







文章索引
写在前面:
大家好呀!~下面每个标题都是超链接,点击即可直达此题蓝桥杯官网在线评测系统(可提交),并在下面笔者的思路和解题,每个cpp 都是通过了oj的,如果大家发现文重有错误或者更好的办法,十分欢迎告诉给我呀,一起学习嘻嘻。
字母阵列
主要思路 找到’L’ 然后 八个方向迭代即可。(emm 一定得是八条射线遍历,不是八皇后那种随机八个方向,所以在dfs中用for即可)
#include<string>
#include<algorithm>
#include<iostream>
using namespace std;
const int N = 110;
string s[N];
const string P = "LANQIAO";
int res = 0, n = 100;
void dfs(int col, int row)
{
for (int x = -1; x <= 1; ++ x) { //九个方向 只访问八个
for (int y = -1 ; y <= 1; ++ y) {
if (x == 0 && y == 0) continue; // 不重复 访问自身
int xi = x + col, yi = row + y; //下一个位置
int i = 1; // 因为 L 已经 匹配了 所以从 'A' (1)开始
for ( ; i <= 6; ++ i) {
if (xi < 0 || yi < 0 || xi >= n || yi >= n || s[xi][yi] != P[i] ) break; // 不符合 就退出
xi += x, yi += y; // 迭代
}
if (i == 7) //正常遍历 完就++
++res;
}
}
}
int main()
{
// cout << 41 <<endl;return 0;
for (int i = 0; i < n; ++ i) {
cin >> s[i];
}
for (int i = 0; i < n; ++ i) {
for (int j = 0; j < n; ++ j) {
if (s[i][j] == 'L') { // 遇到 'L' 就遍历
dfs( i, j);
}
}
}
cout << res << endl;
return 0;
}
方格计数
主要思想:
1、因为圆和正方形的对称性,只用枚举第一象限满足条件的点即可,然后再乘以4.
2、因为枚举第一象限,所以只要保证右端点在圆中,那整个正方形就可以在圆中。(不包括x,y轴,不能构成正方形)
#include<iostream>
#include<cmath>
using namespace std;
const long long N = 50000;
void f1() // O(n^2) 暴力 枚举 第一象限圆中 每一个 右端点
{
long long res = 0;
for (long long i = 1 ; i <= N; ++ i) {
for (long long j = 1; j <= N && i * i + j * j <= N * N ; ++ j) {
++res;
}
}
cout << res * 4 << endl;
}
void f2() // O(n) 只枚举 一个 右端点 y 坐标 即可
{
long long res = 0;
for (long long i = 1; i <= N; ++ i) {
long long x = sqrt(N * N - i * i); // 算出 <= xd的即是可选的 直接取 下整 即可
if ( x <= N && x >= 1)
res += x;
}
cout << res * 4 << endl;
}
int main()
{
f2(); //7853781044
return 0;
}
分数(找规律)
思路: 手写一些前几次的运算,可以发现:**分子每次乘以2+1,分子每次乘以2即可。
#include<iostream>
int main()
{
int n = 20;
int b = 1, suma = 1;
for (int i = 0; i < n - 1; ++ i) {
