







目录
引言
这是我关于Google leveldb的第一篇源码解读系列,我不会对所有源码进行解读,但我尽量保证讲到的点都比较清楚(在精不在多嘛)。
leveldb中的Arena是一个简单的、一次性的内存池的实现,它不像《STL源码剖析》中的内存池那样复杂、容错性强,因为它主要用于Memtable这种不断增加空间、空间满了之后一并存入SST的场景,因此它也是不支持手动调用Delete操作,由析构函数一起调用。
成员变量
// Allocation state
char* alloc_ptr_;
size_t alloc_bytes_remaining_;
// Array of new[] allocated memory blocks
std::vector<char*> blocks_;
// Total memory usage of the arena.
std::atomic<size_t> memory_usage_;
Arena主体部分是一个std::vector<char*>,它用于管理所有分配的内存块。
alloc_ptr_和alloc_bytes_remaining_都是当前正在使用的内存块的状态变量,用于指明可用内存的起点和剩余空间。
memory_usage_则是一个原子变量,用于在高并发场景下统计总体内存使用大小。
除此之外,Arena没有任何其他多余的成员变量,因为它是一次性的,并且存在一定浪费的,这点我们在文章后面讨论。
于是Arena大概长这样:

啥?这图画的居然还一长一短的,并且使用到的内存块居然不是最后一块,为什么呢,我们继续往下看吧!
MemoryUsage
Arena提供三大接口:Allocate、AllocateAligned和MemoryUsage。
我们将从最简单的MemoryUsage讲起。
// Returns an estimate of the total memory usage of data allocated
// by the arena.
size_t MemoryUsage() const {
return memory_usage_.load(std::memory_order_relaxed);
}
由于没有deallocate操作,memory_usage_是只增不减的,增幅为block_bytes + sizeof(char*),其中sizeof(char*)被认为是vector中一个指针大小。
std::memory_order_relaxed只保证操作是原子的,但多核同步顺序是“relaxed”的,并不像std::memory_order_acquire和std::memory_order_release那样有更强的保证,感兴趣可以了解一下。
~Arena
// 需求:memtable不需要单次释放内存
Arena::~Arena() {
for (size_t i = 0; i < blocks_.size(); i++) {
delete[] blocks_[i];
}
}
析构函数也是很简单啦,挨个遍历释放即可。
Allocate
inline char* Arena::Allocate(size_t bytes) {
// The semantics of what to return are a bit messy if we allow
// 0-byte allocations, so we disallow them here (we don't need
// them for our internal use).
assert(bytes > 0);
if (bytes <= alloc_bytes_remaining_) {
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
return AllocateFallback(bytes);
}
Allocate用于不要求字节对齐的分配操作,如果当前内存块余量充足,直接分配,如果不够分配,调用内部的AllocateFallback函数进行分配。
AllocateFallback
char* Arena::AllocateFallback(size_t bytes) {
if (bytes > kBlockSize / 4) {
// Object is more than a quarter of our block size. Allocate it separately
// to avoid wasting too much space in leftover bytes.
char* result = AllocateNewBlock(bytes);
return result;
}
// We waste the remaining space in the current block.
// 浪费就浪费吧...
alloc_ptr_ = AllocateNewBlock(kBlockSize);
alloc_bytes_remaining_ = kBlockSize;
char* result = alloc_ptr_;
alloc_ptr_ += bytes;
alloc_bytes_remaining_ -= bytes;
return result;
}
先介绍代码中出现的一个常量kBlockSize:
kBlockSize默认是4096,也是大部分架构下页的大小,Arena使用它来作为基本的分配单位。
让我们回忆一下,当内存不足时,我们进入到AllocateFallback函数。试想有这么一种情况:当前内存块的余量其实挺充足的,但是用户要了一块很大的内存(大于这个余量),如果我们总是不分青红皂白的重新分配,在这种情况下产生的内部碎片是很大的。
于是leveldb在此处做了一个权衡,这个“很大的内存”被认为是kBlockSize / 4,当超过这个大小,说明并不是这个内存块余量不够充足,而是用户要的太多,那么此时就分配一个新块给用户(注意这个新块大小不是kBlockSize,而是用户要的大小),旧块继续用于此时小内存的分配。反之,说明确实是不够用了,分配一个kBlockSize重新使用。
这样,单个内存块产生的内存碎片最大不会超过kBlockSize / 4,其实我个人感觉也是挺大的,可能这就是Google大佬做的权衡吧。
