







题目来源
数据特点
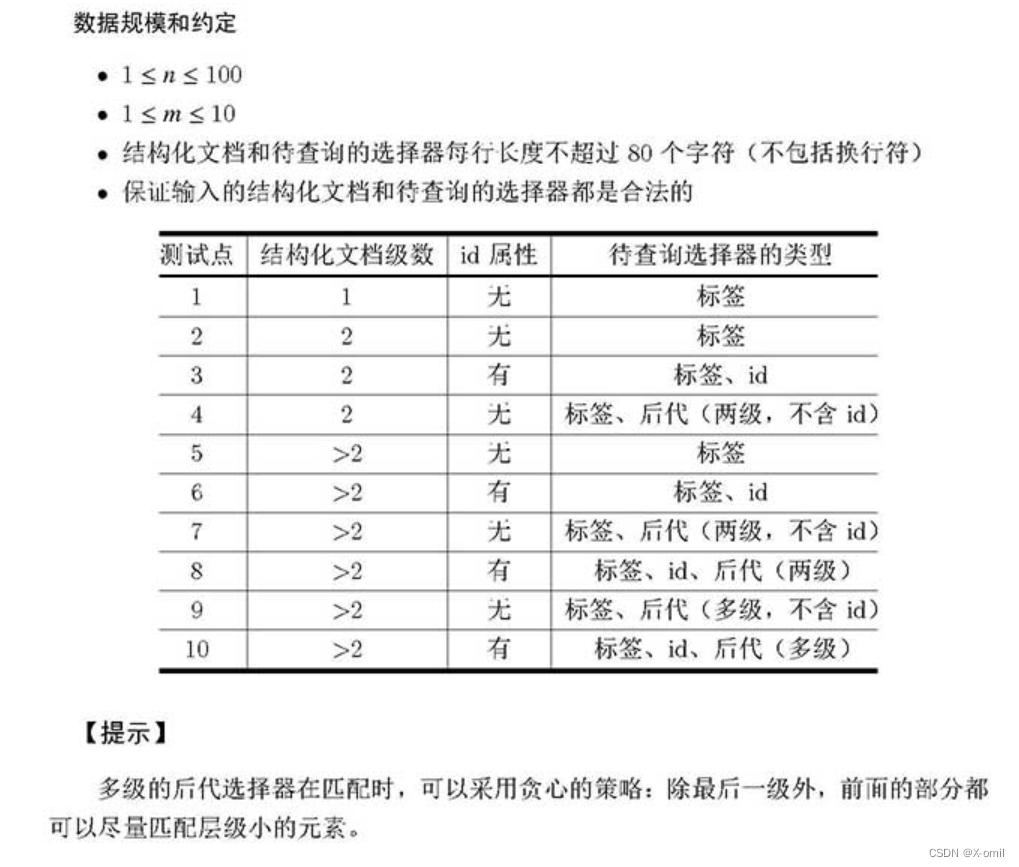
知识点
-
大小写转换:
tolower() 大写转小写。 (其他字符不会变)
c++大小写字符、数字的判断及转换函数
isalpha()
isalnum()
islower()
isupper()
toupper(char)
tolower(char)
isdigit()
to_string() // 将数字转换为字符串 -
fgets(chars, 100, stdin); chars 得是char数组, 是指针的话会出错。
-
getchar() 获取一个字符, 可以用来去掉多余的换行符。
1. getchar(); 2. while(getchar() != '\n) { xxx } -
getline(cin, stringname); stringname是string类型的变量名称。 (位于 #include < string > 头文件中)
当 cin 读取数据时,它会传递并忽略任何前导白色空格字符(空格、制表符或换行符)。一旦它接触到第一个非空格字符即开始阅读,当它读取到下一个空白字符时,它将停止读取。 C++ getline函数用法详解
getline()有两种来源, 用法有点差别。 C++中getline()的用法详解
30分
朝着10分写的
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
using namespace std;
int main() {
ifstream cin("in2.txt");
int N, M;
cin>>N>>M;
string input[N] = {""};
// 获取结构化文档数据
for (int i = 0; i < N; ++i) {
string str;
cin>>str;
int index = 0;
while (index < str.size() && str[index] == '.') {
++index;
}
while (index < str.size()) {
input[i] += tolower(str[index]);
++index;
}
}
// 获取待查询的选择器
for (int i = 0; i < M; ++i) {
string str;
cin>>str;
//getline(str); // 获取一行的信息
for (int j = 0; j < str.size(); ++j) {
str[j] = tolower(str[j]);
}
vector<int> curans;
for (int j = 0; j < N; ++j) {
if (input[j] == str) {
curans.push_back(j + 1);
}
}
// 输出答案
int anssize = curans.size();
cout<<anssize;
for (int j = 0; j < anssize; ++j) {
cout<<" "<<curans[j];
}
cout<<endl;
}
return 0;
}
60分
仅考虑两层且后代选择器全为标签选择器的场景。
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <map>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
struct Node {
int fatherindex;
int level;
int row;
string elem;
string id;
}nodes[101];
int nodesnum = 0;
map<string, vector<int>> elem2index, id2index; // 记录映射关系表
int main() {
int N, M;
cin>>N>>M;
getchar(); // 去除换行
// 获取结构化文档数据
int preindex = -1; // 前一个元素的下标
for (int i = 0; i < N; ++i) {
char chars[100] ; //= " ";
fgets(chars, 100, stdin); // // 获取一行的信息
string str = chars;
str = str.substr(0, str.size() - 1); // 去除换行符
int strindex = 0;
// 记录 .. 数
int level = 0;
while (strindex < str.size() && str[strindex] == '.') {
strindex += 2;
++level;
}
// 获得 元素
string elem = "";
while (strindex < str.size() && str[strindex] != ' ') {
elem += tolower(str[strindex]); // 全变为小写 (如果有数字会不会出错?)
++strindex;
}
// 获得 id属性
strindex += 1; // 跳到 #
string id = "";
while (strindex < str.size()) {
