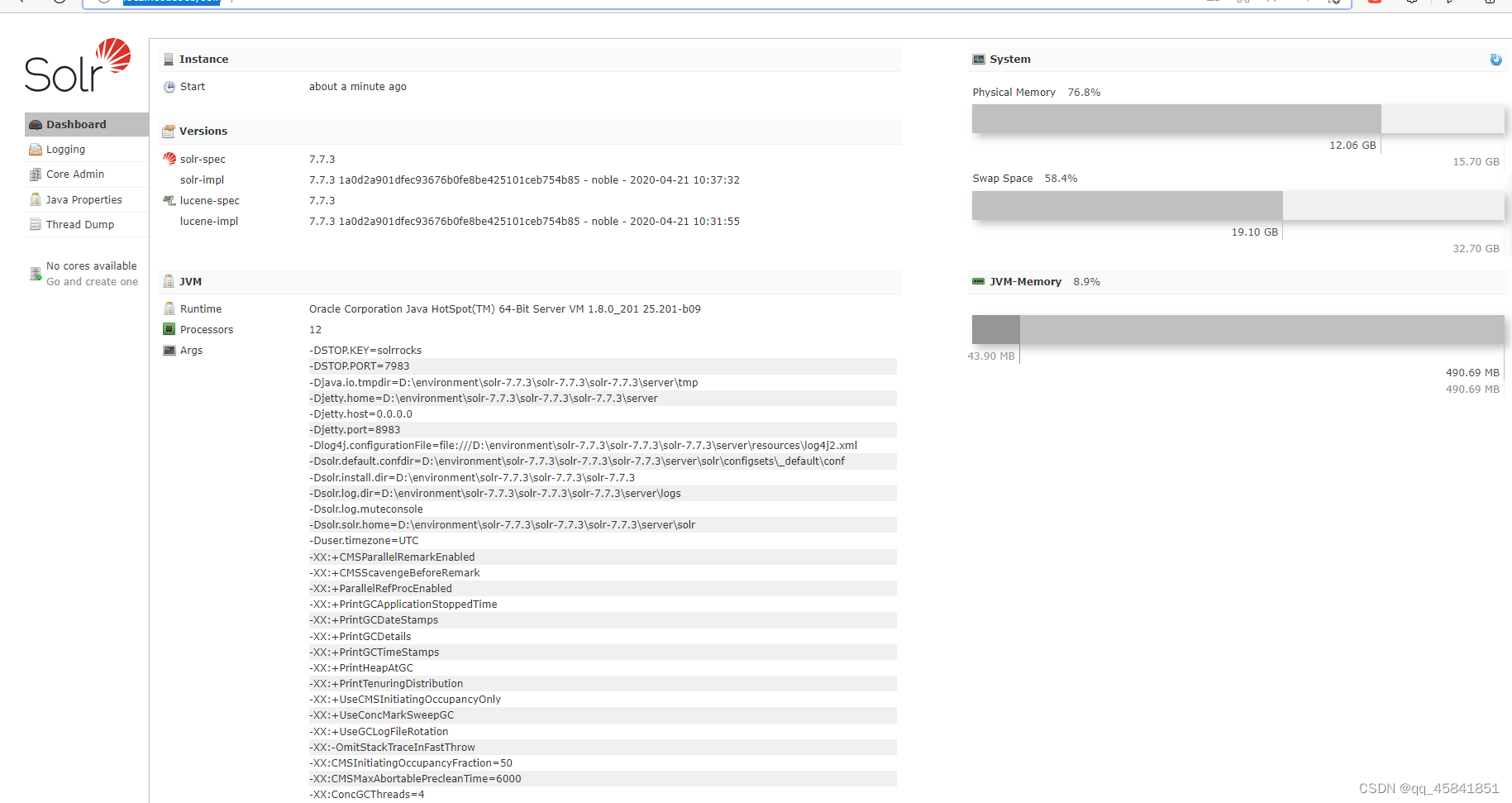
此时Jetty部署Solr成功!
输入solr stop -all可以停止Solr
2.2 tomcat配置Solr
解压一个新的tmocat,用来部署Solr
将安装包下的solr-7.7.3\server\solr-webapp\webapp打成war包,进入solr-7.7.3\server\solr-webapp\webapp,输入cmd,jar cvf solr.war ./*

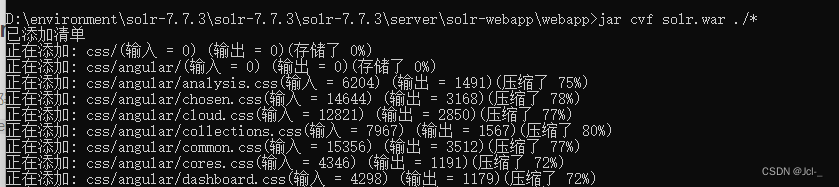
打包成功

将打好的war包复制到tomcat的webapps目录下
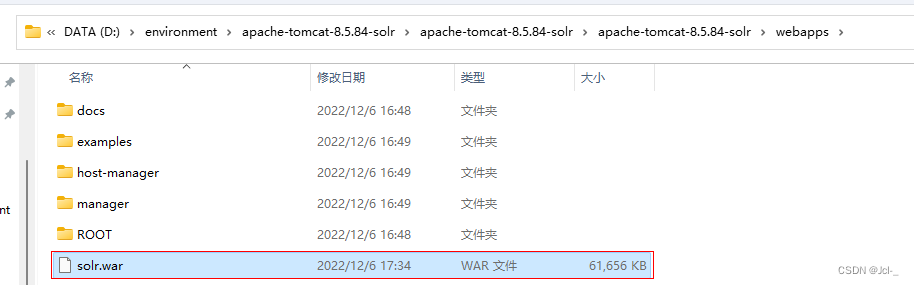
启动tomcat,需要一定的时间
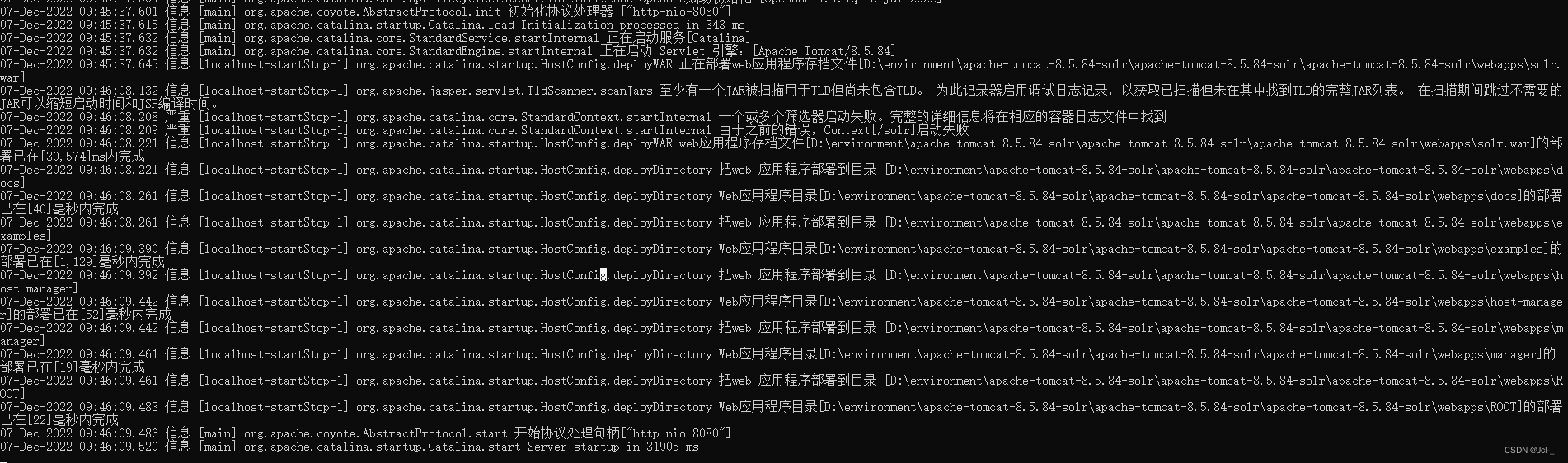
修改webapps/solr/WEB-INF/web.xml的配置solr_home的位置;
在xml中添加Solrhome的配置
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>"Solrhome的位置"</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
根据你写的位置,创建目录
复制solr安装包中的文件到solr_home
还是那个web.xml中,关闭安全认证
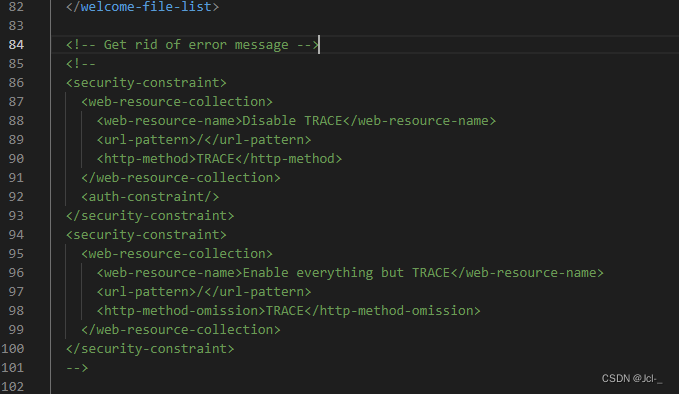
将solr安装包下的/server/lib/ext下的jar包复制到tomcat下的Solr的/WEB-INF/lib/目录下(日志相关jar包)
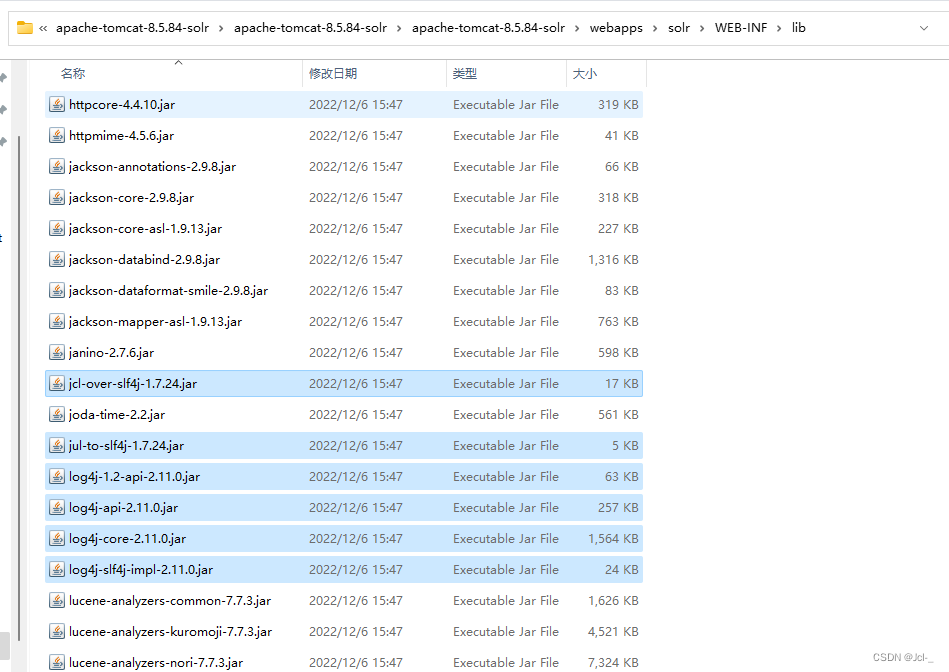
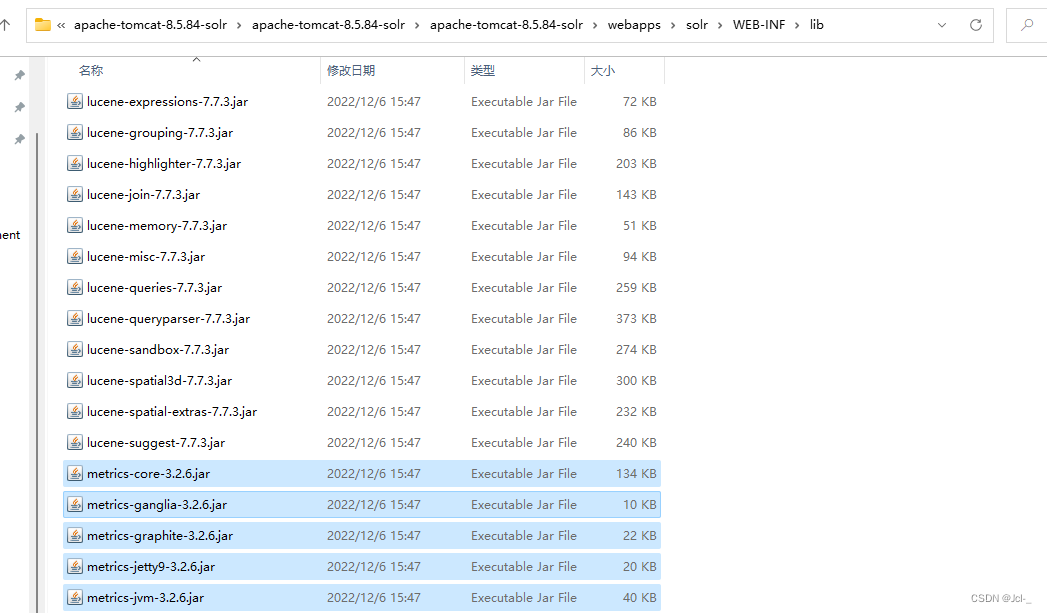
将/server/lib/下的metrics相关包复制到tomcat下的Solr的/WEB-INF/lib/目录下
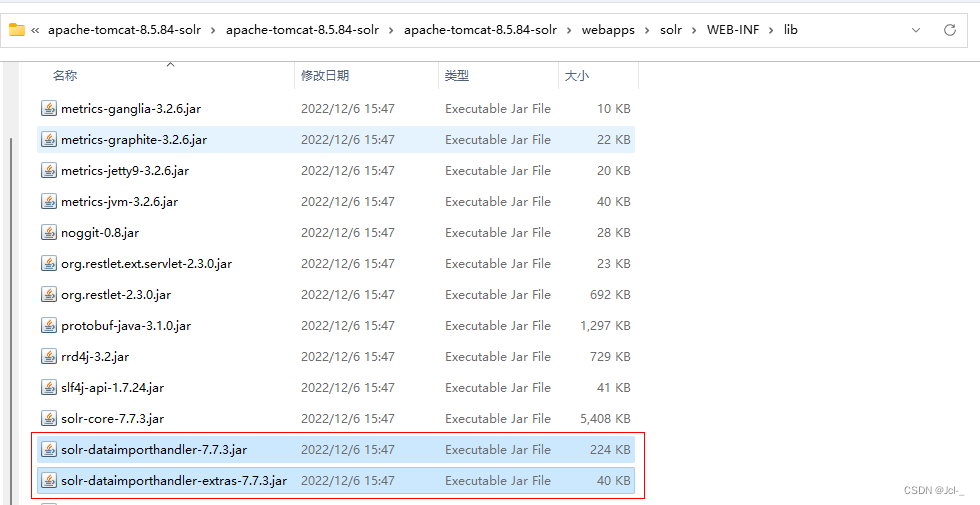
将solr安装包中的solr-7.7.3/dist/文件夹下的两个dataimporthandler文件复制到tomcat下的Solr的/WEB-INF/lib/目录下(这两个包是做数据导入的,数据库中导入到solr时使用)
拷贝log4j2配置文件:将solr/server/resources目录中的log4j配置文件拷贝到web工程目录WEB-INF/classes(自己创建一个classes目录),并且修改日志文件的路径
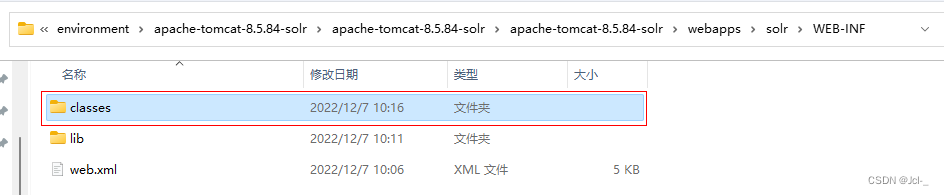
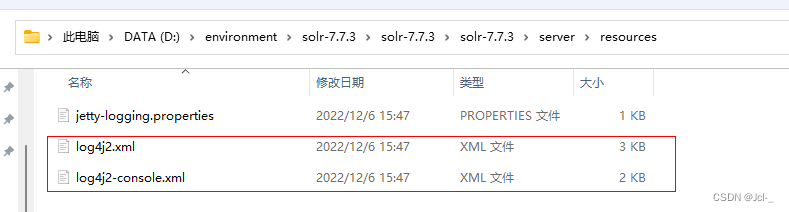

