








论文地址: MAPTR: STRUCTURED MODELING AND LEARNING FOR ONLINE VECTORIZED HD MAP CONSTRUCTION
源代码:MapTR
摘要
High-definition(HD Map)map为自动驾驶场景提供了丰富且精确的环境信息,是自动驾驶系统规划中不可或缺的基础组件。本文提出了 MapTR,一种用于高效在线矢量化高精地图构建的结构化端到端 Transformer 模型。我们提出了一种统一的排列等价建模方法,即将地图元素建模为一组等价排列的点集,从而准确描述地图元素的形状并稳定学习过程。我们设计了一种层次化的查询嵌入方案,用于灵活编码结构化的地图信息,并通过层次化的二分图匹配进行地图元素学习。MapTR 在 nuScenes 数据集上仅使用摄像头输入,就实现了现有矢量化地图构建方法中最佳的性能和效率。特别是,MapTR-nano 在 RTX 3090 上的实时推理速度达到 25.1 FPS,比现有的基于摄像头的最先进方法快 8 倍,同时平均精度(mAP)高出 5.0。即使与现有的多模态方法相比,MapTR-nano 的 mAP 高出 0.7,MapTR-tiny 的 mAP 高出 13.5,且推理速度比现有方法快 3 倍。丰富的定性结果表明,MapTR 在复杂多样的驾驶场景中能够保持稳定且鲁棒的地图构建质量。MapTR 在自动驾驶中具有重要的应用价值。
1 引言
High-definition(HD Map)是专为自动驾驶设计的高精度地图,由实例级矢量化地图元素(如人行横道、车道分隔线、道路边界等)组成,包含丰富的道路拓扑和交通规则语义信息,对于自动驾驶车辆的导航至关重要。
传统高精地图是通过基于 SLAM(Simultaneous Localization and Mapping,同时定位与建图)的方法离线构建的,这种方法流程复杂且维护成本高昂。近年来,在线高精地图构建逐渐受到关注,它通过车辆搭载的传感器在运行时构建车辆周围的地图,从而摆脱了离线人工操作的限制。
早期的研究工作(Chen et al., 2022a; Liu et al., 2021a; Can et al., 2021)利用线形先验知识,基于前视图图像感知开放形状的车道线,但这些方法仅限于单视图感知,无法处理其他具有任意形状的地图元素。随着鸟瞰图(BEV,Bird's Eye View)表示学习的发展,近期的研究工作(Chen et al., 2022b; Zhou & Krähenhübl, 2022; Hu et al., 2021; Li et al., 2022c)通过执行 BEV 语义分割来预测栅格化地图。然而,栅格化地图缺乏矢量化实例级信息(如车道结构),这对于下游任务(例如运动预测和规划)至关重要。为了构建矢量化高精地图,HDMapNet(Li et al., 2022a)通过对像素级分割结果进行分组,但这种方法需要复杂且耗时的后处理。VectorMapNet(Liu et al., 2022a)首次提出了端到端框架,将每个地图元素表示为点序列,并采用级联的粗到细框架,利用自回归解码器顺序预测点,这导致了较长的推理时间。
当前的在线矢量化高精地图构建方法受到效率的限制,无法应用于实时场景。最近,DETR(Carion et al., 2020)采用简单高效的编码器-解码器 Transformer 架构,实现了端到端的目标检测。
自然会提出一个问题:我们能否设计一个类似 DETR 的范式,用于高效的端到端矢量化高精地图构建?我们的 MapTR(Map Transformer)给出了肯定的答案。
与目标检测中可以轻松将物体几何抽象为边界框不同,矢量化地图元素具有更动态的形状。为了准确描述地图元素,我们提出了一个新的统一建模方法,将每个地图元素建模为一组等价排列的点集。点集决定了地图元素的位置,而排列群包括了对应于相同几何形状的点集的所有可能组织序列,避免了形状的歧义。
