







目录
在文章里展示全部的代码的话会非常影响文章的观看,有想要查看全部代码的朋友请到GitHub:https://github.com/aqaswrae/Some-small-crawler-projects
这个就是
想要收藏一下的,请点击一下右上角的小星星哦
谢谢大家

一.创建
首先要创建scrapy项目和爬虫文件,若有疑问,请看scrapy框架的基本使用这一篇文章
链接:Python爬虫-Scrapy框架的基本使用_瓦瓦卡卡的博客-CSDN博客
也是我写的, 🤭🤭
二.写代码
1.将roboots协议一脚踹飞
写代码的第一步:就是先更改roboots协议!!!
找到settings.py文件,将20行的roboots协议注释掉或者直接将其删除
![]()
2.在创建的爬虫文件中写爬虫的代码
我创建的爬虫文件名为 lianjia.py,所以就要在这个文件中写爬虫代码

3.代码
我这次爬取的是链家上的租房数据。https://qd.lianjia.com/zufang/
首先要想好要爬取哪些数据,并在items.py文件中做好数据建模。
class LianjiascrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()#名称
price = scrapy.Field()#价格
link = scrapy.Field()#对应房产数据的链接
scrapy框架内置了xpath语法,所以我们使用xpath语法来获取所需的数据
def parse(self, response):
#房产名称
names = response.xpath('//div[@class="content__list"]/div/a/@title').extract()
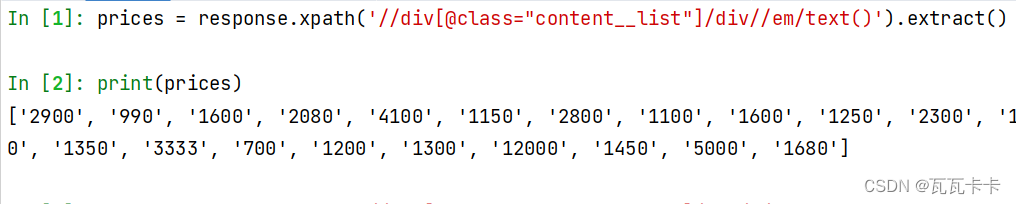
#价格
prices = response.xpath('//div[@class="content__list"]/div//em/text()').extract()
#链接
links = response.xpath('//div[@class="content__list"]/div/a/@href').extract()
#数据总页数total_page
total_page = response.xpath('//div[@class="content__pg"]/@data-totalpage').extract_first()
#当前是第几页
current_page = response.xpath('//div[@class="content__pg"]/@data-curpage').extract_first()
注意:获取数据时,不能单纯的使用xpath语法,要在语句的后边加上extract()才能获取到具体的数据,否则获取到的只是相应内容的对象。
要是觉得写一行获取数据的代码就运行一遍爬虫文件很麻烦的话,建议使用scrapy shell来调试程序,具体操作可以看一下这篇文章的 6.scrapy shell 的使用
Python爬虫-Scrapy框架的基本使用_瓦瓦卡卡的博客-CSDN博客
然后在爬虫文件中导入items.py文件中的类,用来实例化一个item对象,将获得的数据传给这个对象

给数据时,键名必须和数据建模时设置的字段名相同 ;要使用yield将数据返回,这是框架规定好了的,不能使用return,会中断循环
def parse(self, response):
names = response.xpath('//div[@class="content__list"]/div/a/@title').extract()
prices = response.xpath('//div[@class="content__list"]/div//em/text()').extract()
links = response.xpath('//div[@class="content__list"]/div/a/@href').extract()
total_page = response.xpath('//div[@class="content__pg"]/@data-totalpage').extract_first()#数据总页数total_page
current_page = response.xpath('//div[@class="content__pg"]/@data-curpage').extract_first()#当前是第几页
for name,price,link in zip(names,prices,links):
#导入item.py中的类,然后实例化一个对象,将获取的数据传给item,键名必须和字段名统一
item = LianjiascrapyItem()
item['name'] = name.strip()
item['price'] = price
item['link'] = response.urljoin(link)
# 将组建好的字典类型的数据通过yield返回给引擎,再由引擎返回给pipelines文件
yield item
在pipelines.py文件中接收传送过来的数据,将其转换成字典
如果要使打印或保存数据成功,要先将settings.py文件中的管道打开
ITEM_PIPELINES = {
"lianjiascrapy.pipelines.LianjiascrapyPipeline": 300,
}
这样就可以正常打印和保存数据了。在pipelines.py文件中

接下来我们将这些数据保存到json文件中
class LianjiascrapyPipeline:
def __init__(self):
self.file = open('zufang.json','w',encoding='utf-8')#打开json文件
def process_item(self, item, spider):
#返回的item是一个对象,我们要将其转换成字典
dict_item = dict(item)
json_data = json.dumps(dict_item,ensure_ascii=False) + ',\n'
self.file.write(json_data)
return item
def __del__(self):
self.file.close()这样我们的租房数据就保存完成了。
![]()