将Tmocat的bin/catalina.bat中配置日志文件的环境参数
set "JAVA_OPTS=%JAVA_OPTS% -Dsolr.log.dir=C:\webapps\fooFts\logs"
这里我遇到启动失败,闪退的问题,可以查看是否是之前tmocat还在运行没有关闭,或者在配置文件server.xml中修改端口号
问题解决了
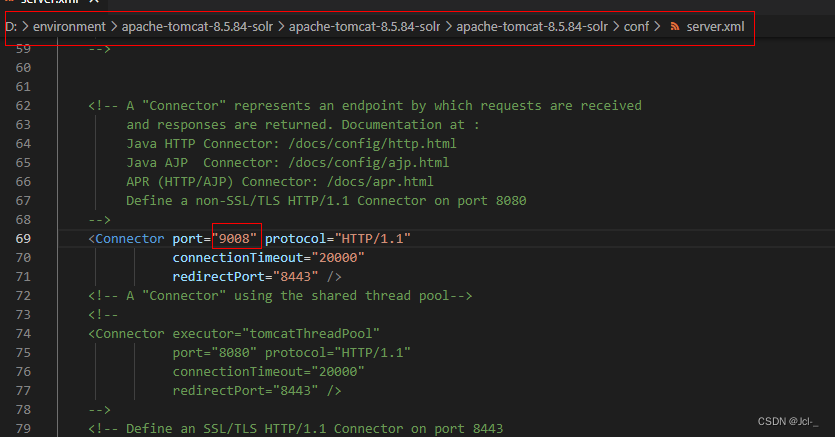
启动Tomcat
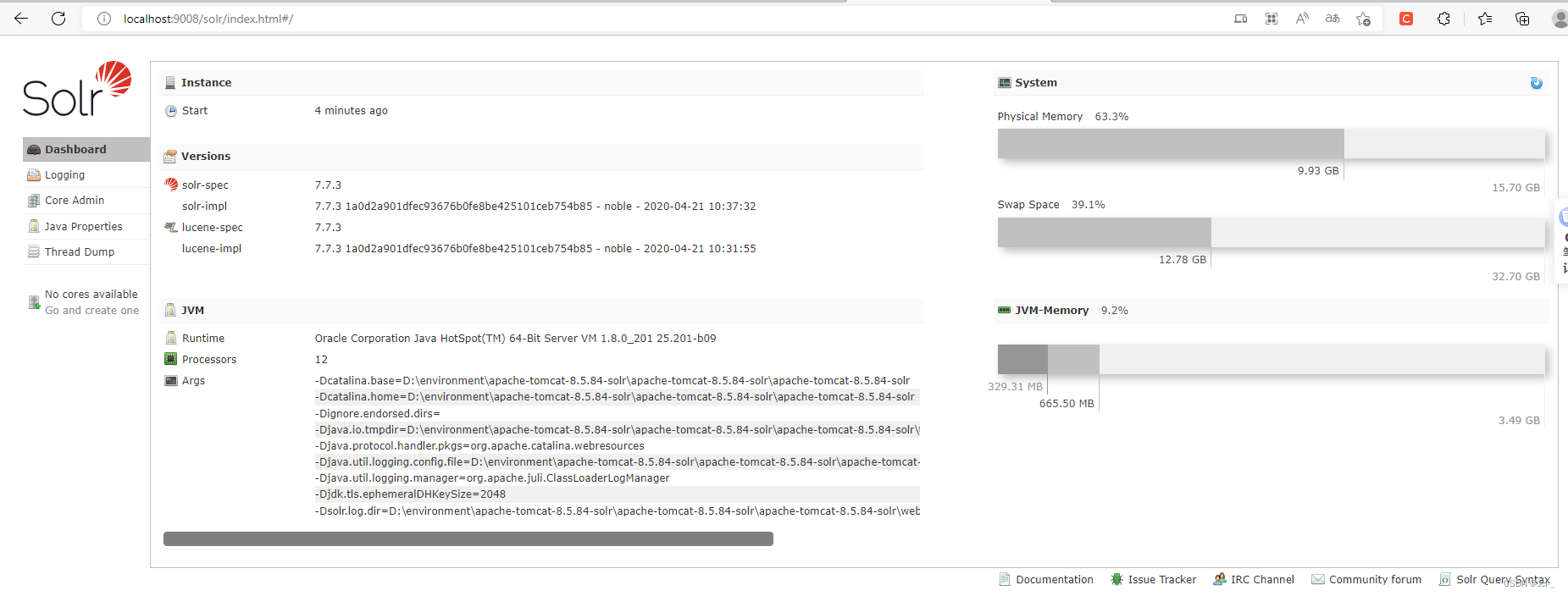
终于部署完毕了,启动看看吧!端口号修改成为自己配置的端口号
http://localhost:9008/solr/index.html#/
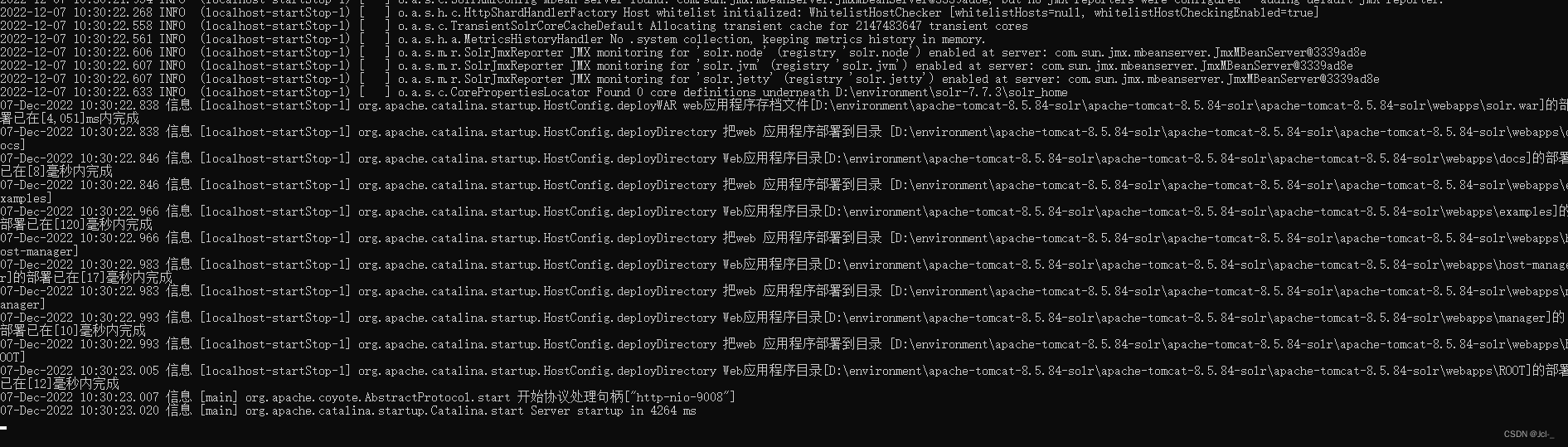
启动成功了!!!
3.Solr基础
3.1 SolrCore
Solr部署启动成功之后需要创建Core才可以使用,类似与Mysql安装完之后需要创建数据库一样
3.1.1 什么是SolrCore
在Solr中,每一个Core,代表一个索引库,里面包含索引数据及其配置信息
solr中可以拥有多个Core,也就是可以同时管理多个索引库
3.1.2 SolrCore的维护(Windows)
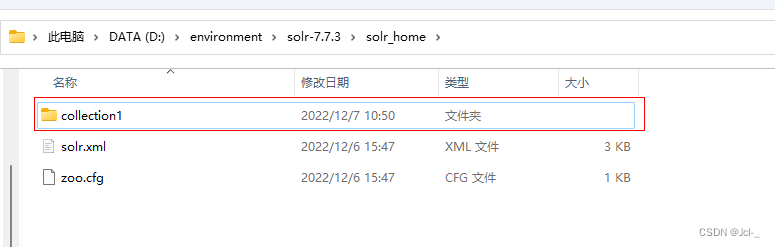
创建在solr_home目录下创建一个SolrCore文件夹
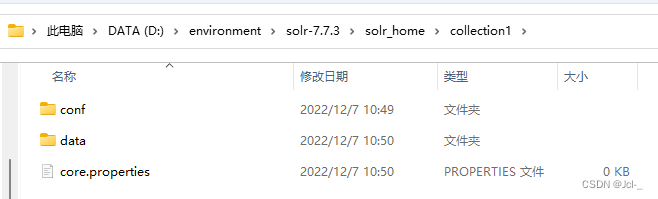
创建conf,data,core.properties
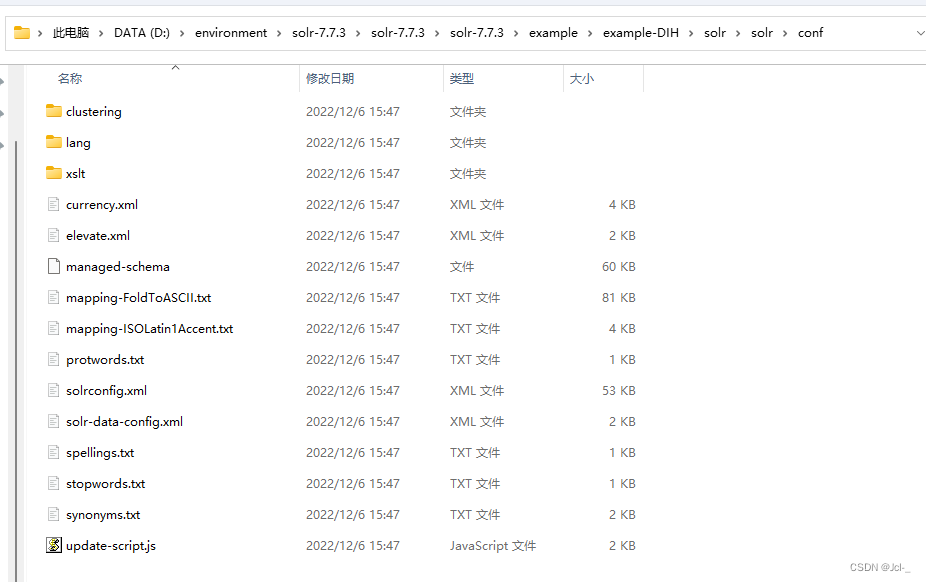
将solr安装包中的solr-7.7.3\example\example-DIH\solr\solr\conf\目录下的文件复制到自己创建的conf中
完成了SolrCore的搭建,启动Tomcat
成功创建了SolrCore
可以在创建的core.properties文件中配置SolrCore的名字
name = jcl
配置成功!
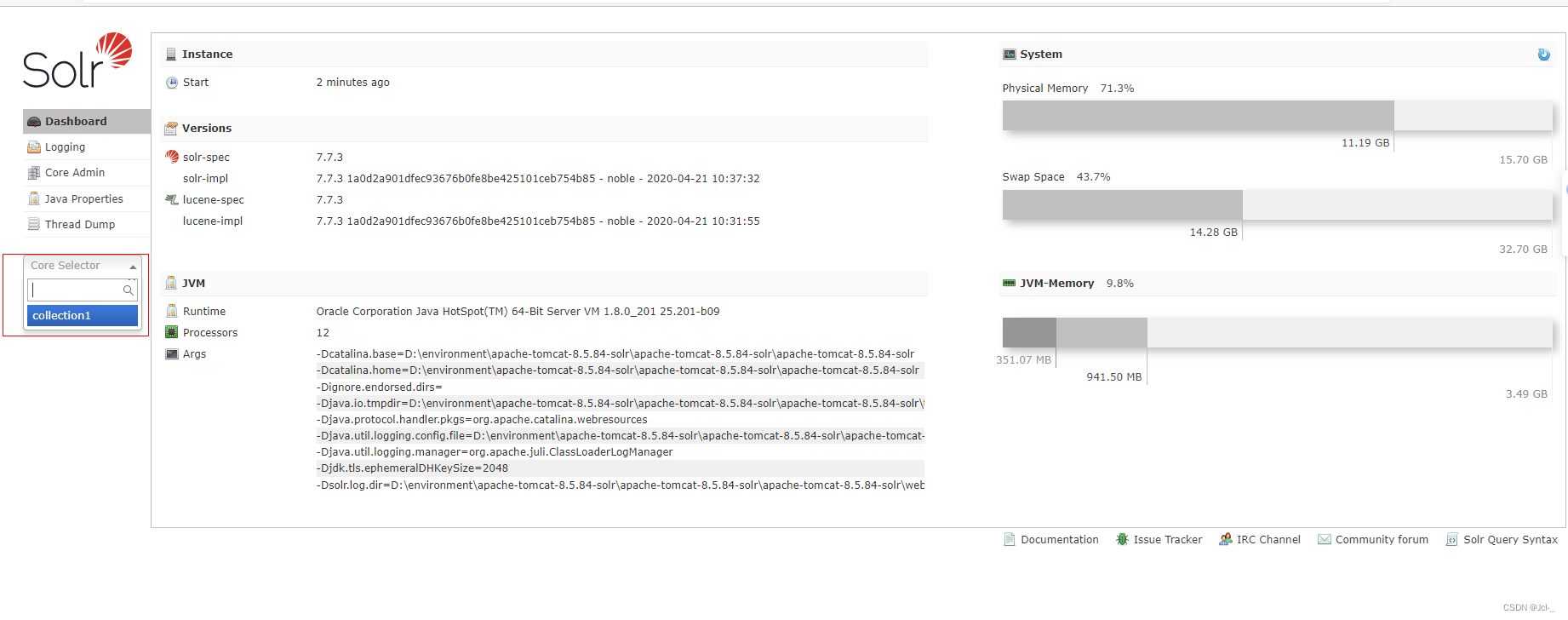

3.2 Solr后台管理系统的使用
3.2.0后台管理界面介绍
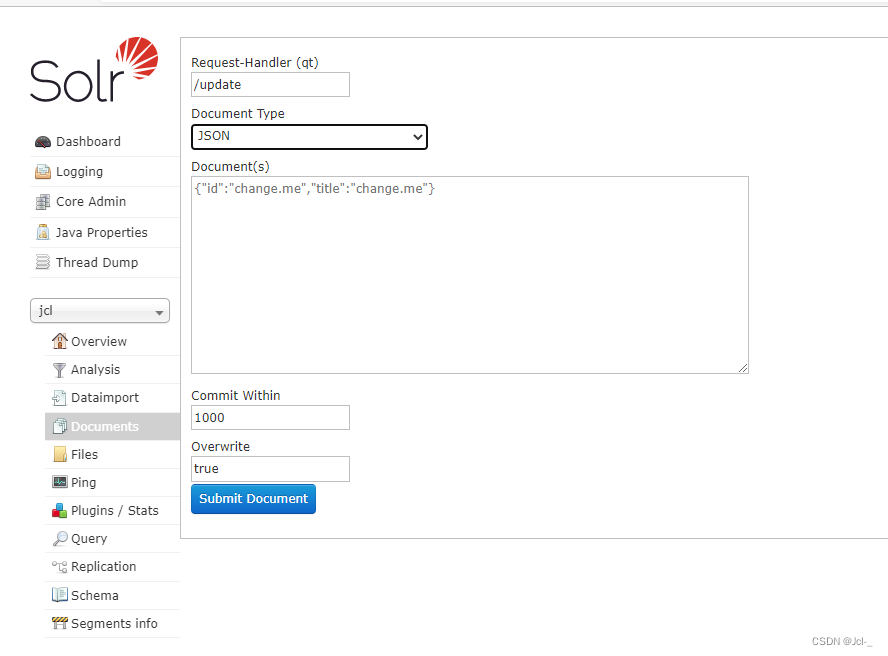
3.2.1 Doucments
一个文档由多个域组成,每个域包括域值和域名。
文档:相当于Msql中的一条记录,
域:相当于msql中的一条记录中的字段
索引:想索引库中添加/修改/删除数据的操作称为创建/修改/删除索引
搜索:搜索数据这个操作称为搜索索引
倒排索引:Lucene会对文档域中的数据进行分词,建立词和文档之间的关系,这个关系就是倒排索引 ----方便根据域中的词快速定位到文档
3.2.2Analyse
作用: 测试域/域类型的分词效果
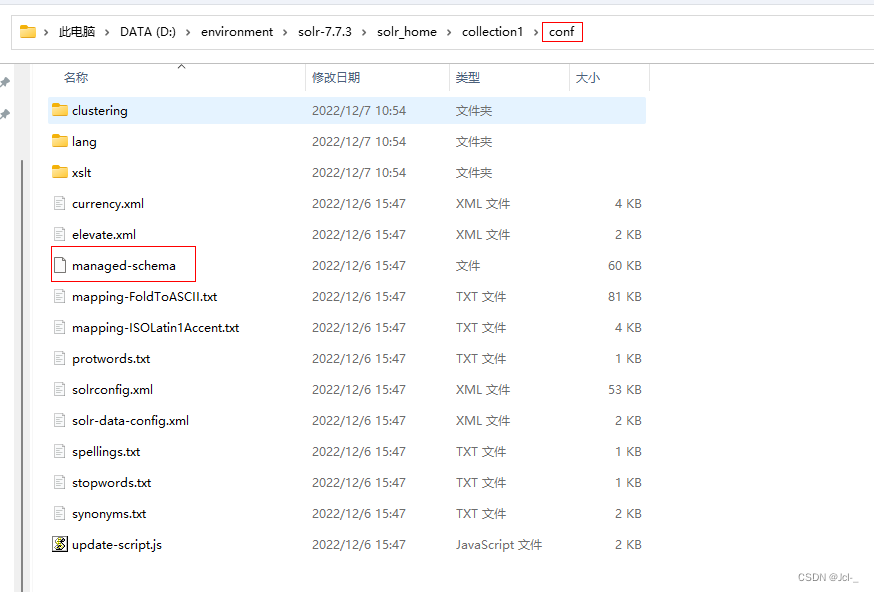
3.2.3 Solr的配置-Field
在SolrCore创建Documents时,发现 id不分词,name对中文不分词,域名不可以随便写
原因就在于Solr的配置 - Field
对managed-schema进行配置
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false"/>
- field标签:定义一个域
- name属性:域名
- indexed:是否索引,是否可以根据该域进行搜索文档,例如图片路径就不需要索引
- stored:是否存储,将来查询的文档中是否包括该域的数据;
- multiValued:是否多值,该域是否可以存储一个数组;(图片列表)
- required:创建文档时,该域是否必须;(id)
- tyep:域类型,决定该域使用的分词器,分词器决定分词效果。域的类型在使用前必须提前定义,在Solr中提供了很多的域类型
例子:创建一个商品图片域和一个商品描述域
<!-- 商品描述域 -->
<field name="item_description" type="text_general" indexed="true" stored="false"></field>
<!-- 商品图片域 -->
<field name="item_image" type="string" indexed="false" stored="true" multiValued="true"></field>
PS:注意要是在自己创建的Solr的配置文件中修改
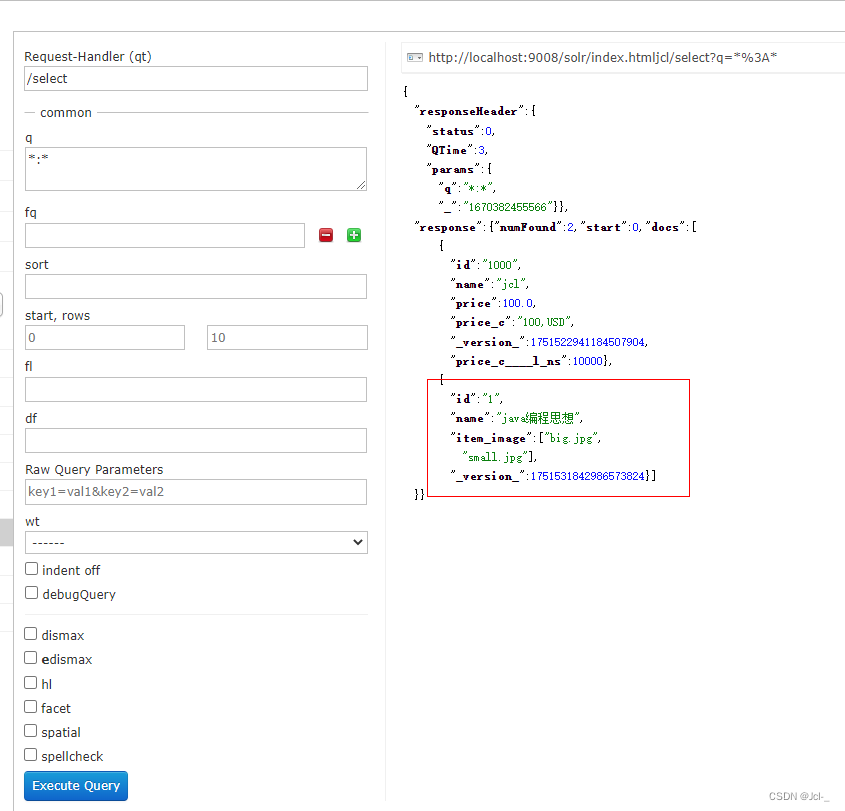
{id:1,name:"java编程思想",item_image:["big.jpg","small.jpg"],item_description:"lucene是apache的开源项目,是一个全文检索的工具包"}
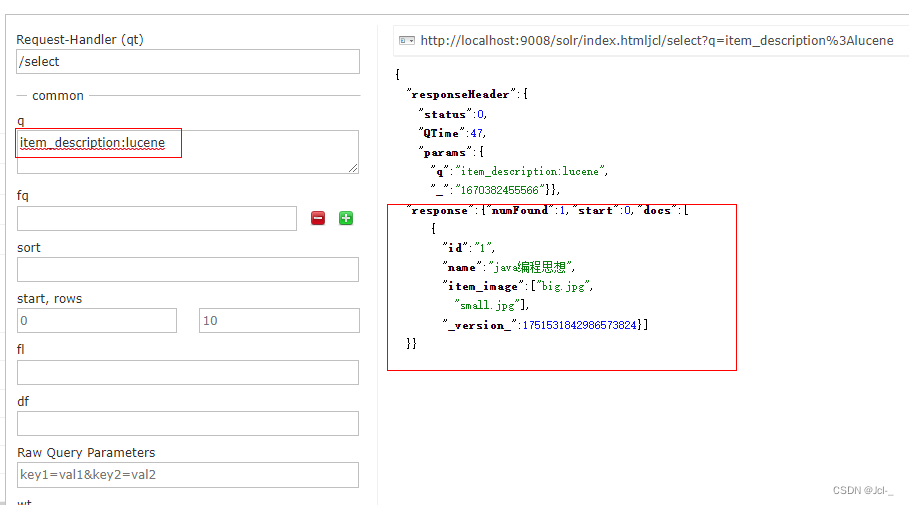
测试结果:可以看到,当stored设置为false时,在查询里看不到数据,但是设置indexed为true时,可以对其进行搜索显示该文档
根据图片描述进行搜索(indexed = true)
3.2.5 Solr的配置-FieldType
Solr已经提供的一些域类型:
- test_general:支持英文分词,不支持中文分词
- string:不分词,适用于id,订单号等等
- pdate:适合日期类型的域,特殊分词,支持大小比较
- pfloat:适合小数类型的域,特殊分词,支持大小比较
- pint:适合整型类型的域,特殊分词,支持大小比较
- plong:适合长整型类型的域。特殊分词,支持大小比较
3.2.5.1相关属性
- name:域类型的名称,定义域类型的必须指定且唯一;将来定义域的时候需要通过域名来指定域类型(重点)
- class:域类型对应的java类,必须指定,如果该类时solr的内置类,使用solr.类名指定即可。如果该类是一个第三方的类,需要指定全类名(重点)
- 如果class是TextField,我们还需要使用子标签来配置分析器
- positionIncrementGap:用于多值字段,定于多值间的间隔,来阻止假的短语匹配(了解)
- enableGraphQueries:是否支持图标查询(了解)
- docValuesFormat:docValues字段的存储格式器:schema-awar codec,配置在solrconfig.xml中的(了解)
- postingsFormat:词条格式器:schema-aware codec,配置在colrconfig.xml中的(了解)
3.2.5.2 Solr自带的FieldType类
分词器的基本概念
分析器就是将用户输入的一串文本分割成为一个个token(单词),一个个token组成了tokenStream(单词集合),然后遍历tokenSteam对其进行过滤操作,比如除去停用词,特殊字符,标点符号和统一转换大小写的形式等等,分词的准确性会直接影响搜索的结果,从某种程度上来讲,分词的算法不同,都会影响返回的结果,因此分析器是搜索的基础。
分析器的工作流程:主要分为分词和过滤
一个分析器可以包含多个过滤器(或0个),但只能有一个分词器
Solr提供的分词器:
标准分词器,经典分词器,关键词分词器,单词分词器,不同的分词器分词的效果不同
Solr中常用的分词器
1.Standard Tokenizer
作用:这个Tokenizer将文本的空格和标点符号当作分隔符,注意,你的Email地址(含有@符号)可能会被分解开;用点号(小数点)连接的部分不会被分隔开来。对于有连接字符的单词也会被分割开来。
<analyzer>
<tokenizer class="sorl.StandardTokenizerFactory"/>
</analyzer>