基于排列等价建模,我们设计了一个结构化框架,输入为车辆搭载的摄像头图像,输出为矢量化高精地图。我们将在线矢量化高精地图构建简化为一个并行回归问题。我们提出了层次化查询嵌入方案,用于灵活编码实例级和点级信息。所有实例及其所有点通过统一的 Transformer 结构同时预测。训练流程被设计为层次化集合预测任务,我们通过层次化二分图匹配依次分配实例和点,并在点级和边级监督几何形状,使用提出的点到点损失和边方向损失进行监督。
凭借所有这些设计,我们提出了 MapTR,一种具有统一建模和架构的高效端到端在线矢量化高精地图构建方法。MapTR 在 nuScenes(Caesar et al., 2020)数据集上实现了现有矢量化地图构建方法中最佳的性能和效率。特别是,MapTR-nano 在 RTX 3090 上的实时推理速度达到 25.1 FPS,比现有的基于摄像头的最先进方法快 8 倍,同时平均精度(mAP)高出 5.0。即使与现有的多模态方法相比,MapTR-nano 的 mAP 高出 0.7,MapTR-tiny 的 mAP 高出 13.5,且推理速度比现有方法快 3 倍。如可视化结果(图 1)所示,MapTR 在复杂多样的驾驶场景中能够保持稳定且鲁棒的地图构建质量。
我们的贡献可以总结如下:
- 我们提出了一种统一的排列等价建模方法,即将地图元素建模为一组等价排列的点集,从而准确描述地图元素的形状并稳定学习过程。
- 基于新的建模方法,我们提出了 MapTR,一个用于高效在线矢量化高精地图构建的结构化端到端框架。我们设计了层次化查询嵌入方案,用于灵活编码实例级和点级信息,通过层次化二分图匹配进行地图元素学习,并在点级和边级监督几何形状,使用提出的点到点损失和边方向损失进行监督。
- MapTR 是首个在复杂多样的驾驶场景中实现稳定且鲁棒性能的实时 SOTA(State-of-the-Art,最先进)矢量化高精地图构建方法。
2 相关工作
HD Map Construction. 最近,随着2D到BEV(鸟瞰图)方法的发展,高精地图构建被表述为基于车辆周围摄像头捕获的多视角图像数据的分割问题。Chen等人(2022b)、Zhou和Krähenbühl(2022)、Hu等人(2021)、Li等人(2022c)、Philion和Fidler(2020)以及Liu等人(2022b)通过执行BEV语义分割生成栅格化地图。为了构建矢量化高精地图,HDMapNet(Li等人,2022a)通过启发式且耗时的后处理步骤将像素级语义分割结果分组以生成实例。VectorMapNet(Liu等人,2022a)是第一个端到端框架,采用两阶段粗到细的框架,并利用自回归解码器顺序预测点,导致推理时间较长且存在排列的歧义。与VectorMapNet不同,MapTR引入了针对地图元素的新型统一建模方法,解决了歧义问题并稳定了学习过程。此外,MapTR构建了一个结构化且高效的单阶段框架,显著提高了效率。
Lane Detection. 车道线检测可以视为高精地图构建的一个子任务,专注于检测道路场景中的车道线元素。由于大多数车道线检测数据集仅提供单视角注释且专注于开放形状元素,相关方法仅限于单视角。LaneATT(Tabelini等人,2021)利用基于锚点的深度车道线检测模型,在准确性和效率之间取得了良好的平衡。LSTR(Liu等人,2021a)采用Transformer架构直接输出车道线形状模型的参数。GANet(Wang等人,2022)将车道线检测表述为关键点估计和关联问题,并采用自底向上的设计。Feng等人(2022)提出了基于参数化贝塞尔曲线的车道线检测方法。Garnett等人(2019)提出的3D-LaneNet在BEV中执行3D车道线检测。STSU(Can等人,2021)在BEV坐标中将车道线表示为有向图,并采用基于贝塞尔曲线的方法从单目相机图像中预测车道线。Persformer(Chen等人,2022a)提供了更好的BEV特征表示,并优化了锚点设计,同时统一了2D和3D车道线检测。与仅在有限的单视角中检测车道线的方法不同,MapTR能够感知360°水平视场内的各种地图元素,并采用统一的建模和学习框架。
