







 HashMap与LinkedHashMap都是Java中常用的Map实现,两者都实现了Map接口。HashMap无法保证遍历顺序,而LinkedHashMap通过维护双向链表保证了插入或访问顺序。当链表长度过长时,HashMap会转换为红黑树以优化性能。了解两者差异并适当选择,能有效提升代码性能。最佳实践包括确保哈希函数分布均匀和在Java 8上实现Comparable接口以优化LinkedHashMap。
HashMap与LinkedHashMap都是Java中常用的Map实现,两者都实现了Map接口。HashMap无法保证遍历顺序,而LinkedHashMap通过维护双向链表保证了插入或访问顺序。当链表长度过长时,HashMap会转换为红黑树以优化性能。了解两者差异并适当选择,能有效提升代码性能。最佳实践包括确保哈希函数分布均匀和在Java 8上实现Comparable接口以优化LinkedHashMap。
HashMap与LinkedHashMap
1. 简介
在日常开发中我们经常会批量操作数据,因此很多高级语言除了提供数组,还给我们提供很多高级的、抽象的数据类型来让我们处理批量数据时得心应手。由于这些轮子对于程序的性能是比较关键的轮子,因此很多语言都内置的提供了比较精致的实现。在java中,这种实现被称为集合框架。集合框架包含的接口、类十分丰富,而且功能强大,因此理解并熟悉java集合框架,对于写出正确高效的程序是十分有必要的。java集合框架中包含两个重要的类LinkedHashMap与HashMap,它们常常被用于按key-value存储、操作数据,对于常见的操作都是常数的时间复杂度,因此被广泛使用,虽然这两个类的作用类似,但是他们的实现和使用场景稍微不同。
2. 二者的区别
HashMap与LinkedHashMap都实现了Map接口,二者的存储形式都是采用bucket加链表的形式来进行存储的。二者的主要区别:
HashMap由于是按照key的hash值映射到对应的bucket中,无法保证遍历HashMap时的顺序是预期的顺序LinkedHashMap在HashMap的基础上加以改进,却可以保证遍历的顺序要么是插入item的顺序或者LRU访问的顺序
这是因为LinkedHashMap维护了一个双向链表来记录数据插入的顺序,因此在迭代遍历生成的迭代器的时候,是按照双向链表的路径进行遍历的。
如果选择LRU访问的顺序,LinkedHashMap对于访问过的item会将其移动到双链表的末尾,这样保证最近访问过的item是处于链表末端,因此较老其不经常使用的item会处于链表前端。这个特性恰好符合LRU的思想,因此LinkedHashMap可以用来实现LRU Cache。Android提供的SDK的LruCache类便是利用LinkedHashMap实现了基于Lru规则的缓存功能。