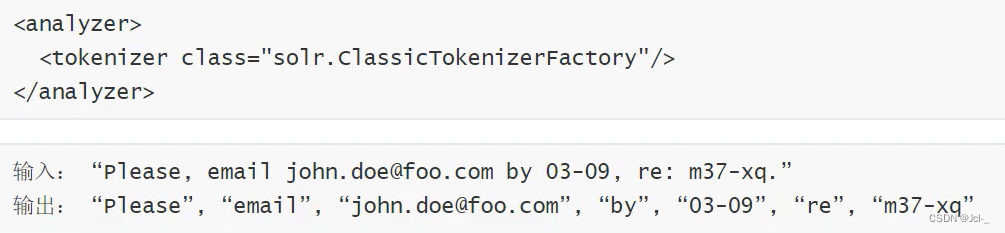
2.Classic Tokenizer
作用:基本与Standard
Tokenizer先后同。注意用点号连接的地方不会被分解开来,用@号连接的邮箱也不会被分解开来,互联网域名也不会被分解开来(wo.com.cn)不会被分解开来,有连接符的单词,如果是数字连接也不会被分解开来
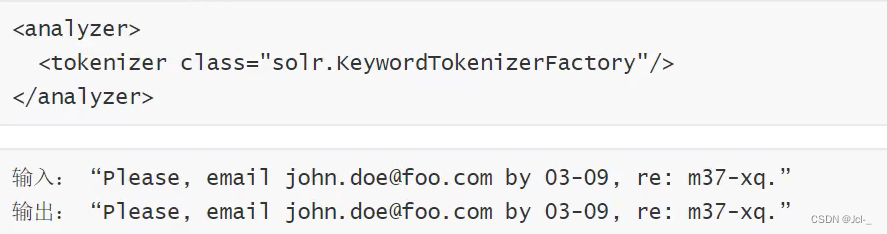
3.Keyword Tokenizer
作用:把整个输入文档当成一个整体
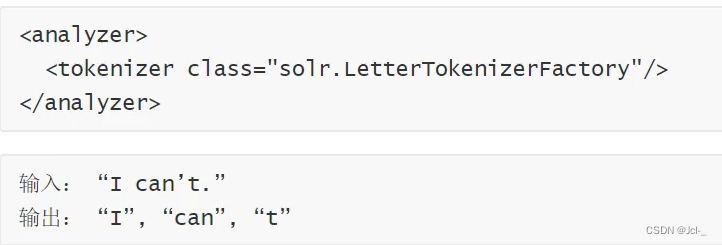
4.Letter Tokenizer
作用:只处理字母,其他的符号都被认为是分割符
5.Lower Case Tokenizer
以非字母元素隔离,并且将所有的字母转换为小写

6.N-Fram Tokenizer
作用:将输入文本转化为指定范围大小的片段的词,注意,空格也会被当成一个字符处理

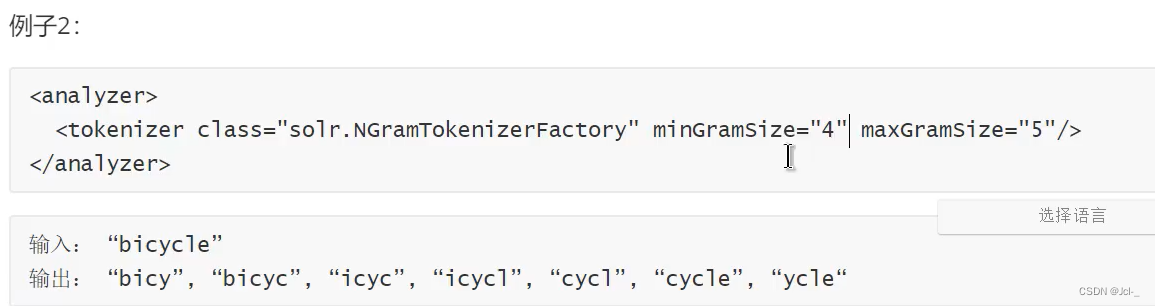
6.Edge N-Fram Tokenizer
作用:与N-Fram Tokenizer类似
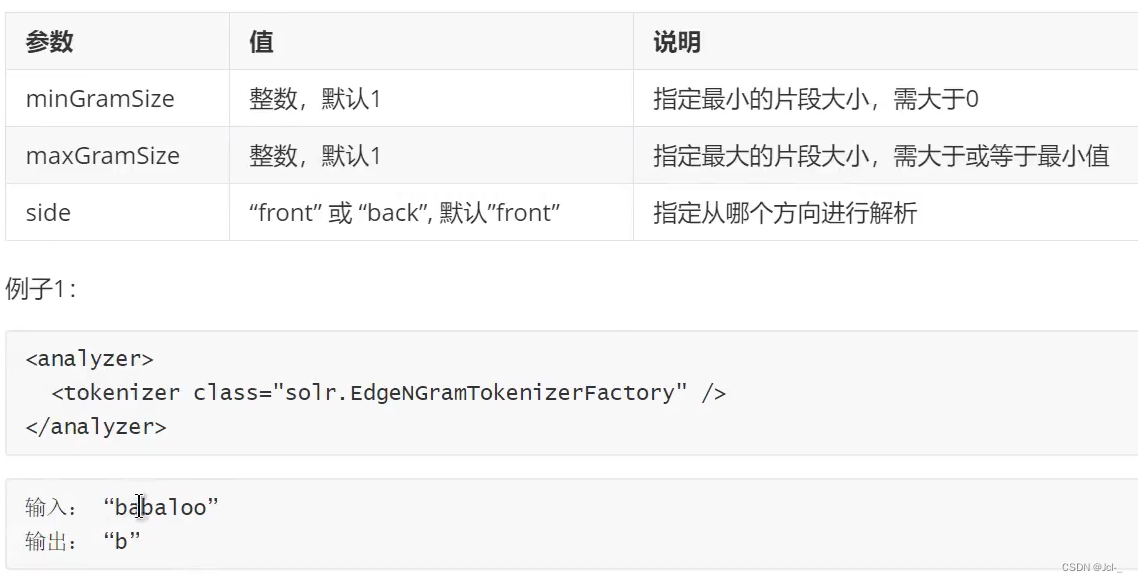
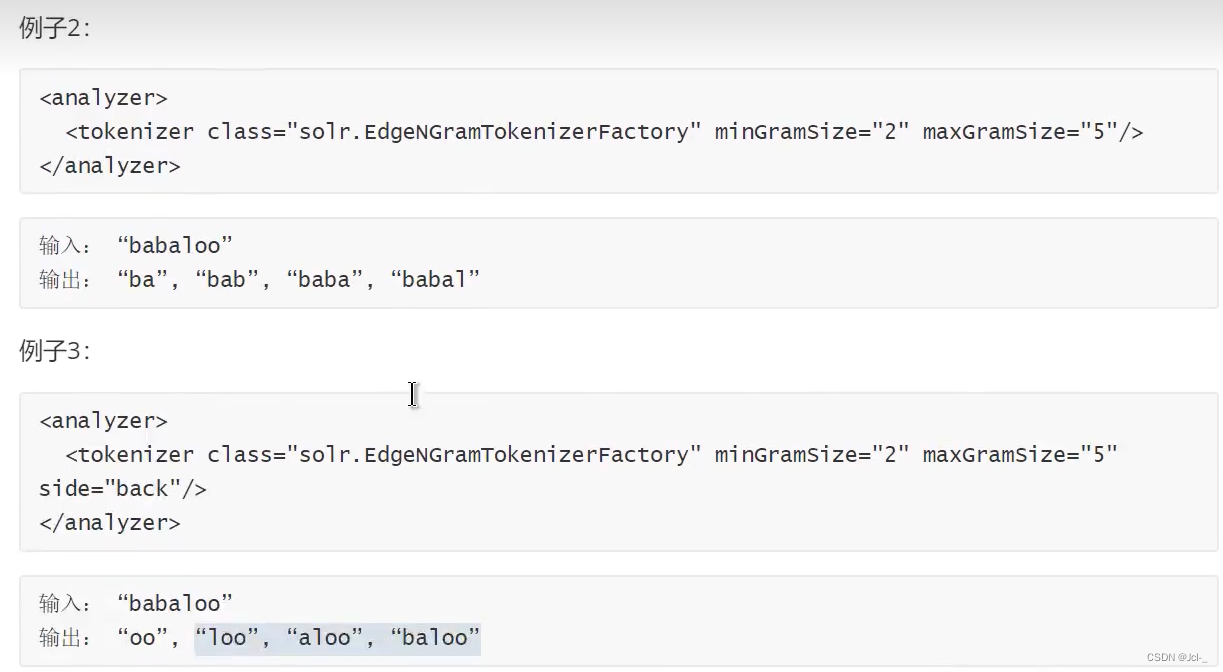
7.Rugular Expression Patthern Tokenizer
作用:可以根据正则表达式来分析文本
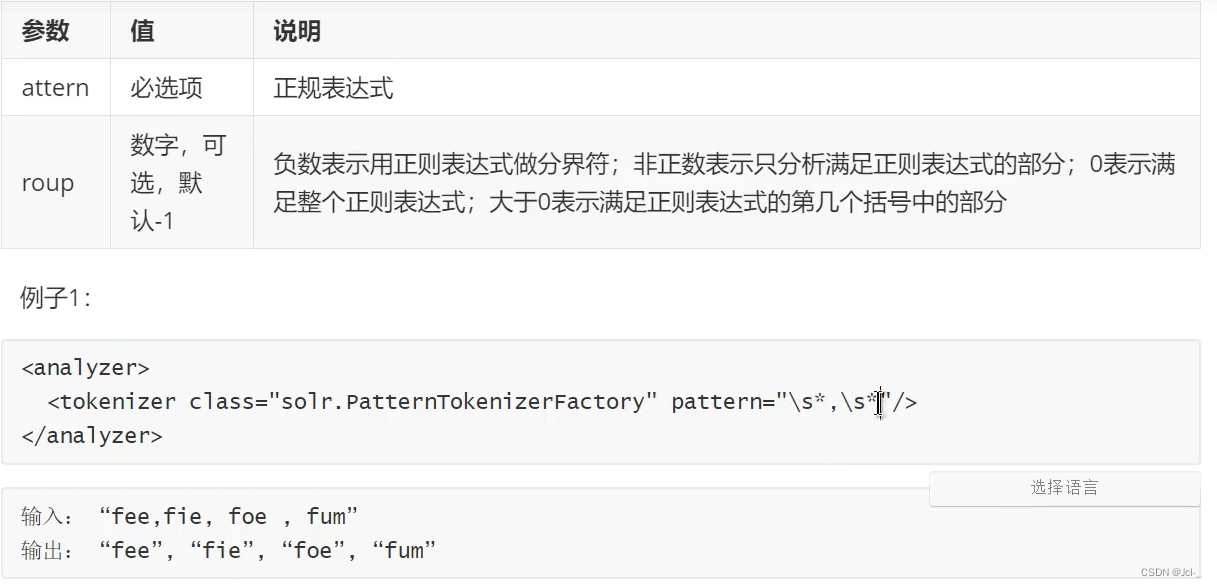
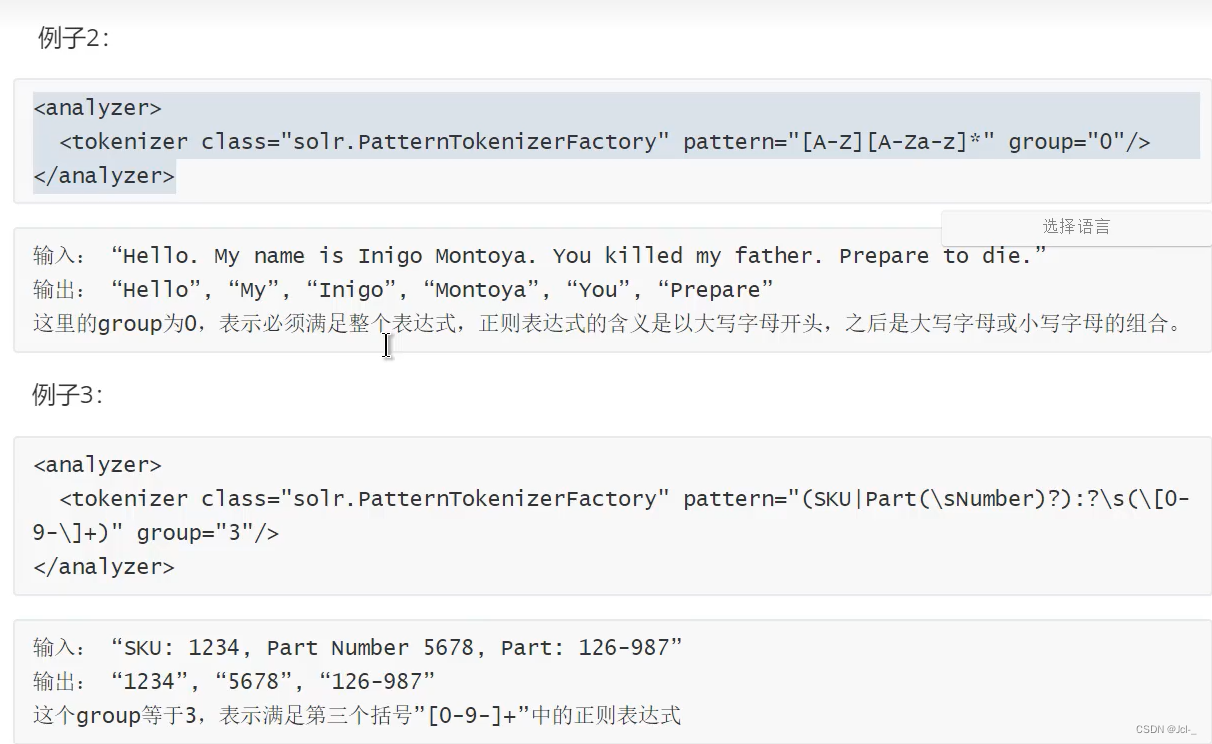
8.White Space Tokenizer
作用:这个Tokenizer将文本的空格当作分隔符

