






在当今的数据驱动的世界中,Python 凭借其强大的功能和丰富的库,成为了处理和分析数据的重要工具。能够准确高效地读取各种类型的数据对于后续的数据分析、挖掘和应用开发至关重要。
数据的来源和格式多种多样,包括文本文件(如 CSV 和 TXT )、Excel 文件、SPSS 数据文件以及 Stata 数据文件等。不同的文件格式有着各自的特点和应用场景。
例如,CSV 和 TXT 文件常用于简单的数据存储和交换,具有格式简洁、易于创建和编辑的优点;Excel 文件则在办公和商业环境中广泛使用,能够容纳复杂的表格结构和数据格式;SPSS 和 Stata 数据文件则常见于专业的统计分析领域。
在 Python 中,我们需要掌握相应的方法和函数来读取这些不同格式的数据。通过正确地使用相关的库和函数,如 pandas 库中的 read_csv 、 read_table 、 read_excel 等函数,以及其他专门用于读取特定格式数据的函数,我们能够将数据顺利地加载到 Python 环境中,为进一步的处理和分析奠定基础。
无论是进行学术研究、商业分析还是开发数据驱动的应用程序,熟练掌握在 Python 中读取各种数据格式的技能都是必不可少的。
1 读取文本文件(CSV或者TXT文件)
读取CSV或者TXT文件需要用到pandas模块中的pd.read_csv()函数或者pd.read_table()函数,其中pd.read_csv()函数主要用来读取CSV文件,而pd.read_table()函数主要用来读取TXT文件。
pd.read_csv()函数的基本语法格式如下:
pd.read_csv('文件.csv',sep=',')其中的参数sep用于指定分隔符,一定要与拟读取的CSV文件中实际的分隔符完全一致,若不设置则默认的分隔符为英文状态下的逗号(即半角逗号)。
常用的分隔符如表所示。

pd.read_table()函数的基本语法格式如下:
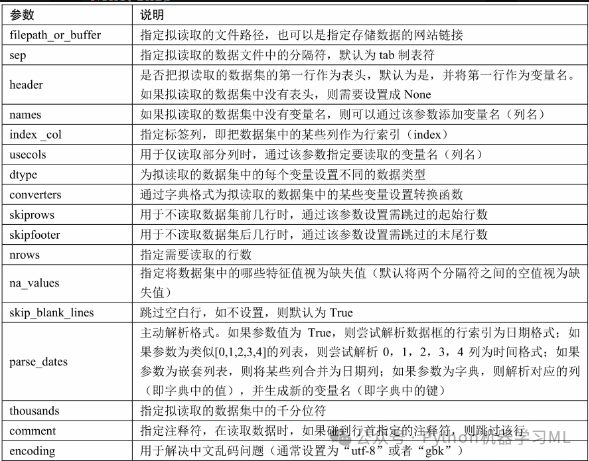
