







一、思想
- 前端:a标签+静态文件
<a href="{% url 'down' %}">下载</a>
- 后端:响应头(django实现文件下载,下文均为django views端实现)
二、使用FileResponse
2.1 代码实例
from django.http import FileResponse
def file_down(request):
file = open(os.path.abspath(os.path.dirname(os.path.dirname(__file__)))+ '/history/vulnscan/vulnscan.pdf', 'rb') # 下载当前目录的上一级目录下的history/vulnscan目录下的vulnscan.pdf文件
response =FileResponse(file)
response['Content-Type']='application/octet-stream'
response['Content-Disposition']='attachment;filename="example.tar.gz"'
return response
假设我当前项目主目录:
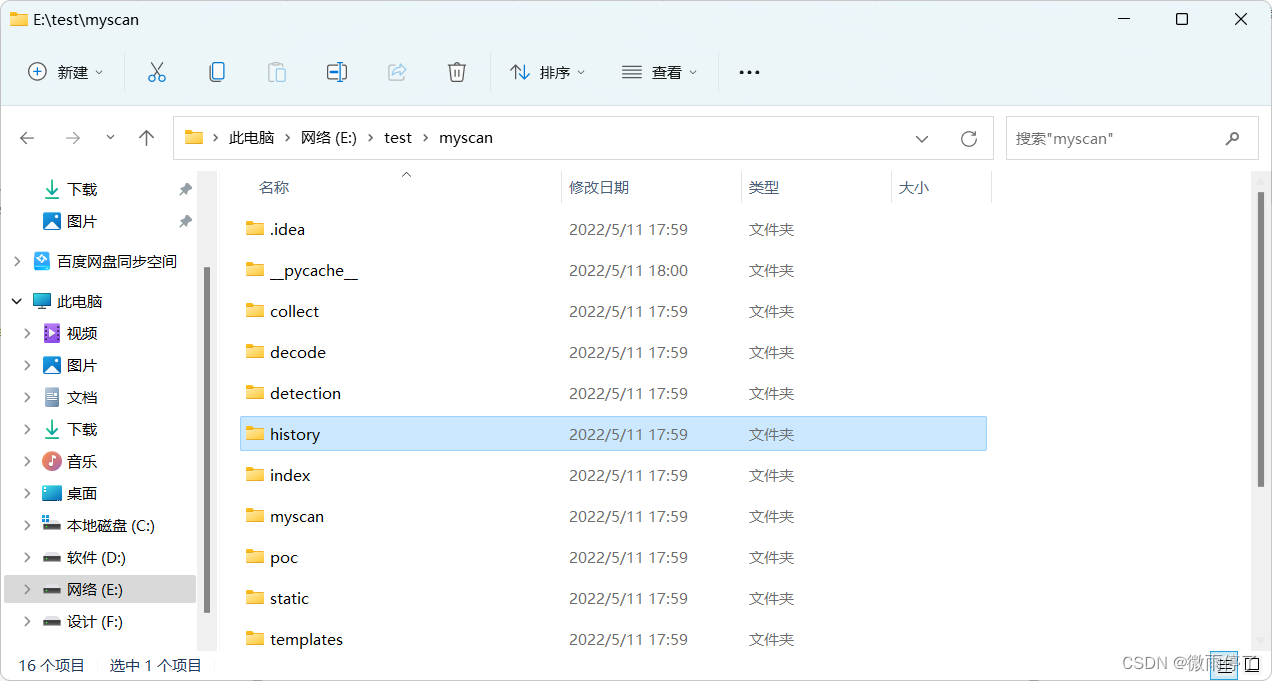
我需下载的文件在:
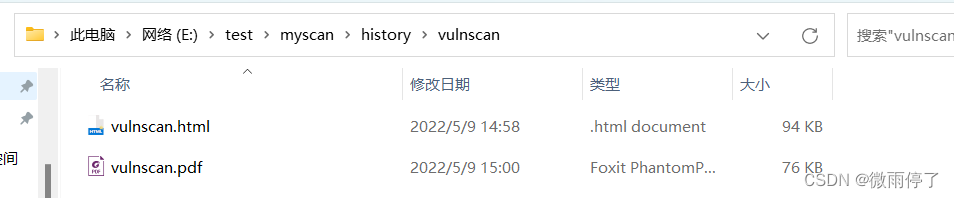
python获取当前工作目录:
p1 = os.path.abspath(os.path.dirname(__file__)) # 获取当前目录
p2 = os.path.abspath(os.path.dirname(os.path.dirname(__file__))) # 获取上级目录
执行下载:
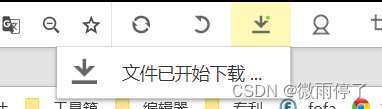
2.2 结合之前
结合我之前文章 python调AWVS接口 新建扫描并导出扫描报告,将下载扫描报告的功能重写到django的views视图中,使用FileResponse方法实现“真正的下载”。
思想:
1、下载入口,当点击html按钮时,触发一系列活动;

2、下载的响应来到后端,服务器先请求AWVS api,再次请求返回的报告地址;
rr = requests.get(url=down_url,headers=self.auth_headers,verify=False)
3、将返回的报告内容写入空文件,生成服务端的报告。每次下载时对旧报告进行覆盖;
path = './history/vulnscan/'
if not os.path.exists(path): # 判断当前路径是否存在,没有则创建new文件夹
os.makedirs(path)
txt = open(path + 'vulnscan.html', 'wb')
txt.write(rr.content) # 写入文件
txt.close()
4、这时服务端总存一份新报告,通过Django再次请求刚写入的本地文件,利Django的FileResponse方法将文件形成流数据,并将响应信息返回给前端,实现下载;
5、验证,可得客户端下载成功。

三、使用HttpResponse
from django.shortcuts import HttpResponse
def file_down(request):
file=open('/home/amarsoft/download/example.tar.gz','rb')
response =HttpResponse(file)
response['Content-Type']='application/octet-stream'
response['Content-Disposition']='attachment;filename="example.tar.gz"'
return response
四、使用StreamingHttpResponse
from django.http import StreamingHttpResponse
def file_down(request):
file=open('/home/amarsoft/download/example.tar.gz','rb')
response =StreamingHttpResponse(file)
response['Content-Type']='application/octet-stream'
response['Content-Disposition']='attachment;filename="example.tar.gz"'
return response
五、Reference
Django 如何实现文件下载: https://www.cnblogs.com/supery007/p/8146035.html















 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











