






目录
我又思考到了一个问题,我们只查询一个字段,如果切换不同的排序条件结果是什么样的,能不能查到,为啥?
在写sql的时候,因为重复数据过多,为了更直观的看到查询效果,采用了distinct关键字进行去重
但是sql后面通过数据采集时间进行排序,结果就出现了报错,去掉distinct关键字则可以查出结果,如下图:
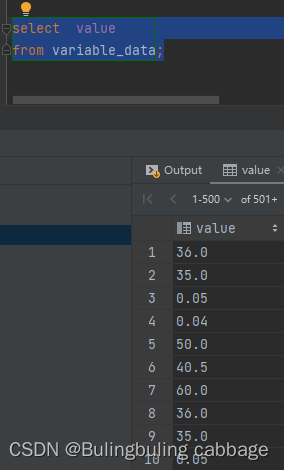
未去重查询数据:
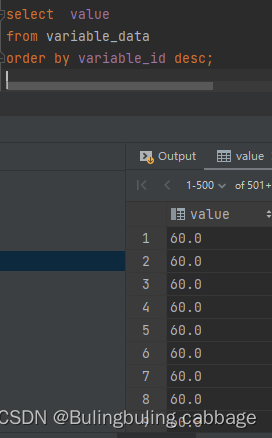
查询数值根据采集时间排序
select value
from variable_data
order by collect_time asc;查询数值和采集时间根据采集时间排序
select value,collect_time
from variable_data
order by collect_time asc;我们可以看到都查询成功且未查询采集时间字段也可以通过采集时间进行排序 然后我们去掉order by ,发现查询结果是一样的
好,没想起来,忘了就去查
ORDER BY
含义:order by 排序字段,
order by默认采用升序(asc),
如果存在 where 子句,那么 order by 必须放到 where 询句后面。
执行顺序
from : 将硬盘上的表文件加载到内存
where: 将符合条件的数据行摘取出来。生成一张新的临时表
group by :根据列中的数据种类,将当前临时表划分成若干个新的临时表
having : 可以过滤掉group by生成的不符合条件的临时表
select : 对当前临时表进行整列读取
order by : 对select生成的临时表,进行重新排序,生成新的临时表
limit : 对最终生成的临时表的数据行,进行截取。
————————————————
版权声明:本文为CSDN博主「前进中的工程师」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/SYSZ520/article/details/116235694
我又思考到了一个问题,我们只查询一个字段,如果切换不同的排序条件结果是什么样的,能不能查到,为啥?
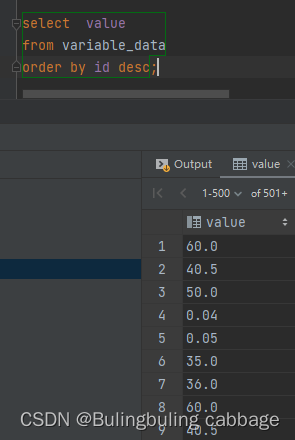
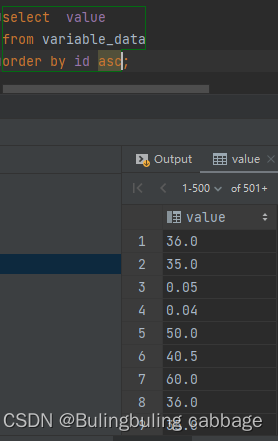
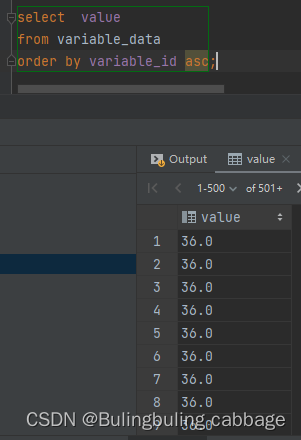
(asc:根据排序字段降序排列, desc:根据排序字段升序排列)
通过两组对比,我们发现这样也是可以行得通的,但是网上没找到想要的资料就采用最原始的方法去翻书,然后就被我发现了黄金屋(参考书籍:MySQL必知必会30页,第五章排序检索数据)
通过非选择列进行排序
通常,order by字句中使用的列将是为显示所选择的列.但是,实际上并不一定要这样,用非检索的列排序数据是完全合法的
意思就是说正常情况下,orderby跟的排序字段,应该是要查找的字段,但是这个字段如果你没有查找(数据表中的字段),也可以作为排序条件,详情参考上图实验对比
去重查询数据:
加上distinct关键字进行去重操作
select distinct value
from variable_data
