






高光谱数据集更换处理
一:test文件查看数据标签
import scipy.io as scio
data = scio.loadmat('XX.mat')
label = scio.loadmat('XX_gt.mat')
print(data)
print(label)
在这里以PaviaU大学数据为例,可以看到数据烈类型为:


即表明数据标签为paviaU和paviaU_gt。
data = scio.loadmat('paviaU.mat')['paviaU']
print(data)
print(data.shape)
label = scio.loadmat('paviaU_gt.mat')['paviaU_gt'].reshape(-1).astype(int)
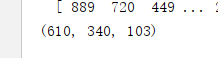
这里把数据维度即103提取出来,最终test文件代码如下:
import scipy.io as scio
data = scio.loadmat('paviaU.mat')['paviaU'].reshape((-1, 103)).astype(int)
'''print(data)
print(data.shape)
'''
label = scio.loadmat('paviaU_gt.mat')['paviaU_gt'].reshape(-1).astype(int)
'''
print(data)
print(label)
'''
二:CNN文件
import torch.nn as nn
import torch
import numpy as np
class Hyperspectral_CNN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=16, kernel_size=4), nn.BatchNorm1d(16), nn.ReLU(),
nn.Conv1d(in_channels=16, out_channels=16, kernel_size=4), nn.BatchNorm1d(16), nn.ReLU(),
)
self.pool1 = nn.MaxPool1d(2)
self.conv2 = nn.Sequential(
nn.Conv1d(in_channels=16, out_channels=32, kernel_size=4), nn.BatchNorm1d(32), nn.ReLU(),
nn.Conv1d(in_channels=32, out_channels=32, kernel_size=4), nn.BatchNorm1d(32), nn.ReLU(),
)
self.pool2 = nn.MaxPool1d(2)
self.conv3 = nn.Sequential(
nn.Conv1d(in_channels=32, out_channels=64, kernel_size=4), nn.BatchNorm1d(64), nn.ReLU(),
nn.Conv1d(in_channels=64, out_channels=64, kernel_size=4), nn.BatchNorm1d(64), nn.ReLU(),
)
self.pool3 = nn.MaxPool1d(2)
self.conv4 = nn.Sequential(
nn.Conv1d(in_channels=64, out_channels=128, kernel_size=4), nn.BatchNorm1d(128), nn.ReLU(),
nn.Conv1d(in_channels=128, out_channels=128, kernel_size=4), nn.BatchNorm1d(128), nn.ReLU(),
)
self.fc1 = nn.Linear(**XX**, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
out = x
out = self.pool1(self.conv1(out))
out = self.pool2(self.conv2(out))
out = self.pool3(self.conv3(out))
out = self.conv4(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.fc2(out)
return out
def feature(self, x):
x = torch.tensor(np.reshape(x, (1, 1, len(x))), dtype=torch.float32)
out = self.pool1(self.conv1(x))
out = self.pool2(self.conv2(out))
out = self.pool3(self.conv3(out))
out = self.conv4(out)
return out.view(-1)
'''import torch
a=torch.ones((16,1,103))
Hyperspectral_CNN(10)(a)
'''
将下面三行运将下面三行运行,并在 out = self.fc1(out)处Degbug截至,可以看到全连接层输入维度为128:
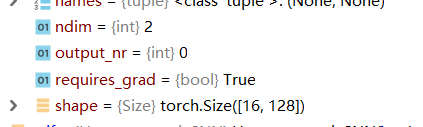
之后在self.fc1 = nn.Linear(**XX**, 128)里面的XX改为128即可。
三、Main函数与dataset函数
之后要做的,就是在主函数与dataset函数里面替换掉地址。
#dataset函数
import torch
import numpy as np
from torch.utils.data import Dataset
class DataSet(Dataset):
def __init__(self, normal_path, defect_path):
super().__init__()
normal = np.loadtxt(normal_path, delimiter=',')
min = np.min(normal, axis=1, keepdims=True)
normal -= min
normal_labels = np.ones(normal.shape[0])
defect = np.loadtxt(defect_path, delimiter=',')
min = np.min(defect, axis=1, keepdims=True)
defect -= min
defect_labels = np.zeros(defect.shape[0])
self.data = np.concatenate((normal, defect), axis=0)
self.label = np.concatenate((normal_labels, defect_labels), axis=0)
def __len__(self):
return self.data.shape[0]
def __getitem__(self, item):
return torch.tensor(np.expand_dims(self.data[item], axis=0), dtype=torch.float32), torch.tensor(
self.label[item], dtype=torch.long)
import os
class CS_DataSet(Dataset):
def __init__(self, path):
super().__init__()
normal = None
for fn in os.listdir(os.path.join(path, '正常')):
data = np.loadtxt(os.path.join(path, '正常', fn), delimiter=',')
if normal is None:
normal = data
else:
normal = np.vstack((normal, data))
normal_labels = np.ones(normal.shape[0])
defect = None
for fn in os.listdir(os.path.join(path, '缺陷')):
data = np.loadtxt(os.path.join(path, '缺陷', fn), delimiter=',')
if defect is None:
defect = data
else:
defect = np.vstack((defect, data))
defect_labels = np.zeros(defect.shape[0])
self.data = np.vstack((normal, defect))
self.labels = np.hstack((normal_labels, defect_labels))
