








论文地址:PETR: Position Embedding Transformation for Multi-View 3D Object Detection
源代码:PETR
摘要:本文开发了用于多视角3D目标检测的位置嵌入变换(PETR)。PETR将3D坐标的位置信息编码到图像特征中,生成具有3D位置感知能力的特征。目标查询(object query)可以感知这些3D位置感知特征,并执行端到端的目标检测。PETR在标准的nuScenes数据集上达到了最先进的性能(NDS为50.4%,mAP为44.1%),并在基准测试中排名第1位。它可以作为未来研究的一个简单而强大的基线模型。
关键词:位置嵌入、Transformer、3D目标检测
1 导言
从多视角图像中进行3D目标检测因其在自动驾驶系统中的低成本而备受关注。以往的研究工作[6,33,49,34,48]主要从单目目标检测的角度解决这一问题。最近,DETR[4]因其在端到端目标检测方面的贡献而受到广泛关注。在DETR[4]中,每个目标查询代表一个目标,并在Transformer解码器中与2D特征交互以生成预测结果(见图1(a))。从DETR[4]框架简单扩展而来的DETR3D[51]为端到端3D目标检测提供了一种直观的解决方案。目标查询预测的3D参考点通过相机参数重新投影到图像空间,并用于从所有相机视图中采样2D特征(见图1(b))。解码器将采样后的特征和查询作为输入,并更新目标查询的表示。然而,DETR3D[51]中的这种2D到3D的转换可能会引入几个问题。首先,参考点的预测坐标可能不够准确,导致采样的特征超出目标区域。其次,仅收集投影点处的图像特征,无法从全局视角进行表示学习。此外,复杂的特征采样过程也会阻碍检测器的实际应用。因此,构建一个无需在线2D到3D转换和特征采样的端到端3D目标检测框架仍然是一个亟待解决的问题。
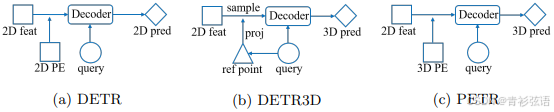
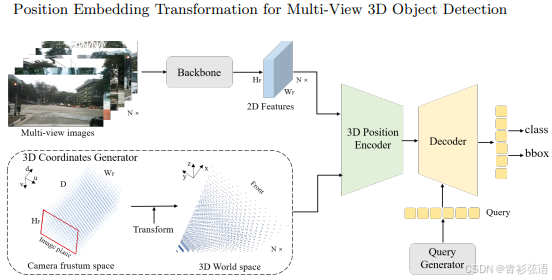
在本文中,我们旨在基于DETR[4]开发一个简单而优雅的3D目标检测框架。我们思考是否有可能将多视角的2D特征转换为具有3D感知能力的特征。这样,目标查询就可以直接在3D环境中进行更新。我们的工作受到隐式神经表示方面进展的启发[17,8,32]。在MetaSR[17]和LIFF[8]中,通过将高分辨率(HR)坐标信息编码到低分辨率(LR)特征中,从而生成任意大小的HR RGB值。在本文中,我们尝试通过编码3D位置嵌入将多视角图像的2D特征转换为3D表示(见图1(c))。为此,首先将不同视图共享的相机视锥空间离散化为网格坐标,然后通过不同相机参数转换坐标,以获得3D世界空间中的坐标。随后,将从backbone提取的2D图像特征和3D坐标输入到一个简单的3D位置编码器中,以生成具有3D感知能力的特征。这些具有3D感知能力的特征将与Transformer解码器中的目标查询进行交互,而更新后的目标查询则进一步用于预测目标类别和3D边界框。与DETR3D[51]相比,所提出的PETR架构具有诸多优势。它保留了原始DETR[4]的端到端特性,同时避免了复杂的2D到3D投影和特征采样。在推理阶段,3D位置坐标可以离线生成,并作为额外的输入位置嵌入。这使得该方法更易于实际应用。总的来说,我们的贡献包括:
-