pd.read_table('文件.txt',sep='\t')pd.read_table(filepath_or_buffer,sep='\t',header='infer',names=None,index_col=None,usecols=None,dtype=None,converters=None,skiprows=None,skipfooter=None,nrows=None,na_values=None,skip_blank_lines=True,parse_dates=False,thousands=None,comment=None,encoding=None)参数说明如表所示。
下面以示例的方式进行讲解。输入以下代码并逐行运行:
import pandas as pd # 导入pandas模块并简称为pd
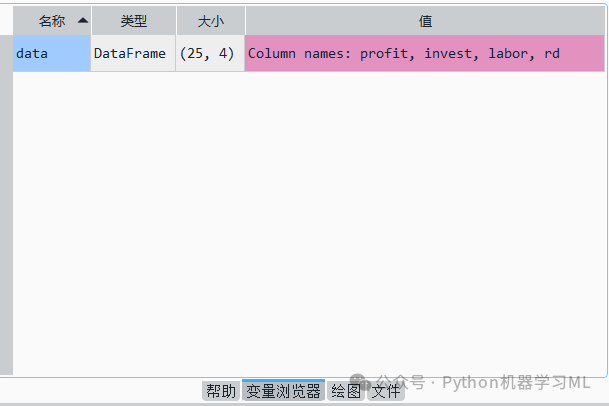
data=pd.read_csv('C:/Users/Administrator/.spyder-py3/数据4.1.csv') # 从设置路径中读取数据4.1文件,数据4.1文件为.csv格式注意,因用户的具体安装路径不同,代码会有所差异。成功载入后,可在Spyder的变量管理器界面找到载入的data数据文件,双击数据文件名data即可打开数据文件,如图所示。
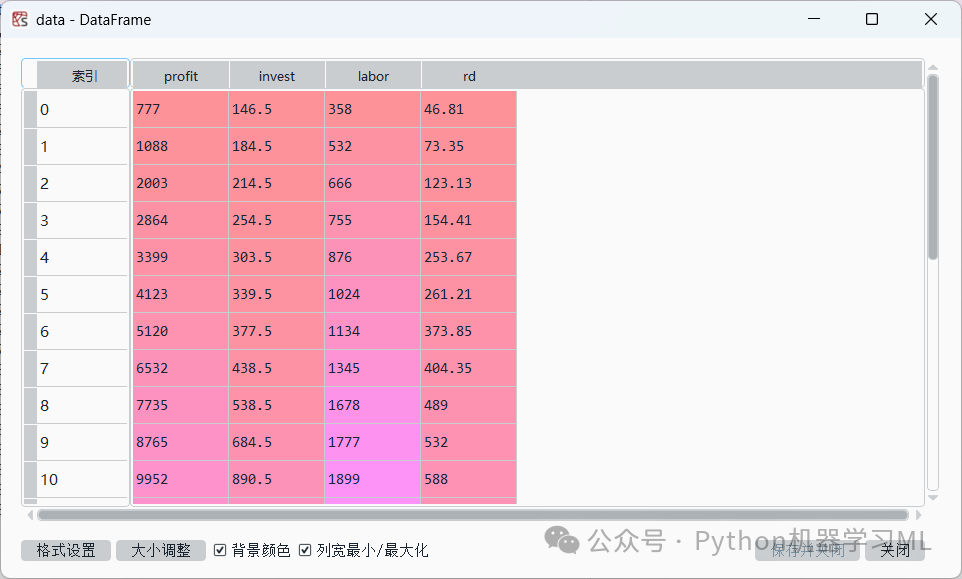
数据4.1.csv
调用pd.read_csv()函数可以直接读取CSV文件。下面我们尝试调用pd.read_csv()函数直接读取TXT文件。
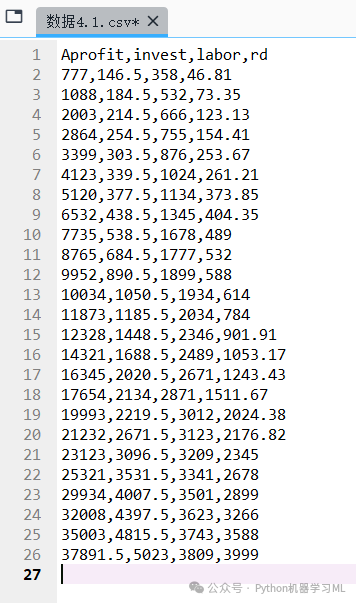
data=pd.read_csv('C:/Users/Administrator/.spyder-py3/数据4.1.txt') # 从设置路径中读取数据4.1文件,数据4.1文件为.txt格式运行结果如图所示。从图中可以发现由于没有正确指定分隔符,因此数据没能够被正确读取。
数据4.1.txt
将分隔符设置为'\t'后,数据就能够被正确读取了.
data=pd.read_csv('C:/Users/Administrator/.spyder-py3/数据4.1.txt',sep='\t') # 从设置路径中读取数据4.1文件,数据4.1文件为.txt格式
将分隔符设置为'\s+'后,数据同样被正确读取.
