









IO通信模型
1. Linux的文件描述符
我们知道在Linux系统中一切皆可以看成是文件,文件又可分为:普通文件、目录文件、链接文件和设备文件。在操作这些所谓的文件的时候,我们每操作一次就找一次名字,这会耗费大量的时间和效率。所以Linux中规定每一个文件对应一个索引,这样要操作文件的时候,我们直接找到索引就可以对其进行操作了。
文件描述符(file descriptor)就是内核为了高效管理这些已经被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符来实现。同时还规定系统刚刚启动的时候,0是标准输入,1是标准输出,2是标准错误。这意味着如果此时去打开一个新的文件,它的文件描述符会是3,再打开一个文件文件描述符就是4…
Linux内核对所有打开的文件有一个文件描述符表格,里面存储了每个文件描述符作为索引与一个打开文件相对应的关系,简单理解就是下图这样一个数组,文件描述符(索引)就是文件描述符表这个数组的下标,数组的内容就是指向一个个打开的文件的指针。

文件描述符参考链接
2.IO通信流程
在操作系统中,如Linux,具有内核kernal的概念;在IO通信中,客户端的连接握手都是要与内核进行沟通的;那么整个过程一定会产生内核状态的切换;
在学习Redis的时候,了解Linux中使用epoll实现Redis高响应的能力,那么什么是epoll?
2.1 传统IO
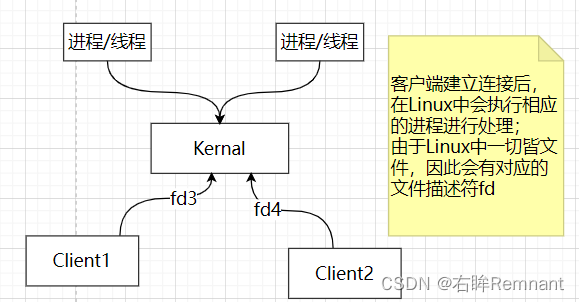
在这里,每一个客户端的连接对应一个文件描述符fd, 对应的OS中需要线程/进程处理,并且同一时刻,都会个占用一个CPU;在每个请求结束前,进程都不能处理其他事情,这就是阻塞模式。
因此,如果客户端请求连接足够大,需要开启一定量的线程/进程去处理,也就产生了内存开销;并且也伴随着CPU调度问题,性能下降。
2.2 非阻塞IO
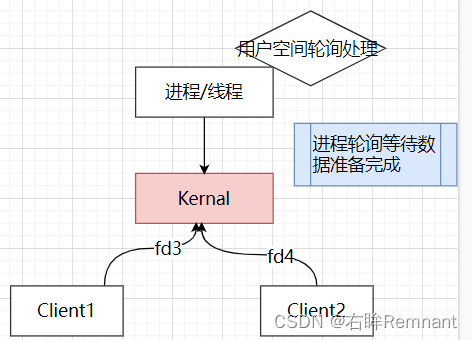
相比于传统IO,这里想使用一个线程/进程去处理多个请求,当请求到达后,有内核去准备相应数据,在此期间进程使用死循环进行轮询等待;一旦收到数据准备完毕就去处理。整个过程是非阻塞的
这里的问题:在忙等期间线程/进程会持续占用CPU,对于CPU的利用率很低。
2.3 select()
为了处理上述的问题,引入了新的系统调用selet, 可以理解成一个代理