order by collect_time asc; 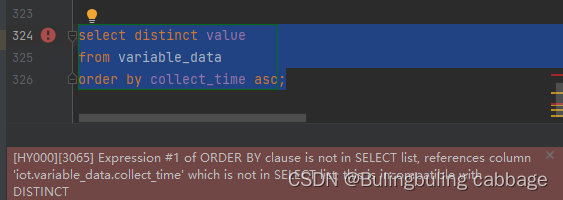
报错信息表明: ORDER BY子句的表达式#1不在SELECT列表中,引用列的数据库的变量数据中collect _time'字段不在SELECT列表中;这是不相容的
通过查询资料了解到,distinct和order by联合使用时,distinct的执行顺序在order by 之前,因此两者同时出现时,先执行distinct产生只包含唯一值的临时表,再对临时表使用order by。
如果order by中的字段和distinct后面的字段名不相同,则语句会出错,因为结果只含有distinct后的唯一字段的值,应在distinct后的字段名中包含order by的字段。
又提到了临时表,那么问题来了,什么叫临时表,在什么情况下又会去创建临时表呢?(转载自https://blog.csdn.net/rubulai/java/article/details/95248627)
一、临时表的概念
在我们操作的表数据量庞大而且又要关联其他表进行查询的时候或者我们操作的数据是临时性数据且在短期内会有很多DML操作(比如购物车)的时候或者我们做查询时需要连接很多个表的时候,如果直接操作数据库的业务表可能效率很低,这个时候我们就可以借助临时表来提升效率。
临时表顾名思义,是一个临时的表,数据库不会将其序列化到磁盘上(有些也会序列化到磁盘上)而是存在于数据库服务器的内存中(因此会增加数据库服务器内存的消耗),在使用完之后就会销毁。临时表分为两种:会话临时表和全局临时表,区别在于可用的作用域和销毁的时机不同。会话临时表只在当前会话(连接)内可用,且在当前会话结束(断开数据库连接)后就会销毁;全局临时表创建后在销毁之前所有用户都可以访问,销毁的时机是在创建该临时表的连接断开且没有其他会话访问时才销毁,实际上在创建全局临时表的会话断开后,其他用户就已经不能在访问该临时表了,但此时该临时表并不会立即销毁,而是等所有正在使用该全局临时表的会话(或者说连接)断开之后才会销毁。当然有时考虑到内存占用的问题,我们也可以手动销毁(DROP)临时表。
目前大多数数据库厂商(Oracle、Sql Server、Mysql)都支持临时表,但不同的数据库创建和使用临时表的语法稍有不同。
二、临时表的创建、使用和删除
1、SQL Server
创建:
方式一:
#会话临时表
CREATE TABLE #临时表名(
字段1 约束条件1,
字段2 约束条件2,
...
);
#全局临时表
CREATE TABLE ##临时表名(
字段1 约束条件,
字段2 约束条件,
...
);
12345678910111213
方式二:
#会话临时表
SELECT 字段列表 INTO #临时表名
FROM 业务表;
#全局临时表
SELECT 字段列表 INTO ##临时表名
FROM 业务表;
1234567
使用:
#查询临时表
SELECT * FROM #临时表名;
SELECT * FROM ##临时表名;
123
删除:
#删除临时表
DROP TABLE #临时表名;
DROP TABLE ##临时表名;
123
2、Mysql
创建:Mysql中没有全局临时表,创建的时候没有#
CREATE TEMPORARY TABLE [IF NOT EXISTS] 临时表名(
字段1 约束条件,
字段2 约束条件,
...