suma = suma * 2 + 1; // 发现规律 分母的和 每次 都是 上一次 *2 + 1
b *= 2; //分子 一直乘以2 即可
}
printf("%d/%d\n", suma, b);
return 0;
}
星期一 (用自带计算器或excel)

#include <iostream>
int main()
{
int n =36524;
std::cout << n / 7 << std::endl;
return 0;
}
猴子分香蕉
#include<iostream>
using namespace std; // 直接枚举 即可
bool check(int i )
{
int x = 1; //从1 开始的余数
while ( i ) {
if (i < 5) return false; // 小于 5 则 false
if ( i % 5 != x) return false;
if ( x == 0) return true;
i -= (i / 5 + i % 5);
x = (x + 1) % 5; // mod 5 的相加
}
return true;
}
int main()
{
for (int i = 1;; ++ i) {
if (check(i)) {
cout << i << endl;
break;
}
}
return 0;
}
缩位求合
思路 题目意思:不断的累加字符串每一位,再将这个累加的num 转为字符串s,直到s只剩一位即可。利用 to_stirng 可以很好的解决 复杂度大概是O(nlongn)
#include<iostream>
#include<string>
using namespace std;
string s;
void work()
{
int num = 0; //用一个 num 把 统计所有字符 总和
for(auto ch : s){
num += ch - '0';
}
s = to_string(num); //再转化为字符串
}
int main()
{
cin >> s;
while (s.size() >= 2) { //直到 只剩下 一个 字符
work();
}
cout << s << endl;
return 0;
}
回家路费
#include<iostream>
using namespace std;
//模拟
int main()
{
int date = 0;
for (int i = 1, sum = 0; sum < 108; i += 2, ++date ) // 模拟即可
sum += i;
cout << date << endl;
return 0;
}
乘积尾零
对每个元素一直除以 2 和 5统计2 和 5 的个数 取min 即是答案。

#include<iostream>
using namespace std;
int num2, num5; // 2 和 5 的数量
int main()
{
// cout <<31 <<endl;// return 0;
int n = 10, x, temp;
for (int i = 0; i < n * n; ++ i) { // 输入一百 个 数据
cin >> x;
temp = x;
while (x && x % 2 == 0) { // 求2 的个数
x >>= 1; // 求出一个 少 一个 右移 即除以二
num2 ++;
}
while (temp && temp % 5 == 0 ) { //一直 求 5 的个数
temp /= 5; // 求出一个 少一个 除以5
num5 ++;
}
}
cout << min(num2, num5) << endl; //31
return 0;
}
倍数问题
此题是一个限制选择个数 体积恰好(k 的倍数)类型的 背包问题 可以采用直接加一维进行枚举 即 f[4][ N ]
- 直接 加一维 暴力 :
for (int i = 1 ; i < n; ++ i) { // O(N *N *3) 即 3 * 1e8 肯定是会超时的
for (int j = 3; j >= 1; -- j)
