






 文章讨论了在使用Calcite解析SQL语句后,遇到中文乱码的问题。问题出在`SqlNode.toSqlString()`方法上,该方法在处理非ASCII字符时将其转换为十六进制表示。解决方案包括1)对查询条件进行关键字替换,尤其是String类型的条件,以及2)使用正则表达式反解字符串。文中给出了具体的正则表达式和反解代码示例。
文章讨论了在使用Calcite解析SQL语句后,遇到中文乱码的问题。问题出在`SqlNode.toSqlString()`方法上,该方法在处理非ASCII字符时将其转换为十六进制表示。解决方案包括1)对查询条件进行关键字替换,尤其是String类型的条件,以及2)使用正则表达式反解字符串。文中给出了具体的正则表达式和反解代码示例。
在使用calcite解析sql语句后,最终想要得到sql字符串时,调用SqlNode.toSqlString(),会将中文解析为乱码。是因为在解析的时候调用了以下方法:
public void quoteStringLiteralUnicode(StringBuilder buf, String val) {
buf.append("u&'");
for (int i = 0; i < val.length(); i++) {
char c = val.charAt(i);
if (c < 32 || c >= 128) {
buf.append('\\');
buf.append(HEXITS[(c >> 12) & 0xf]);
buf.append(HEXITS[(c >> 8) & 0xf]);
buf.append(HEXITS[(c >> 4) & 0xf]);
buf.append(HEXITS[c & 0xf]);
} else if (c == '\'' || c == '\\') {
buf.append(c);
buf.append(c);
} else {
buf.append(c);
}
}
buf.append("'");
}
目前我所使用的calcite1.34.0版本中没有找到设置编码格式的api,解决的办法有两种:
1、采用关键字替换的方式,一般sql中出现乱码都是查询条件中包含中文,此时可以对查询条件进行校验,如果查询条件对应的是String类型,就将其替换成其它字符串(类似预编译中的问号),
2、根据以上方法反解回去,上面的方法很好理解,首先在解析的字符串前后用u&''包住,对于ascii码值小于32或者大于等于128的字符,将其解析为4位十六进制数,并在前面加上反斜杠。其余基本不变。根据以上规则可以得出正则表达式
String regex = "u&'(.*)(\\\\[\\da-f]{4})+(.*)'";
\\\\是用于匹配反斜杠的。在解析时需要注意的是不能将单引号忽略,因为出现乱码的基本都是字符串,在解析时,我们也需要使用''将字符串包住。
public static void main(String[] args) {
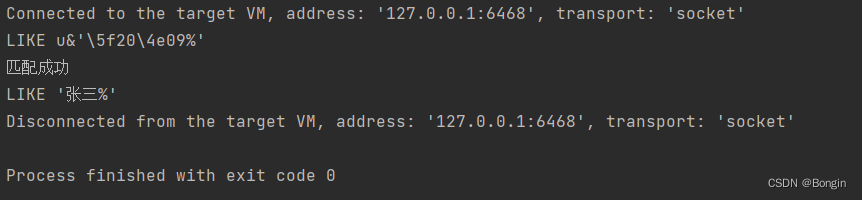
String s = "LIKE u&'\\5f20\\4e09%'";
System.out.println(s);
String regex = "u&'(.*)(\\\\[\\da-f]{4})+(.*)'";
Pattern pattern = Pattern.compile(regex);
Matcher m1 = pattern.matcher(s);
while(m1.find()) {
System.out.println("匹配成功");
StringBuilder builder = new StringBuilder();
builder.append("'");
String group = m1.group();
String temp = group.substring(0,group.length()-1).substring(3);
for(int i = 0;i < temp.length();i ++) {
char c = temp.charAt(i);
if(c == '\\') {
builder.append((char)Integer.parseInt(temp.substring(i + 1,i + 5),16));
i += 4;
} else {
builder.append(c);
}
}
builder.append("'");
s = s.replace(group,builder.toString());
System.out.println(s);
}

















 112
112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









