







一、logistic回归模型简介
虽然logistic回归听上去是用来执行回归任务的,但实际上这是一种分类算法,被广泛用于估算一个实例属于某个特定类别的概率,根据概率大小来进行类别判定;如当判断今年自己是否能过六级时,就要把能过的概率和不能过的概率进行比较,如能过的概率是56%,不能过的概率是54%,显然能过的概率大于不能过的概率,所以我们判断今年自己可以过六级(虽然我六级已经过了2333);
那么我们怎么具体来求能过六级的概率呢,这里就要用到我们之前所学的线性回归和这里的logistic回归了;首先我们列举出影响我们过六级的因素(即属性
x
i
x_i
xi),可能有词汇量,背的作文数量,考试当天的状态等等,然后对它们进行权重判断,即哪些因素时比较重要的,哪些因素相对来说不是很重要的(即
θ
i
\theta_i
θi)。这样我们就可以很自然想到线性回归中的多元回归,借助多元回归模型我们可以将我们的综合英语水平转换成一个值,这个值可能是0到任意一个值;但是我们知道概率是[0,1]的数,怎么将我们求出的值转换成0~1呢,这里就要借助logistic回归中的sigmoid函数了:

sigmoid函数是一种能将任意值映射到0~1的函数,由图也容易看出输入值越大,输出值越接近1,输入值越小,越接近0;
σ
(
z
)
=
1
1
+
e
−
z
\sigma\left( z \right) =\frac{1}{1+e^{-z}}
σ(z)=1+e−z1
def sigmoid(z):
return 1/(1 + np.exp(-z))
这样我们就可以得到logistic回归模型的概率估计:
p
=
h
θ
(
x
)
=
σ
(
x
T
θ
)
=
1
1
+
e
−
x
T
θ
p=h_{\theta}\left( x \right) =\sigma \left( x^T\theta \right) =\frac{1}{1+e^{-x^T\theta}}
p=hθ(x)=σ(xTθ)=1+e−xTθ1
最后模型预测:
y
=
{
1
,
i
f
p
⩾
0.5
0
,
i
f
p
<
0.5
y=\left\{ _{1, if\,\,p\,\,\geqslant \,\,0.5}^{0, if\,\,p\,\,<\,\,0.5} \right.
y={1,ifp⩾0.50,ifp<0.5
即如果
x
T
θ
x^T\theta
xTθ为正类,p的值应不小于0.5,模型预测结果为1;若为负类,p的值应小于0.5,预测结果为0;
二、logistic回归分类实现
1.模型性能评估指标
首先我们先来确定怎样衡量一个分类模型的好坏;在线性回归模型中,我们可以用
R
2
R^2
R2来确定模型的性能,甚至还可以通过画图的方法来直观观察我们创建的模型的预测效果;
而在分类中,如果影响分类的属性
x
i
x_i
xi只有一个或者两个的话我们确实也可以通过画图,构造决策边界来判断我们模型的分类效果,但是当属性过多时,就难以通过画图来直观反映出我们的分类结果;
好在在分类中,模型的其他评估标准有很多,具体如下:
(1)k折交叉验证求精度
精度:分类正确的样本数占样本总数的比例;
通过交叉验证,我们可以充分利用数据集,在有限的数据量下提高模型的准确性;在这里,我们暂且用精度来粗略地表示模型的分类效果;即训练出模型后,将原本的样本属性值传给该模型,使该模型预测出相应的结果,再把该结果与正确标签进行比较,得到预测正确的比例,即为我们模型的精度,但是这样做比较片面,无法全面反映模型的分类能力;
自行实现交叉验证:
#3折交叉验证
import numpy as np
from sklearn.model_selection import StratifiedKFold # 分层抽样
from sklearn.linear_model import SGDClassifier
file1 = "classification_train.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int)
skfolds = StratifiedKFold(n_splits=3, random_state=42) # 3折交叉验证,选定的模型种子是42
for train_index, test_index in skfolds.split(data_x, data_y): # 随机选取训练集和测试集索引
cla = SGDClassifier(random_state=42) # 创建随机梯度下降模型
datax_folds = data_x[train_index]
datay_folds = data_y[train_index]
testx_folds = data_x[test_index]
testy_folds = data_y[test_index]
cla.fit(datax_folds, datay_folds) # 训练模型
y_pred = cla.predict(testx_folds) # 通过训练集训练的模型根据测试集数据预测数据
correct_score = sum(y_pred == testy_folds) / len(y_pred) # 预测正确的占比
print(correct_score)
调用sklearn模块中的交叉验证函数:
# 调用sklearn模块中的交叉验证函数
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import SGDClassifier
import numpy as np
file1 = "classification_train.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int)
cla = SGDClassifier(random_state=23)#创建模型,random_state类似随机种子,若其固定则模型也固定
cla.fit(data_x, data_y)
correct_score = cross_val_score(cla, data_x, data_y, cv=3, scoring="accuracy")#准度即分类正确的占比
print(correct_score)
(2)混淆矩阵,精度,召回率和F1
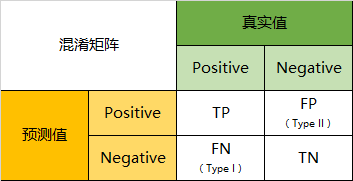
分类模型的预测结果只可能为四类:
真正类:实际为正类,预测为正类;
假正类:实际为负类,预测为正类;
真负类:实际为负类,预测为负类;
假负类:实际为正类,预测为负类;
混淆矩阵就是这四种类型数量的组合,在其中,TP为真正类,FP为假正类,FN为假负类,TN为真负类;
精度:分类正确的样本数占样本总数的比例,精度 = TP / (TP + FP);
召回率:分类器正确检测到的正类实例的比例,召回率 = TP / ( TP + FN);
F1:综合精度和召回率,组合成一个单一指标即F1,F1 = 2 / (1 / 精度 + 1 / 召回率) = TP / (TP + (FN + FP) / 2);
混淆矩阵,精度,召回率,F1的实现:
可以用提供的模块,也可以先求出混淆矩阵后根据公式求;
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
from sklearn.linear_model import SGDClassifier
import numpy as np
file1 = "classification_train.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int)
cla = SGDClassifier(random_state=23)
pred_y = cross_val_predict(cla, data_x, data_y, cv=3)
print("混淆矩阵:")
print(confusion_matrix(data_y, pred_y))#混淆矩阵
confusion_mat = confusion_matrix(data_y, pred_y)
precisionScore = confusion_mat[1, 1] / (confusion_mat[1, 1] + confusion_mat[0, 1]) #精度
# print(precision_score(datay, pred_y)) #精度
recallScore = confusion_mat[1, 1] / (confusion_mat[1, 1] + confusion_mat[1, 0])
# print(recall_score(datay, pred_y)) #召回率
f1Score = 2 * precisionScore * recallScore / (precisionScore + recallScore)
# print(f1_score(datay, pred_y)) #F1
print("精度 召回率 和 F1:", precisionScore, recallScore, f1Score)
不同问题针对精度和召回率的要求不同,需要具体问题具体分析,如“宁可错杀一千,不可放过一个”就是重视召回率;而“宁缺毋滥”的思想就更重视精度;通常来说很难同时兼顾精度和召回率,一方高,另一方一般就比较低,即无法“鱼和熊掌兼得”;
(3)精度与召回率权衡
我们称之前p不小于0.5的为正类中的0.5为阈值;对样例,当我们计算的p值大于阈值时,称为正类,否则为负类;显然,当我们增大阈值时,我们分类模型的精度会提高,召回率会下降;而减少阈值时,召回率会提高,精度会下降;
我们可以根据阈值画出精度和召回率的变化曲线:
精度-召回率曲线
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import precision_recall_curve
from matplotlib import pyplot as plt
from sklearn.linear_model import SGDClassifier
import numpy as np
file1 = "classification_train.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int)
cla = SGDClassifier(random_state=23)
y_scores = cross_val_predict(cla, data_x, data_y, cv=3, method="decision_function")#返回决策分数,即预测数据的准确程度