for (int v = 0; v < k; ++v) {
f[j][v] = max(f[j][v], f[j - 1][(v - item % k + k) % k ] + item);
}
}
- 贪心优化
因为 是要求k的 倍数 如果 有很多同余k 相等的数 ,就没必要都枚举了, 我们只用保留 三个 (可能这三个数都是k的倍数,都最大)最大的即可
因此 只用 3e3 * 3e3 * 4 就可以枚举完 ,1e7 的量级 是完全OK哒
注意点: 因为是恰好为k倍数的体积 :所以一开始 只有f[0][0]合法=0,其余都为负无穷表示不合法。
#include<iostream>
#include<cstring>
#include<set>
using namespace std;
constexpr int N = 1e3 + 10; // 因为 做了贪心 优化: 只要 mod k 下相等 的 至多最大的 三个数 故 1 e3
set<int, greater<int>> arr[N]; // 降序
int n, k;
int f[4][N]; // 前i 个数 中 任意选 , 最多 选 j 个 且 总和 是 k 的倍数 的 最大 总和 是 f[i][j][k] (优化了 空间 i 这一维)
int main()
{
cin >> n >> k;
int x;
for (int i = 0 ; i < n; ++ i) {
scanf("%d", &x);
arr[x % k ].insert(x); //同mod 下相等 的 插入 ,类似 hash 表的方式
}
// 总和 是 k 的倍数 可理解 为 恰好 是 k 的倍数
memset(f, -0x3f, sizeof f); // 一开始 是 前0 个中 任意选 总和 肯定不能 是 1,2,3,4,5... 的倍数 即不合法
f[0][0] = 0; // 只有 选 0 个 且 体积 为 0 才合法
for (int i = 0 ; i < k; ++ i) {
int cnt = 0;
for (auto item : arr[i]) { // 枚举从小到大 枚举 每个 mod k 相等 的数
for (int j = 3; j >= 1; -- j) //优化了空间 从后往前枚举
for (int v = 0; v < k ; ++ v) {
f[j][v] = max(f[j][v], f[j - 1][(v - item % k + k) % k] + item ); //下标 必须是正数 所以 加k
}
if (++cnt == 3) break; //只要前三大的 数 即可
}
}
cout << f[3][0] << endl; //选了三个 mod k 为0 即 是 k 的 倍数
return 0;
}
耐摔指数
类似于限制个数的背包选择最优解问题 ,但是又不一致,因为这个并不是简单的前i个钟选j个,而是枚举每一层 枚举每个选择 择出最优解。 因此这更像是 二维限制的背包问题。 手机个数 和 选择楼层 都算是体积 。而手机个数很小。
因此 可以尝试打表发现规律。 会发现就是类似于 二维体积限制的状态转移
易错:不能先入为主的 认为,最优方案(这种贪心最好能证明出来再做)就是 二分查找 ,因为手机个数可能不够,所以得通过dp选出最优解。
思路:// 枚举 n 层选择方案, 再枚举 (1 ~ n )中每层方案 的最坏情况 的最小值,逐步递推即可
#include<iostream>
#include<cstring>
#include<algorithm>
#include<climits>
using namespace std;
constexpr int N = 10010;
int f[4][N];
int n;
void work(int num) // 类似于 背包问题 每层中最坏情况 中 的 最小 次数 就是最坏运气 下 的 最佳 策略
{
for (int i = 1; i <= n; ++ i) { // 枚举 n 层选择方案
int ans = INT_MAX;
for (int j = 1; j <= i ; ++ j) { // 从 1 开始 枚举 这层 的选择方案