id += tolower(str[strindex]); // 全变为小写 (如果有数字会不会出错?)
++strindex;
}
// 记录映射关系表
elem2index[elem].push_back(i);
if (id != "") {
id2index[id].push_back(i);
}
// 记录当前节点
if (level == 0) { // 初始节点
nodes[nodesnum] = {-1, level, i + 1, elem, id};
}
else if (nodes[preindex].level == level - 1) { // 前一个是父节点
nodes[nodesnum] = {preindex, level, i + 1, elem, id};
}
else { // 前一个不是父节点, 仅考虑两层的情况下, 是同级数据
nodes[nodesnum] = {nodes[preindex].fatherindex, level, i + 1, elem, id};
}
++nodesnum;
preindex = i;
}
// 获取待查询的选择器
for (int i = 0; i < M; ++i) {
char chars[100] ; //= " ";
fgets(chars, 100, stdin); // // 获取一行的信息
string str = chars;
for (int j = 0; j < str.size(); ++j) { // 将元素全小写
str[j] = tolower(str[j]);
}
str = str.substr(0, str.size() - 1);
// 处理 选择器
vector<string> selector; // 记录选择器的信息
string tmp;
for (char c: str) {
if (c == ' ') {
selector.push_back(tmp);
tmp = "";
}
else {
tmp.push_back(c);
}
}
if (tmp != "") {
selector.push_back(tmp);
}
// 记录符合条件的元素的行
vector<int> curans; // 记录符合条件的元素的行
if (selector.size() == 1) { // 选择器是 标签选择器 or id选择器
if (selector[0][0] == '#' && id2index.count(selector[0]) != 0) { // id选择器 且 存在
for (int index: id2index[selector[0]]) {
curans.push_back(nodes[index].row);
}
}
else if (selector[0][0] != '#' && elem2index.count(selector[0]) != 0){ // 标签选择器 其 存在
for (int index: elem2index[selector[0]]) {
curans.push_back(nodes[index].row);
}
}
}
else { // 选择器是 后代选择器
// 仅考虑后代只有两层 且只含标签选择器
string A = selector[0], B = selector[1];
if (elem2index.count(B) != 0) { // 存在 B
for (int childindex: elem2index[B]) {
int fatherindex = nodes[childindex].fatherindex;
if (fatherindex != -1) { // B 存在父节点
if (nodes[fatherindex].elem == A) { // B的父节点 是 A
curans.push_back(nodes[childindex].row);
}
}
}
}
}
// 输出答案
int anssize = curans.size();
cout<<anssize;
for (int j = 0; j < anssize; ++j) {
cout<<" "<<curans[j];
}
cout<<endl;
}
return 0;
}
80分
- 处理后代选择器的思路 : 先遍历候选元素再遍历选择器的内容了。
- 标签大小写不敏感、id属性大小写敏感。
#include <iostream>
#include <vector>
#include <string>
#include <map>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
struct Node {
int fatherindex;
int level;
int row;
string elem;
string id;
}nodes[101];
int nodesnum = 0;
int N, M;
map<string, vector<int>> elem2index, id2index; // 记录映射关系表
int main() {
cin>>N>>M;
getchar(); // 去除换行
// 获取结构化文档数据
int preindex = -1; // 前一个元素的下标
for (int i = 0; i < N; ++i) {