如果数据乱码的话,点击一下右上角提示中的’gbk‘,使用gbk编码打开。
4.翻页
当你去找页面最底下的下一页的超链接的时候,

在元素这个页面中会显示,但是我们要以返回的源码中的数据为准,源码中只有这么一行,是下一页这个a标签的父标签。

思路一:
获取父标签div中的data-totalPage(总页数)属性和data-curPage(当前页)属性,然后将url的前一部分https://qd.lianjia.com/zufang/pg与(当前页+1)拼接起来构成下一页完整的url
total_page = response.xpath('//div[@class="content__pg"]/@data-totalpage').extract_first()#数据总页数total_page
current_page = response.xpath('//div[@class="content__pg"]/@data-curpage').extract_first()#当前是第几页 
这个方法不能将第二个图片中的代码写在if判断语句中(我用来判断是否已经到了第100页),亲测,只能输出第二页完整的url。
我暂时还不知道原因,等我明白了再来写上。
同一天内,我找到原因了,获取到的total_page 和 current_page都是字符串类型的,进行if判断时要转换为int类型!!
完整的函数内容:
def parse(self, response):
names = response.xpath('//div[@class="content__list"]/div/a/@title').extract()
prices = response.xpath('//div[@class="content__list"]/div//em/text()').extract()
links = response.xpath('//div[@class="content__list"]/div/a/@href').extract()
total_page = response.xpath('//div[@class="content__pg"]/@data-totalpage').extract_first()#数据总页数total_page
current_page = response.xpath('//div[@class="content__pg"]/@data-curpage').extract_first()#当前是第几页
for name,price,link in zip(names,prices,links):
#导入item.py中的类,然后实例化一个对象,将获取的数据传给item,键名必须和字段名统一
item = LianjiascrapyItem()
item['name'] = name.strip()
item['price'] = price
item['link'] = response.urljoin(link)
# 将组建好的字典类型的数据通过yield返回给引擎,再由引擎返回给pipelines文件
yield item
#翻页。返回的网页源码中没有下一页的这个a标签,只有一个div标签,获取div标签的属性来进行翻页操作
# 将翻页的请求对象写在if语句下,运行时只会给第二页的url why???
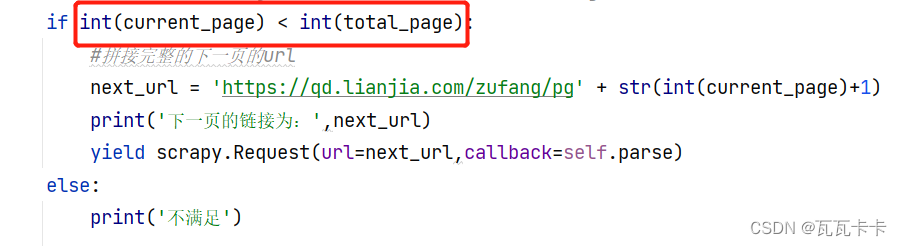
if int(current_page) < int(total_page):
#拼接完整的下一页的url
next_url = 'https://qd.lianjia.com/zufang/pg' + str(int(current_page)+1)
print('下一页的链接为:',next_url)
yield scrapy.Request(url=next_url,callback=self.parse)
else:
print('不满足')
思路二:
获取ul标签中的所有链接,然后循环构造请求对象,返回给引擎
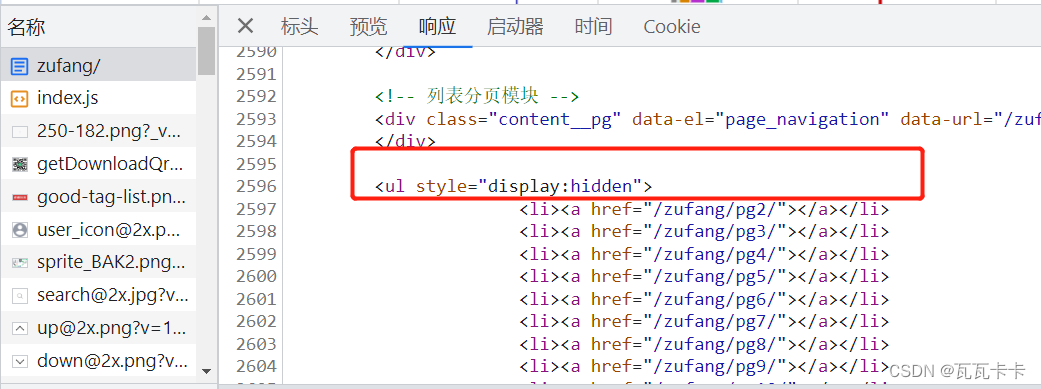
total_url = response.xpath('//div[@id="content"]//ul[2]/li/a/@href').extract()
for i in total_url:
l = 'https://qd.lianjia.com/zufang/' + i
yield scrapy.Request(url=next_url,callback=self.parse)














 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