Solr中常用的过滤器
1.Lower Case Filter
作用:这个filter将所有的词的大写字符转换为小写

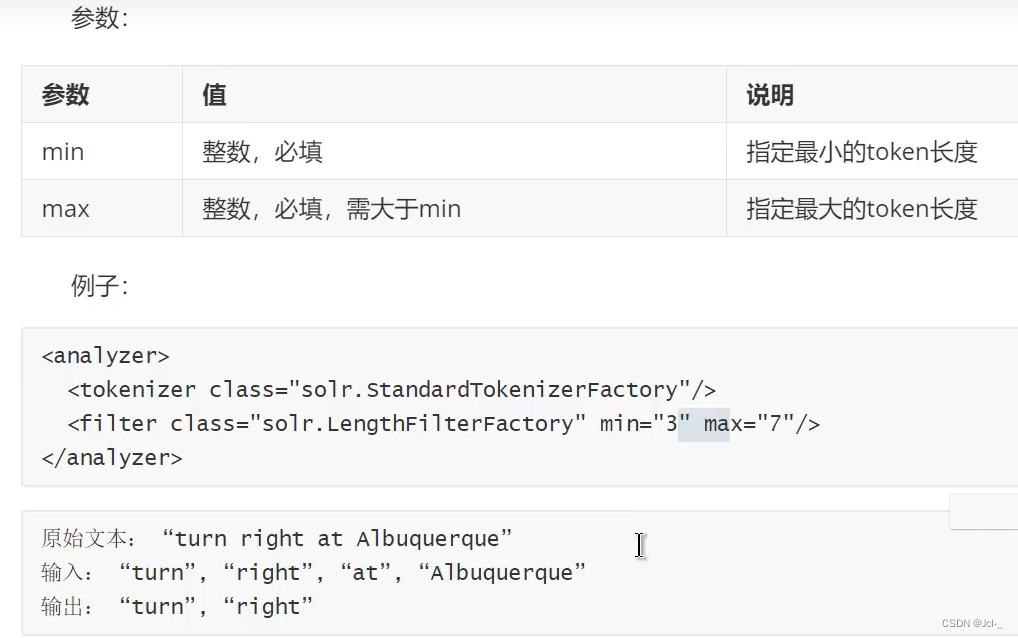
2.Length Filter
处理给定范围长度的tokens
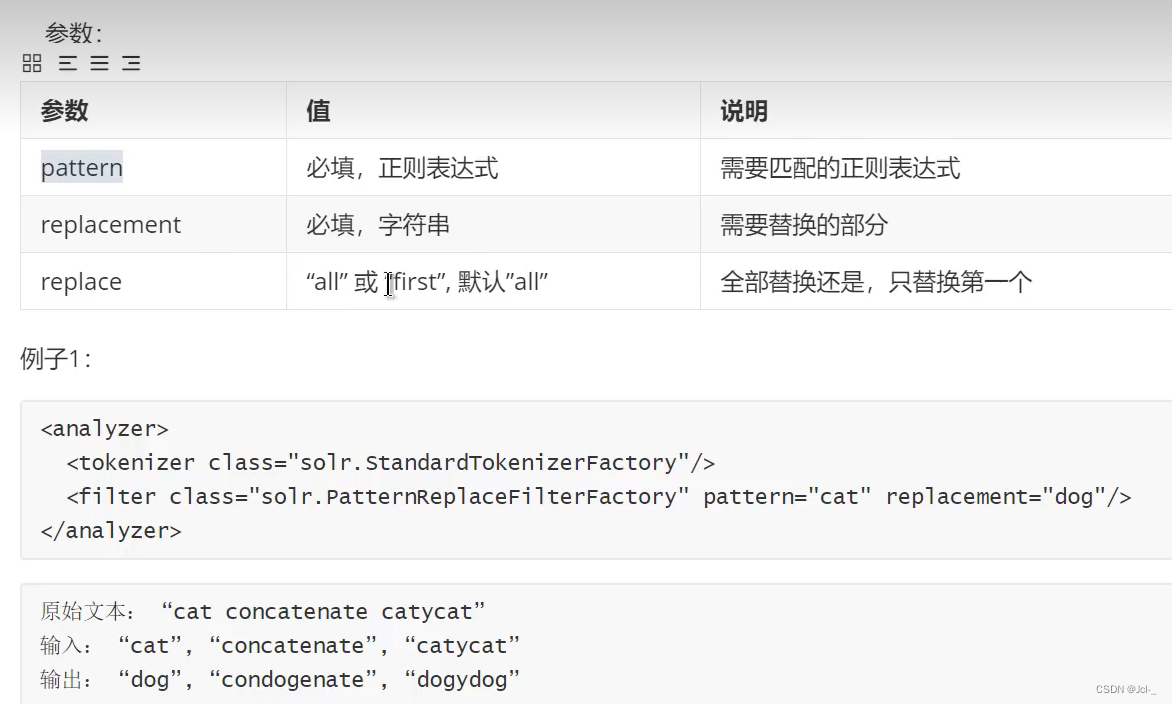
3.Pattern Replace Filter
作用:这个Filter可以使用正则表达式来替换token的一部分内容,与正则表达式想匹配的内容被替换,不匹配的参数不变

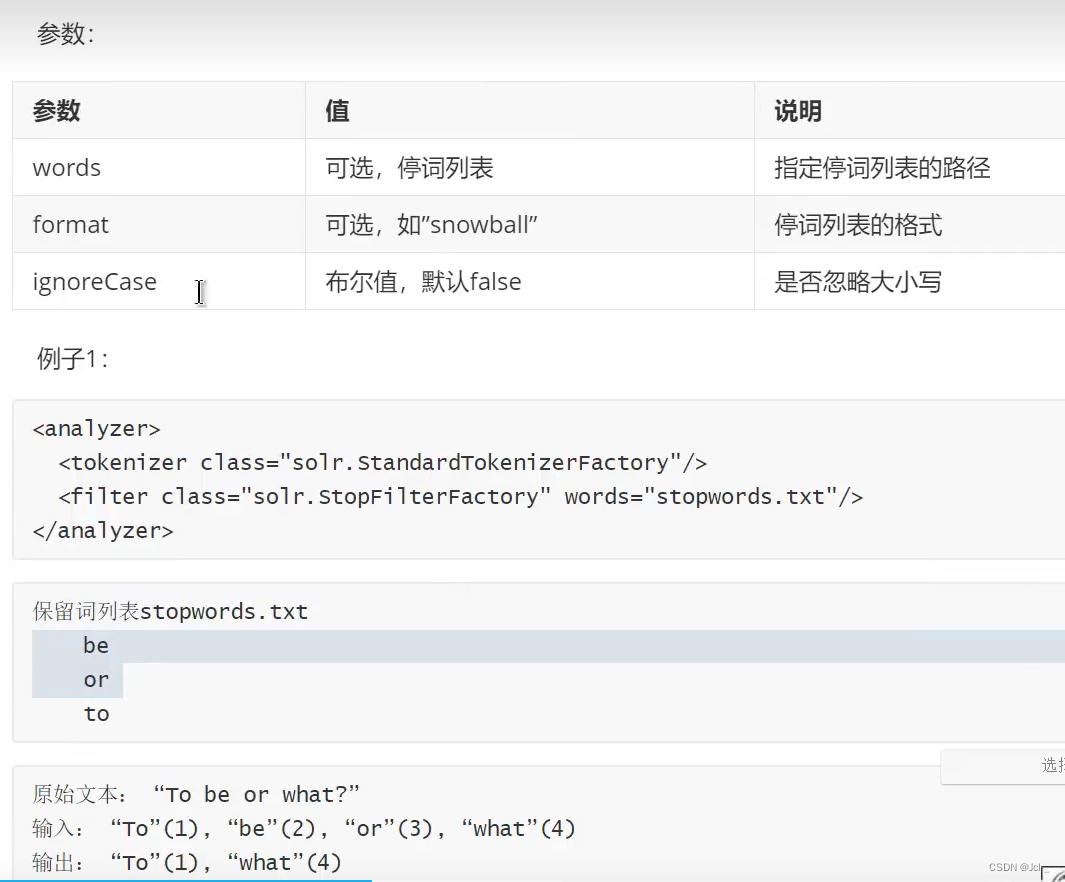
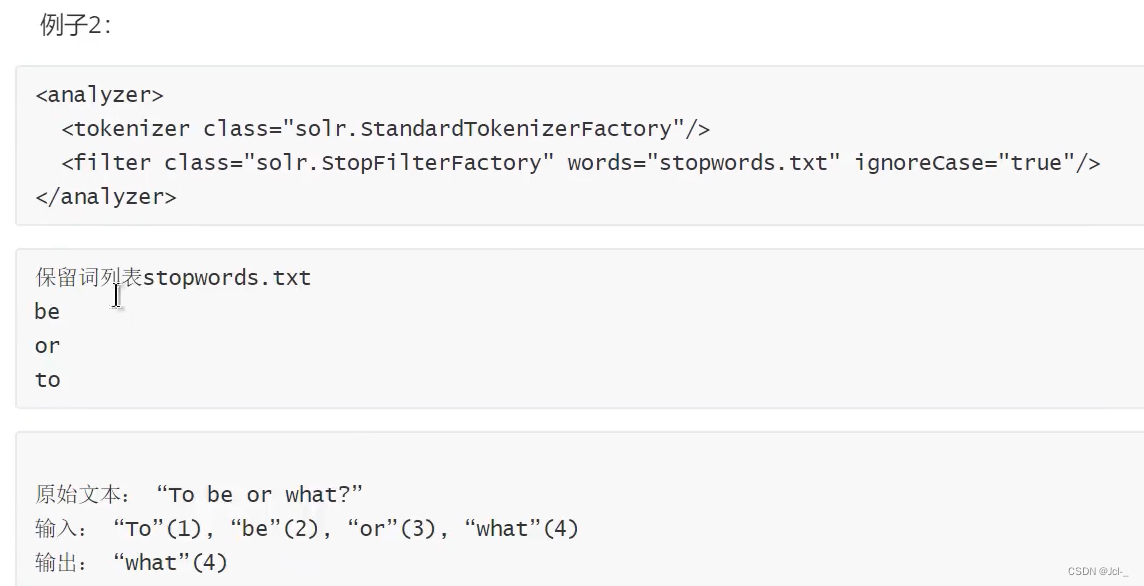
4.Stop Words Filter
作用:这个Filter会在解析时过滤给定的停词列表中的内容
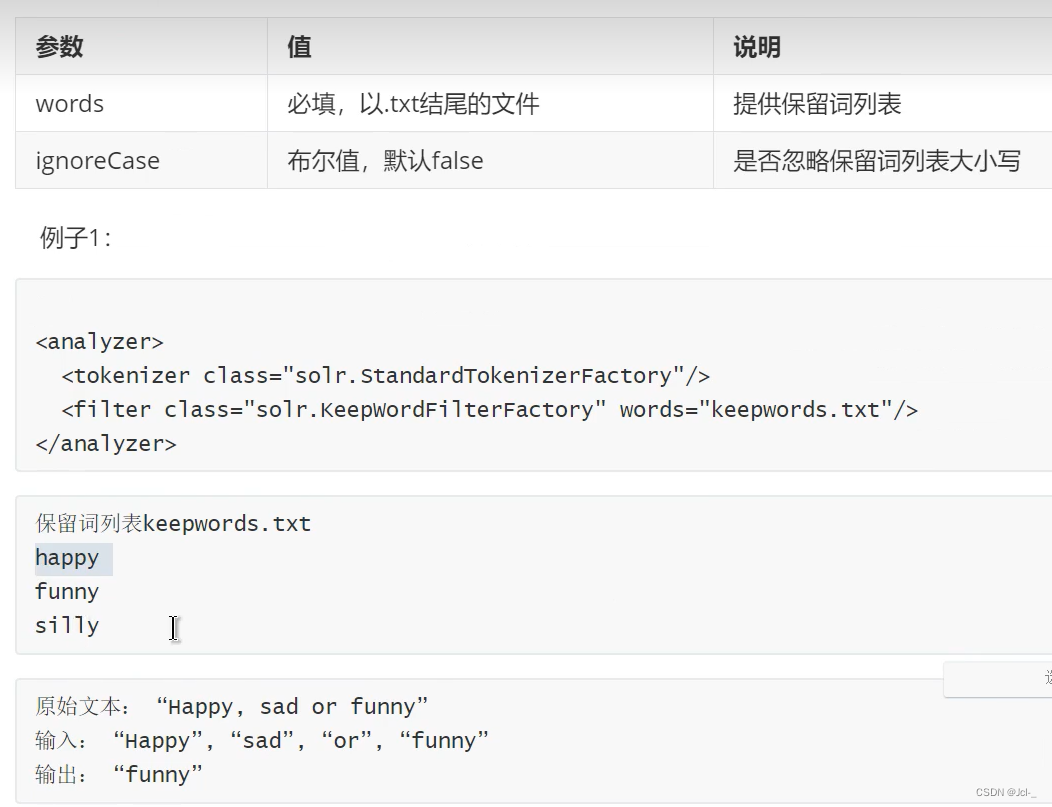
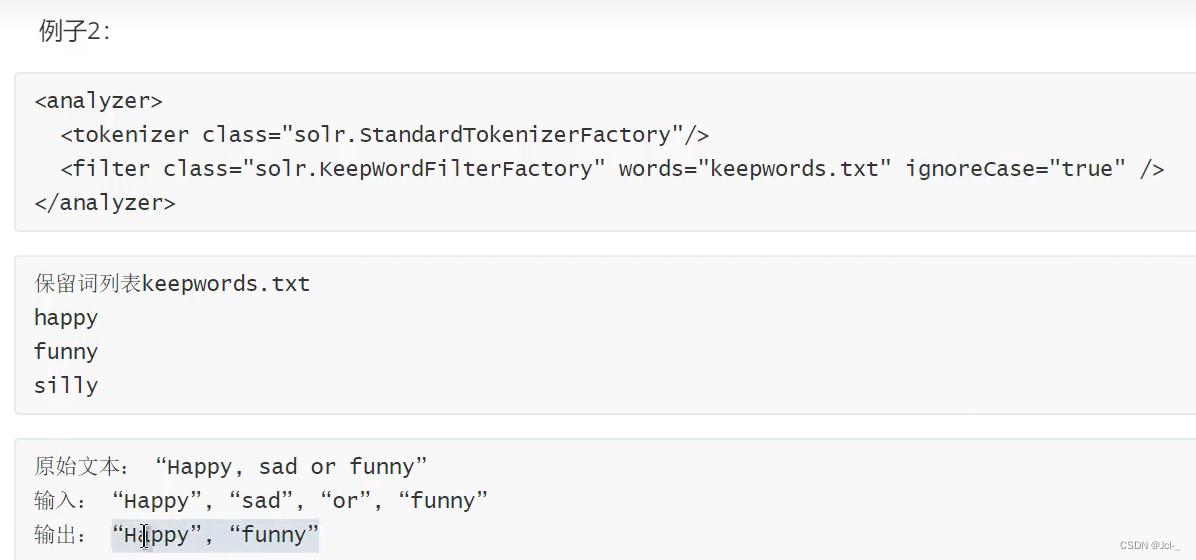
5.Keep Words Filter
作用:这个FIlter将不属于列表中的单词过滤器,与Stop Words Filter作用相反
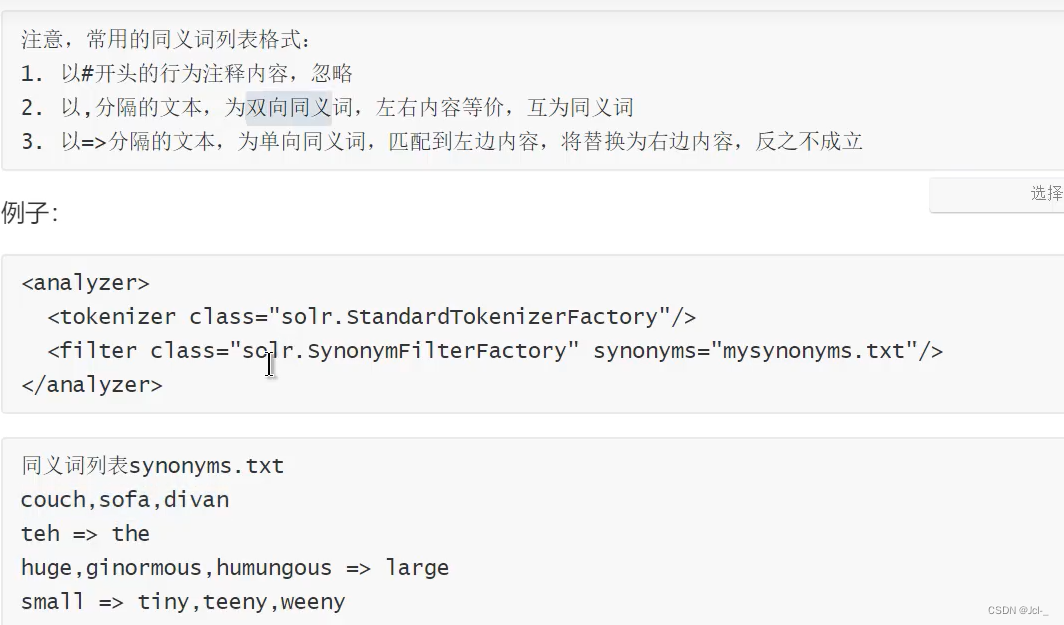
6.Synonym Filter
作用:处理同义词