Contour-based Instance Segmentation. 与MapTR相关的另一条研究线是基于轮廓的2D实例分割(Zhu等人,2022;Xie等人,2020;Xu等人,2019;Liu等人,2021c)。这些方法将2D实例分割重新表述为对象轮廓预测任务,并估计轮廓顶点的图像坐标。CurveGCN(Ling等人,2019)利用图卷积网络预测多边形边界。Lazarow等人(2022)、Liang等人(2020)、Li等人(2021)和Peng等人(2020)依赖中间表示,并采用两阶段范式,即第一阶段执行分割/检测以生成顶点,第二阶段将顶点转换为多边形。这些工作将2D实例掩码的轮廓建模为多边形。它们的建模方法无法处理线状地图元素,因此不适用于地图构建。相比之下,MapTR专为高精地图构建量身定制,以统一的方式建模各种地图元素。此外,MapTR不依赖中间表示,且具有高效紧凑的流程。
3 MapTR
3.1 排列等价建模
MapTR旨在以统一的方式对高精地图进行建模和学习。高精地图是由矢量化的静态地图元素组成的集合,包括人行横道、车道分隔线、道路边界等。为了进行结构化建模,MapTR将地图元素从几何上抽象为闭合形状(如人行横道)和开放形状(如车道分隔线)。通过对形状边界的点进行采样,闭合形状元素被离散化为多边形,而开放形状元素被离散化为折线。
初步来看,多边形和折线都可以表示为有序点集 =
![]() (见图3(Vanilla))。Nv 表示点的数量。然而,点集的排列并未明确定义,且不是唯一的。对于多边形和折线,存在许多等价的排列方式。例如,如图2(a)所示,对于两条相对车道线之间的车道分隔线(折线),定义其方向是困难的。车道分隔线的两个端点都可以被视为起点,点集可以按两个方向组织。在图2(b)中,对于人行横道(多边形),点集可以按两个相反的方向(顺时针和逆时针)连接。并且,多边形点集的循环排列不会影响其几何形状。将固定的排列强加给点集作为监督是不合理的。这种强加的固定排列与其他等价排列相矛盾,阻碍了学习过程。
(见图3(Vanilla))。Nv 表示点的数量。然而,点集的排列并未明确定义,且不是唯一的。对于多边形和折线,存在许多等价的排列方式。例如,如图2(a)所示,对于两条相对车道线之间的车道分隔线(折线),定义其方向是困难的。车道分隔线的两个端点都可以被视为起点,点集可以按两个方向组织。在图2(b)中,对于人行横道(多边形),点集可以按两个相反的方向(顺时针和逆时针)连接。并且,多边形点集的循环排列不会影响其几何形状。将固定的排列强加给点集作为监督是不合理的。这种强加的固定排列与其他等价排列相矛盾,阻碍了学习过程。
为了弥合这一差距,MapTR使用 ![]() 来建模每个地图元素。其中
来建模每个地图元素。其中 ![]() 表示地图元素的点集(
表示地图元素的点集( 是点的数量),而
![]() 表示点集 V 的一组等价排列,涵盖所有可能的组织序列。
表示点集 V 的一组等价排列,涵盖所有可能的组织序列。
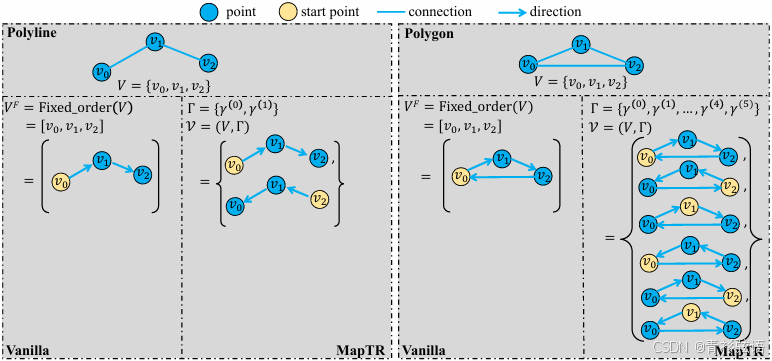
图3. MapTR的排列等价建模示意图。 地图元素被几何抽象并离散化为折线和多边形。MapTR使用 (V,Γ)(一个点集 V 和一组等价排列 Γ)来建模每个地图元素,从而避免歧义并稳定学习过程。