data=pd.read_csv('C:/Users/Administrator/.spyder-py3/数据4.1.txt',sep='\s+') # 从设置路径中读取数据4.1文件,数据4.1文件为.txt格式
调用pd.read_table()函数,不必设置分隔符也可正确读取TXT数据文件
data=pd.read_table('C:/Users/Administrator/.spyder-py3/数据4.1.txt') # 从设置路径中读取数据4.1文件,数据4.1文件为.txt格式
从设置路径中读取数据4.1文件,数据4.1文件为.csv格式,但不把第一行作为表头。
data=pd.read_csv('C:/Users/Administrator/.spyder-py3/数据4.1.csv', header=None) 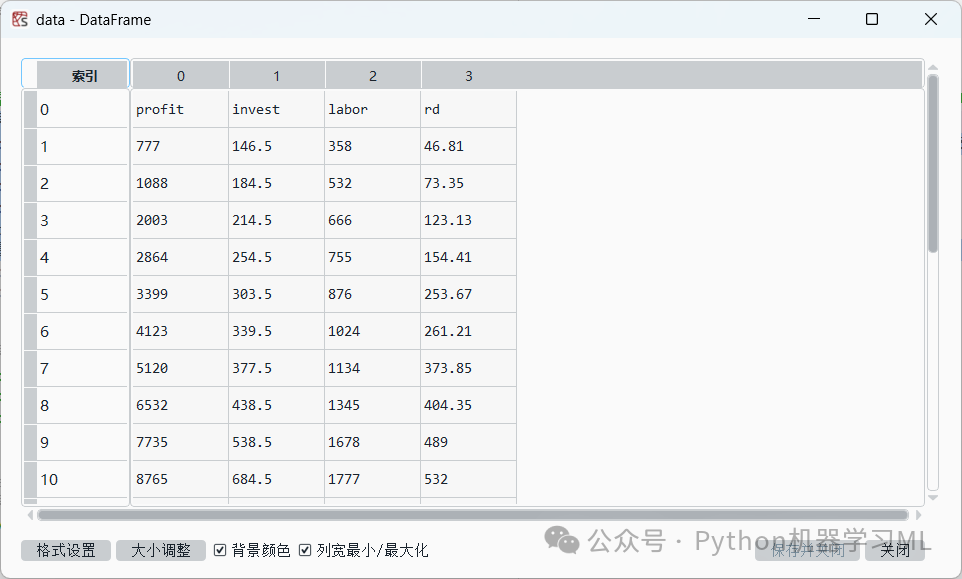
此外,很多时候我们需要摒弃数据集原来的变量名(可能是因为原来的变量名设置不合理、有错误、过长等),就需要设置新的变量名。
data=pd.read_csv('C:/Users/Administrator/.spyder-py3/数据4.1.csv',names = ['V1', 'V2','V3', 'V4']) # 从设置路径中读取数据4.1文件,数据4.1文件为.csv格式,把变量名分别设置为'V1', 'V2', 'V3','V4'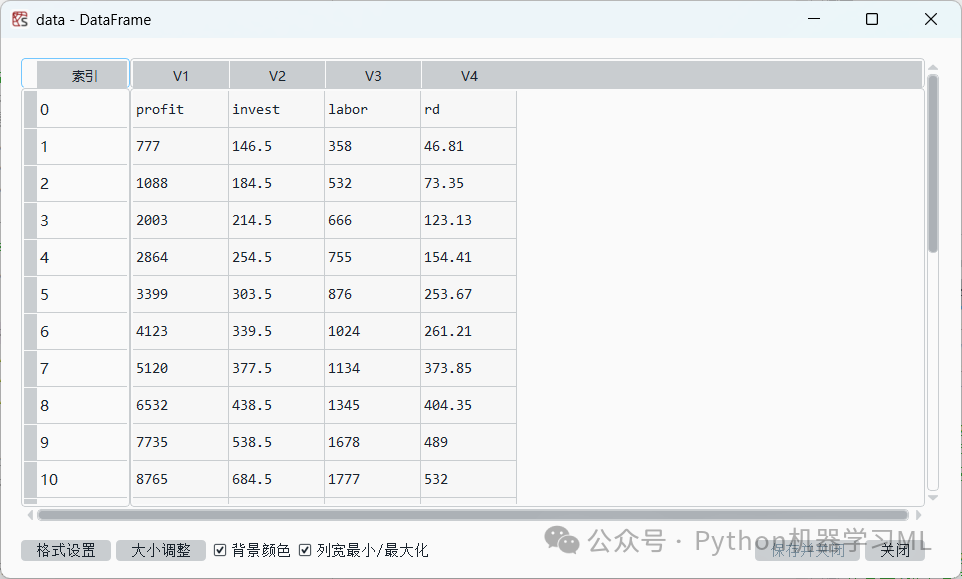
运行结果如图上图所示。可以发现上述设置并没有达到想要的效果,代码应该为:从设置路径中读取数据4.1文件,数据4.1文件为.csv格式,跳过第一行不读取,并且把变量名分别设置为'V1', 'V2', 'V3', 'V4'