TextField的使用
使用TextField作为FieldType的class的时候,必须指定Analyzer
方式一:直接通过class属性指定分析器,该类必须继承org.apache.lucene.analysis
优点:写起来简单
缺点:透明度不够,使用者不知道这个分析器封装了那些分词器和过滤器
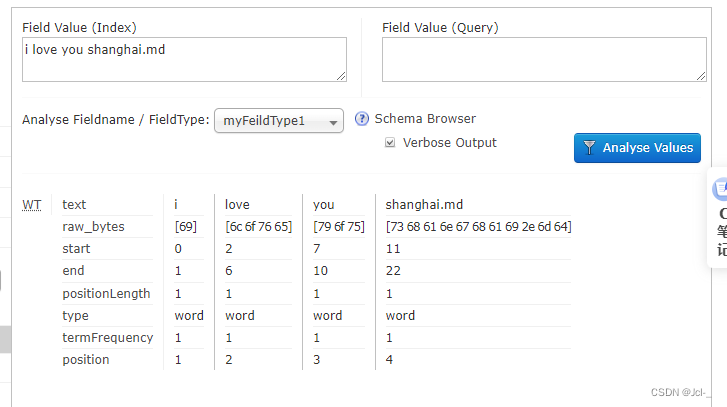
<fieldType name="myFeildType1" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/>
</fieldType>
方式二:可以灵活的组合分词器和过滤器
对于那些复制的分析需求,我们也可以在分析器中灵活的组合分词器和过滤器
<!-- TextField使用方式二:组合分词器和过滤器 -->
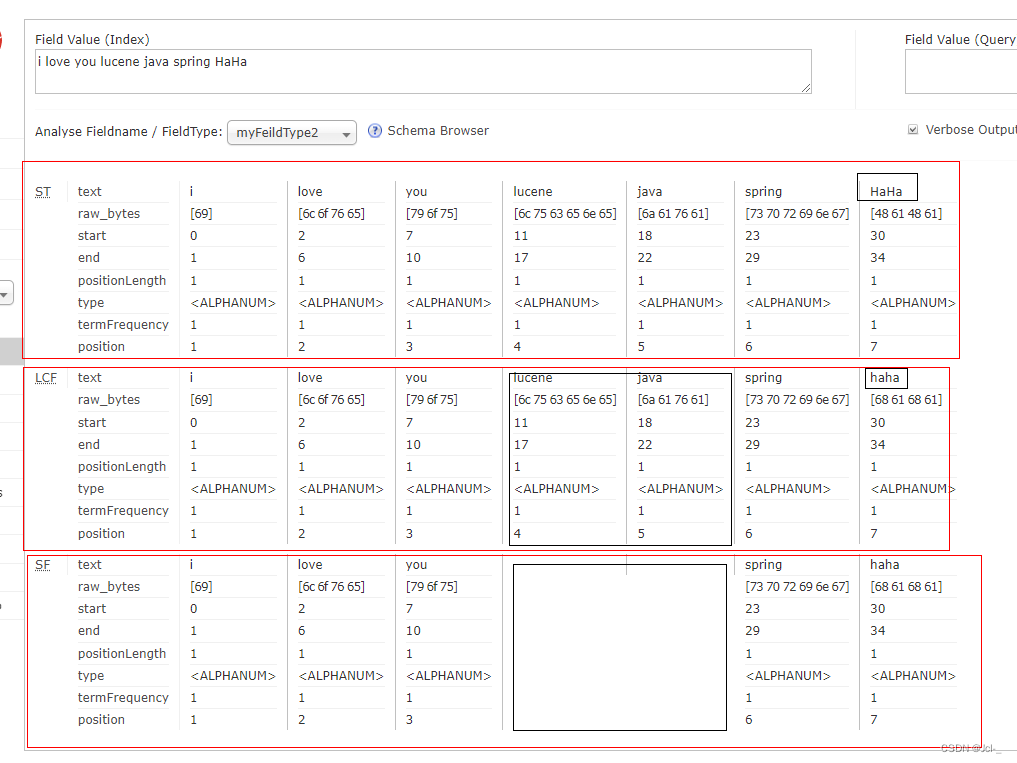
<fieldType name="myFeildType2" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt"/>
</analyzer>
</fieldType>
需要在stopwords.txt设置过滤词
分析结果:
方式三:如果该类型字段索引,查询时需要使用不同的分析器,则需区分配置analyzer
PS:索引采用细粒度分词器,查询采用粗粒度分词器
<!-- 方式三:如果该类型字段索引,查询时需要使用不同的分析器,则需区分配置analyzer -->
<fieldType name="myFieldType3" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="syns.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
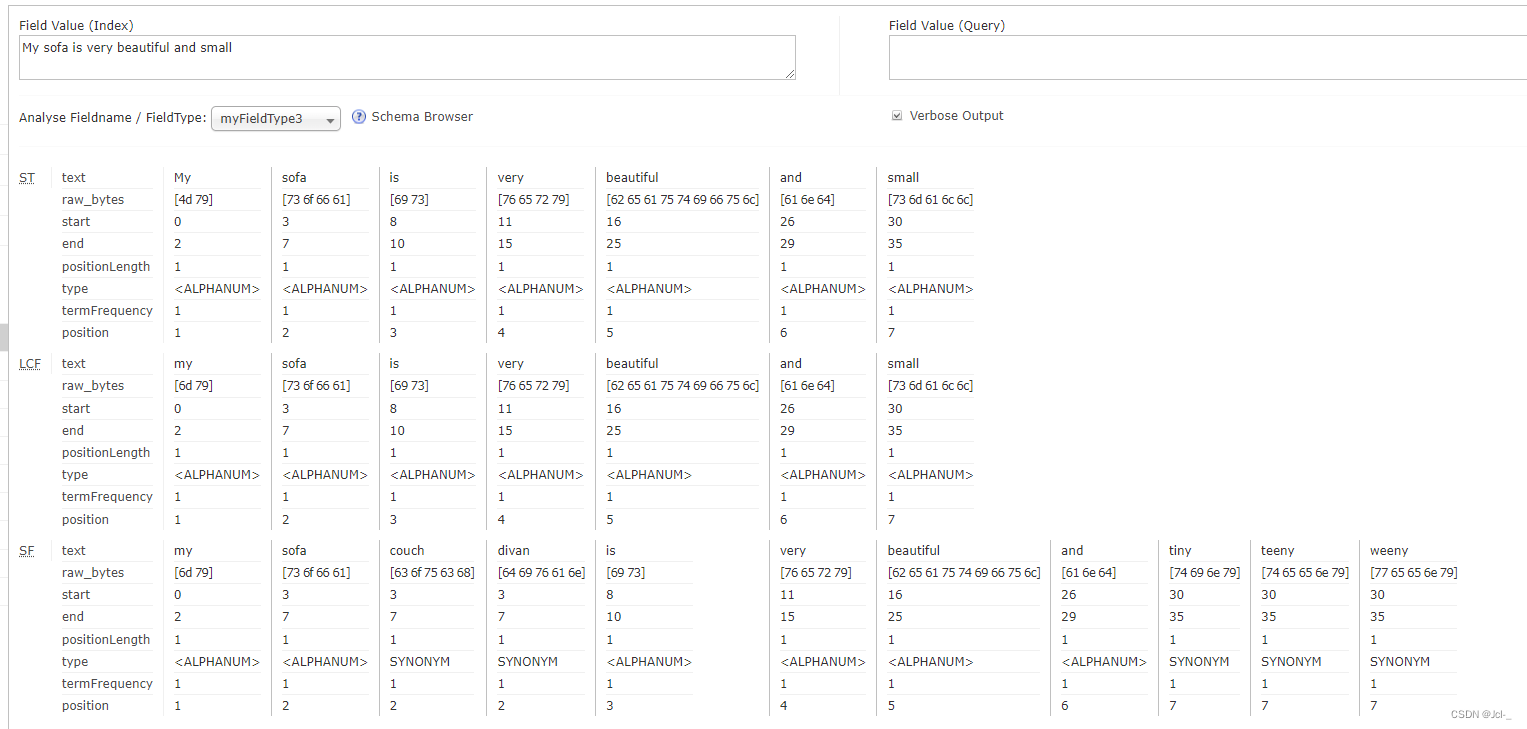
syns.txt
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny
分析index结果
分析query结果

使用自定义FieldType域

DataRangeField(时间域类型)
<field name="item_birthday" type="myDate" indexed="true" stored="true"/>
<!-- 定义DataRangeField日期域类型 -->
<fieldType name="myDate" class="solr.DateRangeField"/>
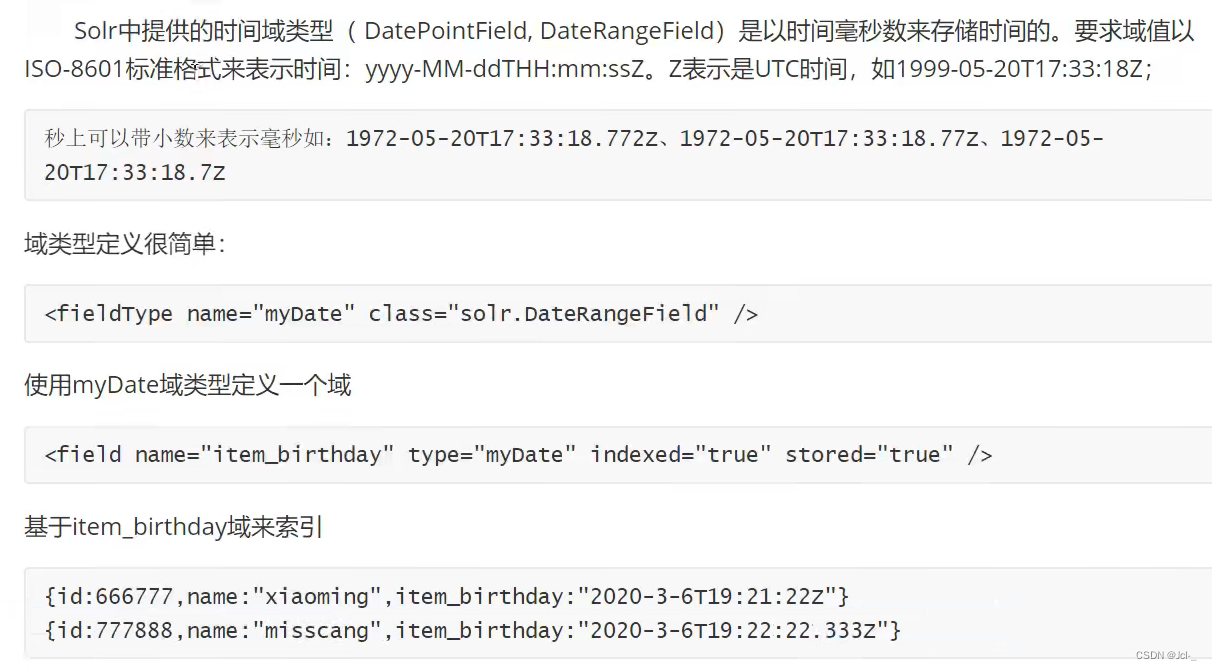
此时,我遇到一个错误
发现问题:末尾的那个Z是大写的,使用小写会报错
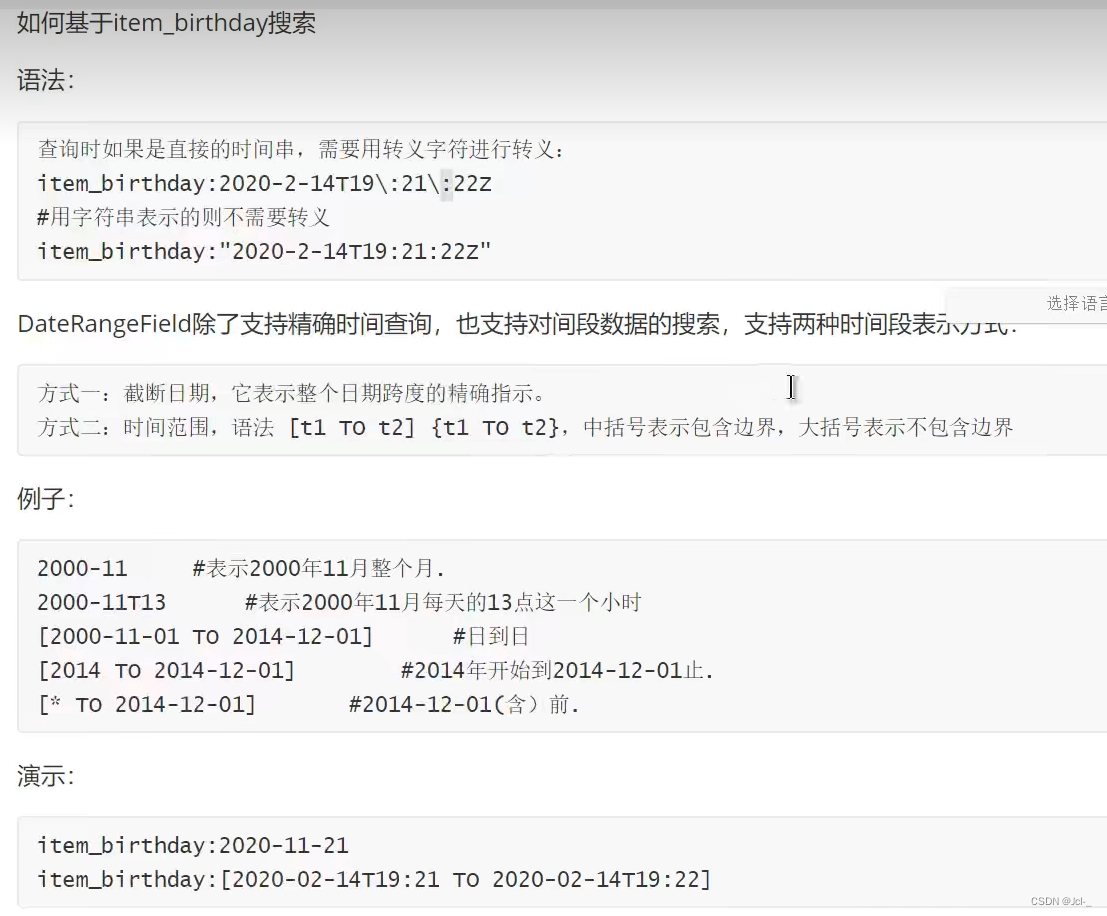
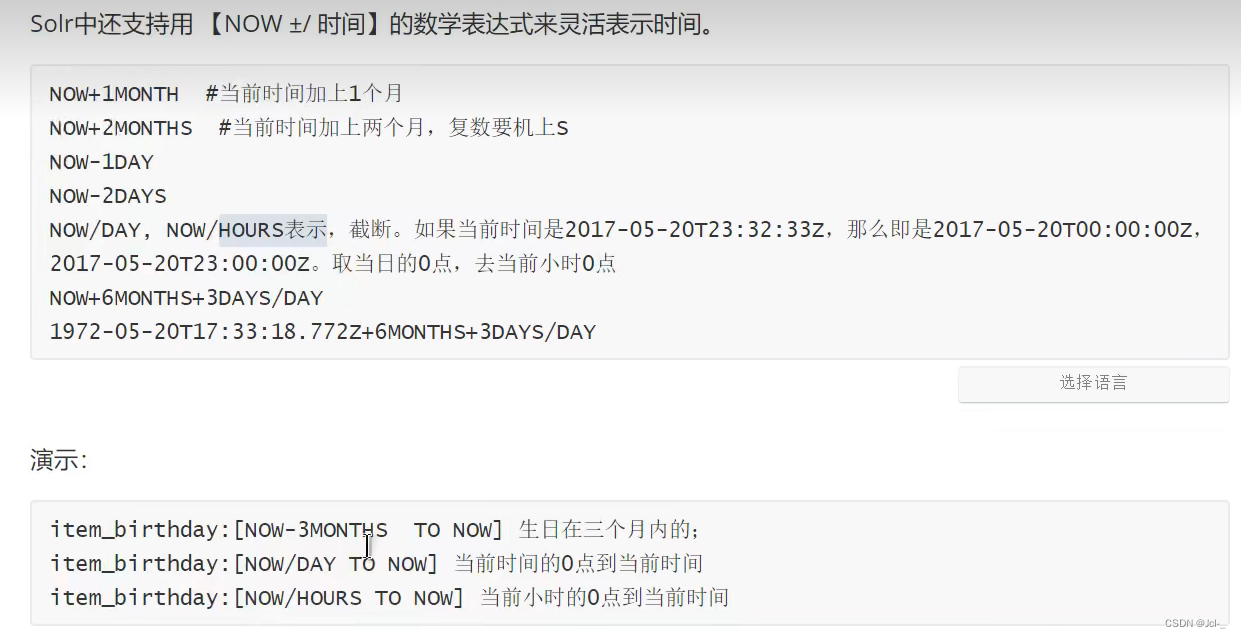
EnumFieldType(时间域类型)
作用:如果域值是一个枚举集合,且排序顺序可以预定的情况下,如果我们想要定义一个域类型,他的域值只能取指定的值,考虑使用EnumFieldType

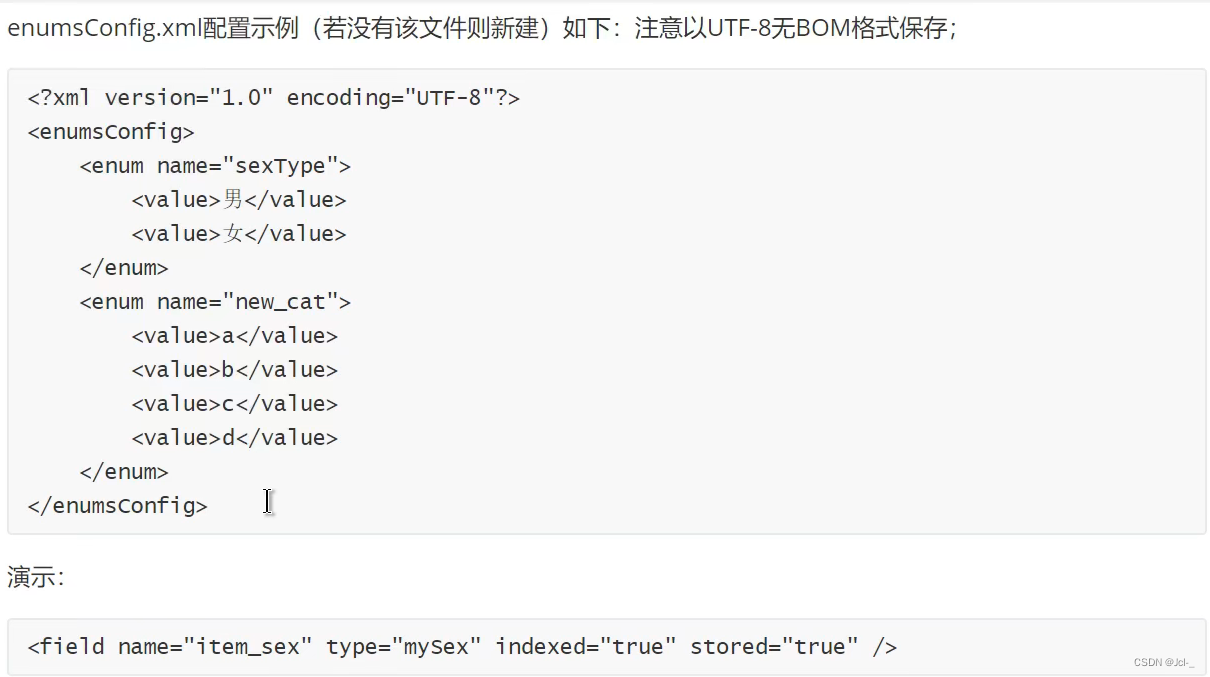
<?xml version="1.0" encoding="UTF-8"?>
<enumsConfig>
<enum name="sexType">
<value>男</value>
<value>女</value>
</enum>
<enum name="new_cat">
<value>a</value>
<value>b</value>
<value>c</value>
<value>d</value>
</enum>
</enumsConfig>
<field name="item_sex" type="mySex" indexed="true" stored="true"/>
<!-- 定义EnumFieldType枚举域类型 -->
<fieldType name="mySex" class="solr.EnumFieldType" enumsConfig="enumsConfig.xml" enumName="sexType" docValues="true"/>
索引
{id:123321,item_birthday:"1992-04-20T20:33:33Z", item_content: "i love sofa" ,item_sex:"男"}
{id:456564,item_birthday: "1992-04-20T20:33:33Z" ,item_content: "i love sofa" ,item_sex:"女"}