);
#根据现有表创建临时表
CREATE TEMPORARY TABLE [IF NOT EXISTS] 临时表名
[AS] SELECT 查询字段
FROM 业务表
[WHERE 条件];
1234567891011
使用:创建的临时表可以和业务表同名,若临时表和业务表同名时在该会话中会使用临时表
SELECT * FROM 临时表名;
1
删除:为避免临时表名和业务表名相同时导致误删除,可以加上TEMPORARY关键字
DROP [TEMPORARY] TABLE 临时表名;
1
3、Oracle
Oracle的临时表也只有会话级的,但同时又细化出了一个事务级别的临时表,事务级别的临时表只在当前事务中有效。
创建:
#会话级别
CREATE GLOBAL TEMPORARY TABLE 临时表名(
字段1 约束条件,
字段2 约束条件,
...
) ON COMMIT PRESERVE ROWS;
#事务级别
CREATE GLOBAL TEMPORARY TABLE 临时表名(
字段1 约束条件,
字段2 约束条件,
...
) ON COMMIT DELETE ROWS;
12345678910111213
使用:
SELECT * FROM 临时表名;
1
删除:
DROP TABLE 临时表名;
1
注意:一个SQL中不能同时出现两次临时表
三、临时表的应用
企业开发中大多都是使用Spring进行事务管理的,很少自己开启事务、提交事务。我们大多都会将事务加在service层,这样在调用service层的每一个方法之前Spring都会为我们开启事务,在方法调用结束之后Spring会为我们提交事务,问题是数据库事务需要的数据库连接是在什么时候获取和释放的呢?这个是会影响我们对临时表的使用的。
一般来说,数据库连接是在事务开启之前获取的,也就是在我们调用事务方法之前,肯定要先获取数据库连接,然后才能开启事务,提交或回滚事务,然后关闭数据库连接,这种情况下貌似如果我们在该方法中创建了临时表,则在此之后直至方法结束之前我们都可以使用这个创建的临时表,这么说基本上是正确的。但有一种情况除外那就是如果我们在事务方法A中调用了另一个事务方法B,而事务方法B的事务传播机制是PROPAGATION_REQUIRES_NEW(将原事务挂起,并新开一个事务)时,如果临时表是在B方法中创建的,则A在调用完B之后(B的事务已经提交了)也不可以使用B中创建的事务级别的临时表,但是可以使用会话级别的临时表以及全局临时表。
————————————————
版权声明:本文为CSDN博主「如不來」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/rubulai/java/article/details/95248627
并且在以下几种情况查询时会创建临时表
1、UNION查询;
2、用到TEMPTABLE算法或者是UNION查询中的视图;
3、ORDER BY和GROUP BY的子句不一样时;
4、表连接中,ORDER BY的列不是驱动表中的;
5、DISTINCT查询并且加上ORDER BY时;
6、SQL中用到SQL_SMALL_RESULT选项时;
7、FROM中的子查询;
8、子查询或者semi-join时创建的表;
所以当我把采集时间加上后,就查询(且去重)成功了,并根据采集时间排序
select distinct value,collect_time
from variable_data
order by collect_time asc;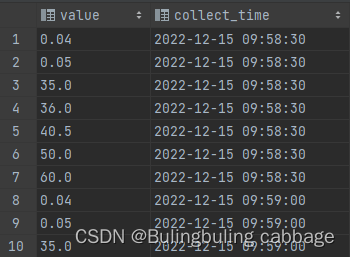
总结(大佬建议):
order by默认是走主键。如果你选定的order by字段不是索引,就会回表遍历所有数据进行排序
distinct是根据排序去重的,有不可预知性
两者慎用(好吧,还是我太菜了,没有接触到那个层面)














 1439
1439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