我们提出了一个简单而优雅的框架,称为PETR,用于多视角3D目标检测。通过将3D坐标编码到多视角特征中,将特征转换到3D域。目标查询可以通过与具有3D感知能力的特征交互来更新,并生成3D预测结果。
-
为多视角3D目标检测引入了一种新的具有3D感知能力的表示方法。引入了一个简单的隐式函数,用于将3D位置信息编码到2D多视角特征中。
-
实验证明PETR在标准nuScenes数据集上达到了最先进的性能(NDS为50.4%,mAP为44.1%),并在3D目标检测排行榜上排名第1位。
2 相关工作
2.1 基于Transformer的目标检测
Transformer [47] 是一种广泛应用于建模长距离依赖的注意力模块。在Transformer中,特征通常会添加位置嵌入,以提供图像 [13,53,27]、序列 [15,47,11,10,54] 和视频 [1,24,52] 的位置信息。Transformer-XL [10] 使用相对位置嵌入来编码成对标记之间的相对距离。ViT [13] 将学习到的位置嵌入添加到补丁表示中,以编码不同补丁之间的距离。MViT [24] 分解了相对位置嵌入的距离计算,并对时空结构进行建模。最近,DETR [4] 将Transformer引入2D目标检测任务中,用于端到端检测。在DETR [4] 中,每个目标由一个目标查询表示,该查询通过Transformer解码器与2D图像特征交互。然而,DETR [4] 的收敛速度较慢。[44] 将这种缓慢的收敛归因于交叉注意力机制,并设计了一个仅编码器的DETR。此外,许多工作通过添加位置先验来加速收敛。SMAC [14] 预测每个查询的2D高斯权重图作为空间先验。Deformable DETR [58] 将目标查询与2D参考点关联,并提出可变形交叉注意力以执行稀疏交互。[50,30,26] 从锚点或锚框生成目标查询,使用位置先验实现快速收敛。SOLQ [12] 扩展自DETR [58],使用目标查询同时执行分类、边界框回归和实例分割。
2.2 基于视觉的3D目标检测
基于视觉的3D目标检测是从相机图像中检测3D边界框。许多先前的工作 [6,33,20,21,41,19,2,49,48] 在图像视图中执行3D目标检测。M3D-RPN [2] 引入了深度感知卷积,学习用于3D目标检测的位置感知特征。FCOS3D [49] 将3D真值转换到图像视图,并扩展FCOS [46] 以预测3D立方体参数。PGD [48] 遵循FCOS3D [49],使用概率表示来捕获深度的不确定性。它在很大程度上缓解了深度估计问题,同时引入了更多的计算预算和更大的推理延迟。DD3D [34] 表明,在大规模深度数据集上进行深度预训练可以显著提高3D目标检测的性能。最近,一些工作尝试在3D世界空间中进行3D目标检测。OFT [39] 和 CaDDN [38] 将单目图像特征映射到鸟瞰图(BEV),并在BEV空间中检测3D目标。ImVoxelNet [40] 在3D世界空间中构建一个3D体素,并采样多视角特征以获得体素表示。然后使用3D卷积和特定领域的头部在室内外场景中检测目标。类似于CaDDN [38],BEVDet [18] 使用Lift-Splat-Shoot [37] 将2D多视角特征转换为BEV表示。有了BEV表示后,使用CenterPoint [55] head以直观的方式检测3D目标。遵循DETR [4],DETR3D [51] 将3D目标表示为目标查询。由目标查询生成的3D参考点反复投影回所有相机视图,并采样2D特征。基于BEV的方法倾向于引入Z轴误差,导致在其他3D感知任务(例如3D车道检测)中表现不佳。基于DETR的方法可以从端到端建模中获得更多好处,并使用更多的训练增强。我们的方法是基于DETR的,以简单有效的方式检测3D目标。我们将3D位置信息编码到2D特征中,生成具有3D感知能力的特征。目标查询可以直接与这种3D感知表示交互,而无需投影误差。