// 分摔 坏 和没摔坏 两种 情况 考虑 ,坏了 手机数 -1 ,层数 -1, 好的 话 手机数不变 则只有测 上面的剩下的层数
int maxv = max(f[num - 1][j - 1], f[num][ i - j ] ) + 1; // 这一次 本身 的 1 也得加上
ans = min(ans, maxv);
}
f[num][i] = ans;
}
}
int main() // 分情况 考虑 到某一层 摔坏了 和 没摔坏
{
cin >> n;
for (int i = 1; i <= n ; ++ i ) f[1][i] = i;
work(2);
work(3);
cout << f[3][n] << endl;
return 0;
}
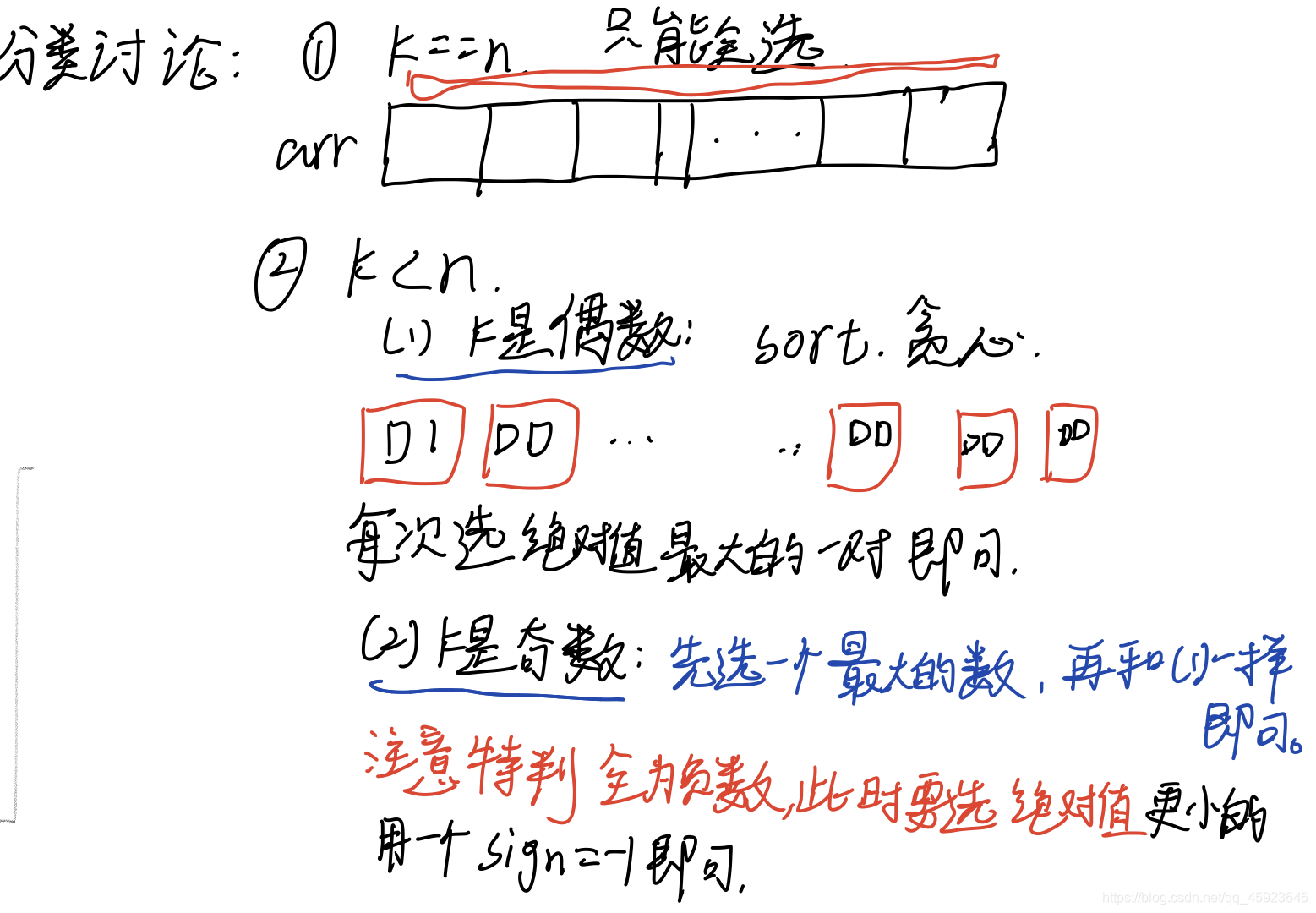
乘积最大
思路 : 双指针 + 贪心 :主要难点 : 分类讨论 时,尽可能的把 各种方式的写法统一起来,这样会好些很多
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
using LL = long long ;
constexpr int N = 1e5 + 10, mod = 1000000009;
int arr[N], n, k;
int main()
{
cin >> n >> k;
for (int i = 0 ; i < n; ++ i) scanf("%d", &arr[i]);
sort(arr, arr + n);
int l = 0, r = n - 1, sign = 1;
LL res = 1;
if (k & 1) { //只用讨论是不是奇数 即可 只要是偶数计算 方法就一样
res = arr[ r --];
k -- ;
if (res < 0) // 全为 负数 我们就只要绝对值 更小的 也就是 负数 更大的
sign = -1; //也可以直接 在这里 直接从右端 开始 乘 再输出 结束。
}
while (k) { // 双指针 两端遍历
LL x = (LL)arr[l] * arr[l + 1], y = (LL)arr[r] * arr[r - 1]; // 乘积过程 过程 可能 1e10 得转LL
if (x * sign > y * sign) {
res = x % mod * res % mod;
l += 2;
}
else {
res = y % mod * res % mod;
r -= 2;
}
k -= 2;
}
cout << res << endl;
return 0;
}
次数差
思路:因为s最长只有 1000,且都是字母, 所以 直接用unordered_map 统计 可以规避掉 0次数的处理然后直接算max 和min 即可
#include<iostream>
#include<unordered_map>
using namespace std;
unordered_map<char, int> ha; // 直接用 hash表 做 这样就就 不用考虑 没有 输入过的 字母了
string s;
int main()
{
cin >> s;
for (auto ch : s)
ha[ch ] ++;
int maxv = 0, minv = 1001;
for (auto &x : ha) {
maxv = max(x.second, maxv);
minv = min(x.second, minv);
}
cout << maxv - minv << endl;
return 0;
}
等腰三角形
思路 :找规律 1 为 中点 底边 长为 2 * n + 1。
#include<iostream>
#include<string>
using namespace std;
constexpr int N = 310;
int n ;
char s[N][N];
// 枚举 从上到下 从左到右 再 从下到上 枚举即可
int main()
{
cin >> n;
for (int i = 1 ; i < N; ++i) //便于 输出 先全部 赋 为 '.'