具体来说,对于折线元素(见图3(左侧)), 包括2种等价排列:
![]()
对于多边形元素(见图3(右侧)), 包括 2 ×
种等价排列:
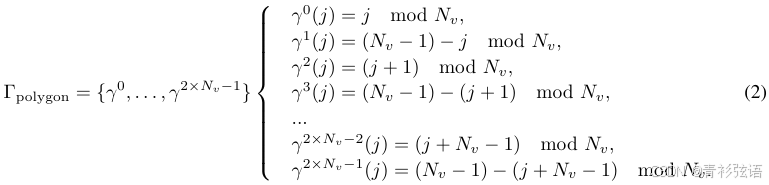
通过引入等价排列的概念,MapTR以统一的方式建模地图元素,并解决了歧义问题。MapTR进一步引入了层次化二分图匹配(见第3.2节和第3.3节)用于地图元素学习,并设计了一个结构化的编码器-解码器Transformer架构,以高效地预测地图元素(见第3.4节)。
3.2 层次化匹配
MapTR并行地推断一组固定大小的 N 个地图元素,遵循DETR(Carion等人,2020;Fang等人,2021)的端到端范式。N 被设置为大于场景中典型地图元素的数量。我们将 N 个预测的地图元素表示为 ![]() 。将真值(GT)地图元素集填充为∅(空对象)以形成大小为 N 的集合,表示为
。将真值(GT)地图元素集填充为∅(空对象)以形成大小为 N 的集合,表示为 ![]() 。
。![]() ,其中
,其中、
和
分别是GT地图元素
的目标类别标签、点集和排列群。
![]() ,其中
,其中 和
分别是预测的类别置信度和预测的点集。为了实现结构化的地图元素建模和学习,MapTR引入了层次化二分图匹配,即依次进行实例级匹配和点级匹配。
Instance-levelMatching. 首先,我们需要找到预测地图元素 {} 和GT地图元素 {
} 之间的最优实例级标签分配
。
是 N 个元素的一个排列
![]() ,其具有最低的实例级匹配成本:
,其具有最低的实例级匹配成本:
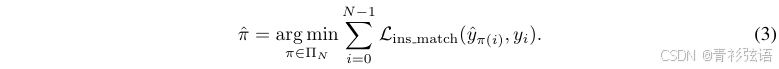
![]() 是预测
是预测 和GT
之间的成对匹配成本,它同时考虑了地图元素的类别标签和点集的位置:
![]()
![]() 是类别匹配成本项,定义为预测类别置信度
是类别匹配成本项,定义为预测类别置信度 和目标类别标签
之间的Focal Loss(Lin等人,2017)。
![]() 是位置匹配成本项,它反映了预测点集
是位置匹配成本项,它反映了预测点集 和GT点集
之间的位置相关性(更多细节见附录B)。我们使用匈牙利算法来找到最优的实例级分配
,这与DETR中使用的算法一致。
Point-level Matching. 在实例级匹配之后,每个预测的地图元素 被分配了一个GT地图元素
。然后对于每个被分配了正标签的预测实例(
≠ ∅),我们进行点级匹配,以找到预测点集
和GT点集
之间的最优点到点分配
∈
,其具有最低的点级匹配成本:
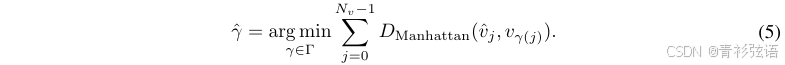
![]() 是预测点集
是预测点集 的第 j 个点和GT点集 V 的第
(j) 个点之间的曼哈顿距离。
3.3 TRAINING LOSS
MapTR基于最优的实例级和点级分配(和 {
})进行训练。损失函数由三部分组成:classification loss、point2point loss和edge direction loss:
![]()
其中 λ、α 和 β 是用于平衡不同损失项的权重。
Classification Loss. 借助实例级最优匹配结果 ,每个预测的地图元素被分配一个类别标签。分类损失是一个Focal Loss项,定义如下:
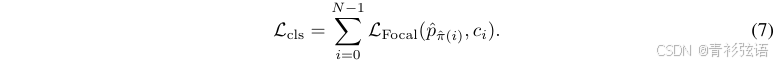
Point2point Loss. Point2point loss用于监督每个预测点的位置。对于每个具有索引 i 的GT实例,根据点级最优匹配结果 ,每个预测点
![]() 被分配一个GT点
被分配一个GT点![]() 。点到点损失定义为每对分配点之间的曼哈顿距离之和:
。点到点损失定义为每对分配点之间的曼哈顿距离之和:
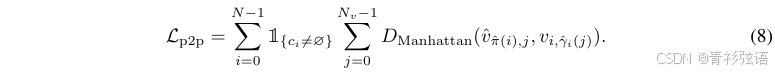
Edge Direction Loss. Point2point loss仅监督折线和多边形的节点点,而没有考虑边(相邻点之间的连接线)。为了准确表示地图元素,边的方向也很重要。因此,我们进一步设计了边方向损失,以在更高层次的边上监督几何形状。具体来说,我们考虑预测边![]() 和GT边
和GT边![]() 之间的余弦相似度:
之间的余弦相似度:
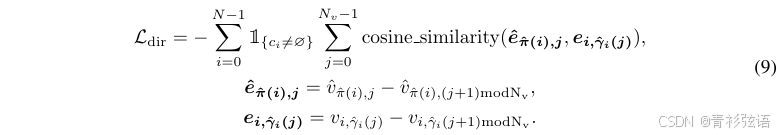
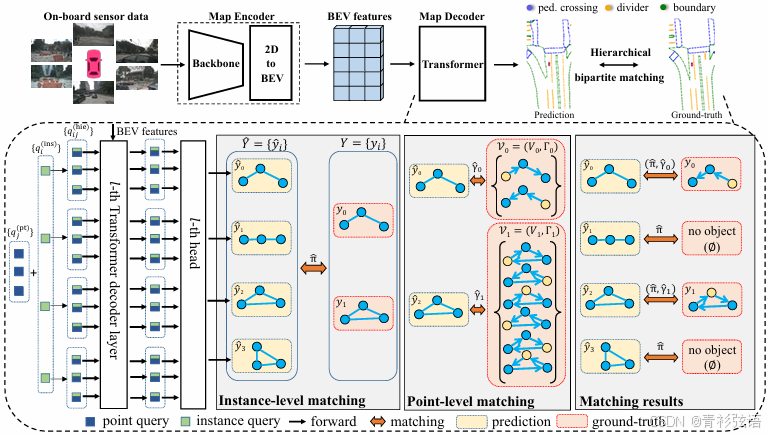
图4. MapTR的整体架构。MapTR采用编码器-解码器范式。地图编码器将传感器输入转换为统一的鸟瞰图(BEV)表示。地图解码器采用层次化查询嵌入方案,明确地对地图元素进行编码,并基于排列等价建模执行层次化匹配。MapTR是完全端到端的,整个流程高度结构化、紧凑且高效。
3.4 ARCHITECTURE
MapTR采用编码器-解码器范式,其整体架构如图4所示。
Input Modality. MapTR以车辆搭载的多视角摄像头图像作为输入。MapTR也兼容其他车载传感器(例如激光雷达和雷达)。将MapTR扩展到多模态数据是直接且简单的。得益于合理的排列等价建模,即使仅使用摄像头输入,MapTR也能显著优于其他多模态方法。
Map Encoder. MapTR的地图编码器从多视角摄像头图像中提取特征,并将其转换为统一的特征表示,即鸟瞰图(BEV)表示。给定多视角图像![]() ,我们利用传统的主干网络生成多视角特征图
,我们利用传统的主干网络生成多视角特征图![]() 。然后,将2D图像特征F 转换为BEV特征
。然后,将2D图像特征F 转换为BEV特征![]() 。默认情况下,我们采用GKT(Chen等人,2022b)作为基础的2D到BEV转换模块,考虑到其易于部署和高效性。MapTR兼容其他转换方法,并保持稳定性能,例如CVT(Zhou和Krähenhübl,2022)、LSS(Philion和Fidler,2020;Liu等人,2022c;Li等人,2022b;Huang等人,2021)、可变形注意力(Li等人,2022c;Zhu等人,2021)和IPM(Mallot等人,1991)。相关消融研究见表4。
。默认情况下,我们采用GKT(Chen等人,2022b)作为基础的2D到BEV转换模块,考虑到其易于部署和高效性。MapTR兼容其他转换方法,并保持稳定性能,例如CVT(Zhou和Krähenhübl,2022)、LSS(Philion和Fidler,2020;Liu等人,2022c;Li等人,2022b;Huang等人,2021)、可变形注意力(Li等人,2022c;Zhu等人,2021)和IPM(Mallot等人,1991)。相关消融研究见表4。
MapDecoder. 我们提出了一种层次化查询嵌入方案,用于明确地对每个地图元素进行编码。具体来说,我们定义了一组实例级查询![]() 和一组点级查询
和一组点级查询![]() ,这些查询被所有实例共享。每个地图元素(索引为 i )对应一组层次化查询
,这些查询被所有实例共享。每个地图元素(索引为 i )对应一组层次化查询![]() 。第 i 个地图元素的第 j 个点的层次化查询表示为:
。第 i 个地图元素的第 j 个点的层次化查询表示为:
![]()
地图解码器包含多个级联的解码器层,这些层迭代更新层次化查询。在每个解码器层中,我们采用多头自注意力(MHSA)机制,使层次化查询之间相互交换信息(包括实例内和实例间)。然后,我们采用可变形注意力(Zhu等人,2021)机制,使层次化查询与BEV特征进行交互,这一设计受到BEVFormer(Li等人,2022c)的启发。每个查询 预测参考点