2.3 隐式神经表示
隐式神经表示(INR)通常通过多层感知器(MLP)将坐标映射到视觉信号,这是一种高效建模3D对象 [35,9,31]、3D场景 [32,43,5,36] 和2D图像 [17,8,45,42] 的方法。NeRF [32] 使用全连接网络来表示特定场景。为了合成新视图,沿相机光线的5D坐标作为查询输入到网络中,并输出体积密度和视图依赖的辐射强度。在MetaSR [17] 和 LIFF [8] 中,HR坐标被编码到LR特征中,可以生成任意大小的HR图像。我们的方法可以被视为3D目标检测中INR的扩展。2D图像被编码了3D坐标,以获得具有3D感知能力的特征。3D空间中的锚点通过MLP转换为目标查询,并进一步与具有3D感知能力的特征交互,以预测相应的3D目标。
3 方法
3.1 总体架构
图2展示了所提出的PETR的整体架构。给定来自N个视角的图像 ![]() ,这些图像被输入到主干网络(例如ResNet-50 [16])中,以提取2D多视角特征
,这些图像被输入到主干网络(例如ResNet-50 [16])中,以提取2D多视角特征 ![]() 。在3D坐标生成器中,首先将相机视锥空间离散化为一个3D网格。然后,通过相机参数变换网格坐标,生成3D世界空间中的坐标。将3D坐标与2D多视角特征一起输入到3D位置编码器中,生成具有3D感知能力的特
。在3D坐标生成器中,首先将相机视锥空间离散化为一个3D网格。然后,通过相机参数变换网格坐标,生成3D世界空间中的坐标。将3D坐标与2D多视角特征一起输入到3D位置编码器中,生成具有3D感知能力的特![]() 。这些3D特征进一步输入到Transformer解码器中,并与由查询生成器生成的目标查询进行交互。更新后的目标查询用于预测目标类别以及3D边界框。
。这些3D特征进一步输入到Transformer解码器中,并与由查询生成器生成的目标查询进行交互。更新后的目标查询用于预测目标类别以及3D边界框。
3.2 3D坐标生成器
为了建立2D图像与3D空间之间的关系,我们将相机视锥空间中的点投影到3D空间,因为这两个空间之间的点是一一对应的。类似于DGSN [7],我们首先将相机视锥空间离散化,生成一个大小为 (,
,D) 的3D网格。网格中的每个点可以表示为
![]() ,其中 (
,其中 (,
) 是图像中的像素坐标,
是沿图像平面法线方向的深度值。由于网格被不同视角共享,可以通过逆3D投影计算出3D世界空间中对应的3D坐标
![]() :
:
![]()
其中 ∈
是第i个视角的变换矩阵,用于建立3D世界空间与相机视锥空间之间的变换关系。如图2所示,经过变换后,所有视角的3D坐标覆盖了场景的全景。我们进一步按照公式(2)对3D坐标进行归一化:
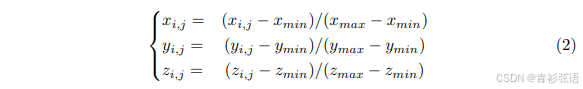
其中 [,
,
,
,
,
] 是3D世界空间中的感兴趣区域(RoI)。最终,将
×
×D 个点的归一化坐标转置为
