







什么是LinkedHashMap?
LinkedHashMap是Java中的一种特殊类型的HashMap,它继承自HashMap并实现了Map接口。与普通的HashMap不同,LinkedHashMap在内部使用双向链表维护了插入顺序或者访问顺序,故而保证元素的顺序。
LinkedHashMap的主要用途是在需要保持元素顺序的场景中使用,它可以用来实现LRU(least Recently Used ,最近很少使用) 缓存,通俗的讲就是根据元素的访问顺序进行缓存淘汰,当然,linkedHashMap还可以用于实现有序的映射表,保持元素按照插入顺序或者访问顺序排列。

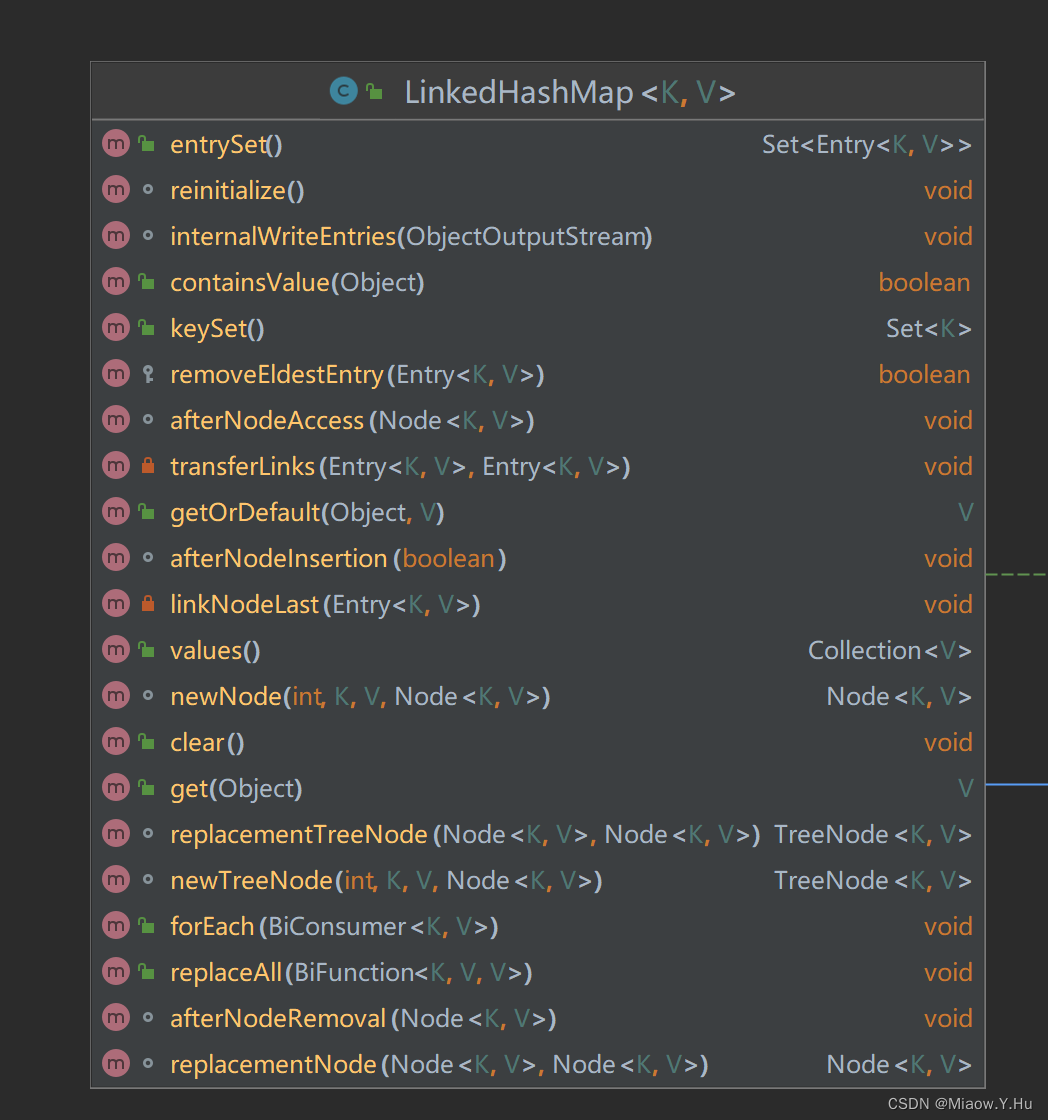
优缺点
LinkedHashMap的优点:
- 保持元素访问:LinkedHashMap可以按照插入顺序或访问顺序保持元素的顺序,适用于需要保持顺序的场景。
- 快速访问: LinkedHashMap的底层使用哈希表实现,因此可以快速进行元素的查找和访问。
- 可以预测的迭代顺序:用于使用链表维护元素顺序,迭代LinkedHashMap时可以按照插入顺序或者访问顺序进行,迭代顺序是可以预测的。
LinkedHashMap的缺点:
- 占用更多的内存:相比普通的HashMap,LinkedHashMap需要额外的内存来维护链表结构,故而会占用更多的内存空间。
- 插入和删除性能略低:由于需要维护链表结构,LinkedHashMap在插入和删除元素时,相对于普通的HashMap会略微降低性能。
底层实现原理
LinkedHashMap的底层实现原理是通过继承HashMap并使用一个双向链表来维护元素的顺序。每个Entry节点都包含了前驱节点和后继节点的引用,这样可以在插入、删除和访问元素时,通过修改链表节点的引用来维护元素的顺序。
具体来说,LinkedHashMap在HashMap的基础上增加了一个双向链表,用于维护元素的顺序。链表中的每个节点都是一个Entry对象,包含了键值对的信息以及前驱节点和后继节点的引用。
当元素被插入LinkedHashMap时,会在链表的尾部添加一个新的节点。当元素被访问时,LinkedHashMap会将该节点移动到链表的尾部,以保持访问顺序。这样,最近访问的元素会位于链表的尾部,而最早访问的元素会位于链表的头部。
通过哈希表和链表的结合,LinkedHashMap实现了快速的查找和保持元素顺序的特性。在哈希表中,通过键的哈希值进行快速查找,而在链表中,通过修改节点的引用来维护元素的顺序。
需要注意的是,LinkedHashMap提供了两种顺序模式:插入顺序和访问顺序。默认情况下,LinkedHashMap使用插入顺序,即元素按照插入的顺序排列。可以通过构造函数或者调用setAccessOrder(true)方法来设置为访问顺序,即元素按照访问的顺序排列。
LinkedHashMap的底层实现使得它在保持元素顺序的同时,仍然具有快速的查找和插入性能。然而,由于需要维护额外的链表结构,LinkedHashMap相对于普通的HashMap会占用更多的内存空间。此外,在插入和删除元素时,相对于普通的HashMap,LinkedHashMap的性能略低。因此,在选择使用LinkedHashMap时,需要根据具体的需求权衡其优缺点。
代码案例:
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapExample {
public static void main(String[] args) {
// 创建一个LinkedHashMap,按照插入顺序保持元素顺序
LinkedHashMap<String, Integer> linkedHashMap = new LinkedHashMap<>();
// 向LinkedHashMap中插入元素
linkedHashMap.put("Apple", 10);
linkedHashMap.put("Banana", 5);
linkedHashMap.put("Orange", 8);
linkedHashMap.put("Grapes", 15);
// 遍历LinkedHashMap,按照插入顺序输出元素
for (Map.Entry<String, Integer> entry : linkedHashMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
output:
Apple: 10
Banana: 5
Orange: 8
Grapes: 15
假设我们有一个需求,需要实现一个简单的LRU(Least Recently Used,最近最少使用)缓存,即当缓存已满时,淘汰最近最少使用的元素。这个需求可以使用LinkedHashMap来实现。
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
public static void main(String[] args) {
LRUCache<Integer, String> cache = new LRUCache<>(3);
cache.put(1, "Apple");
cache.put(2, "Banana");
cache.put(3, "Orange");
System.out.println(cache); // 输出:{1=Apple, 2=Banana, 3=Orange}
cache.get(1); // 访问键为1的元素,将其移动到链表尾部
cache.put(4, "Grapes"); // 添加新元素,触发淘汰最近最少使用的元素
System.out.println(cache); // 输出:{2=Banana, 3=Orange, 4=Grapes}
}
}
上述代码中我们定义了一个LRUCache类,继承自LinkedHashMap。在LRUCache的构造函数中,我们指定了缓存的容量。通过调用父类的构造函数,我们创建了一个LinkedHashMap,并设置了accessOrder参数为true,以实现访问顺序。
我们重写了removeEldestEntry方法,当缓存的大小超过容量时,会返回true,触发淘汰最近最少使用的元素。
在main方法中,我们创建了一个容量为3的LRUCache对象,并向其中插入了三个键值对。然后,我们访问键为1的元素,将其移动到链表尾部。接着,我们添加了一个新的键值对,触发淘汰最近最少使用的元素。最后,我们输出LRUCache的内容,可以看到最近访问的元素保留在链表尾部,而最早访问的元素被淘汰。
















 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