for (int j = 1; j < N; ++ j)
s[i][j] = '.';
string num;
for (int i = 1; i <= 10 * n; ++ i) { // 实际上 应该是 2-3倍 左右的 n 但要细算边界 干脆开了10倍
for (auto a : to_string(i))
num += a;
}
int i = 1, j = n, k = 0; // 从 (1,n ) 中点开始枚举
for (; i <= n; ++i, --j) { // i-1 ,j + 1, 最后 i 为 n + 1, j 为 -1
s[i][j] = num[k ++];
}
for (-- i, ++j, --k; j <= 2 * n - 1; ++ j ) { //让 i -1 ,j + 1, k -1 即可 ,最后 j 为 2 *n - 1
s[i][j] = num[k ++ ];
}
for (--j, --k; i > 1; -- i, --j) // j - 1 , k - 1
s[i][j] = num[k ++];
for (int i = 1; i <= n; ++ i) {
for (int j = 1; j <= n + i - 1; ++ j) //注意到 每行 都是 只有 n + i - 1 个
cout << s[i][j] ;
puts("");
}
return 0;
}
递增三元组
思路 :1. 暴力 枚举 a中每个元素,每次枚举b中大于a[i]的,并在b中枚举大于b[j]的。三重循环 O(n ^ 3) 1e15 肯定超时了
2. 顺着 这个思路 用乘法原理来做 ,a 和c 中的元素 是独立的, 因此我们对 a,b,c 都排序(b 可排 可不排,排序之后可以在枚举时做优化(文中没做),但复杂度都是O(nlongn)
3. 也可以用双指针(滑动窗口)来优化,写法是类似的
枚举 b中每个元素 , 在a中找 小于 <b[i] 元素的数量,再在c中找>b[i]的数量相乘即可 再求和即可。 例 :

#include<algorithm>
#include<iostream>
using namespace std;
using LL = long long ;
constexpr int N = 1e5 + 10;
int a[N], b[N], c[N];
int n;
int main()
{
cin >> n; //下标从 1 开始 的好处 是 : 下标 的位置 就 是 元素 的个数 比如 a[1] 1 则也可以代表 有一个元素
for (int i = 1; i <= n; ++i) scanf("%d", a + i);
for (int i = 1; i <= n; ++i) scanf("%d", b + i);
for (int i = 1; i <= n; ++i) scanf("%d", c + i);
sort(a + 1, a + 1 + n);
sort(b + 1, b + 1 + n);
sort(c + 1, c + 1 + n);
LL res = 0; // 因为 最大 可能 是 1e5 * 1e5 * 1e5 会爆int
for (int i = 1; i <= n; ++ i) {
int na = lower_bound(a + 1, a + n + 1, b[i]) - a - 1 ; // 返回 左边 第一个 >= b[i] 的位置 -1 个 则是 我们需要的 < b[i] 的位置
int nc = upper_bound(c + 1, c + n + 1, b[i]) - c ; // 返回 左边 第一个 > b[i] 的位置 正好 是我们想要的位置
res += (LL) na * ( n - nc + 1); // 记得转 LL // nc 是包含在内 的 所以 n - nc +1
}
cout << res << endl;
return 0;
}
付账问题
思路:贪心,从实际出发,有些人 的钱少,有些人正好,有些人多,为了保证方差尽可能小,显然得让这三种人 出的钱尽可能接近。
