






【软件工程实践】Hive研究-Blog9
2021SC@SDUSC
研究内容介绍
本人负责的是负责的是将查询块QB转换成逻辑查询计划(OP Tree)
如下的代码出自apaceh-hive-3.1.2-src/ql/src/java/org/apache/hadoop/hive/ql/plan中,也就是我的分析目标代码。之前的Hive研究-Blog1-8中已经完成了对mapper文件夹下所有的代码解析,从本周开始我们将研究下一个文件夹ptf中的源码。这周的任务是研究ptf文件夹下的BoundaryDef.java文件。

BoundaryDef.java文件代码解析
我们首先附上整个java文件代码
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hive.ql.plan.ptf;
import org.apache.hadoop.hive.ql.parse.WindowingSpec.BoundarySpec;
import org.apache.hadoop.hive.ql.parse.WindowingSpec.Direction;
public class BoundaryDef {
Direction direction;
private int amt;
private final int relativeOffset;
public BoundaryDef(Direction direction, int amt) {
this.direction = direction;
this.amt = amt;
// Calculate relative offset
switch(this.direction) {
case PRECEDING:
relativeOffset = -amt;
break;
case FOLLOWING:
relativeOffset = amt;
break;
default:
relativeOffset = 0;
}
}
public Direction getDirection() {
return direction;
}
/**
* Returns if the bound is PRECEDING.
* @return if the bound is PRECEDING
*/
public boolean isPreceding() {
return this.direction == Direction.PRECEDING;
}
/**
* Returns if the bound is FOLLOWING.
* @return if the bound is FOLLOWING
*/
public boolean isFollowing() {
return this.direction == Direction.FOLLOWING;
}
/**
* Returns if the bound is CURRENT ROW.
* @return if the bound is CURRENT ROW
*/
public boolean isCurrentRow() {
return this.direction == Direction.CURRENT;
}
/**
* Returns offset from XX PRECEDING/FOLLOWING.
*
* @return offset from XX PRECEDING/FOLLOWING
*/
public int getAmt() {
return amt;
}
/**
* Returns signed offset from XX PRECEDING/FOLLOWING. Negative for preceding.
*
* @return signed offset from XX PRECEDING/FOLLOWING
*/
public int getRelativeOffset() {
return relativeOffset;
}
public boolean isUnbounded() {
return this.getAmt() == BoundarySpec.UNBOUNDED_AMOUNT;
}
public int compareTo(BoundaryDef other) {
int c = getDirection().compareTo(other.getDirection());
if (c != 0) {
return c;
}
return this.direction == Direction.PRECEDING ? other.amt - this.amt : this.amt - other.amt;
}
@Override
public String toString() {
if (direction == null) return "";
if (direction == Direction.CURRENT) {
return Direction.CURRENT.toString();
}
return direction + "(" + (getAmt() == Integer.MAX_VALUE ? "MAX" : getAmt()) + ")";
}
}
解析开始。
全局变量简要分析
我们先来看看有哪些全局变量。
Direction direction;
private int amt;
private final int relativeOffset;
我们先看一下,这个Direction类是什么样的一个类?我们首先在网页上搜索,发现无法搜索到有关的内容。而我们搜索的关键字从"Java中的Diection"到"Hive中的Direction"都无法搜索出我们想要的内容。我们不妨换一个思路:观察引入的包,看其是否包含了这个类。果不其然,我们在开头的声明中看见了如下语句:
import org.apache.hadoop.hive.ql.parse.WindowingSpec.Direction;,这显然是一个Hive的官方接口,于是我们便去apache官网查看这个接口所对应的内容。我们在官网果然搜索到了这个内容:连接
这里就是我们需要查看的内容文档。我们先来看一下其继承的类:Enum<WindowingSpec.Direction>。这里有一个非常关键的信息:关键词Enum。在Java中,Enum是一个类,它包含了自定义的对象,方便引用而没有必要承受参数设置错误的风险去构造一个新的对象。我们可以来看一下它的其中一种用法:
public enum WeekDay {
Mon("Monday"), Tue("Tuesday"), Wed("Wednesday"), Thu("Thursday"), Fri( "Friday"), Sat("Saturday"), Sun("Sunday");
private final String day;
private WeekDay(String day) {
this.day = day;
}
public static void printDay(int i){
switch(i){
case 1: System.out.println(WeekDay.Mon); break;
case 2: System.out.println(WeekDay.Tue);break;
case 3: System.out.println(WeekDay.Wed);break;
case 4: System.out.println(WeekDay.Thu);break;
case 5: System.out.println(WeekDay.Fri);break;
case 6: System.out.println(WeekDay.Sat);break;
case 7: System.out.println(WeekDay.Sun);break;
default:System.out.println("wrong number!");
}
}
public String getDay() {
return day;
}
}
在底层逻辑中,上面的枚举类型Enum参数WeekDay经过反编译后会得到如下内容:
public final class WeekDay extends java.lang.Enum{
public static final WeekDay Mon;
public static final WeekDay Tue;
public static final WeekDay Wed;
public static final WeekDay Thu;
public static final WeekDay Fri;
public static final WeekDay Sat;
public static final WeekDay Sun;
static {};
public static void printDay(int);
public java.lang.String getDay();
public static WeekDay[] values();
public static WeekDay valueOf(java.lang.String);
}
我们可以看到,编译后的Enum类型的变量就相当于是一个类了,非常的方便。此外,它还可以改写tostring方法和其他的方法,也有自定义getter和setter的方法,非常好用。
我们接着来看官方API给出的解释。这个WindowingSpec.Direction包含了三个常量:CURRENT,FOLLOWING,PRECEDING。在本枚举类有两个static静态方法,第一个方法是valueOf(String name),返回值是一个实例化对象,该方法返回的是枚举类型中的实例,通过调用该方法时传入的名字作为索引进行查找;第二个方法values(),返回的是包含的所有实例化对象,以一个数组的形式进行返回。
values