另外可以发现在java8中HashMap和LinkedHashMap有了改动,据说在某些Hash碰撞严重时,性能也不会太差。java8之前的Map实现的问题是当出现某个bucket的后面的链表太长了,也就是说发生hash冲突的item太多了,这样会导致访问操作退化到了O(n)。
java8的改进便是当bucket的链表长度大于阈值的时候,会将链表重新组织为一颗红黑树,这样在hash碰撞严重的时候性能还是可以保证到log(n).改进前后的示意图如下所示:
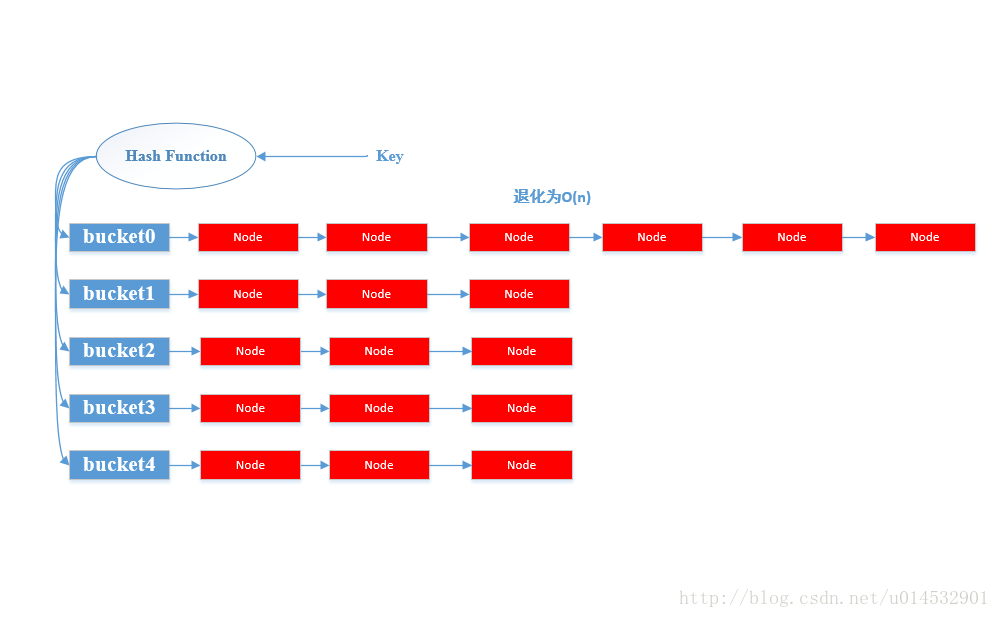
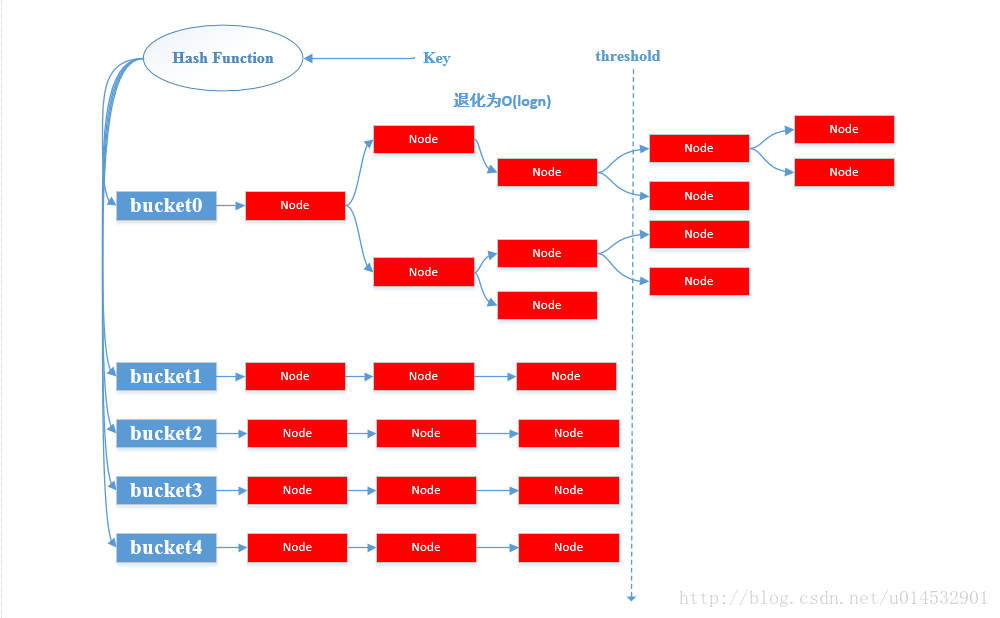
在使用LinkedHashMap和HashMap的时候应该注意Key的hash值是怎么取得,如果不同的key经常出现相同的hash值,则会频繁出现冲突,降低性能。
同时,由于改进后的HashMap会在某个bucket后的链表长度超过某个阈值时,重新将连边组织为一颗红黑树,因此在java8上的key最好实现Comparable接口来保证key是可以通过compareTo进行比较的,因为这样会简化建立红黑树的判断流程,提高效率。当然如果不实现Comparable接口的话,也会有相应的方法保证hash值冲突的item形成一颗平衡的红黑树。
3. 源码阅读
此处选取几个关键的地方进行源码分析:
- 对于
HashMap重点关注这几个方法
final void treeifyBin(Node<K,V>[] tab, int hash)public V put(K key, V value)final void treeify(Node<K,V>[] tab)static int tieBreakOrder(Object a, Object b)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//通过hash找到对应的桶,如果桶空则直接新建一个链表节点置于桶中并成为链表头
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//桶不为空,则从桶内存放的链表头开始查找
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//运气好的话,在链表头就找到了,注意此处key的匹配规则,首先是 == 匹配,然后再是调用equals方法匹配
e = p;
else if (p instanceof TreeNode)//如果该桶内存放的不再是链表,而是一颗树,则按树的规则去执行。
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//按链表顺序查找,并记录链表的节点数目
if ((e = p.next) == null) {
//如果查找到了链表尾,认为匹配到key,则新建一个节点
p.next = newNode(hash, key, value, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