permutation = np.random.permutation(self.data.shape[0]) # 记下第一维度的打乱顺序
self.data = self.data[permutation, :]
self.labels = self.labels[permutation]
def __len__(self):
return self.data.shape[0]
def __getitem__(self, item):
return torch.tensor(np.expand_dims(self.data[item], axis=0), dtype=torch.float32), torch.tensor(
self.labels[item], dtype=torch.long)
import scipy.io as scio
class Hyperspectral_DataSet(Dataset):
def __init__(self, data_path,label_path):
super().__init__()
self.data=scio.loadmat(data_path)['paviaU'].reshape((-1,103)).astype(int)
self.labels=scio.loadmat(label_path)['paviaU_gt'].flatten().astype(int)
permutation = np.random.permutation(self.data.shape[0])
self.data = self.data[permutation, :]
self.labels = self.labels[permutation]
def __len__(self):
return self.data.shape[0]
def __getitem__(self, item):
return torch.tensor(np.expand_dims(self.data[item], axis=0), dtype=torch.float32), torch.tensor(
self.labels[item], dtype=torch.long)
#主函数
import argparse
import logging
import os
from matplotlib import pyplot as plt
import random
import time
import numpy as np
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
# from data.signal_data import get_signal
from modle.cnn import *#是把一个模块中所有函数都导入进来;
from utils.misc import AverageMeter, accuracy, save_checkpoint # , #plot_confusion_matrix
from data.dataset import DataSet, CS_DataSet, Hyperspectral_DataSet
best_acc = 0 # acc是指模型训练精度
train_loss = [] # loss是训练的的损失值
test_loss = []
train_acc = []
test_acc = []
device =torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
def main():
global best_acc
model = Hyperspectral_CNN(num_classes=17) # 17种分类类别
model=model.to(device)#指定了设备之后,就需要将模型加载到相应设备中,此时需要使用model=model.to(device),将模型加载到相应的设备中。
criterion = nn.CrossEntropyLoss() # PyTorch损失函数之交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.0001) # 学习率0.0001
BATCH_SIZE = 128 # 一个包128个样本
EPOCH = 10 # 循环次数
train_db = Hyperspectral_DataSet('./hyperspectral-files/PaviaU.mat',
'./hyperspectral-files/PaviaU_gt.mat')
# 用来划分 validation的主要作用是来验证是否过拟合、以及用来调节训练参数等。 val-验证集
train_db, val_db = torch.utils.data.random_split(train_db, [int(len(train_db) * 0.8), int(len(train_db) * 0.2)]) # 用来划分
train_loader = DataLoader(train_db, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(val_db, batch_size=BATCH_SIZE)
for epoch in range(EPOCH):# EPOCH = 200 # 循环次数
model.train()#model.train()是保证BN(批量归一化)层能够用到每一批数据的均值和方差。
count = 0.
all = 0
total_loss = 0.
# enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
for batch_idx, (input, target) in enumerate(train_loader): #enumerate在字典上是枚举、列举的意思
all += input.shape[0]#input.shape图像的垂直尺寸(高度)
input=input.to(device)
target=target.to(device)
output = model(input)
loss = criterion(output, target)
output = torch.argmax(output, 1) # 我们想要求每一行最大的列标号
count += (output == target).sum()
total_loss += loss.cpu().item() # loss.cpu().item() 把数值取出来
optimizer.zero_grad() # 先将梯度归零(
loss.backward() # 反向传播计算得到每个参数的梯度值
optimizer.step() # 通过梯度下降执行一步参数更新
train_loss.append(total_loss )
train_acc.append(count / all)
print('train_acc:',count/all)
model.eval()
count = 0.
all = 0
loss = 0.0
with torch.no_grad():
for (input, target) in test_loader:
all += input.shape[0]
input=input.to(device)
target=target.to(device)
out = model(input)
loss += criterion(out, target)
out = torch.argmax(out, 1)
count += (out == target).sum()
acc = count / all
print('test_acc:',acc)
test_loss.append(loss)
test_acc.append(acc)
if acc > best_acc:
best_acc = acc
torch.save(model.state_dict(), './hyperspectral-checkpoints/best-{}.pth'.format(best_acc))
fig, ax = plt.subplots(1, 2)
ax[0].plot(range(EPOCH), train_loss, label='train_loss')
ax[0].plot(range(EPOCH), test_loss, label='test_loss')
ax[0].legend()
ax[1].plot(range(EPOCH), train_acc, label='train_acc')
ax[1].plot(range(EPOCH), test_acc, label='test_acc')
ax[1].legend() #设置图例
plt.savefig('./result.png')
if __name__ == '__main__':
main()















 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