的二维归一化BEV坐标 (
,
)。然后,我们在参考点周围采样BEV特征并更新查询。
地图元素通常具有不规则形状,需要长距离上下文信息。每个地图元素对应一组参考点![]() ,这些点具有灵活且动态的分布。参考点
,这些点具有灵活且动态的分布。参考点![]() 能够适应地图元素的任意形状,并为地图元素学习捕获信息丰富的上下文。
能够适应地图元素的任意形状,并为地图元素学习捕获信息丰富的上下文。
MapTR的预测头设计简单,包含一个分类分支和一个点回归分支。分类分支预测实例类别置信度,而点回归分支预测点集的位置。对于每个地图元素,它输出一个 2
维向量,表示
个点的归一化BEV坐标。
4 实验
Dataset and Metric. 我们在流行的 nuScenes 数据集(Caesar 等人,2020)上评估 MapTR。该数据集包含 1000 个场景,每个场景持续约 20 秒,关键样本以 2Hz 的频率进行标注。每个样本包含来自 6 个摄像头的 RGB 图像,覆盖了车辆周围的 360° 水平视场。按照之前的方法(Li 等人,2022a;Liu 等人,2022a),我们选择了三种地图元素进行公平评估:人行横道、车道分隔线和道路边界。感知范围为 X 轴的 [-15.0m, 15.0m] 和 Y 轴的 [-30.0m, 30.0m]。我们采用平均精度(AP)来评估地图构建的质量。使用 Chamfer 距离 DChamfer 来判断预测和真实值是否匹配。我们在几个 Chamfer 距离阈值(∈T,其中 T={0.5,1.0,1.5})下计算
,并取所有阈值的平均值作为最终的 AP 指标:
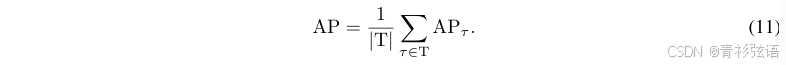
Implementation Details. MapTR 使用 8 个 NVIDIA GeForce RTX 3090 GPU 进行训练。我们采用 AdamW 优化器(Loshchilov 和 Hutter,2019)和余弦退火学习率调度。对于 MapTR-tiny,我们采用 ResNet50(He 等人,2016)作为backbone,并以总batch size为 32(包含 6 个视角的图像)进行训练。所有消融实验均基于训练了 24 个周期的 MapTR-tiny 进行。MapTR-nano 专为实时应用设计,采用 ResNet18 作为主干网络。更多细节请参阅附录 A。
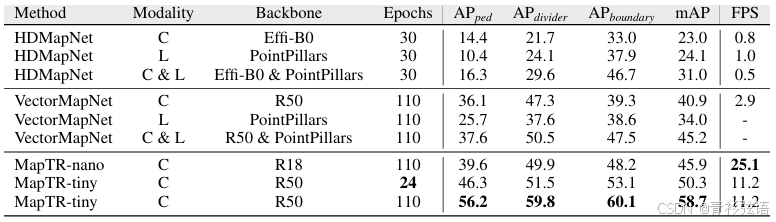
表1. 与最新方法(Liu等人,2022a;Li等人,2022a)在 nuScenes 验证集上的比较。“C”和“L”分别表示摄像头和激光雷达。“Effi-B0”和“PointPillars”分别对应于 Tan和Le(2019)以及 Lang等人(2019)。其他方法的 AP 值取自 VectorMapNet 的论文。VectorMapNet-C 的 FPS 由其作者提供,并在 RTX 3090 上测量。其他 FPS 值均在同一台配备 RTX 3090 的机器上测量。“-”表示相应的结果不可用。即使仅使用摄像头输入,MapTR-tiny 也显著优于多模态方法(+13.5 mAP)。MapTR-nano 实现了基于摄像头的 SOTA性能,并以 25.1 FPS 的速度运行,首次实现了实时矢量化地图构建。
4.1 COMPARISONS WITH SOTA METHODS
在表 1 中,我们将 MapTR 与最新方法进行了比较。MapTR-nano 在 RTX 3090 上的实时推理速度达到 25.1 FPS,比现有的基于摄像头的最佳方法(VectorMapNet-C)快 8 倍,同时平均精度(mAP)高出 5.0。即使与现有的多模态方法相比,MapTR-nano 的 mAP 高出 0.7,MapTR-tiny 的 mAP 高出 13.5,且推理速度比现有方法快 3 倍。MapTR 也是一种快速收敛的方法,24-epoch schedule即可展现出卓越的性能。