precisions, recalls, thresholds = precision_recall_curve(data_y, y_scores)#精度,召回率,阈值
def precision_vs_recall(precisions, recalls, thresholds):
plt.figure(figsize=(10, 5), dpi=80)
plt.plot(thresholds, precisions[:-1], "--", label="precision", color="blue")
plt.plot(thresholds, recalls[:-1], "-", label="recall", color="red")
plt.xlabel("thresholds")
plt.grid()
plt.legend(loc='upper right')
plt.show()
precision_vs_recall(precisions, recalls, thresholds)

(4)ROC曲线
受试者工作特征曲线与精度/召回曲线很类似,是刻画真正类率(即召回率)与假正类率(被错误分为正类的负类实例比例)关系的一种曲线,也可以用来评价分类模型性能
from sklearn.metrics import roc_auc_score
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import roc_curve
from matplotlib import pyplot as plt
import numpy as np
file1 = "classification_train.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int)
cla = SGDClassifier(random_state=23)
y_scores = cross_val_predict(cla, data_x, data_y,cv=3, method="decision_function")
fpr, tpr, thresholds = roc_curve(data_y, y_scores)
def rocCurve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label, color="blue")
plt.plot([0, 1], [0, 1], '--', color="red")
plt.grid()
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.title("FPR vs TPR")
plt.show()
rocCurve(fpr, tpr) #绘制auc曲线
print("ROC AUC: ", roc_auc_score(data_y, y_scores)) #auc为ROC曲线下面积,是衡量分类器好坏的指标之一,分类越好的分类器auc越接近1

ROC AUC(曲线下面积)越接近1,模型的分类效果越好;

三、logistic回归实现二分类
由之前的:
p
=
h
θ
(
x
)
=
σ
(
x
T
θ
)
=
1
1
+
e
−
x
T
θ
p=h_{\theta}\left( x \right) =\sigma \left( x^T\theta \right) =\frac{1}{1+e^{-x^T\theta}}
p=hθ(x)=σ(xTθ)=1+e−xTθ1
y
=
{
1
,
i
f
p
⩾
0.5
0
,
i
f
p
<
0.5
y=\left\{ _{1, if\,\,p\,\,\geqslant \,\,0.5}^{0, if\,\,p\,\,<\,\,0.5} \right.
y={1,ifp⩾0.50,ifp<0.5
将y看成样本x被视为正类的可能性,则1-y就是样本x被视为负类的可能性,有:
ln
y
1
−
y
=
w
T
x
+
b
\ln \frac{y}{1-y}=w^Tx+b
ln1−yy=wTx+b
即
ln
p
(
y
=
1
∣
x
)
p
(
y
=
0
∣
x
)
=
w
T
x
+
b
\ln \frac{p\left( y=1|x \right)}{p\left( y=0|x \right)}=w^Tx+b
lnp(y=0∣x)p(y=1∣x)=wTx+b
我们可以推出:
p
(
y
=
1
∣
x
)
=
e
w
T
x
+
b
1
+
e
w
T
x
+
b
p\left( y=1|x \right) =\frac{e^{w^Tx+b}}{1+e^{w^Tx+b}}
p(y=1∣x)=1+ewTx+bewTx+b
p
(
y
=
0
∣
x
)
=
1
1
+
e
w
T
x
+
b
p\left( y=0|x \right) =\frac{1}{1+e^{w^Tx+b}}
p(y=0∣x)=1+ewTx+b1
最后得到代价函数:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
log
(
p
(
i
)
)
+
(
1
−
y
(
i
)
log
(
1
−
p
(
i
)
)
)
]