![]()
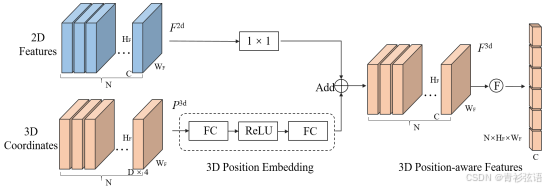
3.3 3D位置编码器
3D位置编码器的目的是通过将2D图像特征 ={
∈
,i=1,2,…,N} 与3D位置信息关联起来,生成具有3D感知能力的特征
={
∈
,i=1,2,…,N}。类似于MetaSR [17],3D位置编码器可以表示为:
![]()
其中 ψ(⋅) 是位置编码函数,如图3所示。接下来,我们描述 ψ(⋅) 的具体实现。给定2D特征 和3D坐标
,首先将
输入到一个多层感知器(MLP)网络中,将其转换为3D位置嵌入(PE)。然后,通过一个 1×1 卷积层将2D特征
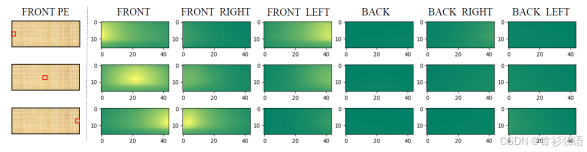
进行变换,并与3D PE相加,从而生成具有3D感知能力的特征。最后,将这些具有3D感知能力的特征展平,作为Transformer解码器的关键组成部分。关于3D PE的分析:为了展示3D PE的效果,我们在前视图中随机选择三个点的位置嵌入,并计算这些点与所有多视角PE之间的相似度。如图4所示,靠近这些点的区域倾向于具有更高的相似度。例如,当我们选择前视图中的左侧点时,前左视图的右侧区域将具有相对较高的响应。这表明3D PE隐式地建立了不同视角在3D空间中的位置相关性。
3.4 查询生成器和解码器
Query生成器:原始DETR [4] 直接使用一组可学习的参数作为初始目标queries。类似于Deformable-DETR [58],DETR3D [51] 基于初始化的目标queries预测参考点。为了缓解3D场景中的收敛困难,类似于Anchor-DETR [50],我们首先在3D世界空间中以均匀分布的方式初始化一组可学习的锚点,范围从0到1。然后将3D锚点的坐标输入到一个包含两个线性层的小型MLP网络中,生成初始目标queries 。在实践中,采用3D空间中的锚点可以保证PETR的收敛,而采用DETR中的设置或在BEV空间中生成锚点则无法实现令人满意的检测性能。更多细节请参考我们的实验部分。
Decoder:对于decoder网络,我们遵循DETR [4] 中的标准Transformer decoder,包括L层decoder。这里,我们将decoder层中的交互过程表示为:
![]()
其中是第l层的decoder。
∈
是第l层更新后的目标queries。M和C分别表示queries的数量和通道数。在每一层decoder中,目标queries通过多头注意力和前馈网络与具有3D感知能力的特征进行交互。经过迭代交互后,更新后的目标queries具有高级表示,可用于预测相应的目标。
3.5 Head and Loss
head主要包括用于分类和回归的两个分支。来自decoder的更新后目标查询被输入到head中,以预测目标类别的概率以及3D边界框。注意,回归分支预测的是相对于锚点坐标的相对偏移量。为了与DETR3D进行公平比较,我们还采用了分类的Focal Loss [25] 和3D边界框回归的L1 loss。设 y=(c,b) 和 =(
,
) 分别表示一组真值和预测值。使用匈牙利算法 [22] 进行真值和预测值之间的标签分配。假设 σ 是最优分配函数,则3D目标检测的loss可以总结为:
![]()
其中 表示分类的Focal Loss,
是3D边界框回归的L1 loss。
是一个超参数,用于平衡不同损失。
4 实验