4.2 消融研究
为了验证不同设计的有效性,我们在 nuScenes 验证集上进行了消融实验。更多消融实验请参阅附录 B。

表2. 关于建模方法的消融实验。传统的建模方法为点集强加了一个唯一的排列顺序,导致了歧义。MapTR引入了排列等价建模方法以避免歧义,这不仅稳定了学习过程,还显著提升了性能(+5.9 mAP)。
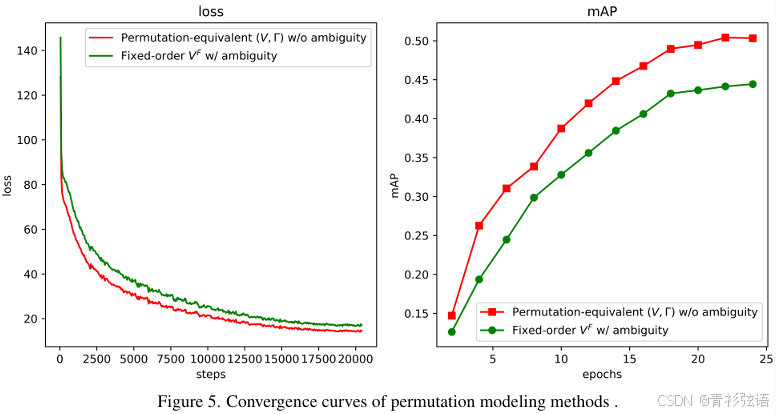
排列等价建模的有效性。在表 2 中,我们提供了关于排列等价建模的消融实验。与将唯一排列强加于点集的传统建模方法相比,排列等价建模解决了地图元素的歧义问题,并带来了 5.9 mAP 的提升。对于人行横道,提升甚至达到了 11.9 AP,证明了其在建模多边形元素方面的优越性。我们还在图 5 中可视化了学习过程,展示了所提建模方法的稳定性。
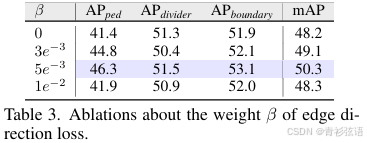
Effectiveness of Edge Direction Loss. 表 3 提供了关于边方向损失权重的消融实验。当权重 β=0 时,表示不使用edge direction loss;而当 β= 时,表示提供了适当的监督,这也是我们默认的设置。

2D-to-BEVTransformation. 在表 4 中,我们对 2D 到 BEV 转换方法进行了消融实验,包括 IPM(Mallot 等人,1991)、LSS(Liu 等人,2022c;Philion 和 Fidler,2020)、Deformable Attention(Li 等人,2022c)和 GKT(Chen 等人,2022b)。为了与 IPM 和 LSS 公平比较,GKT 和可变形注意力均采用了单层配置。实验表明,MapTR 兼容多种 2D 到 BEV 转换方法,并能保持稳定的性能。我们默认采用 GKT 作为 MapTR 的配置,考虑到其易于部署和高效性。
4.3 定性可视化
我们在图 1 中展示了复杂多样的驾驶场景下的预测矢量化高精地图结果。MapTR 保持了稳定且令人印象深刻的结果。更多定性结果请参阅附录 C。我们还在补充材料中提供了视频,以展示其鲁棒性。
5 CONCLUSION
MapTR 是一个用于高效在线矢量化高精地图构建的结构化端到端框架,采用简单的encoder-decoder Transformer 架构和层次化二分图匹配,基于提出的排列等价建模进行地图元素学习。大量实验表明,该方法能够在具有挑战性的 nuScenes 数据集上精确感知任意形状的地图元素。我们希望 MapTR 能够作为自动驾驶系统的一个基础模块,并推动下游任务(例如运动预测和规划)的发展。
附录
A 实现细节
本节提供了方法和实验的更多实现细节。
Data Augmentation. 源图像的分辨率为1600×900。对于MapTR-nano,我们将源图像按0.2的比例缩放。对于MapTR-tiny,我们将源图像按0.5的比例缩放。默认使用颜色抖动。
Model Setting. 在所有实验中,训练时分别将λ、α和β设置为2、5和5e-3。对于MapTR-tiny,我们将实例级查询和点级查询的数量分别设置为50和20。每个BEV网格的大小设置为0.3米,并堆叠了6个Transformer解码器层。我们以总批量大小为32(包含6个视角的图像)、学习率为6e-4进行训练,主干网络的学习率乘数为0.1。所有消融实验均基于训练了24个周期的MapTR-tiny进行。对于MapTR-nano,我们将实例级查询和点级查询的数量分别设置为100和20。每个BEV网格的大小设置为0.75米,并堆叠了2个Transformer解码器层。我们以110个周期、总批量大小为192、学习率为4e-3进行训练,主干网络的学习率乘数为0.1。我们采用GKT(Chen等人,2022b)作为MapTR的默认2D到BEV模块。