以初始化定义好的顺序返回一个WindowingSpec.Direction数组。调用方式为:WindowingSpec.Direction.values()
valueOf

返回一个实例化的具体对象,由传入的参数名字决定。
鉴于在BoundartDef文件中仍然存在很多我们不认识的参数类型和方法,我们不妨再来解析另外一个导入文件org.apache.hadoop.hive.ql.parse.WindowingSpec.BoundarySpec的内容,再开始对整个文件的源码进行解析。
同样的,我们在官网上查找对这个类的描述:链接

我们发现,这是一个抽象的类,且实现的接口是Comparable。当然,既然是抽象类那么说明其中由某一些方法是还未实现的,不过实现的方法已经够我们所用了。这个类其中有四个方法。

方法getAmt()和方法setAmt(int amt)
从方法名上就可以看出这是一对get和setter方法。而这个amt是一个什么参数呢?我们不妨看一下全局变量,发现了一个参数名为UNBOUNDED_AMOUNT的int类型的全局变量。那么amt就是其缩写了。那么这个get和set方法就是对其的get和set方法了。
方法getDirection()和setDirection(WindowingSpec.Direction dir)
同样的,我们在上文中已经解释过这个WindowingSpec.Direction是一个什么样的类了,故这里不再冗余的解释。这个get和set方法就是设置和得到一个WindowingSpec.Direction类型的变量。
回到BoundaryDef.java的源码中来,我们可以知道全局变量direction的意思了,也知道amt是属于BoundarySpec的amt。而最后的relativeOffset我们暂时还不清楚它的作用,我们可以在下文继续观察。
至此,我们将导入的包以及BoundaryDef.java的全局变量全部解释完毕,现在我们已经做足了前期工作,可以正式开始解析了。
构造方法BoundaryDef
public BoundaryDef(Direction direction, int amt) {
this.direction = direction;
this.amt = amt;
// Calculate relative offset
switch(this.direction) {
case PRECEDING:
relativeOffset = -amt;
break;
case FOLLOWING:
relativeOffset = amt;
break;
default:
relativeOffset = 0;
}
}
在开头设置了两个全局变量的值为传入的参数,是一个常规的构造类方法操作。接下来就是一个switch语句,相当于是多个if的集合。当direction参数为PRECEDING时将relativeOffset的值设置为-amt;当direction参数为FOLLOWING时将relativeOffset设置为amt;当direction参数为其他值(这里其实也包含了direction值为CURRENT的情况)。至此,整个构造方法结束。
方法getDirection
public Direction getDirection() {
return direction;
}
这是一个简单的getter方法,返回的参数是全局变量direciton。
方法isPreceding
/**
* Returns if the bound is PRECEDING.
* @return if the bound is PRECEDING
*/
public boolean isPreceding() {
return this.direction == Direction.PRECEDING;
}
这个方法是判断direction是否为PRECEDING实例化对象的方法。这里值得注意的一点是:枚举型Enum变量的比较方法不能使用equals方法,因为它们不是字符串,必须要使用==方法进行判断。
方法isFollowing
/**
* Returns if the bound is FOLLOWING.
* @return if the bound is FOLLOWING
*/
public boolean isFollowing() {
return this.direction == Direction.FOLLOWING;
}
这个方法和上个方法类似,将全局变量是否等于Direction.FOLLOWING的bolean值返回。
方法isCurrentRow
/**
* Returns if the bound is CURRENT ROW.
* @return if the bound is CURRENT ROW
*/
public boolean isCurrentRow() {
return this.direction == Direction.CURRENT;
}
与先前的两个方法类似,判断全局变量是否等于Direction.CUURRENT的boolean值返回。
方法getAmt
public int getAmt() {
return amt;
}
这是一个getter方法,用于得到全局变量amt的值。
方法getRelativeOffset
/**
* Returns signed offset from XX PRECEDING/FOLLOWING. Negative for preceding.
*
* @return signed offset from XX PRECEDING/FOLLOWING
*/
public int getRelativeOffset() {
return relativeOffset;
}
这也是一个getter方法,用于得到RelativeOffset的值。
方法isUnbounded
public boolean isUnbounded() {
return this.getAmt() == BoundarySpec.UNBOUNDED_AMOUNT;
}
这是判断我们全局变量amt是否与BoundarySpec中的全局变量UNBOUNDED_AMOUNT是否相等,然后返回boolean值。
方法CompareTo
public int compareTo(BoundaryDef other) {
int c = getDirection().compareTo(other.getDirection());
if (c != 0) {
return c;
}
return this.direction == Direction.PRECEDING ? other.amt - this.amt : this.amt - other.amt;
}