3.2.6Solr的配置-DynamicField 动态域
作用:如果在业务中有特别多的域需要定义,其中有很多域的类型是相同的,那么可以定义一个域名规则,索引的时候,只要域名符合该规则就可以
如:整型域都是一样的定义,则可以定义一个动态域如下
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
注意:只支持*作为通配符,只支持前缀和后缀两种方式
{id:38383,item_birthday:"1992-04-20T20:33:33Z" ,item_content: "i love sofa" ,item_sex:"女",bf_i :5}
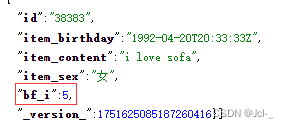
3.2.7Solr的配置-复制域
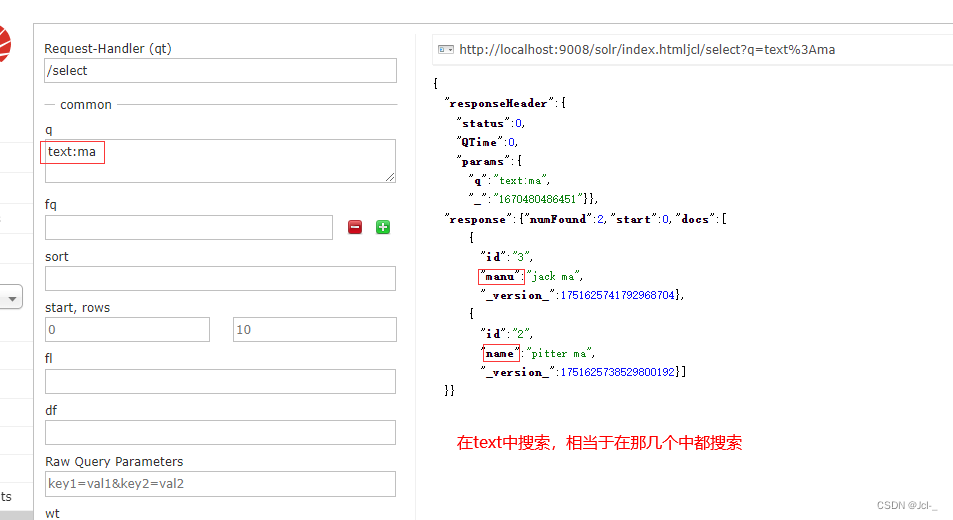
作用:复制域允许一个或多个数据填充存到另一个域中,他的最主要的作用,基于某一个域搜索,相当于在多个域中进行搜索
<copyFie1d source="cat" dest="text" />
<copyField source="name" dest="text"/>
<copyField source="manu" dest="text" />
<copyField source="features" dest="text" />
<copyField source="includes" dest="text" />
cat name manu features includes text都是so1r提前定义好的域。
将cat name manu features inc1udes域的内容填充到text域中;
将来基于text域进行搜索,相当于在cat name manu features includes域中搜索;
索引
{id: 1, name : "pitter wang"}
{id: 2 , name : "pitter ma"}
{id: 3, manu : "jack ma"}
{id: 4, manu : "jack liu"}
3.2.8 Solr的配置-主键域
作用:指定用作唯一标识文档的域,必须。在Solr中默认将id域作为主键域,也可以将其他改为主键域,但是一般都不会修改
<uniqueKey>id</uniqueKey>
3.2.9 Solr的配置-中文分词器
因为Solr提供的分词器对中文的分词效果不是很理想,因为断词需要语境,所以需要学习市面上主流的中文分词器
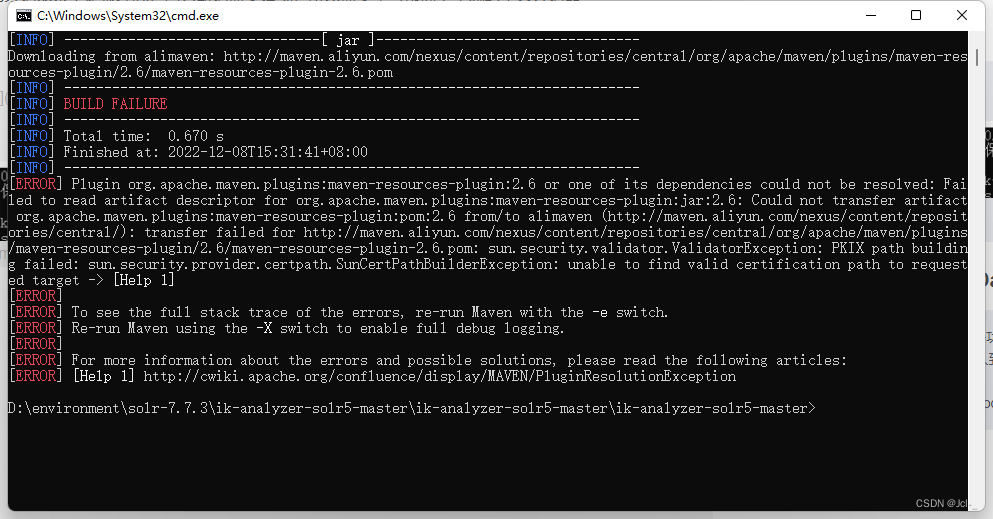
IK Analyzer
下载地址:ik-analyzer-solr5
打包
bug
未解决,但是我直接从网上下载了一个jar包
链接:https://pan.baidu.com/s/1vyPVQFiyzXf2TKQrBCylZg?pwd=irkj
提取码:irkj


<!-- 定义ik分析域 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
…
3.2.10 Solr的数据导入(DataImport)
在Solr后台管理系统中提供了一个功能叫做DataImport,作用是将数据库中的数据导入到数据库中,简称DHI;
DataImport将数据库中的数据导入到索引库的方法:
1.查询数据库中的记录
2.将数据库中的一条记录转换为Document,并进行索引
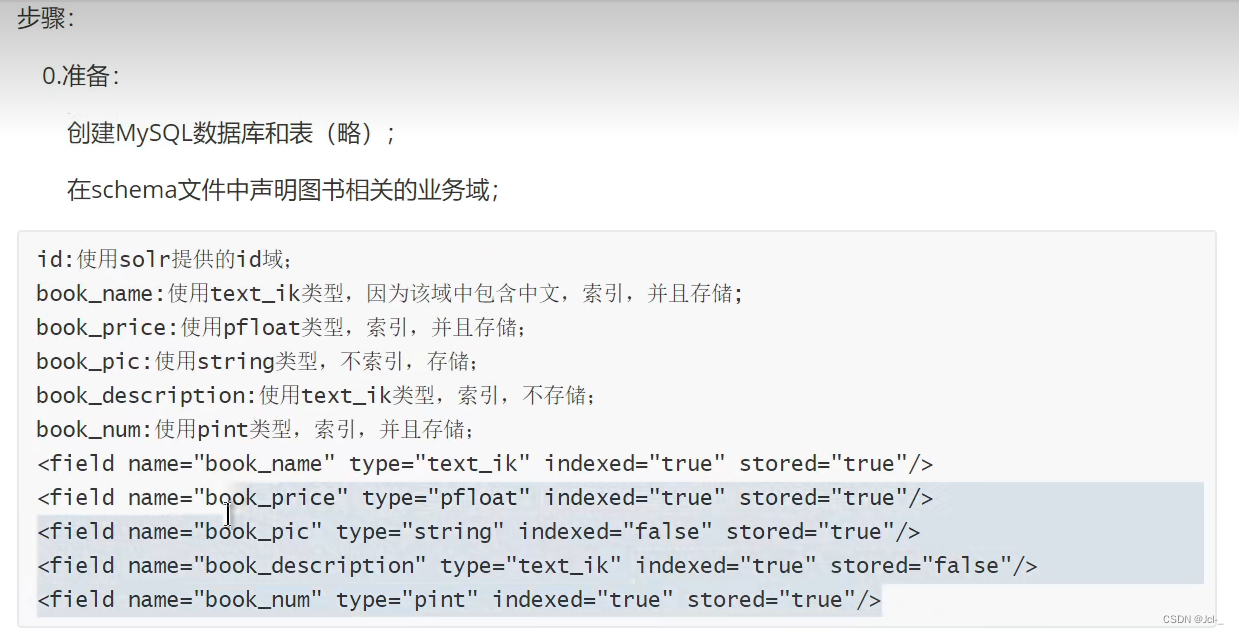
<!-- big_oth_npp_report相关业务域 -->
<field name="big_oth_npp_report_rpt_nd" type="string" indexed="true" stored="true" />
<field name="big_oth_npp_report_no" type="string" indexed="true" stored="true" />
<field name="big_oth_npp_report_theme" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_publish_org" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_npp_org" type="text_ik" indexed="true" stored="true" />

<!-- big_oth_npp_report相关业务域 -->
<field name="big_oth_npp_report_rpt_nd" type="string" indexed="true" stored="true" />
<field name="big_oth_npp_report_no" type="string" indexed="true" stored="true" />
<field name="big_oth_npp_report_theme" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_publish_org" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_npp_org" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_crew_no" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_report_date" type="myDate" indexed="true" stored="true" />
<field name="big_oth_npp_report_write_name" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_write_time" type="myDate" indexed="true" stored="true" />
<field name="big_oth_npp_report_attach" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_flag" type="text_ik" indexed="true" stored="true" />
<field name="big_oth_npp_report_create_time" type="myDate" indexed="true" stored="true" />
<field name="big_oth_npp_report_update_time" type="myDate" indexed="true" stored="true" />
<field name="big_oth_npp_report_is_delete" type="pint" indexed="true" stored="true" />
<dataConfig>
<!-- 首先配置数据源指定数据库的连接信息 -->
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/pigxx_cnpboxdb?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8&allowMultiQueries=true"
user="root"
password="123456"/>
<!-- entitty作用:数据库中的字段和域名如何映射
name:表示,任意
query:执行的查询语句
-->
<document>
<entity name="big_oth_npp_report" query="select * from big_oth_npp_report">
<!-- 每一个field映射着数据库中的列与文档中的域,column是数据库的列,name是solr中的域(要在managed-schema文件中配置过才可以) -->
<field column="id" name="id"/>
<field column="rpt_nd" name="big_oth_npp_report_rpt_nd"/>
<field column="no" name="ibig_oth_npp_report_no"/>
<field column="theme" name="big_oth_npp_report_theme"/>
<field column="publish_org" name="big_oth_npp_report_publish_org"/>
<field column="npp_org" name="big_oth_npp_report_npp_org"/>
<field column="crew_no" name="big_oth_npp_report_crew_no"/>
<field column="report_date" name="big_oth_npp_report_report_date"/>
<field column="write_name" name="big_oth_npp_report_write_name"/>
<field column="write_time" name="big_oth_npp_report_write_time"/>
<field column="attach" name="big_oth_npp_report_attach"/>
<field column="flag" name="big_oth_npp_report_flag"/>
<field column="create_time" name="big_oth_npp_report_create_time"/>
<field column="update_time" name="big_oth_npp_report_update_time"/>
<field column="is_delete" name="big_oth_npp_report_is_delete"/>
</entity>
</document>
</dataConfig>
bug好家伙,又又又遇到问题了
Field must have a column attribute
根据报错的意思看了下我写的xml,果然单词拼错了,我真是服了,是column~
bug
2022-12-08 17:34:30.759 ERROR (Thread-5) [ ] o.a.s.h.d.DataImporter Full Import failed:java.lang.RuntimeException: java.lang.RuntimeException: org.apache.solr.handler.dataimport.DataImportHandlerException: Invalid type for data source: com.alibaba.druid.pool.DruidDataSource Processing Document # 1
at org.apache.solr.handler.dataimport.DocBuilder.execute(DocBuilder.java:271)
at org.apache.solr.handler.dataimport.DataImporter.doFullImport(DataImporter.java:424)
at org.apache.solr.handler.dataimport.DataImporter.runCmd(DataImporter.java:483)
at org.apache.solr.handler.dataimport.DataImporter.lambda$runAsync$0(DataImporter.java:466)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.RuntimeException: org.apache.solr.handler.dataimport.DataImportHandlerException: Invalid type for data source: com.alibaba.druid.pool.DruidDataSource Processing Document # 1
at org.apache.solr.handler.dataimport.DocBuilder.buildDocument(DocBuilder.java:417)
at org.apache.solr.handler.dataimport.DocBuilder.doFullDump(DocBuilder.java:330)
at org.apache.solr.handler.dataimport.DocBuilder.execute(DocBuilder.java:233)
... 4 more
Caused by: org.apache.solr.handler.dataimport.DataImportHandlerException: Invalid type for data source: com.alibaba.druid.pool.DruidDataSource Processing Document # 1
at org.apache.solr.handler.dataimport.DataImportHandlerException.wrapAndThrow(DataImportHandlerException.java:69)
at org.apache.solr.handler.dataimport.DataImporter.getDataSourceInstance(DataImporter.java:383)
at org.apache.solr.handler.dataimport.ContextImpl.getDataSource(ContextImpl.java:100)
at org.apache.solr.handler.dataimport.SqlEntityProcessor.init(SqlEntityProcessor.java:53)
at org.apache.solr.handler.dataimport.EntityProcessorWrapper.init(EntityProcessorWrapper.java:77)
at org.apache.solr.handler.dataimport.DocBuilder.buildDocument(DocBuilder.java:434)
at org.apache.solr.handler.dataimport.DocBuilder.buildDocument(DocBuilder.java:415)
... 6 more
Caused by: java.lang.ClassNotFoundException: Unable to load com.alibaba.druid.pool.DruidDataSource or org.apache.solr.handler.dataimport.com.alibaba.druid.pool.DruidDataSource
at org.apache.solr.handler.dataimport.DocBuilder.loadClass(DocBuilder.java:935)
at org.apache.solr.handler.dataimport.DataImporter.getDataSourceInstance(DataImporter.java:381)
... 11 more
Caused by: org.apache.solr.common.SolrException: Error loading class 'com.alibaba.druid.pool.DruidDataSource'
at org.apache.solr.core.SolrResourceLoader.findClass(SolrResourceLoader.java:557)
at org.apache.solr.core.SolrResourceLoader.findClass(SolrResourceLoader.java:488)
at org.apache.solr.handler.dataimport.DocBuilder.loadClass(DocBuilder.java:926)
... 12 more
Caused by: java.lang.ClassNotFoundException: com.alibaba.druid.pool.DruidDataSource
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.net.FactoryURLClassLoader.loadClass(URLClassLoader.java:817)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.solr.core.SolrResourceLoader.findClass(SolrResourceLoader.java:541)
... 14 more
修改配置后解决…,修改后的结果就是上面的配置
3.2.11 solrconfig.xml
…
3.2.12后台管理界面其他操作
…
4.Solr查询
4.1Solr查询概述
4.2相关度排序
查询出来的结果会按照相关度进行排序,比如出现次数,以及设置权重
4.3查询解析器(QueryParase)
作用:对查询内容进行解析
4.4查询语法
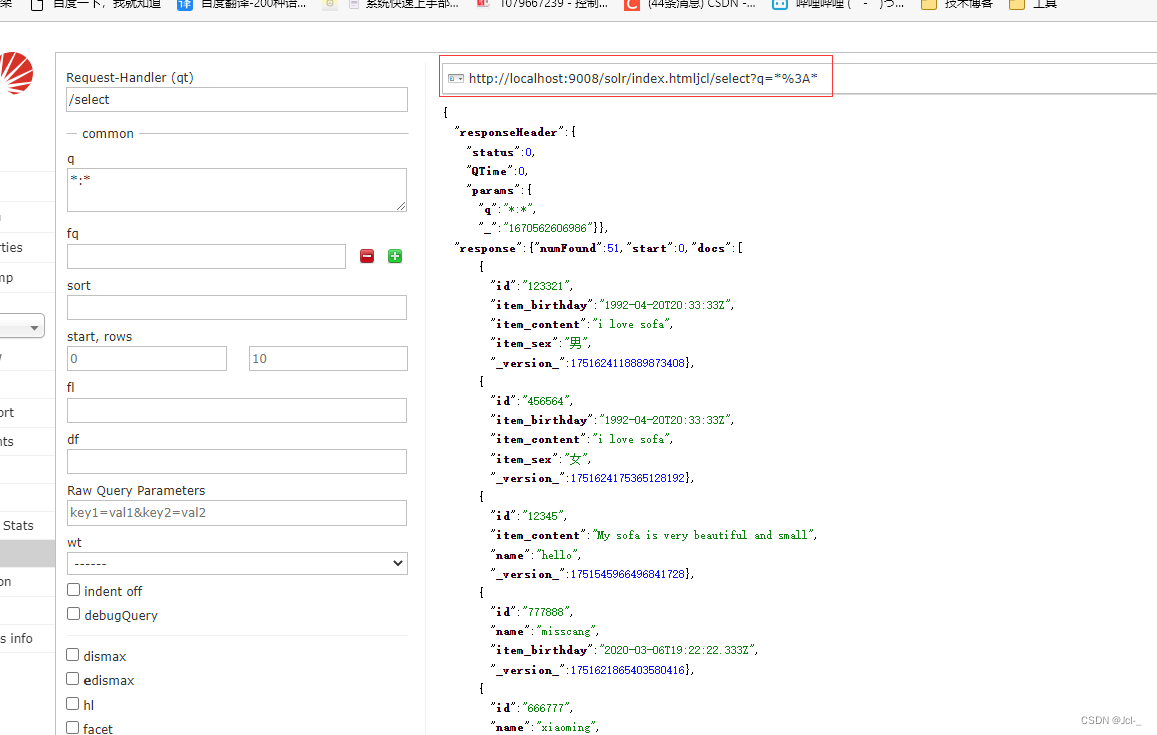
http://localhost:9008/solr/jcl/select?q=%3A:查询请求的url
http://localhost:9008/solr:solr服务地址
jcl:SolrCore /select:请求处理器
?q=%3A:请求处理参数
4.4.1基本查询参数
q:查询条件
fq:过滤条件
start:结果集第一条记录的偏移量,用于分页,默认为0
rows:返回文档的记录数,用于分页,默认10
sort:排序,格式:sort=+<asc|desc>[,+<asc|desc>默认是相关性排序
fl:返回指定的域名,多个域名用逗号或者空格分隔,默认返回所有域
wt:返回响应的格式,例如xml,json
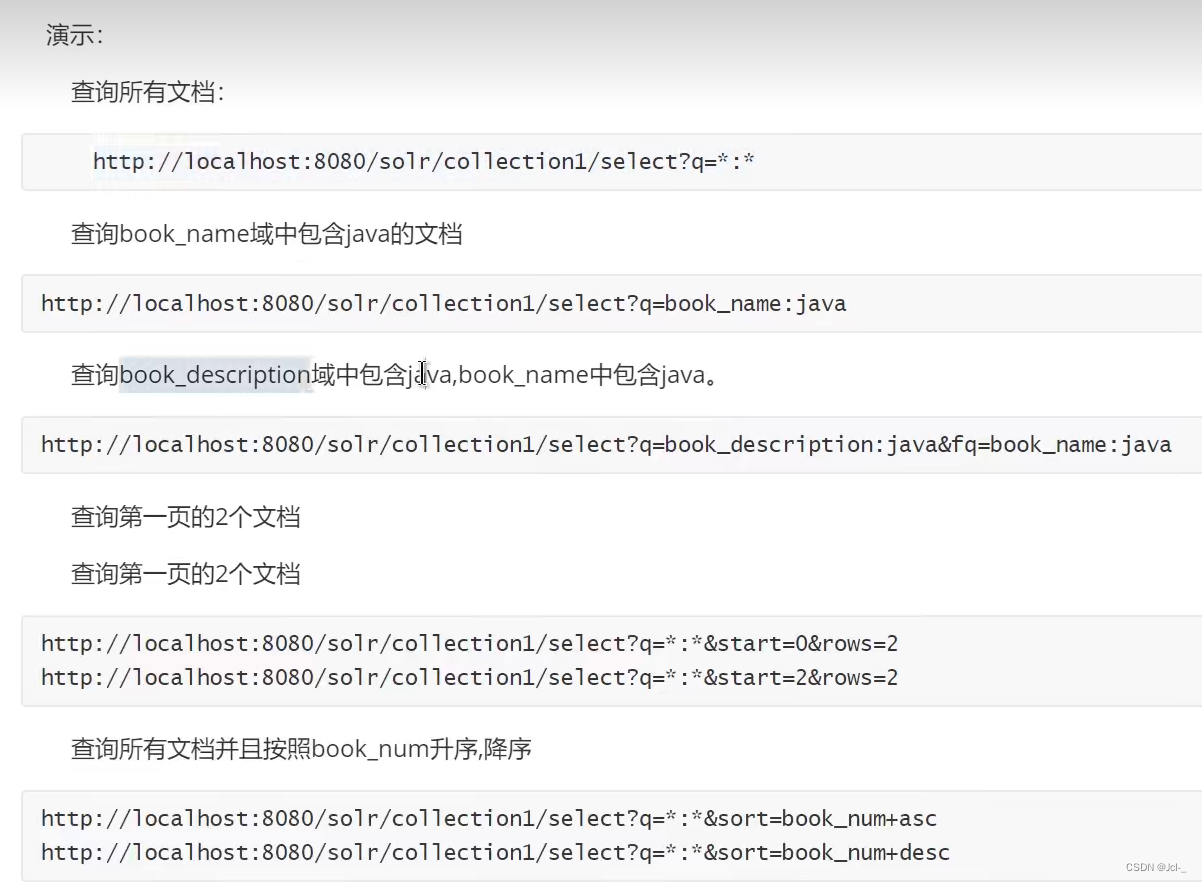
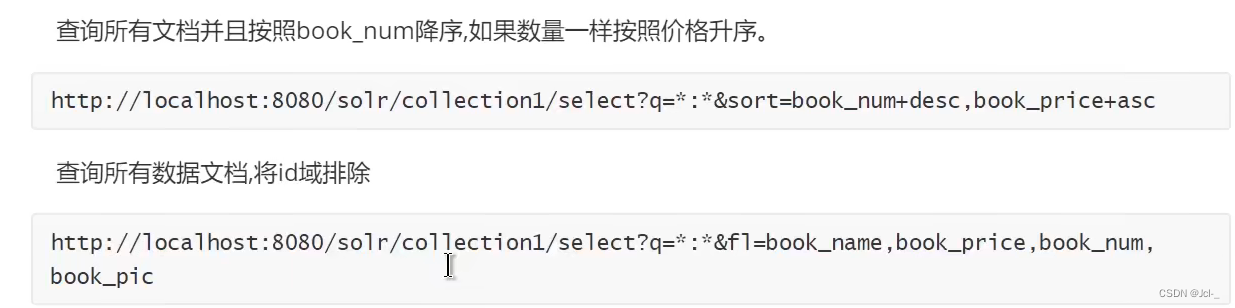