Dataset Preprocessing. 我们按照Liu等人(2022a)和Li等人(2022a)的方法处理地图注释。将感知范围内的地图元素提取为真实值地图元素。默认情况下,感知范围为X轴的[-15.0m, 15.0m]和Y轴的[-30.0m, 30.0m]。
B 消融研究
Point Number. 关于建模每个地图元素所用点数的消融实验结果如表5所示。点数太少无法描述地图元素复杂的几何形状,而点数过多则会影响效率。我们默认设置MapTR的点数为20。
Element Number. 关于地图元素数量的消融实验结果如表6所示。我们默认将MapTR-tiny的地图元素数量设置为50。
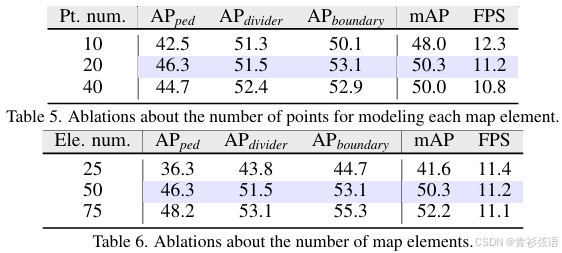
Decode rLayer Number. 关于地图解码器层数的消融实验结果如表7所示。随着层数增加,地图构建性能有所提升,但在层数达到6时趋于饱和。
Position Matching Cost. 如第3.2节所述,我们在实例级匹配中采用了位置匹配成本项Lposition(V^π(i),Vi),以反映预测点集V^π(i)和真实点集Vi之间的位置相关性。如表8所示,我们比较了两种成本设计,即Chamfer距离成本和点到点成本。点到点成本与点级匹配成本类似。具体来说,我们找到最佳的点到点分配,并将所有点对的曼哈顿距离之和作为两个点集的位置匹配成本。实验表明,点到点成本优于Chamfer距离成本。

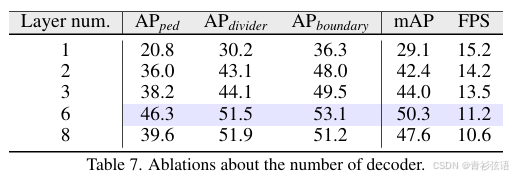
Swin Transformer Backbones. 关于Swin Transformer backbones(Liu等人,2021b)的消融实验结果如表9所示。
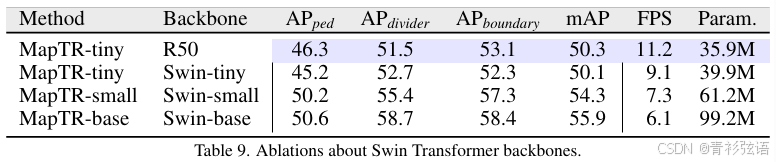
Modality. 多传感器感知对于自动驾驶的安全性至关重要,MapTR兼容其他车载传感器,如激光雷达。如表10所示,在仅训练24个周期的情况下,多模态MapTR显著优于先前的最佳结果17.3 mAP,同时速度快2倍。
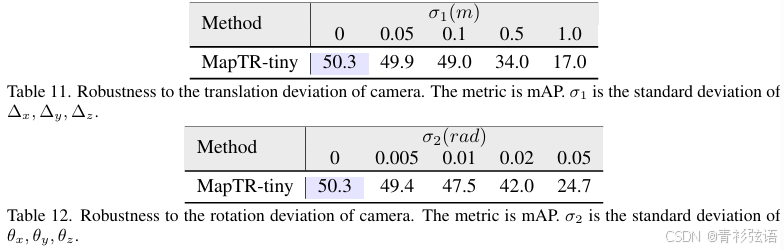
Robustness to the camera deviation. 在实际应用中,摄像头内参通常较为准确且变化较小,但摄像头外参可能由于摄像头位置偏移、标定误差等原因而不准确。为了验证鲁棒性,我们遍历验证集,并为每个样本随机生成噪声。我们分别添加平移和旋转偏差,其标准差分别为不同数值。需要注意的是,我们为所有摄像头和所有坐标添加噪声,且噪声服从正态分布。存在极个别样本的偏差较大,对性能影响显著。如表11和表12所示,当平移偏差的标准差σ1为0.1米或旋转偏差的标准差σ2为0.02弧度时,MapTR仍能保持相当的性能。
Detailed running time. 为了更深入地了解MapTR的效率,我们在表13中展示了MapTR-tiny(仅使用多摄像头输入)的每个组件的详细运行时间。

C 定性可视化
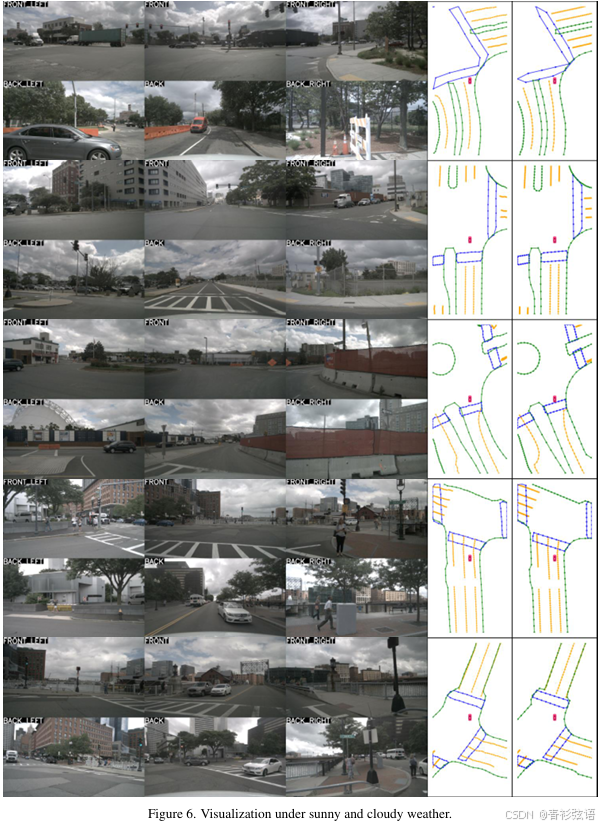
我们在nuScenes验证集的不同天气条件和复杂道路环境下展示了MapTR的地图构建结果。如图6、图7和图8所示,MapTR保持了稳定且令人印象深刻的结果。视频结果见补充材料。




















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