其实此处还有一点是比较聪明的,试想一下,如果当不够分配时我们不考虑kBlockSize / 4,直接分配新块,当当前块余量真的很小了(比如说是1),这就失去了内存池的意义。
由于无论如何调用到的都是malloc出来的内存,所以AllocateFallback必然返回一个对齐的内存。
图中blocks_[3]对应的内存块就反映了这种情况。
AllocateNewBlock
char* Arena::AllocateNewBlock(size_t block_bytes) {
char* result = new char[block_bytes];
blocks_.push_back(result);
memory_usage_.fetch_add(block_bytes + sizeof(char*),
std::memory_order_relaxed);
return result;
}
AllocateNewBlock是一个private member function,当需要分配新空间时使用,原理也很简单。
我们应该注意的是,传入的block_bytes不一定是kBlockSize,也可能是一个大于kBlockSize / 4的bytes,因此在blocks_[3]对应的内存中,我画的相对短,不过大于 a quarter(四分之一)。
AllocateAligned
char* Arena::AllocateAligned(size_t bytes) {
const int align = (sizeof(void*) > 8) ? sizeof(void*) : 8;
// 静态断言:判断是否是2的n次方(只有一个1存在)
static_assert((align & (align - 1)) == 0,
"Pointer size should be a power of 2");
size_t current_mod = reinterpret_cast<uintptr_t>(alloc_ptr_) & (align - 1);
// slop:溢出
size_t slop = (current_mod == 0 ? 0 : align - current_mod);
size_t needed = bytes + slop;
char* result;
if (needed <= alloc_bytes_remaining_) {
result = alloc_ptr_ + slop;
alloc_ptr_ += needed;
alloc_bytes_remaining_ -= needed;
} else {
// AllocateFallback always returned aligned memory
result = AllocateFallback(bytes);
}
assert((reinterpret_cast<uintptr_t>(result) & (align - 1)) == 0);
return result;
}
重点来了,由于AllocateAligned被用于字节对齐,所有我们先讨论一下它。
浅谈字节对齐
字节对齐不仅保证了CPU访存效率,对于特定的平台,对齐是基本要求(否则出错)。
如注释所言,标库的malloc保证了返回的地址是自动对齐的,因为标准库并不知道这个地址的用途,所以尽量保证我们在强转时的正确性。当然,保证对齐也会产生一定的内部碎片,感兴趣可以阅读malloc分配内存进行对齐的操作的代码来简单了解,不过这篇博客并不是很全,建议大家着重阅读那句:
int offset = alignment - 1 + sizeof(void*);
内存碎片实际上在此处产生。
(align & (align - 1)) == 0
这里用到一个位运算魔法,用于判断align是不是2的次方。
2的次方有个特点,转成补码是只有一个1的,而align & (align - 1)可以帮我们快速消除最低位的1,还是很有意思的。
此外,它使用了static_assert,在编译时进行检查(align也是一个在编译期就能确定的值,因此不会报错),不会对运行产生开销。
(alloc_ptr_) & (align - 1)
这套位运算其实是求余操作的快速实现,效率相较于运算符%是比较高的。其中align - 1相当于一个掩码,与运算后就得到余数了。
AllocateAligned逻辑
有了这些前置知识,我们再来讨论函数的具体逻辑。
由于考虑到对齐,我们需要计算出实际需要多少字节,代码中变量为needed:
size_t needed = bytes + slop;
而slop实际是需要补齐的字节,它由align - current_mod得到:
size_t slop = (current_mod == 0 ? 0 : align - current_mod);
current_mod就是用到位运算求得的余数(对alloc_ptr_求得的):
size_t current_mod = reinterpret_cast<uintptr_t>(alloc_ptr_) & (align - 1);
与Allocate类似,余量充足,则直接返回,不足则调用AllocateFallback,上面介绍过AllocateFallback一定返回对齐的地址。
听起来有点抽象,我们还是画张图看看。
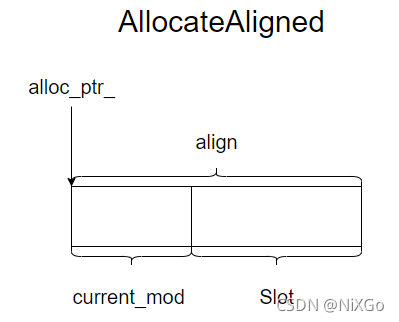
Arena的优缺点
- 优点:
- 一定程序避免了cookie,当然这也是内存池基本上都会有的优点。
- 因为简单,所以速度快。
- 缺点:
- 上面提到过,会产生一定的内部碎片,目前见过比较好的实现其实就是侯捷老师着重点出的那个,写项目用上的话我觉得也是一个加分项。
- 使用场景少,毕竟不提供deallocate操作。
- 不当的访存可能带来灾难,访问动态分配出来的内存,系统是不会产生诸如segment fault之类的错误的,因此在Arena内,正确的使用获取到的内存是程序员的责任。
相关代码
util/arena.h
util/arena.cc
我个人的注释版本(不定期更新)















 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