4.4.2组合查询
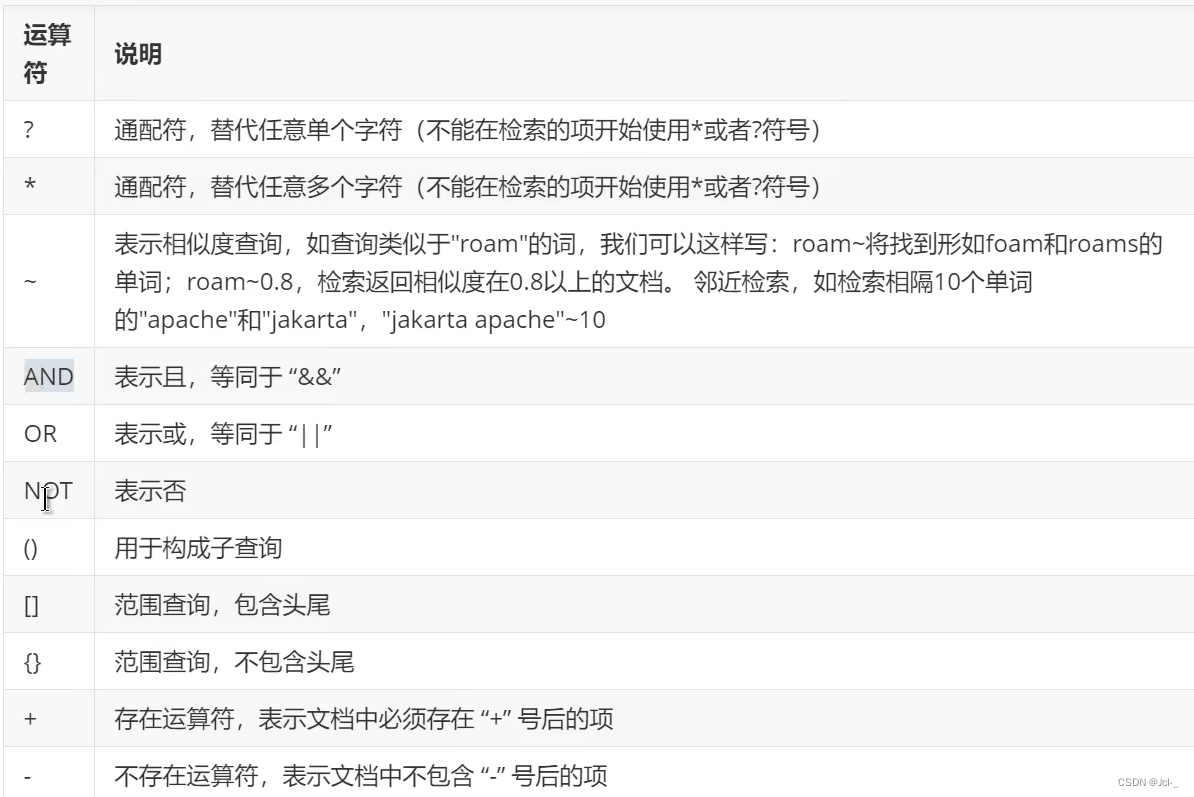
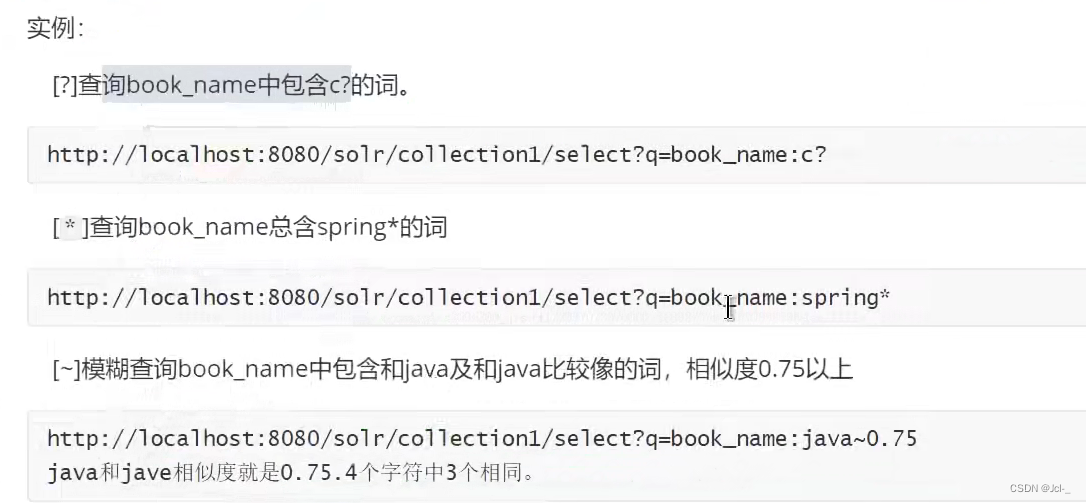

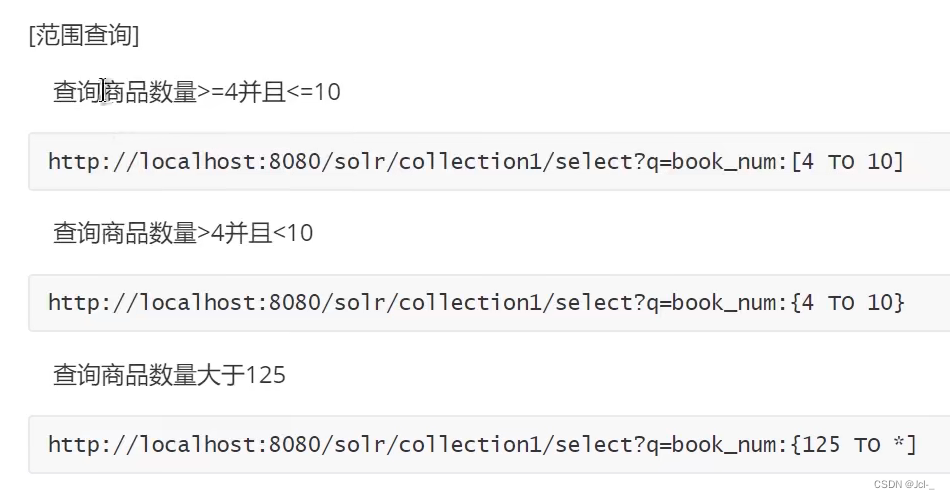
4.4.3 q和fq的区别
从使用上:q必须传参数,fq可以传可以不传,在执行查询的时候,必须有q,可以有fq也可以没有
从功能上:
q有两项功能:1.根据用户输入的查询条件,查询符合条件的文档。2.使用相关算法,匹配到的文档进行相关度排序
fq只有一项功能:对匹配到的文档进行过滤,不会影响相关度排序,效率高
4.4.4 Solr排序结果和排序
wt,指定返回类型
fl:指定返回文档包含的域类型 product(a,b) :a*b



4.5 高级查询-facet查询
4.5.1简单介绍
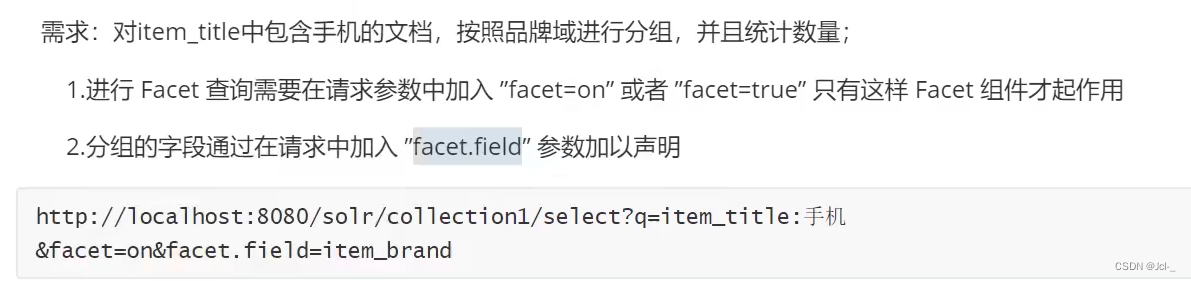
作用:可以根据用户搜索条件,按照指定域进行分组并且统计,类似于关系型数据库中的group by 分组查询;
Face比较适合的域: 一般代表了实体的某种公共属性的域,如商品的品牌,商品的分类,商品的制造厂家,商品的出版商得到 Facet域的要求
facet的域必须被索引,一般来说该域无需分词,无需存储,

4.5.3 facet查询的分类
1.facet_queries:表示根据条件进行分组统计查询
2.facet_fields:代表根据域分组统计查询
3.facet_ranges:可以根据时间区间和数字区间进行分组统计查询
4.facet_intervals:可以根据时间区间和数字区间进行分组统计查询
4.5.4 facet_fields

…
4.6 高级查询-group查询
4.7 高级查询-高亮查询
4.8 Solr Query Suggest
4.8.3拼写检查(主要是DirectSolrSpellChecker)
<fieldType name="spell_text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
<field name="spell" type="spell_text_ik" multiValued="true" indexed="true" stored="false"/>
<copyField source="big_oth_npp_report_theme" dest="spell"/>
<copyField source="big_oth_npp_report_publish_org" dest="spell"/>
<copyField source="big_oth_npp_report_write_name" dest="spell"/>
<copyField source="big_oth_npp_report_crew_no" dest="spell"/>
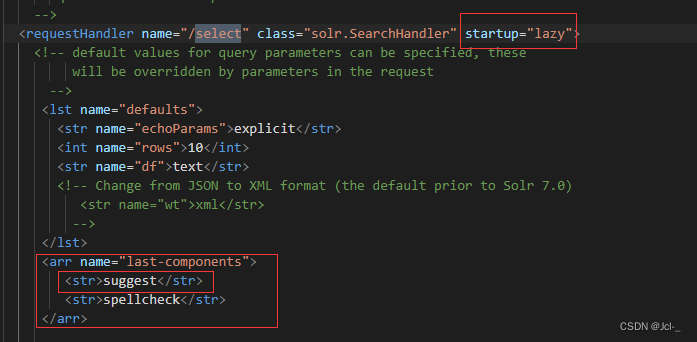
修改solrconfig.xml文件中的配置

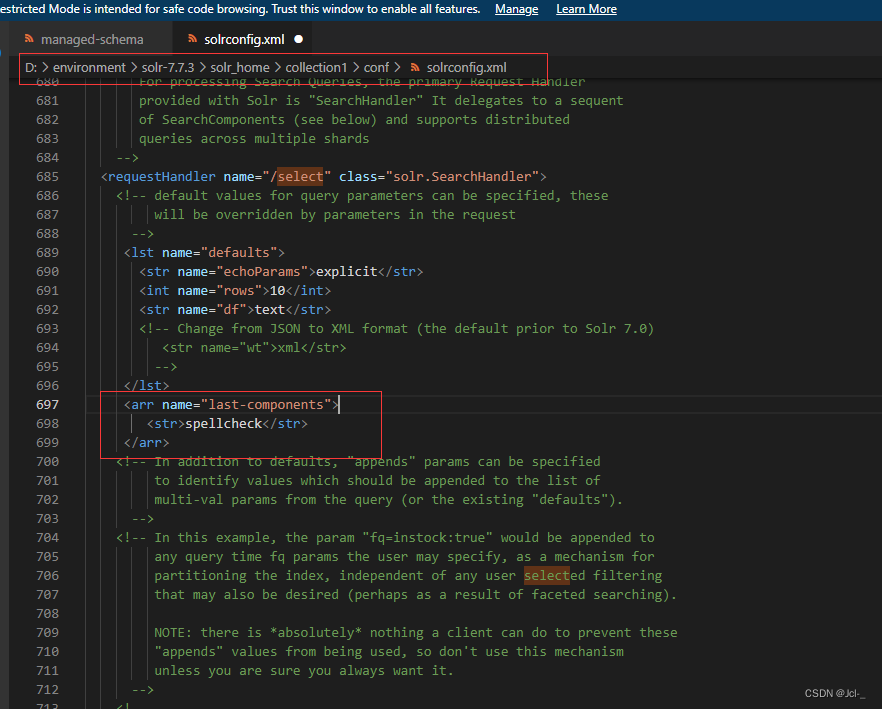
<arr name="last-components">
<str>spellcheck</str>
</arr>
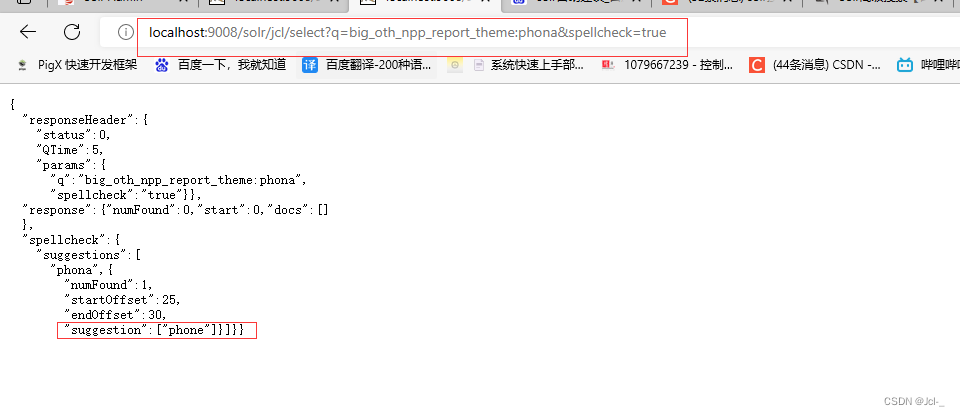
http://localhost:9008/solr/jcl/select?q=big_oth_npp_report_theme:phona&spellcheck=true
bug: 不显示分词建议,可以查询到分词结果
bug解决,原因是配置文件中单词大小写问题,配置还是直接复制比较好,不然出错了太难找了~