J\left( \theta \right) =-\frac{1}{m}\sum_{i=1}^m{\left[ y^{\left( i \right)}\log \left( p^{\left( i \right)} \right) +\left( 1-y^{\left( i \right)}\log \left( 1-p^{\left( i \right)} \right) \right) \right]}
J(θ)=−m1i=1∑m[y(i)log(p(i))+(1−y(i)log(1−p(i)))]
对代价函数求关于
θ
\theta
θ的偏导
∂
∂
θ
j
J
(
θ
)
=
1
m
∑
i
=
1
m
(
σ
(
θ
T
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\frac{\partial}{\partial \theta _j}J\left( \theta \right) =\frac{1}{m}\sum_{i=1}^m{\left( \sigma \left( \theta ^Tx^{\left( i \right)} \right) -y^{\left( i \right)} \right)}x_{j}^{\left( i \right)}
∂θj∂J(θ)=m1i=1∑m(σ(θTx(i))−y(i))xj(i)
接下来根据该偏导方程用梯度下降求解即可:
1.BGD实现logistic回归
import numpy as np
from sklearn.metrics import classification_report#评估模型
from numpy import dot
file1 = "classification_train.txt"
file2 = "classification_test.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int).reshape(len(data_x), 1)
test_x = np.loadtxt(file2, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
test_y = np.loadtxt(file2, delimiter=',', usecols=(0), dtype = int)
def sigmoid(z):
return 1/(1 + np.exp(-z))
def cost_function(theta, x, y): #损失函数
return np.mean(-y * np.log(sigmoid(x.dot(theta)) - (1 - y) * np.log(1 - sigmoid(x.dot(theta)))))
def gradient(theta, x, y): #梯度
return x.T.dot(sigmoid(x.dot(theta)) - y) / len(x)
theta = np.random.rand(8, 1)
alpha = 0.01
for i in range(100000):
grad = gradient(theta, data_x, data_y) #求梯度
theta = theta - grad * alpha #更新
print("cost_function ", cost_function(theta, data_x, data_y))
threshold = 0.5 #阈值设为0.5
pred_y = sigmoid(test_x.dot(theta))
pred_y = np.where(pred_y >= threshold, 1, 0)#转换成0与1
print(classification_report(test_y, pred_y))#评估该分类模型的各项参数

参数调试了很久还是这个样子,虽然好像损失函数还行,但是精度以及正类的召回率太低了。。就挺差的;
SGD实现logistic回归:
import numpy as np
import numpy as np
from sklearn.metrics import classification_report
from numpy import dot
from numpy import random
file1 = "classification_train.txt"
file2 = "classification_test.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int).reshape(len(data_x), 1)
test_x = np.loadtxt(file2, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
test_y = np.loadtxt(file2, delimiter=',', usecols=(0), dtype = int)
def sigmoid(z):
return 1/(1 + np.exp(-z))
def cost_function(theta, x, y): #损失函数
return np.mean(-y * np.log(sigmoid(x.dot(theta)) - (1 - y) * np.log(1 - sigmoid(x.dot(theta)))))
def gradient(theta, x, y): #梯度