char chars[100] ; //= " ";
fgets(chars, 100, stdin); // // 获取一行的信息
string str = chars;
str = str.substr(0, str.size() - 1); // 去除换行符
int strindex = 0;
// 记录 .. 数
int level = 0;
while (strindex < str.size() && str[strindex] == '.') {
strindex += 2;
++level;
}
// 获得 元素
string elem = "";
while (strindex < str.size() && str[strindex] != ' ') {
elem += tolower(str[strindex]); // 全变为小写 (如果有数字会不会出错?)
++strindex;
}
// 获得 id属性
strindex += 1; // 跳到 #
string id = "";
while (strindex < str.size()) {
id += str[strindex]; // !!!!!!id属性大小写敏感!!!!!!
++strindex;
}
// 记录映射关系表
elem2index[elem].push_back(i);
if (id != "") {
id2index[id].push_back(i);
}
// 记录当前节点
if (level == 0) { // 初始节点
nodes[nodesnum] = {-1, level, i + 1, elem, id};
}
else if (nodes[preindex].level == level - 1) { // 前一个是父节点
nodes[nodesnum] = {preindex, level, i + 1, elem, id};
}
else if (nodes[preindex].level == level) { // 同级节点
nodes[nodesnum] = {nodes[preindex].fatherindex, level, i + 1, elem, id};
}
else { // 不是level = 0、 前一个不是父节点也不是同级节点, 要往前找
for (int j = nodesnum - 1; j >= 0; --j) { // 找父元素下标, 即最近的那个level - 1的
if (nodes[j].level == level - 1) {
nodes[nodesnum] = {j, level, i + 1, elem, id};
break;
}
}
}
++nodesnum;
preindex = i;
}
// 获取待查询的选择器
for (int i = 0; i < M; ++i) {
char chars[100] ; //= " ";
fgets(chars, 100, stdin); // // 获取一行的信息
string str = chars;
str = str.substr(0, str.size() - 1);
// 处理 选择器
vector<string> selector; // 记录选择器的信息
string tmp;
for (char c: str) {
if (c == ' ') {
if (tmp[0] != '#') { // elem大小写不敏感!!!! , id敏感!!!
for (int j = 0; j < tmp.size(); ++j) { // 将元素全小写
tmp[j] = tolower(tmp[j]);
}
}
selector.push_back(tmp);
tmp = "";
}
else {
tmp.push_back(c);
}
}
if (tmp != "") {
if (tmp[0] != '#') { // elem大小写不敏感!!!! , id敏感!!!
for (int j = 0; j < tmp.size(); ++j) { // 将元素全小写
tmp[j] = tolower(tmp[j]);
}
//cout<<"HHH"<<endl;
}
selector.push_back(tmp);
}
// 记录符合条件的元素的行
vector<int> curans; // 记录符合条件的元素的行
if (selector.size() == 1) { // 选择器是 标签选择器 or id选择器
if (selector[0][0] == '#' && id2index.count(selector[0]) != 0) { // id选择器 且 存在
for (int index: id2index[selector[0]]) {
curans.push_back(nodes[index].row);
}
}
else if (selector[0][0] != '#' && elem2index.count(selector[0]) != 0){ // 标签选择器 其 存在
for (int index: elem2index[selector[0]]) {
curans.push_back(nodes[index].row);
}
}
}
// 选择器是 !后代选择器!