则: 不够 平均数 的全出,够的人都出平均数即可 (平均数’,已经去除过不够的人 的平均数)。
#include<iostream>
#include<cstring>
#include<cmath>
#include<algorithm>
using namespace std;
constexpr int N = 5e5 + 10;
double arr[N], e; // e 是 s/n 他们本来就要出的平均值
int n;
double s;
int main()
{
cin >> n >> s;
e = double(s) / n;
for (int i = 0 ; i < n ; ++ i) scanf("%lf", &arr[i]);
sort(arr, arr + n); // 先排序
double res = 0;
int num = n; // 剩余 未处理 的 数 的个数 一开始 自然 是 n
for (int i = 0 ; i < n ; ++ i) { // 从小到大 遍历
if (arr[i] < s / num ) { // 遇到小于 绝对值 的 就 直接 全要
res += (arr[i] - e) * (arr[i] - e); //方差计算
s -= arr[i]; // 减去 arr[i] 这个数
num --;
continue;
}
//否则 说明后面的数 都 >= s / n 则 都出 s/n 这样他们的方差 更小
res += num * (s / num - e) * (s / num - e);
break;
}
printf("%.4lf\n", sqrt(res / n)); // .4 就是 保留四位小数 四舍五入输出的
return 0;
}
航班时间
思路: 二元一次方程组 直接 得到 res = (y1- x1 +y2 - x2) /2;
难点 在于 格式化 输入 和输出 。 用sscanf 做格式化输入,printf做格式化输出会很方便, 还有 就是 因为除以2 可能会有精度丢失,而题目要求 输出的精度 是要精确要秒的 , 所以我们得至少转化为 秒 来计算
见代码:
#include <cstdio>
#include<iostream>
#include<string>
using namespace std;
string s1, s2;
int work(string &s)
{
if (s.back() != ')') s += " (+0)"; //把 他们都变成 一种 类型 即 都有 +d 这种类型来读
int h1, m1, t1, h2, m2, t2, d = 0;
sscanf(s.c_str(), "%d:%d:%d %d:%d:%d (+%d)", &h1, &m1, &t1, &h2, &m2, &t2, &d); //用sscanf 把他们读出来
return (h2 + d * 24) * 3600 + m2 * 60 + t2 - ( h1 * 3600 + m1 * 60 + t1); //返回 y - x
}
int main()
{
int t ;
cin >> t;
getline(cin, s1);
while (t -- ) {
getline(cin, s1);
getline(cin, s2);
int t = (work(s1) + work(s2)) / 2; // 结果 则是 ((y1 - x1) + (y2 - x2) )/2
printf("%02d:%02d:%02d\n", t / 3600, t % 3600 / 60, t % 60); //用 % 02d 来补齐两位
}
return 0;
}
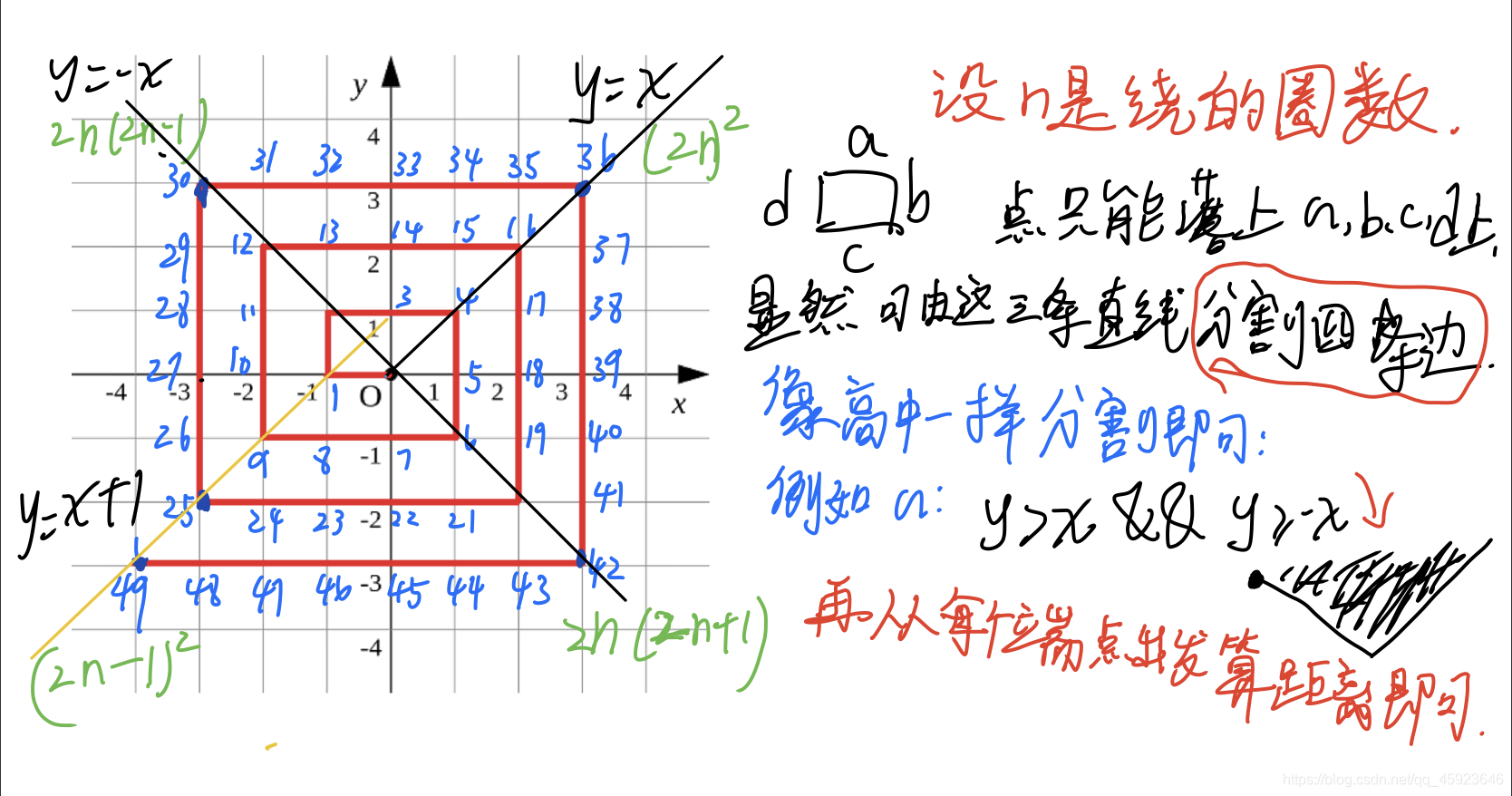
螺旋折线
思路: 1.: 暴力点 1e9*1e9 1e18 肯定过不了。暴力边可以1e9 但也超时了。
2. 找规律:先算出每个点的 距离 。可以发现四个角点 与圈数的规律 。
3. 再由角点 到 每个边上的距离可以直接算,就可以O(1) 算出各个点的距离。
4. 再用线性规划的方式 每次都用两条直线划分出一个边(实际上是一个范围).
