






金融风控训练营-Task01学习笔记
本学习笔记为阿里云天池龙珠计划金融风控训练营的学习内容,学习链接为:https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.20850282.J_3678908510.2.66604d57RXum1U&postId=170948
一、学习知识点概要
-
学习目的与赛题理解
-
数据概况与预测指标
-
代码示例实验
二、学习内容
1、学习目的与赛题理解
(1)Task01的学习目的主要是理解赛题数据和目标,清楚评分体系,熟悉赛题流程。
(2)赛题的任务是根据给定的数据集,建立相应的模型来预测金融风险。
2、数据概况与预测指标
2.1数据概况
比赛界面想对应的数据的概况介绍可以帮助我们理解和分析数据。
train.csv
- id 为贷款清单分配的唯一信用证标识
- loanAmnt 贷款金额
- term 贷款期限(year)
- interestRate 贷款利率
- installment 分期付款金额
- grade 贷款等级
- subGrade 贷款等级之子级
- employmentTitle 就业职称
- employmentLength 就业年限(年)
- homeOwnership 借款人在登记时提供的房屋所有权状况
- annualIncome 年收入
- verificationStatus 验证状态
- issueDate 贷款发放的月份
- purpose 借款人在贷款申请时的贷款用途类别
- postCode 借款人在贷款申请中提供的邮政编码的前3位数字
- regionCode 地区编码
- dti 债务收入比
- delinquency_2years 借款人过去2年信用档案中逾期30天以上的违约事件数
- ficoRangeLow 借款人在贷款发放时的fico所属的下限范围
- ficoRangeHigh 借款人在贷款发放时的fico所属的上限范围
- openAcc 借款人信用档案中未结信用额度的数量
- pubRec 贬损公共记录的数量
- pubRecBankruptcies 公开记录清除的数量
- revolBal 信贷周转余额合计
- revolUtil 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额
- totalAcc 借款人信用档案中当前的信用额度总数
- initialListStatus 贷款的初始列表状态
- applicationType 表明贷款是个人申请还是与两个共同借款人的联合申请
- earliesCreditLine 借款人最早报告的信用额度开立的月份
- title 借款人提供的贷款名称
- policyCode 公开可用的策略代码=1新产品不公开可用的策略代码=2
- n系列匿名特征 匿名特征n0-n14,为一些贷款人行为计数特征的处理
2.2预测指标
2.2.1分类算法常见的评估指标:
(1)混淆矩阵(Confuse Matrix)
- 若一个实例是正类,并且被预测为正类,即为真正类TP(True Positive)
- 若一个实例是正类,但是被预测为负类,即为假负类FN(False Negative)
- 若一个实例是负类,但是被预测为正类,即为假正类FP(False Positive)
- 若一个实例是负类,并且被预测为负类,即为真负类TN(True Negative)
demo实现:

(2)准确率(Accuracy)
常用的一个评价指标,但不适合样本不均衡的情况。
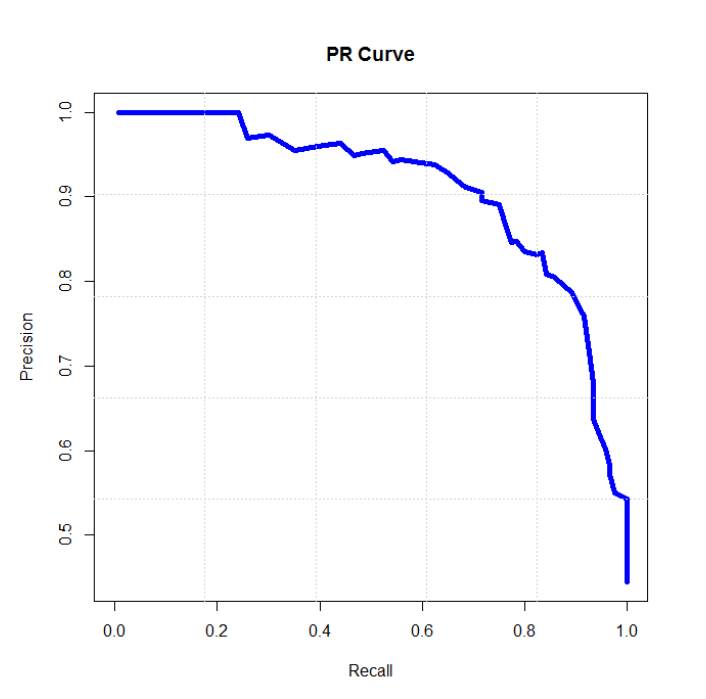
(3)P-R曲线(Precision-Recall Curve)
描述精确率和召回率变化的曲线
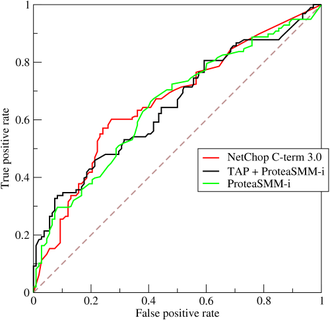
(4)ROC(Receiver Operating Characteristic)
TPR:在所有实际为正例的样本中,被正确地判断为正例之比率。
ROC空间将假正例率(FPR)定义为 X 轴,真正例率(TPR)定义为 Y 轴。
(5)AUC(Area Under Curve)
被定义为 ROC曲线 下与坐标轴围成的面积,面积的数值不大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。此次竞赛采用AUC作为评价指标。
2.2.2金融风控预测类常见的评估指标:
(1)ROC
(2)AUC
(3)KS(Kolmogorov-Smirnov)
在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力越强。但也并不是越强玥好,由下表可得知,KS在61%-75%之间为最佳。
| KS(%) | 好坏区分能力 |
|---|---|
| 20以下 | 不建议采用 |
| 20-40 | 较好 |
| 41-50 | 良好 |
| 51-60 | 很强 |
| 61-75 | 非常强 |
| 75以上 | 过于高,疑似存在问题 |
demo实现:

3、代码示例实验
利用Task01学习任务中的demo熟悉dsw的使用。




三、学习问题与解答
(1)最大是问题是需要一定的Python基础才能看懂代码写什么,自己写的时候才知道应该怎么用
(2)主要是不太了解上面所说的那些数据和指标,第一次看起来就是一头雾水,看不懂数据感觉无法理解自己应该在什么时候使用什么方法用到数据
四、学习思考与总结
这次的Task简单介绍了赛题的相关介绍,介绍了一些数据和指标,让我们熟悉熟悉赛程以及dsw的使用。第一次接触这类型的活动,希望自己能够坚持下去,有所收获。















 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