return x.T.dot(sigmoid(x.dot(theta)) - y) / len(x)
def learning_rate(t):#学习率
return 1 / (100 + t)
theta = np.random.rand(8, 1)
m = len(data_x)
batch_size = 30
epochs = 30
for epoch in range(epochs):
for i in range(m):
index = np.random.randint(m, size=batch_size)
x = data_x[index]
y = data_y[index]
grad = gradient(theta, x, y) / batch_size # 求梯度
theta = theta - grad * learning_rate(epoch / 1000 + m / 10000) # 更新
print("cost_function: ", cost_function(theta, data_x, data_y))
threshold = 0.5
pred_y = sigmoid(test_x.dot(theta))
pred_y = np.where(pred_y >= threshold, 1, 0)
print(classification_report(test_y, pred_y))
调参是真的麻烦,而且主要是调了之后的结果也还是不理想,不知道为什么对负类的分类结果比较好,但是正类就不行了(竟然低于50%,瞎猜都有50%的正确率呀。。),召回率真的是离谱了,负类的高达96%,正类的低的可怕,竟然只有14%,(虽然只是这次比较偶然,但是调了阈值后发现负类和正类的召回率总是不能同时较高,很奇怪),挺失败的;

3.自带SGD模块和LogisticRegression模块实现logistic回归
(1)LogisticRegression in linear_model
用sklearn中自带的逻辑回归模块;
linear_model是个好东西,竟然连现成的LogisticRegression都有,直接套就完事了;
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
file1 = "classification_train.txt"
file2 = "classification_test.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int)
test_x = np.loadtxt(file2, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
test_y = np.loadtxt(file2, delimiter=',', usecols=(0), dtype = int)
log = LogisticRegression()
log.fit(data_x, data_y)
pred_y = log.predict(test_x)
print(classification_report(test_y, pred_y))

看到这结果突然感到很感动,因为这结果太好了(比自己实现的强太多了吧),轮子还是非常强的QAQ
(2)SGD in linear_model
#linear中的SGDClassifier模块
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import classification_report
import numpy as np
file1 = "classification_train.txt"
file2 = "classification_test.txt"
data_x = np.loadtxt(file1, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
data_y = np.loadtxt(file1, delimiter=',', usecols=(0), dtype = int)
test_x = np.loadtxt(file2, delimiter=',', usecols=None,dtype = np.float32)[:,1:]
test_y = np.loadtxt(file2, delimiter=',', usecols=(0), dtype = int)
cla = SGDClassifier(random_state=23)
cla.fit(data_x, data_y)
pred_y = cla.predict(test_x)
print(classification_report(test_y, pred_y))

这应该是用logistic回归最好的结果了,看来如果用logictic回归用于该数据集的分类的话最好的结果就是和这个差不多了,可以考虑用其他方法(正类分类正确率终于上了70%!但是正确率还是相当低呀);
四、多分类
很多时候问题答案并不是非黑即白的,即可能有多种结果,而我们上述的内容都是针对二分类问题的,所以接下来我们要考虑解决多分类问题;
1.一些多分类算法
朴素贝叶斯分类器,随机森林分类器,决策树分类器等算法可以用来解决多分类问题,这其中每个部分内容都比较多,可以自成一个章节,这里不多赘述;