data=pd.read_csv('C:/Users/Administrator/.spyder-py3/数据4.1.csv', skiprows=[0],names =['V1', 'V2', 'V3', 'V4'])) 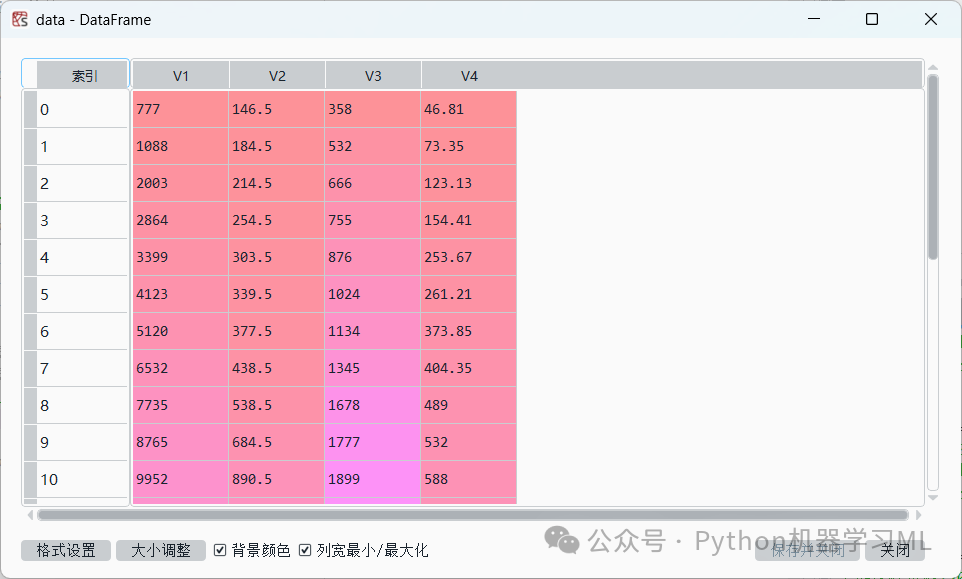
2 读取excel数据
import pandas as pd#导入pandas模块,并简称为pd
data=pd.read_excel('C:/Users/Administrator/.spyder-py3/数据4.1.xlsx')
data=pd.read_excel('C:/Users/Administrator/.spyder-py3/数据4.1.xlsx',sheet_name='数据4.1副本') # 读取某个sheet表
data=pd.read_excel('C:/Users/Administrator/.spyder-py3/数据4.1.xlsx')[['profit','invest']] # 读取并筛选几列3 读取spss数据
#pip install --upgrade pyreadstat#安装pyreadstat,大家在运行时把最前面的#号去掉
import pandas as pd#导入pandas模块,并简称为pd
data=pd.read_spss('C:/Users/Administrator/.spyder-py3/数据7.1.sav')4 读取stata数据
import pandas as pd#导入pandas模块,并简称为pddata=pd.read_stata('C:/Users/Administrator/.spyder-py3/数据8.dta')















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