4.1 数据集和评估指标
我们在 nuScenes 基准测试 [3] 上验证了我们的方法。nuScenes 是一个大规模的多模态数据集,包含来自 6 个cameras、1 个lidar和 5 个radars的数据。该数据集包含 1000 个场景,官方将其划分为 700/150/150 个场景,分别用于训练、验证和测试。每个场景包含 20 秒的视频帧,并且每 0.5 秒对 3D 边界框进行完整标注。与官方评估指标一致,我们报告 nuScenes 检测分数(NDS)和平均精度均值(mAP),以及平均平移误差(mATE)、平均尺度误差(mASE)、平均方向误差(mAOE)、平均速度误差(mAVE)和平均属性误差(mAAE)。
4.2 实现细节
为了提取 2D 特征,我们使用 ResNet [16]、Swin-Transformer [27] 或 VoVNetV2 [23] 作为backbone。C5 特征(第 5 阶段的输出)被上采样并与 C4 特征(第 4 阶段的输出)融合,以生成 P4 特征。使用 1/16 输入分辨率的 P4 特征作为 2D 特征。对于 3D 坐标生成,我们遵循 CaDDN [38] 中的线性递增离散化(LID),沿深度轴采样 64 个点。我们将 X 和 Y 轴的区域设置为 [−61.2m, 61.2m],Z 轴的区域设置为 [−10m, 10m]。3D 世界空间中的坐标被归一化到 [0, 1]。遵循 DETR3D [51],我们将分类和回归的平衡参数 设置为 2.0。PETR 使用 AdamW [29] 优化器进行训练,权重衰减为 0.01。学习率初始化为 2.0×
,并采用余弦退火策略 [28] 进行衰减。采用多尺度训练策略,较短边随机选择在 [640, 900] 范围内,较长边不超过 1600。遵循 CenterPoint [55],实例的真值在 3D 空间中随机旋转,范围为 [−22.5°, 22.5°]。所有实验在 8 块 Tesla V100 GPU 上进行 24 个epochs(2x schedule)的训练,batch size为 8。在推理过程中未使用测试时增强方法。
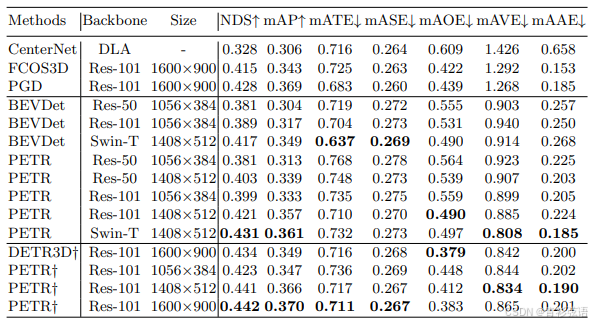
表1:nuScenes验证集上最近工作的比较。FCOS3D和PGD的结果经过微调,并使用测试时增强进行测试。DETR3D、BEVDet和PETR使用CBGS [57]进行训练。†表示从FCOS3D主干网络初始化。
4.3 与最先进方法的比较
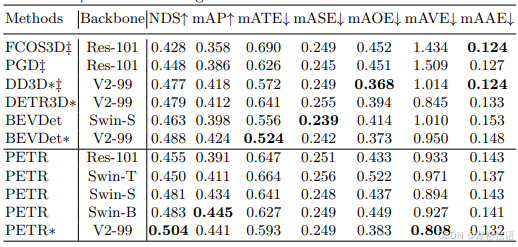
如表1所示,我们首先在 nuScenes 验证集上与最先进方法进行性能比较。结果显示 PETR 在 NDS 和 mAP 指标上均取得了最佳性能。CenterNet [56]、FCOS3D [49] 和 PGD [48] 是典型的单目 3D 目标检测方法。与 FCOS3D [49] 和 PGD [48] 相比,使用 ResNet-101 [16] 的 PETR 在 NDS 上分别超过了它们 2.7% 和 1.4%。然而,PGD [48] 由于明确的深度监督,实现了相对较低的 mATE。此外,我们还将 PETR 与多视角 3D 目标检测方法 DETR3D [51] 和 BEVDet [18] 进行了比较,它们在统一视图中检测 3D 目标。