我们先来看一下这个compareTo方法。我们知道,compareTo() 方法用于将 Number 对象与方法的参数进行比较。可用于比较 Byte, Long, Integer等。该方法用于两个相同数据类型的比较,两个不同类型的数据不能用此方法来比较。
语法
public int compareTo( NumberSubClass referenceName )
参数
referenceName – 可以是一个 Byte, Double, Integer, Float, Long 或 Short 类型的参数。
返回值
如果指定的数与参数相等返回0。
如果指定的数小于参数返回 -1。
如果指定的数大于参数返回 1。
我们来举一个例子来直观的了解这个函数的用法:
public class Test{
public static void main(String args[]){
Integer x = 5;
System.out.println(x.compareTo(3));
System.out.println(x.compareTo(5));
System.out.println(x.compareTo(8));
}
}
输出
1
0
-1
我们看一下c的赋值语句。首先是调用了getDirection方法,得到全局变量direction和传入参数的direction一起比较,然后得到返回值再赋值给c。然后判断c如果不是0也就是说全局变量direction和传入参数的direction不相等,就返回c。如果c等于0,说明他们相等,则判断全局变量direction是否等于PRECEDING这个实例,返回两者amt的差值,具体是谁减谁被减则要看判断的true值和false值。
方法tostring
@Override
public String toString() {
if (direction == null) return "";
if (direction == Direction.CURRENT) {
return Direction.CURRENT.toString();
}
return direction + "(" + (getAmt() == Integer.MAX_VALUE ? "MAX" : getAmt()) + ")";
}
这里覆盖了toString方法。如果全局变量direction是null的,则返回一个空的字符串,如果direction就是CURRENT实例,则执行CURRENT实例中的tostring方法的。如果都不是,则判断amt的值是否与MAX_VALUE相等,如果相等则返回MAX,如果不相等则返回amt的值。
至此,BoundartDef.java文件全部解析完毕。
PTFExpressionDef.java文件代码解析
我们接着再来解析一个java文件,首先附上源代码
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.hive.ql.plan.ptf;
import org.apache.hadoop.hive.ql.exec.ExprNodeEvaluator;
import org.apache.hadoop.hive.ql.plan.Explain;
import org.apache.hadoop.hive.ql.plan.Explain.Level;
import org.apache.hadoop.hive.ql.plan.ExprNodeDesc;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
public class PTFExpressionDef {
String expressionTreeString;
ExprNodeDesc exprNode;
transient ExprNodeEvaluator exprEvaluator;
transient ObjectInspector OI;
public PTFExpressionDef() {}
public PTFExpressionDef(PTFExpressionDef e) {
expressionTreeString = e.getExpressionTreeString();
exprNode = e.getExprNode();
exprEvaluator = e.getExprEvaluator();
OI = e.getOI();
}
public String getExpressionTreeString() {
return expressionTreeString;
}
public void setExpressionTreeString(String expressionTreeString) {
this.expressionTreeString = expressionTreeString;
}
public ExprNodeDesc getExprNode() {
return exprNode;
}
public void setExprNode(ExprNodeDesc exprNode) {
this.exprNode = exprNode;
}
@Explain(displayName = "expr", explainLevels = { Level.USER, Level.DEFAULT, Level.EXTENDED })
public String getExprNodeExplain() {
return exprNode == null ? null : exprNode.getExprString();
}
public ExprNodeEvaluator getExprEvaluator() {
return exprEvaluator;
}
public void setExprEvaluator(ExprNodeEvaluator exprEvaluator) {
this.exprEvaluator = exprEvaluator;
}
public ObjectInspector getOI() {
return OI;
}
public void setOI(ObjectInspector oI) {
OI = oI;
}
}
开始解析。
全局变量解析
String expressionTreeString;
ExprNodeDesc exprNode;
transient ExprNodeEvaluator exprEvaluator;
transient ObjectInspector OI;
我们先来看一下第一次出现的这个ExprNodeDesc类是一个什么样类型的类。我们观察导入的包,找到了和它同名的包org.apache.hadoop.hive.ql.plan.ExprNodeDesc;,接着我们在官方的API中找到了对该类的解析:

等到我们需要用到里面的方法或者属性时,我们再从里面的内容进行比对查阅。接着是我们第一次接触的Java关键字"transient",这是有什么作用的关键字?我们查阅资料得知:Java中transient关键字的作用,简单地说,就是让某些被修饰的成员属性变量不被序列化。那么什么是Java中序列化的定义呢:Java中对象的序列化指的是将对象转换成以字节序列的形式来表示,这些字节序列包含了对象的数据和信息,一个序列化后的对象可以被写到数据库或文件中,也可用于网络传输,一般当我们使用缓存cache(内存空间不够有可能会本地存储到硬盘)或远程调用rpc(网络传输)的时候,经常需要让我们的实体类实现Serializable接口,目的就是为了让其可序列化。当然,序列化后的最终目的是为了反序列化,恢复成原先的Java对象,要不然得到一堆不符合调用格式的数据是无用的,所以序列化后的字节序列都是可以恢复成Java对象的,这个过程就是反序列化。那么什么情况下,一个对象的某些字段不需要被序列化呢?如果有如下情况,可以考虑使用关键字transient修饰:类中的字段值可以根据其它字段推导出来,如一个长方形类有三个属性:长度、宽度、面积,那么在序列化的时候,面积这个属性就没必要被序列化了。最后,为什么要不被序列化呢,主要是为了节省存储空间,其它的感觉没啥好处,可能还有坏处(有些字段可能需要重新计算,初始化什么的),总的来说,利大于弊。我们来看一个简单的例子来直观的感受这个方法:
package tmp;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
class Rectangle implements Serializable{
/**
*
*/
private static final long serialVersionUID = 1710022455003682613L;
private Integer width;
private Integer height;
private transient Integer area;
public Rectangle (Integer width, Integer height){
this.width = width;
this.height = height;
this.area = width * height;
}
public void setArea(){
this.area = this.width * this.height;
}
@Override
public String toString(){
StringBuffer sb = new StringBuffer(40);
sb.append("width : ");
sb.append(this.width);
sb.append("\nheight : ");
sb.append(this.height);
sb.append("\narea : ");
sb.append(this.area);
return sb.toString();
}
}
public class TransientExample{
public static void main(String args[]) throws Exception {
Rectangle rectangle = new Rectangle(3,4);
System.out.println("1.原始对象\n"+rectangle);
ObjectOutputStream o = new ObjectOutputStream(new FileOutputStream("rectangle"));
// 往流写入对象
o.writeObject(rectangle);
o.close();
// 从流读取对象
ObjectInputStream in = new ObjectInputStream(new FileInputStream("rectangle"));
Rectangle rectangle1 = (Rectangle)in.readObject();
System.out.println("2.反序列化后的对象\n"+rectangle1);
rectangle1.setArea();
System.out.println("3.恢复成原始对象\n"+rectangle1);
in.close();
}
}
输出:
1.原始对象
width : 3
height : 4
area : 12
2.反序列化后的对象
width : 3
height : 4
area : null
3.恢复成原始对象
width : 3
height : 4
area : 12
总的来说,transient的作用是为了节约空间,因为hive处理的是海量规模的数据,因此节约空间是必须要实现的基本需求。解析了这些,我们再来看一下新出现的两个类:ExprNodeEvaluator类以及ObjectInspector类。同样的,我们直接到apache官网上查找这两个类的内容。关于ExprNodeEvaluator类:

ObjectInspector类:

我们等到需要使用到其方法或者变量时再仔细地参考解析。
类构造器方法PTFExpressionDef
public PTFExpressionDef() {}
public PTFExpressionDef(PTFExpressionDef e) {
expressionTreeString = e.getExpressionTreeString();
exprNode = e.getExprNode();
exprEvaluator = e.getExprEvaluator();
OI = e.getOI();
}
有两个构造方法,一个是空的构造方法,而另一个是传入一个PTFExpressionDef类参数进行赋值,将所有的变量都设置为传入参数的自带变量。
参数expressionTreeString的getter与setter方法
public String getExpressionTreeString() {
return expressionTreeString;
}
public void setExpressionTreeString(String expressionTreeString) {
this.expressionTreeString = expressionTreeString;
}
这是普遍的getter和setter方法,用于得到和设置参数。
参数exprNode的getter与setter方法
public ExprNodeDesc getExprNode() {
return exprNode;
}
public void setExprNode(ExprNodeDesc exprNode) {
this.exprNode = exprNode;
}
这是普遍的getter和setter方法,用于得到和设置参数。
方法getExprNodeExplain
@Explain(displayName = "expr", explainLevels = { Level.USER, Level.DEFAULT, Level.EXTENDED })
public String getExprNodeExplain() {
return exprNode == null ? null : exprNode.getExprString();
}
这里的Explain语句指定的是Explain类的。而这个类拥有全局变量String类型的displayName,数组类型的explainLevels(其中的元素类型为Explain.Level)。我们来看一下数组的设定:
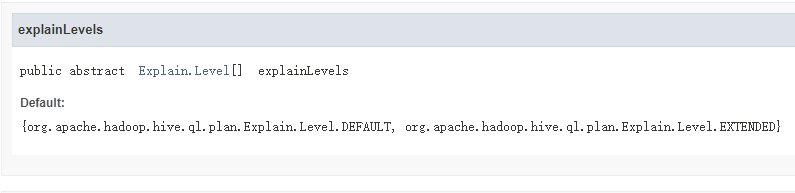
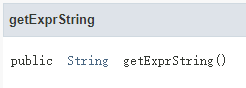
很显然,这是将数组设为默认指定值。接着是判断exprNode变量是否为空,如果为空则返回null,不为空则调用方法getExprString()。而这个方法在ExprNodeDesc类中,返回的是String类型的变量。
参数exprEvalutor的getter与setter方法
public ExprNodeEvaluator getExprEvaluator() {
return exprEvaluator;
}
public void setExprEvaluator(ExprNodeEvaluator exprEvaluator) {
this.exprEvaluator = exprEvaluator;
}
这是普遍的getter和setter方法,用于得到和设置参数。
参数OI的getter与setter方法
public ObjectInspector getOI() {
return OI;
}
public void setOI(ObjectInspector oI) {
OI = oI;
}
这是普遍的getter和setter方法,用于得到和设置参数。
至此,PTFExpressionDef.java文件全部解析完成。
小结
通过本周的学习,我认识到了更加底层的逻辑,对Hive有了更加深刻的认识。希望在下一周的学习中能够继续学到新的知识。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









