







 本文介绍了一种名为CINO-GCN的藏文文本分类方法,利用预训练模型CINO提取文本特征,并通过构建的文本图进行图卷积神经网络分类。实验表明,CINO-GCN在藏文文本分类任务上优于其他基线模型,特别是在处理样本数量较少的类别时表现出色。
本文介绍了一种名为CINO-GCN的藏文文本分类方法,利用预训练模型CINO提取文本特征,并通过构建的文本图进行图卷积神经网络分类。实验表明,CINO-GCN在藏文文本分类任务上优于其他基线模型,特别是在处理样本数量较少的类别时表现出色。
仅供自己学习使用,禁止转载和搬运,有不对的地方还请批评指正!
如有侵权,联系立删!
本文提出一种真对藏文长文本分类的方法CINO-GCN,通过微调与训练语言模型CINO作为嵌入层,获得藏文文档和音节的特征表示,然后根据整个数据集的音节共现关系和文档间的TF-IDF值对藏文文本图进行建模,与CINO生成的结点特征输入到图卷积神经网络(GCN)做进一步的特征提取,最后通过softmax得到分类结果。
模型设计
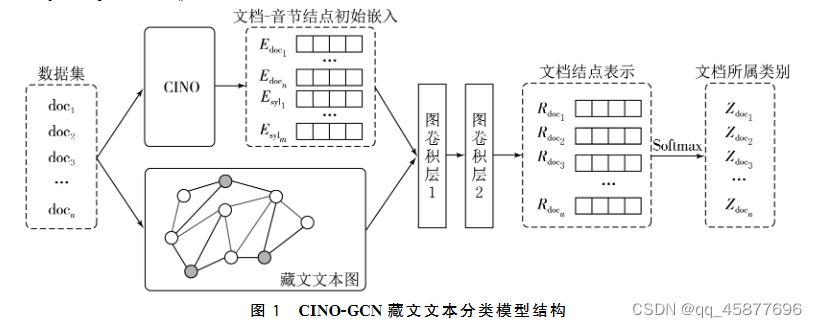
1、对CINO模型进行微调来适应数据集的特征;
2、笼统的统计出藏文文章数据集包含的
个不重复的藏文音节,构成音节集合
,将这些内容都输入到CINO中得到对应的特征表示作为初始嵌入矩阵;同时根据数据集
提供的信息构建文档-音节异构文本图得到邻接嵌入矩阵;
3、将文本嵌入矩阵和音节嵌入矩阵一起输入到具有两层卷积的图神经网络中得到每篇文章的最终文档结点表示,通过softmax操作得到每篇文档最终的预测类别
。
预训练模型提取文本特征
使用CINO模型来提取文本特征(获取的是藏文文本音节对应的CINO词向量):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