2.多分类策略
实际上不需要用到新的多分类算法,用之前的logistic回归就可以实现多分类,只是需要用到多分类策略;
(1)OvR
即一对剩余,或者说一对多策略,具体是这样的:当我们想要对某个东西进行多分类;如对一批国产芒果进行分类,判断它们是来自我国哪个省的;我们就训练出34个二元分类器,然后用这批芒果训练这些分类器,最终每个分类器都会给出相应的正类概率或者说决策分数;如广西分类器给出的分数最高,有90%,所以我们判断这批芒果最可能来自广西,即哪个分类器决策分数最高,我们就判断样本属于哪一类。
(2)OvO
即一对一策略,同样以上述芒果举例;我们的做法是把所有可能的类结果两两配对,为每一对类别都训练一个二元分类器,如广西和广东一类,训练一个二元分类器看芒果属于广西的概率大还是属于广东的概率大,这样我们就需要 N ∗ ( N − 1 ) / 2 N * (N - 1) / 2 N∗(N−1)/2即 34 ∗ 33 / 2 = 561 34 *33/2=561 34∗33/2=561个分类器;然后统计一下哪个类获胜最多,如广西赢得最多,赢了33次,那么我们就判断芒果属于广西,即哪个类获胜最多我们就判断样本属于哪个类;
OvO一般只适用于少部分算法如数据规模较大的支持向量机算法,因为它所需要的分类器数量太多了,需要建立 N ∗ ( N − 1 ) / 2 N * (N - 1) / 2 N∗(N−1)/2个,而OvR就要好很多,只需要建立 N N N个分类器,所以一般情况下我们选择OvR策略;
(3)调用sklearn中的OneVsRestClassifier模块实现基于OvR策略的多分类
鸢尾花:经典的分类数据集,共有150个样本,其中有四个属性,3个类别(0,1,2);
from sklearn.multiclass import OneVsRestClassifier
from sklearn.metrics import classification_report
from sklearn.datasets import load_iris #导入鸢尾花数据,共有150个样本,其中有四个属性,3个类别(0,1,2)
from sklearn.linear_model import LogisticRegression
iris = load_iris()#载入数据集
data_x = iris["data"] #获取花卉样本属性
data_y = iris["target"] #获取花卉标签
ovr_cla = OneVsRestClassifier(LogisticRegression())#调用OvR策略模块
ovr_cla.fit(data_x, data_y)
pred_y = ovr_cla.predict(data_x)
print(classification_report(data_y, pred_y))

效果非常好,0类甚至达到了百分之百的分类正确(这数据太友好了吧,感动)
或者暴力,直接训练三个0,1,2类的分类器,再把数据放进里面,看哪一类的分数更高就分到哪一类;
3.softmax回归
(1)模型简介
实际上logistic回归经过拓展后并不是只能执行二分类任务,也能执行多分类任务,这样就不用管我们之前的二分分类器的训练与组合策略,升级后的logistic回归被称为softmax回归,或者说多元logistic回归;
softmax回归的原理和之前的OvR策略很像,也是先计算出每一个类的分数;有所不同的是在softmax回归中,我们会对这些分数进行处理:对它们应用softmax函数(或者说归一化指数),接着就能得出每个类的概率,然后看哪个类的概率最高,我们就把样本归到哪个类中。
softmax回归中的第k类的分数计算:(该式子和之前线性回归求预测值的很像)
s
k
(
x
)
=
x
T
θ
(
k
)
s_k\left( x \right) =x^T\theta ^{\left( k \right)}
sk(x)=xTθ(k)
求得分数后,将其带入softmax函数来求得是第k类的概率:(和logistic回归中的sigmoid函数类似)
p
k
=
σ
(
s
(
x
)
)
k
=
e
s
k
(
x
)
∑
j
=
1
k
e
s
j
(
x
)
p_k=\sigma \left( s\left( x \right) \right) _k=\frac{e^{s_k\left( x \right)}}{\sum_{j=1}^k{e^{s_j\left( x \right)}}}
pk=σ(s(x))k=∑j=1kesj(x)esk(x)
注意,
σ
\sigma
σ中的
s
(
x
)
s(x)
s(x)是一个包含了样本对应的每个类分数的向量;
很明显,通过该式子得到的结果一定为0~1的值,且某个类初始分数越高,其概率就越大,即:
y
=
a
r
g
k
max
σ
(
s
(
x
)
)
k
=
a
r
g
k
max
s
k
(
x
)
=
a
r
g
k
max
(
(
θ
(
k
)
)
T
x
)
y=arg_k\max \sigma \left( s\left( x \right) \right) _k=arg_k\max s_k\left( x \right) =arg_k\max \left( \left( \theta ^{\left( k \right)} \right) ^Tx \right)