else { // 选择器是 后代选择器
// 初始化
int selectorsize = selector.size();
vector<int> original; // 存储最初的所在的nodes下标
if (selector[selectorsize - 1][0] == '#') { // id
original = id2index[selector[selectorsize - 1]];
}
else { // elem
original = elem2index[selector[selectorsize - 1]];
}
// 遍历每个候选者
for (int j = 0; j < original.size(); ++j) {
vector<string> curselector = selector; // 当前候选者需要走过的选择器的内容
int curselectorindex = selector.size() - 1; // 初始下标
int curindex = original[j]; // 当前候选者的nodes下标
while (curindex != -1 && curselectorindex >= 0) {
string sele = selector[curselectorindex]; // 当前选择器的内容
if (sele[0] == '#' && nodes[curindex].id == sele) { // id选择器 且 符合
--curselectorindex;
curindex = nodes[curindex].fatherindex;
}
else if (sele[0] != '#' && nodes[curindex].elem == sele){ // 标签选择器 且 符合
--curselectorindex;
curindex = nodes[curindex].fatherindex;
}
else {
break;
}
}
if (curselectorindex == -1) { // 能够走完所有路, 则记录
curans.push_back(nodes[original[j]].row);
}
}
}
// 输出答案
int anssize = curans.size();
cout<<anssize;
for (int j = 0; j < anssize; ++j) {
cout<<" "<<curans[j];
}
cout<<endl;
}
return 0;
}
代码完整思路
-
定义数据结构。
使用下边的结构体存储输入的结构化文档。struct Node { int fatherindex; // 当前行元素的父元素在nodes中的下标 int level; // 用于记录当前元素的层级关系(缩进) int row; // 当前元素所在的行数 string elem; // 当前元素的标签 string id; // 当前元素的id属性 }nodes[101]; // nodes用于存储所有的元素信息使用下面的映射表来记录 元素标签与元素在nodes中的下标 以及 元素id属性与元素在nodes中的下标
map<string, vector<int>> elem2index, id2index; -
在输入结构化文档时, 记录所有的元素信息以及映射信息。
2.1 记录元素的层级关系// 记录 .. 数 int level = 0; while (strindex < str.size() && str[strindex] == '.') { strindex += 2; ++level; }2.2 分离出元素的标签, 标签不区分大小写。代码中统一使用小写
// 获得 元素 string elem = ""; while (strindex < str.size() && str[strindex] != ' ') { elem += tolower(str[strindex]); // 全变为小写 (如果有数字会不会出错?) ++strindex; }2.3 分离出元素的id属性, 标签区分大小写!
// 获得 id属性 strindex += 1; // 跳到 '#' string id = ""; while (strindex < str.size()) { id += str[strindex]; // !!!!!!id属性大小写敏感!!!!!! ++strindex; }2.4 记录映射关系表
// 记录映射关系表 elem2index[elem].push_back(i); if (id != "") { id2index[id].push_back(i); }2.5 记录当前元素的信息到 nodes中。要特别注意这四种情况。
// 记录当前节点 if (level == 0) { // 初始节点 nodes[nodesnum] = {-1, level, i + 1, elem, id}; } else if (nodes[preindex].level == level - 1) { // 前一个是父节点 nodes[nodesnum] = {preindex, level, i + 1, elem, id}; } else if (nodes[preindex].level == level) { // 同级节点 nodes[nodesnum] = {nodes[preindex].fatherindex, level, i + 1, elem, id}; } else { // 不是level = 0、 前一个不是父节点也不是同级节点, 要往前找 for (int j = nodesnum - 1; j >= 0; --j) { // 找父元素下标, 即最近的那个level - 1的 if (nodes[j].level == level - 1) { nodes[nodesnum] = {j, level, i + 1, elem, id}; break; } } -
在待查询的选择器时, 处理标签选择器、id选择器(选择器长度为1)以及后代选择器(后代选择器是由前两种构成的, 长度未定)。
3.1 处理每一行的选择器信息,根据空格将选择器分开。 注意标签的大小写不敏感, id属性敏感。
// 处理 选择器 vector<string> selector; // 记录选择器的信息 string tmp; for (char c: str) { if (c == ' ') { if (tmp[0] != '#') { // elem大小写不敏感!!!! , id敏感!!! for (int j = 0; j < tmp.size(); ++j) { // 将元素全小写 tmp[j] = tolower(tmp[j]); } } selector.push_back(tmp); tmp = ""; } else { tmp.push_back(c); } } if (tmp != "") { if (tmp[0] != '#') { // elem大小写不敏感!!!! , id敏感!!! for (int j = 0; j < tmp.size(); ++j) { // 将元素全小写 tmp[j] = tolower(tmp[j]); } } selector.push_back(tmp); }3.2 当待询问的选择器为 标签选择器 或 id选择器时:
// 记录符合条件的元素的行 vector<int> curans; // 记录符合条件的元素的行 if (selector.size() == 1) { // 选择器是 标签选择器 or id选择器 if (selector[0][0] == '#' && id2index.count(selector[0]) != 0) { // id选择器 且 存在 for (int index: id2index[selector[0]]) { curans.push_back(nodes[index].row); } } else if (selector[0][0] != '#' && elem2index.count(selector[0]) != 0){ // 标签选择器 其 存在 for (int index: elem2index[selector[0]]) { curans.push_back(nodes[index].row); } } }3.3 当待询问的选择器为 后代选择器: 根据目标选择器(最后的那个)选出候选者,遍历每个每个候选者时遍历每个选择器中的内容, 看候选者是否符合要求。符合要求则将其所在行数计入答案curans中。
// 选择器是 !后代选择器! else { // 选择器是 后代选择器 // 初始化 int selectorsize = selector.size(); vector<int> original; // 存储最初的所在的nodes下标 if (selector[selectorsize - 1][0] == '#') { // id original = id2index[selector[selectorsize - 1]]; } else { // elem original = elem2index[selector[selectorsize - 1]]; } // 遍历每个候选者 for (int j = 0; j < original.size(); ++j) { //cout<<"*"<<curans.size()<<endl; vector<string> curselector = selector; // 当前候选者需要走过的选择器的内容 int curselectorindex = selector.size() - 1; // 初始下标 int curindex = original[j]; // 当前候选者的nodes下标 // 遍历每个选择器的内容 while (curindex != -1 && curselectorindex >= 0) { string sele = selector[curselectorindex]; // 当前选择器的内容 if (sele[0] == '#') { // id选择器 if (nodes[curindex].id == sele) { // 符合 --curselectorindex; //cout<<"**id "<<nodes[curindex].id<<" "<<sele<<endl; } curindex = nodes[curindex].fatherindex; } else { // 标签选择器 if (nodes[curindex].elem == sele) { // 符合 --curselectorindex; //cout<<"**elem "<<nodes[curindex].elem<<" "<<sele<<endl; } curindex = nodes[curindex].fatherindex; } } if (curselectorindex == -1) { // 能够走完所有路, 则记录 curans.push_back(nodes[original[j]].row); } } }3.4 输出答案
// 输出答案 int anssize = curans.size(); cout<<anssize; for (int j = 0; j < anssize; ++j) { cout<<" "<<curans[j]; } cout<<endl;
100分
之前在处理后代选择器的遍历每个选择器的内容时, if else部分逻辑不对。现在修改啦。
11 6
html
..head
....title
..body
....h1
....div #main
....P #subtiTle
......h2
........p #one
......div
........p #two
P
#subtitle
h3
div p
#subtiTle h2 #one
html div #two
对于之前的代码,上边示例中最后的 html div #two 无法处理。
#include <iostream>
#include <vector>
#include <string>
#include <map>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
struct Node {
int fatherindex;
int level;
int row;
string elem;
string id;
}nodes[101];
int nodesnum = 0;
int N, M;
map<string, vector<int>> elem2index, id2index; // 记录映射关系表
int main() {
cin>>N>>M;
getchar(); // 去除换行
// 获取结构化文档数据
int preindex = -1; // 前一个元素的下标
for (int i = 0; i < N; ++i) {
char chars[100] ; //= " ";
fgets(chars, 100, stdin); // // 获取一行的信息
string str = chars;
str = str.substr(0, str.size() - 1); // 去除换行符
int strindex = 0;
// 记录 .. 数
int level = 0;
while (strindex < str.size() && str[strindex] == '.') {
strindex += 2;
++level;
}
// 获得 元素
string elem = "";
while (strindex < str.size() && str[strindex] != ' ') {
elem += tolower(str[strindex]); // 全变为小写 (如果有数字会不会出错?)