#include<iostream>
using namespace std;
using LL = long long ;
int main()
{
int x, y; //圈数 n 实际上就是 每条边 上 不变 的坐标 的 绝对值
cin >> x >> y;
if ( y > x && y >= -x) { //在上边
LL n = y;
cout << (2 * n)* (2 * n - 1) + x + y << endl;
}
else if (y <= x && y > -x) { // 在右边
LL n = x ;
cout << 2 * n * 2 * n + x - y;
}
else if (y <= -x && y < x + 1) { //在下边
LL n = -y;
cout << (2 * n )* (2 * n + 1) + n - x << endl;
}
else { // 在左边
LL n = -x;
cout << (2 * n - 1)* (2 * n - 1) + y - (x + 1) << endl;
}
return 0;
}
全球变暖
思路: 连通块模型 ,遍历 每一个连通块,统计每一个连通块中的 靠海陆地的数量,是否 与 连通块中陆地数量相同,相同 res就 ++ (并且这道题 不用处理边界,因为边界全是 ‘.’ ,我们只访问 是 ‘#’ 的结点,是不会越界的)
#include<iostream>
using namespace std;
constexpr int N = 1010;
char s[N][N];
int n, res = 0, p = 0; // p 代表 每个连通块 中 的 靠海 陆地 的数量
const int dx[] = {1, -1, 0, 0}, dy[] = {0, 0, 1, -1};
int dfs(int x, int y)
{
s[x][y] = 'x'; // 用 x 表示 这个 点已经 被访问过了 当然 也可以多开一个 bool 数组 来做这件事
int re = 1;
for (int i = 0 ; i < 4; ++ i) {
int xi = x + dx[i], yi = y + dy[i];
if (s[xi][yi] == '.') { // 只要这个 结点 周围 原来 是 有 海洋 的 那就加1
++p;
break;
}
}
for (int i = 0 ; i < 4; ++ i) { // 如果 有相邻 的陆地 就继续统计
int xi = x + dx[i], yi = y + dy[i];
if (s[xi][yi] == '#')
re += dfs(xi, yi);
}
return re;
}
int main()
{
cin >> n;
for (int i = 0 ; i < n ; ++ i)
scanf("%s", s[i]);
for (int i = 0 ; i < n; ++ i) { // 遍历 每一个 连通块
for (int j = 0 ; j < n; ++ j) {
if (s[i][j] == '#') { //访问陆地
p = 0;
if (dfs( i, j) == p) res ++ ; //如果 这个连通块中 所有 陆地都 和 海 相邻 则会被淹没
}
}
}
cout << res << endl;
return 0;
}
日志统计
思路:贪心 因为是对每一id的时间跨度统计点赞。所以把id的每一个点赞时间分出来统计即可。
1、考虑到 id 的值很小 (1e5) 因此 直接创建一个数组 把所有id装起来,并在里面像拉链法一样 拉出去一条 把时间ts从小到大 的序列
2、因为需要满足的时间区间是 d,我们维持一个首尾差距不大于d的区间 一直滑动检测每一个id的时间(ts 有序排列,由multi_set维持升序)即可。
3检测成功就输出 i 即id号 ,因为i是从小到大遍历 所以直接满足了升序输出
