







 该文章展示了如何使用Python的requests库获取网页HTML内容,并通过正则表达式进行数据匹配和提取。作者提供了两个正则模式(pat1和pat2)来抓取指定网页表格中的特定数据,并将结果合并展示。
该文章展示了如何使用Python的requests库获取网页HTML内容,并通过正则表达式进行数据匹配和提取。作者提供了两个正则模式(pat1和pat2)来抓取指定网页表格中的特定数据,并将结果合并展示。
Python爬虫的初学练习,非常简单
爬取网页地址:https://changyongdianhuahaoma.bmcx.com/
先看一手网页啥样子
import re
import requests
url = "https://changyongdianhuahaoma.bmcx.com/"
response = requests.get(url)
HTML = response.text
print(HTML) #观察网页代码
查看网页代码可以看到数据如图:
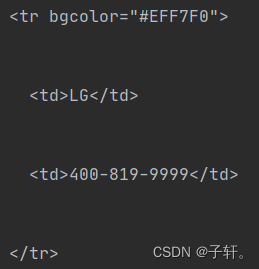
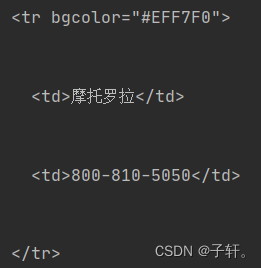
使用正则表达式匹配一下就好
下面是所有代码
import re
import requests
url = "https://changyongdianhuahaoma.bmcx.com/"
response = requests.get(url)
HTML = response.text
print(HTML) #观察网页代码
#正则表达式
pat1 = r' <tr bgcolor="#EFF7F0">[\s\S]*?<td>(.*?)</td>[\s\S]*?<td>[\s\S]*?</td>[\s\S]*?</tr>'
pat2 = r' <tr bgcolor="#EFF7F0">[\s\S]*?<td>[\s\S]*?</td>[\s\S]*?<td>(.*?)</td>[\s\S]*?</tr>'
#compile()方法: 编译正则表达式
pattern1 = re.compile(pat1)
pattern2 = re.compile(pat2)
#findall()方法
#所有匹配到的字符,以列表的形式返回,如果未匹配到数据则返回空列表
result1 = pattern1.findall(HTML)
result2 = pattern2.findall(HTML)
print(result1) #观察爬取数据是否有误
print(result2)
a = []
for i in zip(result1,result2): #两项数据合并
a.append(i)
print(a)
散会


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