由于 DETR3D [51] 和 BEVDet [18] 在图像大小和主干初始化方面遵循不同的设置,我们分别与它们进行比较以确保公平性。我们的方法在 NDS 上分别超过了它们 0.8% 和 1.4%。表2展示了在 nuScenes 测试集上的性能比较。我们的方法在 NDS 和 mAP 上也取得了最佳性能。为了与 BEVDet [18] 进行公平比较,使用 Swin-S 主干和 2112×768 图像大小的 PETR 也进行了训练。结果显示,PETR 在 mAP 上超过了 BEVDet [18] 3.6%,在 NDS 上超过了 1.8%。值得注意的是,使用外部数据时,PETR 的性能与现有方法相当。当使用外部数据时,使用 VoVNetV2 [23] 主干的 PETR 实现了 50.4% 的 NDS 和 44.1% 的 mAP。据我们所知,PETR 是第一个超过 50.0% NDS 的基于视觉的方法。
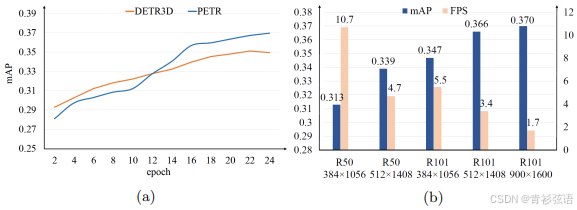
表2:nuScenes测试集上的最近工作比较。* 表示使用外部数据训练。‡ 表示测试时增强。
我们还对 PETR 的收敛性和检测速度进行了分析。我们首先比较了 DETR3D [51] 和 PETR 的收敛性(见图5(a))。PETR 在前12个周期内比 DETR3D [51] 收敛得慢,但最终实现了更好的检测性能。这表明 PETR 需要更长的训练周期才能完全收敛。我们猜测原因是 PETR 通过全局注意力学习 3D 相关性,而 DETR3D [51] 在局部区域内感知 3D 场景。图5(b) 进一步报告了 PETR 在不同输入尺寸下的检测性能和速度。FPS 在单个 Tesla V100 GPU 上测量。对于相同的图像尺寸(例如,1056×384),我们的 PETR 推理速度为 10.7 FPS,而 BEVDet [18] 为 4.2 FPS。需要注意的是,BEVDet [18] 的速度是在 NVIDIA 3090 GPU 上测量的,该 GPU 比 Tesla V100 更强大。
表3:3D位置嵌入的影响。2D PE是DETR中常用的位置嵌入。MV是用于区分不同视图的多视角位置嵌入。3D PE是本文提出的方法中的3D位置嵌入。
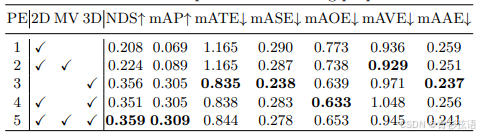
表4:不同离散化方法和感兴趣区域(ROI)范围对3D坐标归一化的影响分析。UD表示均匀离散化,LID表示线性递增离散化。

4.4 消融研究
在本节中,我们对 PETR 的一些重要组成部分进行了消融研究。所有实验均使用 ResNet-50 主干的单级 C5 特征进行,且不使用 CBGS [57]。
3D位置嵌入的影响:我们评估了不同位置嵌入(PE)的效果(见表3)。当仅使用 DETR 中的普通 2D PE 时,模型仅能收敛到 6.9% 的 mAP。然后,我们添加了多视角先验(将视图数量转换为 PE)以区分不同视图,带来了轻微的改进。当仅使用由 3D 坐标生成的 3D PE 时,PETR 可以直接实现 30.5% 的 mAP。这表明 3D PE 为感知 3D 场景提供了强大的位置先验。此外,当我们将 3D PE 与 2D PE 和多视角先验结合使用时,性能得到了提升。值得注意的是,主要改进来自 3D PE,而 2D PE/多视角先验可以根据实际情况选择性使用。