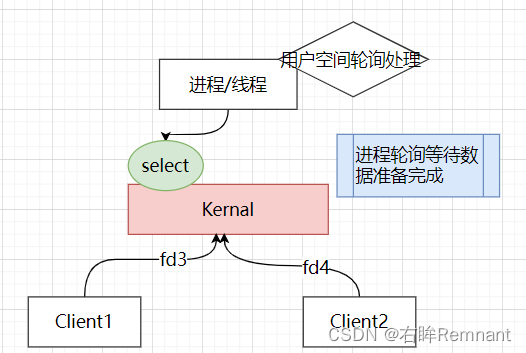
数据准备期间的等待不在由用户进程去持有,而是交由一个系统调用去监听;
用户线程会将所有需要监听的事件(fd)通知select去监听,然后可以做其他事情,可处理事件由select发起中断通知CPU;这个过程称为多路复用
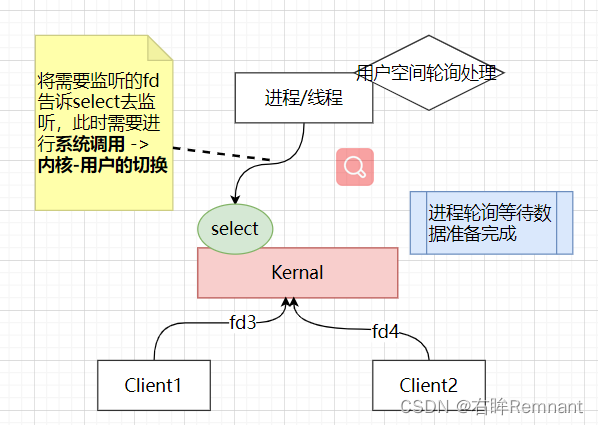
问题:有说过,线程需要将监听的fd通知给select,那么如果fd过多,二者之间的交互数据会增多,需要进行非核心数据的拷贝,那么也会产生额外开销进行用户-内核的切换。
如:进程/线程先告诉select去监听哪些fd(数据拷贝), select发现可以处理了,通知线程(第二次拷贝)
2.4 mmap, epoll的引入
对于select中的非核心数据导致的用户-内核的切换;问题在于二者数据的通信部署于不同的工作空间,所以有了将这些公共数据共享的想法;这个操作使用的是mmap
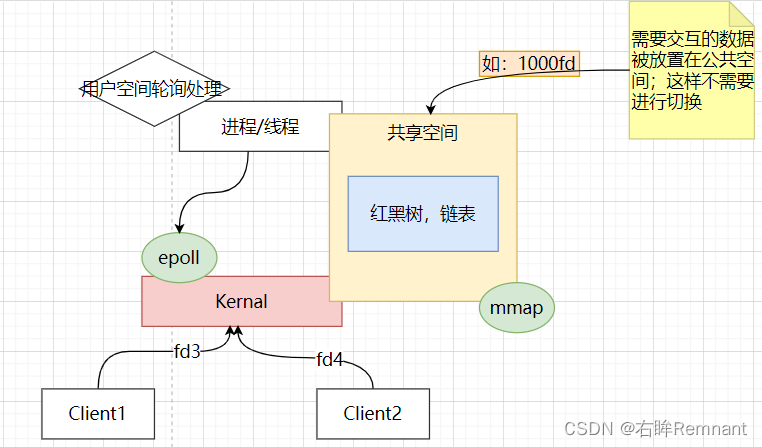
非核心数据的交互信息被放置在公共区域,进程,epoll不需要切换直接访问;这里的epoll可以理解和select有类似的监听作用,但是更强大,是多个系统调用的集合。
共享空间中维护不同数据结构,通过红黑树维护需要监听的fd文件描述符,准备好的事件会放入链表中然后进行遍历处理。
明天看看Linux,提醒自己一下
PageBuffer
在执行读写操作的时候会发生系统调用,由用户态切换到内核态;并且数据的写入过程不会直接作用与磁盘,而是先写到PageBuffer中,在不手动执行flush()的前提下PageBuffer中数据的写入由OS决定。
PageBuffer中缓存者若干Page页(4K),如果访问PageBUffer的时候未命中将发生缺页中断,可以由协处理器从磁盘读数据到pageBuffer中,然后进行返回
协处理器可以帮助CPU分担部分工作,在协处理器的配合下CPU可以处理其他事情
当pageBuffer中的page被修改后,这个部分成为脏页,需要重新写入磁盘
Linux中使用
sysctl -a # 可以查看系统参数
sysctl -a | grep dirty # 可以查看Linux中脏页处理的参数
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10 # 后台处理阈值,当达到设定后发生OS的磁盘写