y=argkmaxσ(s(x))k=argkmaxsk(x)=argkmax((θ(k))Tx)
由于argmax是返回使函数最大化的变量值,所以当概率取得最大值时,返回的就是对应的类别k;
(2)多分类的具体实现
知道了softmax回归的基本原理后,我们就可以借助它来帮助我们解决多分类任务啦;我们的目标是想要正确执行多分类,即给定一个样本,分类器返回对应正确的类别;根据上述,为了使分类效果更好,我们想要尽可能增大样本正确类的概率,而减少其他错误类的概率。如芒果分类,假如它来自广西,那么我们想要使广西这个类在经过softmax函数后得到的概率尽可能大,而其他省的类得到的概率尽可能小,以防止产生混淆,这样我们多分类的结果才会比较正确。
为了达成这个目的,我们引入交叉熵代价函数,通过最小化该函数来求出正确的类别k:
J
(
Θ
)
=
−
1
m
∑
i
=
1
m
∑
k
=
1
K
y
k
(
i
)
log
(
p
k
(
i
)
)
J\left( \varTheta \right) =-\frac{1}{m}\sum_{i=1}^m{\sum_{k=1}^K{y_{k}^{\left( i \right)}}\log \left( p_{k}^{\left( i \right)} \right)}
J(Θ)=−m1i=1∑mk=1∑Kyk(i)log(pk(i))
其中
y
k
(
i
)
y_k^{(i)}
yk(i)为属于类k的第i个样本的目标概率,即对于第i个样本,若它的标签是类k,则
y
k
(
i
)
y_k^{(i)}
yk(i)就为1,否则为0;
当K=2时我们可以发现该函数就和我们之前logistic回归所用的代价函数是一样的;
交叉熵经常被用来衡量目标类与计算出的类概率的匹配程度;
交叉熵代价函数对
θ
(
k
)
\theta^{(k)}
θ(k)的梯度:
∇
θ
(
k
)
J
(
Θ
)
=
1
m
∑
i
=
1
m
(
p
k
(
i
)
−
y
k
(
i
)
)
x
(
i
)
=
1
m
∑
i
=
1
m
(
s
o
f
t
max
(
x
i
,
θ
k
)
−
y
k
(
i
)
)
x
(
i
)
=
1
m
∑
i
=
1
m
(
e
x
T
θ
k
∑
j
=
1
k
e
x
T
θ
(
j
)
−
y
k
(
i
)
)
x
(
i
)
\nabla _{\theta \left( k \right)}J\left( \varTheta \right) =\frac{1}{m}\sum_{i=1}^m{\left( p_{k}^{\left( i \right)}-y_{k}^{\left( i \right)} \right) x^{\left( i \right)}}=\frac{1}{m}\sum_{i=1}^m{\left( soft\max \left( x_i,\theta ^k \right) -y_{k}^{\left( i \right)} \right)}x^{\left( i \right)} \\ \,\, =\frac{1}{m}\sum_{i=1}^m{\left( \frac{e^{x^T\theta ^k}}{\sum_{j=1}^k{e^{x^T\theta ^{\left( j \right)}}}}-y_{k}^{\left( i \right)} \right)}x^{\left( i \right)}
∇θ(k)J(Θ)=m1i=1∑m(pk(i)−yk(i))x(i)=m1i=1∑m(softmax(xi,θk)−yk(i))x(i)=m1i=1∑m(∑j=1kexTθ(j)exTθk−yk(i))x(i)
接下来就是用梯度下降求解了(虽然我暂时还没弄出python实现,太菜了)
(3)softmax回归模块实现
from sklearn.metrics import classification_report
from sklearn.datasets import load_iris #导入鸢尾花数据,共有150个样本,其中有四个属性,3个类别(0,1,2)
from sklearn.linear_model import LogisticRegression
iris = load_iris()#载入数据集
data_x = iris["data"] #获取花卉样本属性
data_y = iris["target"] #获取花卉标签
sof_reg = LogisticRegression(multi_class="multinomial", solver="lbfgs", C=3)#可以理解为softmax回归是一种特殊的logistictic回归,所以在LogisticRegression模块中,
sof_reg.fit(data_x, data_y)#只要调一下multi_class就可以使用softmax回归了,lbfgs是一种支持softmax回归的求解器(solver),参数C控制默认使用的正则化
pred_y = sof_reg.predict(data_x)
print(classification_report(data_y, pred_y))

tql!















 6144
6144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