3D坐标生成器:在 3D 坐标生成器中,相机视锥空间的透视视图被离散化为 3D 网格。然后,通过感兴趣区域(RoI)对 3D 世界空间中的变换坐标进行归一化。在这里,我们探索了不同离散化方法和 RoI 范围的效果(见表4)。均匀离散化(UD)与线性递增离散化(LID)相比表现相似。我们还尝试了几种常见的 RoI 区域,范围为 (−61.2m, −61.2m, −10.0m, 61.2m, 61.2m, 10.0m) 的 RoI 区域比其他区域表现更好。
表5:所提出的PETR中不同组件的消融研究
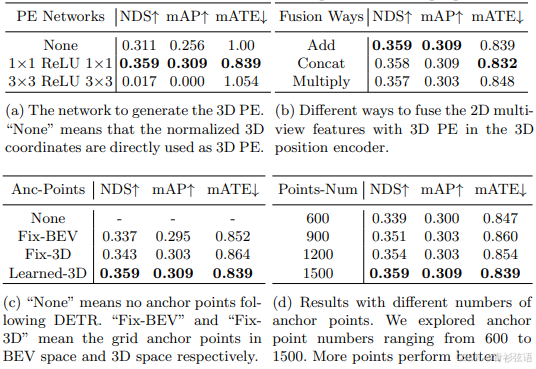
3D位置编码器:3D位置编码器用于将 3D 位置编码到 2D 特征中。在这里,我们首先探索将 3D 坐标转换为 3D 位置嵌入的多层感知器(MLP)的效果。如表5(a)所示,使用简单 MLP 的网络与仅对齐 2D 特征通道数的基线相比,可以在 NDS 和 mAP 上分别提高 4.8% 和 5.3% 的性能。当使用两个 3×3 卷积层时,模型将无法收敛,因为 3×3 卷积破坏了 2D 特征与 3D 位置之间的对应关系。此外,我们在表5(b)中比较了在 3D 位置编码器中将 2D 图像特征与 3D PE 融合的不同方式。与add融合相比,concat操作实现了相似的性能,同时超过了multi融合。
Query生成器:表5(c)展示了不同锚点对生成查询的影响。在这里,我们比较了四种类型的锚点:“None”、“Fix-BEV”、“Fix-3D” 和 “Learned-3D”。原始 DETR(“None”)直接使用一组可学习的参数作为目标查询,而不使用锚点。全局特征的目标查询使模型无法收敛。“Fix-BEV” 是在 BEV 空间中生成的固定锚点,数量为 39×39。“Fix-3D” 是在 3D 世界空间中生成的固定锚点,数量为 16×16×6。“Learned-3D” 是在 3D 空间中定义的可学习锚点。我们发现“Fix-BEV” 和 “Fix-3D” 的性能都低于可学习锚点。我们还探索了锚点的数量(见表5(d)),范围从 600 到1500。模型在使用1500个锚点时达到了最佳性能。考虑到随着锚点数量的增加,计算成本也在增加,我们简单地选择使用1500个锚点来进行权衡。


4.5 可视化
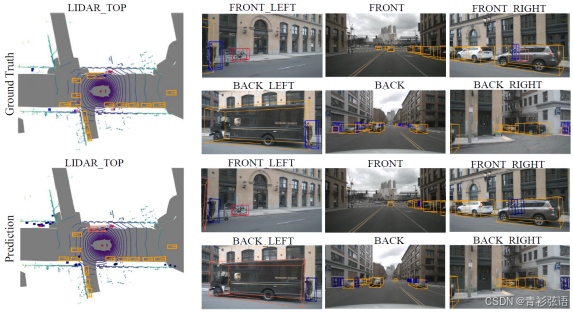
图 6 展示了一些定性的检测结果。3D边界框被投影并在鸟瞰图(BEV)空间和图像视图中绘制。如鸟瞰图所示,预测的边界框与真值非常接近,这表明我们的方法实现了良好的检测性能。我们还可视化了来自多视角图像的对象查询生成的注意力图。如图 7 所示,对象查询倾向于关注同一对象,即使在不同的视角中也是如此。这表明3D位置编码能够建立不同视角之间的位置相关性。最后,我们提供了一些失败案例(见图 8)。失败案例用红色和绿色圆圈标记。红色圆圈显示了一些未被检测到的小物体。绿色圆圈中的物体被错误分类。错误检测主要发生在不同车辆在外形上具有高度相似性时。
5 结论
本文为多视角3D目标检测提供了一种简单而优雅的解决方案。通过3D坐标的生成和位置编码,2D特征可以被转化为具有3D位置感知的特征表示。这种3D表示可以直接整合到基于查询的 DETR 架构中,并实现端到端的检测。该方法达到了最先进的性能水平,并可作为未来研究的有力基准。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