#include<iostream>
#include<set>
#include<queue>
using namespace std;
constexpr int N = 1e5 + 10;
multiset<int> id[N]; // 用multiset 懒得排序了 ,时间复杂度 O(n long n)
int n, d, k, ti, ids;
int main()
{
cin >> n >> d >> k;
for (int i = 0 ; i < n; ++ i) {
scanf("%d%d", &ti, &ids);
id[ids].insert(ti); // 把 t 按从小到大 的顺序 插入 到每一个 id 中
}
for (int i = 0; i < N; ++ i) {
queue<int> q; // 用一个队列 来做 滑动窗口
for (auto &a : id[i]) { // 遍历 每个id 的 所有点赞时间
q.push(a);
if (q.back() - q.front() >= d) q.pop(); // 维持一个 d 时间跨度 的窗口
else if (q.size() >= k) { //k 个 元素 所以 已经 足够 k 个 赞 了 直接输出,break 我们是从小到大 遍历 的,因此输出 也不必排序了。
cout << i << '\n';
break;
}
}
}
return 0;
}
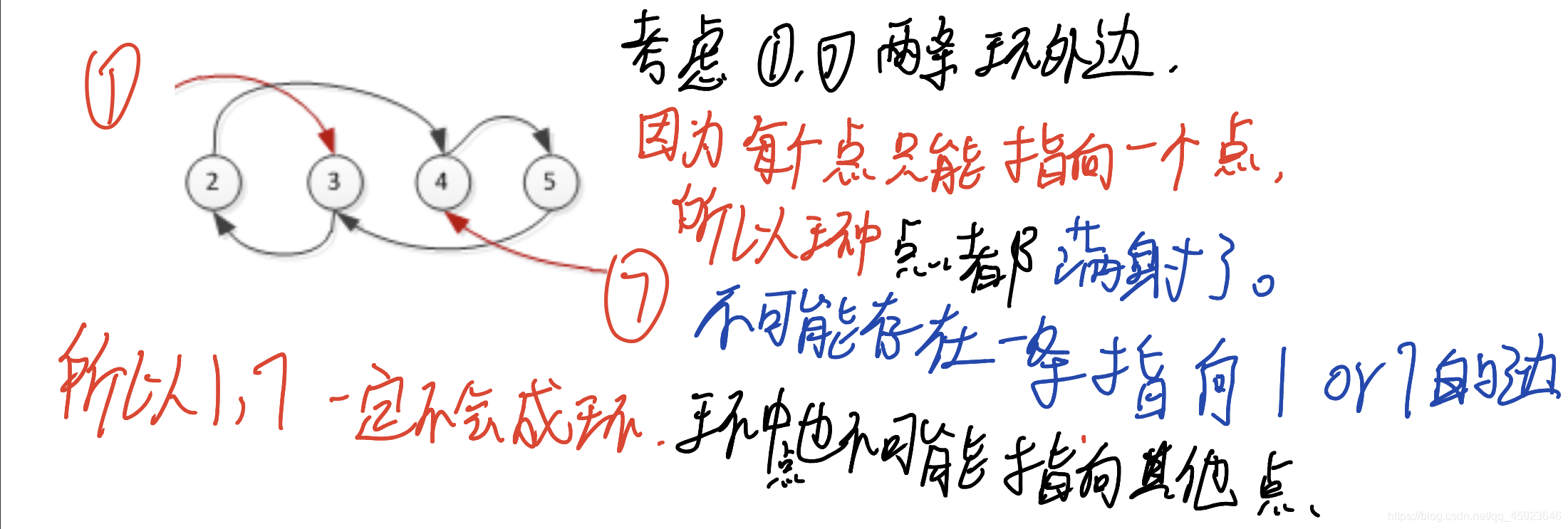
小朋友崇拜圈
思路1: 暴力枚举 :枚举每一个 点 ,再一直遍历下去直到有环,统计最大值O(n^2) 超时了,不过应该起码有一半分吧。
思路2 因为这题有一个很重要的特性,每个点都只会指向一个点,因此我们可以一个环一个环 的枚举(加一个is_loop判断即可)。这样是O(n)的完全可以过,还可以锦上添花一点,环外面指向环的点也不用访问
#include<iostream>
#include<unordered_set>
using namespace std;
constexpr int N = 1e5 + 10;
int e[N], n ;
unordered_set<int> vis;
int is_loop[N];
int main()
{
cin >> n;
int x ; //从这步操作 我们 可以 看出 每个结点 最多 只会 指向 一个结点
for (int i = 1 ; i <= n ; ++ i) scanf("%d", &x), e[i] = x; // i 指向x
int res = 0;
for (int i = 1; i <= n ; ++i) {
if (is_loop[i]||is_loop[i]) continue; // 是环中的点 肯定 不会再有更长的环
vis.insert(i); //寻找 第二次 访问过的点 那就是 环的起点
int pos = i;
for(;vis.find(e[pos]) == vis.end(); pos = e[pos]) //寻找环
vis.insert(pos);
int cnt = 1 ;
auto t = *vis.find(e[pos]); //先处理第一个元素
is_loop[t] = true;
for (int iter = e[t]; iter != t; iter = e[iter], ++cnt) //把这个环中元素 都 置为 true,不再访问 并统计环中元素个数
is_loop[iter] = true;
res = max(res, cnt); //取max
vis.clear(); // vis 每次都针对一个环
}
cout << res << endl;
return 0;
}
更新中…














 7279
7279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