++strindex;
}
// 获得 id属性
strindex += 1; // 跳到 #
string id = "";
while (strindex < str.size()) {
id += str[strindex]; // !!!!!!id属性大小写敏感!!!!!!
++strindex;
}
// 记录映射关系表
elem2index[elem].push_back(i);
if (id != "") {
id2index[id].push_back(i);
}
// 记录当前节点
if (level == 0) { // 初始节点
nodes[nodesnum] = {-1, level, i + 1, elem, id};
}
else if (nodes[preindex].level == level - 1) { // 前一个是父节点
nodes[nodesnum] = {preindex, level, i + 1, elem, id};
}
else if (nodes[preindex].level == level) { // 同级节点
nodes[nodesnum] = {nodes[preindex].fatherindex, level, i + 1, elem, id};
}
else { // 不是level = 0、 前一个不是父节点也不是同级节点, 要往前找
for (int j = nodesnum - 1; j >= 0; --j) { // 找父元素下标, 即最近的那个level - 1的
if (nodes[j].level == level - 1) {
nodes[nodesnum] = {j, level, i + 1, elem, id};
break;
}
}
}
++nodesnum;
preindex = i;
}
// 获取待查询的选择器
for (int i = 0; i < M; ++i) {
char chars[100] ; //= " ";
fgets(chars, 100, stdin); // // 获取一行的信息
string str = chars;
str = str.substr(0, str.size() - 1);
// 处理 选择器
vector<string> selector; // 记录选择器的信息
string tmp;
for (char c: str) {
if (c == ' ') {
if (tmp[0] != '#') { // elem大小写不敏感!!!! , id敏感!!!
for (int j = 0; j < tmp.size(); ++j) { // 将元素全小写
tmp[j] = tolower(tmp[j]);
}
}
selector.push_back(tmp);
tmp = "";
}
else {
tmp.push_back(c);
}
}
if (tmp != "") {
if (tmp[0] != '#') { // elem大小写不敏感!!!! , id敏感!!!
for (int j = 0; j < tmp.size(); ++j) { // 将元素全小写
tmp[j] = tolower(tmp[j]);
}
}
selector.push_back(tmp);
}
// 记录符合条件的元素的行
vector<int> curans; // 记录符合条件的元素的行
if (selector.size() == 1) { // 选择器是 标签选择器 or id选择器
if (selector[0][0] == '#' && id2index.count(selector[0]) != 0) { // id选择器 且 存在
for (int index: id2index[selector[0]]) {
curans.push_back(nodes[index].row);
}
}
else if (selector[0][0] != '#' && elem2index.count(selector[0]) != 0){ // 标签选择器 其 存在
for (int index: elem2index[selector[0]]) {
curans.push_back(nodes[index].row);
}
}
}
// 选择器是 !后代选择器!
else { // 选择器是 后代选择器
// 初始化
int selectorsize = selector.size();
vector<int> original; // 存储最初的所在的nodes下标
if (selector[selectorsize - 1][0] == '#') { // id
original = id2index[selector[selectorsize - 1]];
}
else { // elem
original = elem2index[selector[selectorsize - 1]];
}
// 遍历每个候选者
for (int j = 0; j < original.size(); ++j) {
vector<string> curselector = selector; // 当前候选者需要走过的选择器的内容
int curselectorindex = selector.size() - 1; // 初始下标
int curindex = original[j]; // 当前候选者的nodes下标
// 遍历每个选择器的内容
while (curindex != -1 && curselectorindex >= 0) {
string sele = selector[curselectorindex]; // 当前选择器的内容
if (sele[0] == '#') { // id选择器
if (nodes[curindex].id == sele) { // 符合
--curselectorindex;
}
curindex = nodes[curindex].fatherindex;
}
else { // 标签选择器
if (nodes[curindex].elem == sele) { // 符合
--curselectorindex;
}
curindex = nodes[curindex].fatherindex;
}
}
if (curselectorindex == -1) { // 能够走完所有路, 则记录
curans.push_back(nodes[original[j]].row);
}
}
}
// 输出答案
int anssize = curans.size();
cout<<anssize;
for (int j = 0; j < anssize; ++j) {
cout<<" "<<curans[j];
}
cout<<endl;
}
return 0;
}















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