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 30 # 前台处理,发生后阻塞用户进程
vm.dirty_writeback_centisecs = 500
vi /etc/sysctl.conf # 可以编辑系统参数配置
此时点击关机,模拟单点故障,不存在备份写回的操作
再次打开虚拟机查看文件大小
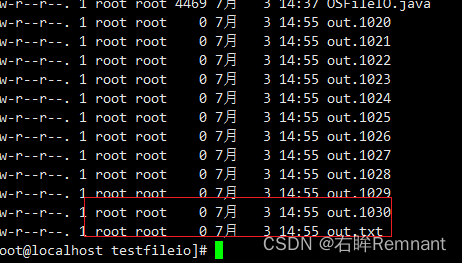
重启后发现本来写入的数据全部丢失了,说明之前写入的位置都是pageCache,还没有达到设定的阈值写回磁盘持久化。
使用Buffer
当使用buffer的时候,产生的数据量如下:
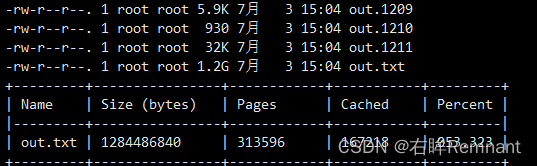
当使用Buffer的时候,会将批量的数据进行写入;而之前使用的传统IO为1字节这样进行写入的,每次写入pageCache都会进行一次系统调用,用户态和内核态的切换,因此会产生很多的性能损耗。
而使用了Buffer通过批量传递数据,减少了系统调用的次数。
nio文件读写
对之前整理的NIO知识的补充:BIO和NIO
NIO:多路复用技术,在提供的JavaAPI当中会使用ByteBuffer作为数据缓冲提高读写的效率。
其中:
MappedByteBuffer map = rafchannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096);
这是用于文件读写的ByteBuffer,不同与SocketBuffer,这里的map是文件读写特有的,底层使用mmap, 会生成MMaped对象,其中的数据将直接作用与pageCache,直接联通了用户和内核,避免了状态的切换。
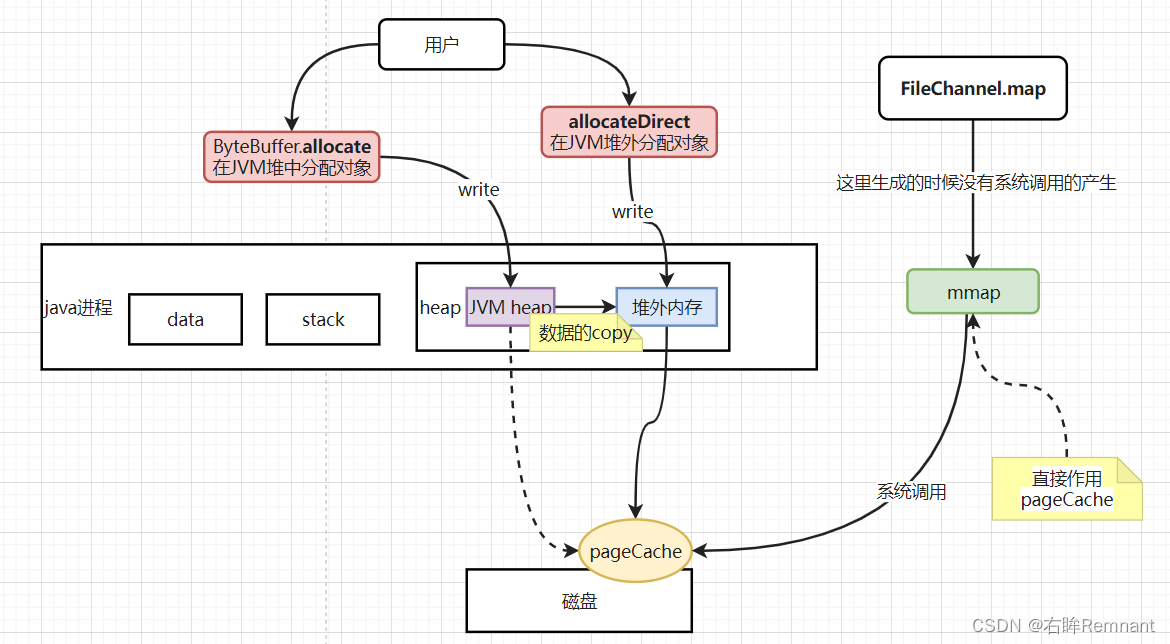
Nio中的三种内存分配方式:
ByteBuffer.allocate, 在堆空间中直接分配内存,需要额外的拷贝从JVM内换出最后到pageCache
ByteBuffer.allocateDirect: 利用直接内存,减少了一次从JVM内的数据拷贝过程
FileChannel.map,文件读写中特有的方法,可以利用mmap直接作用pageChahe















 1156
1156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