4.8.4 自动建议
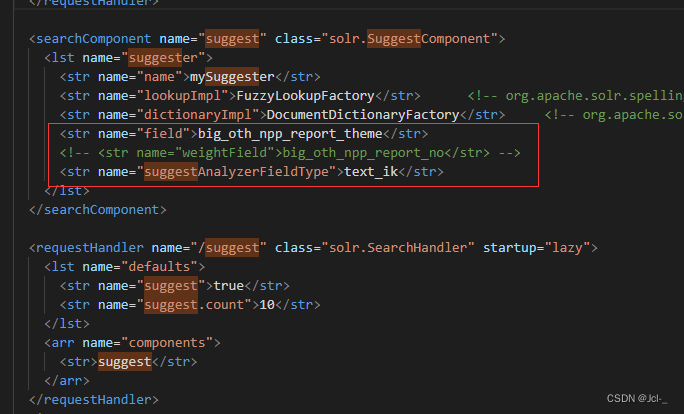
http://localhost:9008/solr/jcl/suggest?q=phone&suggest=true&suggest.dictionary=mySuggester
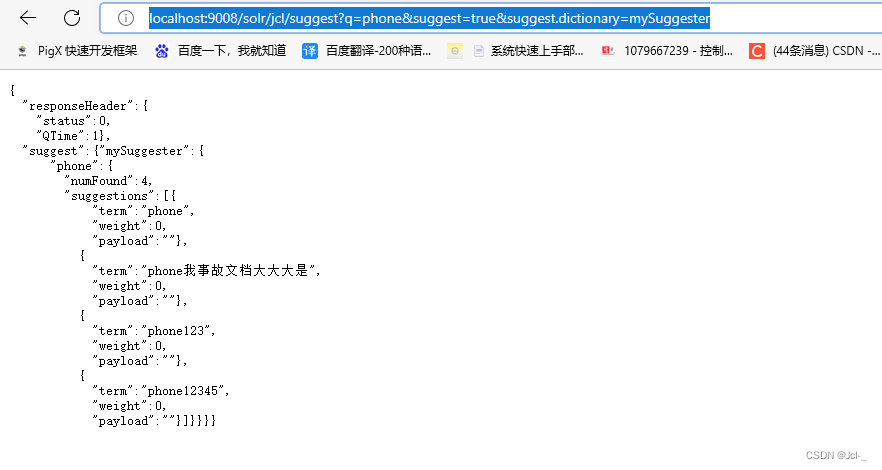
将自动建议组件配置到select请求处理器中
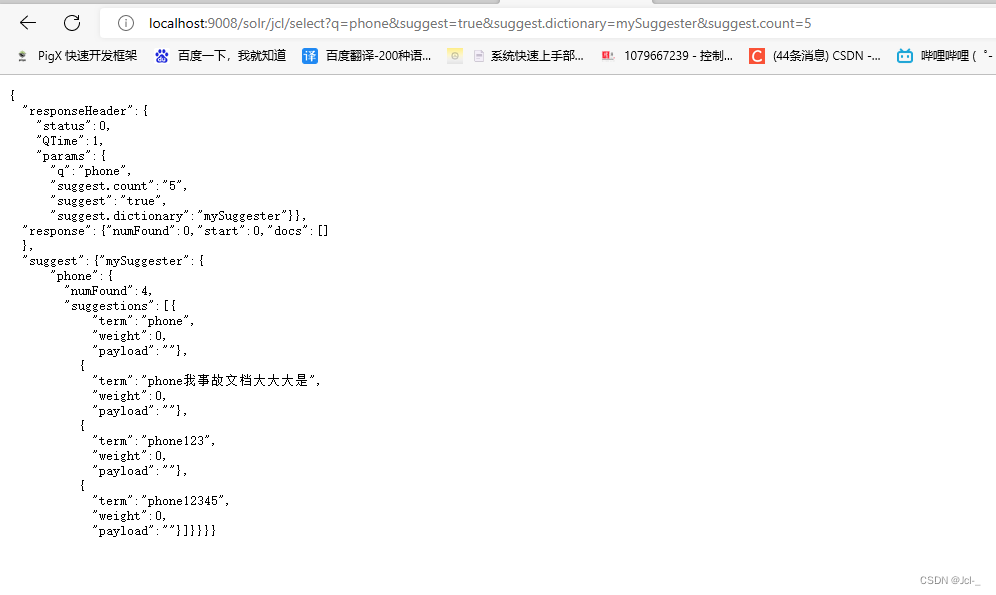
http://localhost:9008/solr/jcl/select?q=phone&suggest=true&suggest.dictionary=mySuggester&suggest.count=5
5.SolrJ(重要)
Solr官方推出的一套专门操作Solr的java的API,就叫做SolrJ
底层是HttpClient方法完成SolrJ
SolrJ核心的API:
1.SolrClient
2.HttpSolrClient:适合单节点情况与Solr进行交互
3.CloudSolrClient:适合集群的情况下与Solr进行交互
本文主要是关于HttpClient(因为没有集群,采用单节点的方式)
准备工作
导包(最好和自己的solr版本保持一致)
<!-- https://mvnrepository.com/artifact/org.apache.solr/solr-solrj -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.7.3</version>
</dependency>
在yml中配置SolrCore地址
url: http://localhost:9008/solr/jcl
启动类
@SpringBootApplication
public class SolrApplication {
public static void main(String[] args) {
SpringApplication.run(SolrApplication.class,args);
}
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
@Value("${url}")
private String url;
@Bean
public SolrClient creatHttpSolrClient(){
HttpSolrClient.Builder builder = new HttpSolrClient.Builder(url);
return builder.build();
}
}
5.3 HttpSolrClient
5.3.1 索引
5.3.1.1 添加
@Test
public void TestAdd() throws SolrServerException, IOException {
SolrInputDocument document = new SolrInputDocument();
document.setField("id","10086");
document.setField("big_oth_npp_report_flag","10086");
document.setField("big_oth_npp_report_create_time","2021-03-09T08:43:11Z");
solrClient.add(document);
solrClient.commit();
}
5.3.1.2修改
@Test
public void TestUpdate() throws SolrServerException, IOException {
SolrInputDocument document = new SolrInputDocument();
document.setField("id","10086");
document.setField("big_oth_npp_report_flag","10086");
document.setField("big_oth_npp_report_create_time","2021-03-09T08:43:11Z");
document.setField("big_oth_npp_report_crew_no","10086");
solrClient.add(document);
solrClient.commit();
}
5.3.1.3删除
/**
* 根据id删除文档
* @throws SolrServerException
* @throws IOException
*/
@Test
public void TestDeleteById() throws SolrServerException, IOException {
solrClient.deleteById("10086");
solrClient.commit();
}
/**
* 根据条件删除
* @throws SolrServerException
* @throws IOException
*/
@Test
public void TestDeleteByQuery() throws SolrServerException, IOException {
solrClient.deleteByQuery("id:10086");
solrClient.commit();
}
拼写检查和主动建议
/**
* 测试自动建议
* @throws IOException
* @throws SolrServerException
*/
@Test
public void testSuggest() throws IOException, SolrServerException {
SolrQuery solrQuery = new SolrQuery();
//设置参数
solrQuery.setQuery("phone");
//开启自动建议
solrQuery.set("suggest",true);
//指定自动建议的组件
solrQuery.set("suggest.dictionary","mySuggester");
solrQuery.set("suggest.count",5);
QueryResponse response = solrClient.query(solrQuery);
SuggesterResponse suggesterResponse = response.getSuggesterResponse();
Map<String, List<Suggestion>> suggestions = suggesterResponse.getSuggestions();
for (String key : suggestions.keySet()) {
//词
System.out.println(key);
List<Suggestion> suggestionList = suggestions.get(key);
for (Suggestion suggestion : suggestionList) {
String term = suggestion.getTerm();
System.out.println(term);
}
}
}
/**
* 查询big_oth_npp_report_theme中包含phona的内容。要求进行拼写检查。
* @throws SolrServerException
* @throws IOException
*/
@Test
public void testSpellCheck() throws SolrServerException, IOException {
SolrQuery solrQuery = new SolrQuery();
solrQuery.setQuery("big_oth_npp_report_theme:phona");
solrQuery.set("spellcheck",true);
QueryResponse response = solrClient.query(solrQuery);
//解析查询结果
SpellCheckResponse spellCheckResponse = response.getSpellCheckResponse();
Map<String, SpellCheckResponse.Suggestion> suggestionMap = spellCheckResponse.getSuggestionMap();
for (String key : suggestionMap.keySet()) {
System.out.println(key);
SpellCheckResponse.Suggestion suggestion = suggestionMap.get(key);
List<String> alternatives = suggestion.getAlternatives();
System.out.println(alternatives);
}
}
5.3.2 基本查询
5.3.2.1 主查询加过滤查询
@Test
public void TestQuery() throws SolrServerException, IOException {
SolrQuery solrQuery = new SolrQuery();
// solrQuery.set("q","id:10086");
solrQuery.setQuery("*:*");//与solrQuery.set("q","id:10086");等价
solrQuery.addFilterQuery("big_oth_npp_report_no:[0 TO 1}");
QueryResponse query = solrClient.query(solrQuery);
System.out.println("query:"+query);
SolrDocumentList results = query.getResults();
for (SolrDocument result : results) {
System.out.println("result"+result);
}
System.out.println("NumFound:"+results.getNumFound());
}
5.3.2.2 分页
solrQuery.setStart((1-1)*5);
solrQuery.setRows(5);
5.3.2.3 排序
solrQuery.addSort("big_oth_npp_report_is_delete",SolrQuery.ORDER.desc);
solrQuery.addSort("id",SolrQuery.ORDER.desc);
5.3.2.4 别名
solrQuery.setFields("id","no:big_oth_npp_report_no");
5.4 SolrJ实现拼写检查
需求:查询item_theme包含phone的内容,需要进行乒协检查
http://localhost:9008/solr/jcl/select?q=big_oth_npp_report_theme:phona&spellcheck=true
@Test
public void testSpellCheck() throws SolrServerException, IOException {
SolrQuery solrQuery = new SolrQuery();
solrQuery.setQuery("big_oth_npp_report_theme:phona");
solrQuery.set("spellcheck",true);
QueryResponse response = solrClient.query(solrQuery);
//解析查询结果
SpellCheckResponse spellCheckResponse = response.getSpellCheckResponse();
Map<String, SpellCheckResponse.Suggestion> suggestionMap = spellCheckResponse.getSuggestionMap();
for (String key : suggestionMap.keySet()) {
System.out.println(key);
SpellCheckResponse.Suggestion suggestion = suggestionMap.get(key);
List<String> alternatives = suggestion.getAlternatives();
System.out.println(alternatives);
}
}

5.5 SolrJ实现了拼写建议
http://localhost:9008/solr/jcl/select?q=phone&suggest=true&suggest.dictionary=mySuggester&suggest.count=5
@Test
public void testSuggest() throws IOException, SolrServerException {
SolrQuery solrQuery = new SolrQuery();
//设置参数
solrQuery.setQuery("phone");
//开启自动建议
solrQuery.set("suggest",true);
//指定自动建议的组件
solrQuery.set("suggest.dictionary","mySuggester");
solrQuery.set("suggest.count",5);
QueryResponse response = solrClient.query(solrQuery);
SuggesterResponse suggesterResponse = response.getSuggesterResponse();
Map<String, List<Suggestion>> suggestions = suggesterResponse.getSuggestions();
for (String key : suggestions.keySet()) {
//词
System.out.println(key);
List<Suggestion> suggestionList = suggestions.get(key);
for (Suggestion suggestion : suggestionList) {
String term = suggestion.getTerm();
System.out.println(term);
}
}
}

5.6 使用SolrJ完成Core的管理
5.6.1 Core的添加
复制一个Core文件,删除里面的properties文件

注入bean
@Value("${url}")
private String url;
@Bean
public SolrClient creatHttpSolrClient(){
HttpSolrClient.Builder builder = new HttpSolrClient.Builder(url);
return builder.build();
}
yml
url: http://localhost:9008/solr
/**
* 交换两个SolrCore
* @throws SolrServerException
* @throws IOException
*/
@Test
public void swapSolrCore() throws SolrServerException, IOException {
CoreAdminRequest.swapCore("jcl", "collection2", solrClient);
}
/**
* 删除Solr中的SolrCore,但是不删除硬盘中的,可以通过create再次创建
* @throws SolrServerException
* @throws IOException
*/
@Test
public void unloadSolrCore() throws SolrServerException, IOException {
CoreAdminRequest.unloadCore("collection2", solrClient );
}
/**
* 重命名SolrCore
* @throws SolrServerException
* @throws IOException
*/
@Test
public void renameSolrCore() throws SolrServerException, IOException {
CoreAdminRequest.renameCore("collection2","jcl2" , solrClient);
}
/**
* 重新从硬盘加载SolrCore到Solr中
* @throws SolrServerException
* @throws IOException
*/
@Test
public void reloadSolrCore() throws SolrServerException, IOException {
CoreAdminRequest.reloadCore("collection2", solrClient );
}
/**
* 添加SolrCore
* @throws SolrServerException
* @throws IOException
*/
@Test
public void createSolrCore() throws SolrServerException, IOException {
CoreAdminRequest.createCore("collection2","D:/environment/solr-7.7.3/solr_home/collection2",solrClient);
}
6.Spring Data Solr(开发)
pom
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.10.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
yml
spring:
data:
solr:
host: http://localhost:8080/solr
6.2 SolrTemplate
@Bean
public SolrTemplate solrTemplate(SolrClient solrClient) {
return new SolrTemplate(solrClient);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {
@Field
private Integer id;
@Field("name")
private String name;
}
6.2.1 索引(添加,按id删除,按条件删除,修改)
@Autowired
private SolrTemplate solrTemplate;
/**
* 测试按条件删除索引
* @throws IOException
* @throws SolrServerException
*/
@Test
public void testDeleteQuery() throws IOException, SolrServerException {
SolrDataQuery query = new SimpleQuery("*:*");
solrTemplate.delete("jcl",query);
solrClient.commit("jcl");
}
@Test
public void testSpringDataSolrDelete() throws IOException, SolrServerException {
solrTemplate.deleteByIds("jcl", "1");
solrClient.commit("jcl");
}
/**
* 测试使用spring-data-solr的saveBean()方法修改一个Solr索引
*/
@Test
public void testSpringDataSolrUpdate() {
User jcl1234 = new User(1,"jcl1234");
solrTemplate.saveBean("jcl",jcl1234);
solrTemplate.commit("jcl");
}
/**
* 测试使用spring-data-solr的saveBean()方法添加一个Solr索引
*/
@Test
public void testSpringDataSolrAdd() {
User jcl123 = new User(1,"jcl123");
solrTemplate.saveBean("jcl",jcl123);
solrTemplate.commit("jcl");
}
6.2.2 基本查询
6.2.2.1 主查询+过滤查询
/**
* 测试基本查询
* 结果:总记录数,总页数是1页,说明没有分页。虽然没有分页。但是他并没有把716条数据都查询出来,只查询了满足条件并且相关度高的前10个。
*/
@Test
public void testBaseQuery() {
Query solrQuery = new SimpleQuery("*:*");
// solrQuery.addFilterQuery(new SimpleQuery(new Criteria("name").is("jcl")));
// solrQuery.addFilterQuery(new SimpleQuery(new Criteria("price").greaterThanEqual(100)));//>=
// solrQuery.addFilterQuery(new SimpleQuery(new Criteria("price").lessThan(110)));//<
solrQuery.setOffset(11L);//设置从第几条开始查询
solrQuery.setRows(5);//设置每页有几行
//按照price降序,并且price相同时按照id升序
solrQuery.addSort(new Sort(Sort.Direction.DESC,"price"));
solrQuery.addSort(new Sort(Sort.Direction.ASC,"price"));
ScoredPage<User> userScoredPage = solrTemplate.queryForPage("jcl", solrQuery, User.class);
long totalElements = userScoredPage.getTotalElements();//获得文档数量
System.out.println(totalElements);
int totalPages = userScoredPage.getTotalPages();//总页数
System.out.println(totalPages);
List<User> content = userScoredPage.getContent();//获取第一页数据
for (User user : content) {
System.out.println(user);
}
}
6.2.2.2 拼写检查
/**
* 测试SpringDataSolr进行拼写检查
* @throws IOException
* @throws SolrServerException
*/
@Test
public void testSpringDataSolrSpellCheck() throws IOException, SolrServerException {
//查询item_title中包含iphonexX Galaxz的
SimpleQuery q = new SimpleQuery("name: phona");
q.setSpellcheckOptions(SpellcheckOptions.spellcheck().extendedResults());
SpellcheckedPage<User> page = solrTemplate.query("jcl",q, User.class);
long totalElements = page.getTotalElements();
if(totalElements == 0) {
Collection<SpellcheckQueryResult.Alternative> alternatives = page.getAlternatives();
for (SpellcheckQueryResult.Alternative alternative : alternatives) {
System.out.println(alternative.getTerm());
System.out.println(alternative.getSuggestion());
}
}
}














 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









