






目录
定义
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器人等,可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络爬虫算法。使用Python可以很方便地编写出爬虫程序,进行互联网信息的自动化检索。
基本原理
爬虫的工作原理是通过发送HTTP请求从网页服务器获取的内容,然后解析网页并提取所需的数据。具体步骤如下:
1. 发送HTTP请求:通过爬虫程序发送HTTP请求到目标网站的服务器,请求获取网页的内容。
2. 接收网页内容:爬虫程序接收到服务器返回的网页内容,这通常是HTML、XML或JSON格式的文本。
3. 解析网页:爬虫程序使用解析器(如解析库或正则表达式)对网页内容进行解析,提取出需要的数据,如文本、链接、图片地址等。
4. 数据处理和存储:爬虫程序对提取的数据进行处理,进行清洗、筛选、转换等操作,然后将数据保存到数据库、文件或其他存储介质中。
5. 进行下一步操作:根据需要,爬虫程序可以继续访问其他链接,深入爬取更多的网页内容,或者执行其他相关任务。
应用
爬虫主要应用于数据采集、搜索引擎、监测与分析、推荐系统、自动化任务等领域。通过爬虫,可以自动化地收集互联网上的信息,并进行数据分析和运用,从而为用户提供更丰富的服务和策略。
例子
爬取网页数据,首先分析源码,思考构造什么样的正则表达式
import requests
import re
import time
url = "http://10.9.46.192/spider/"
def get_html(url) :
res = requests.get(url = url)
html = res.text
return html
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.5195.102 Safari/537.36"
}
def get_img_path_list(html) :
img_path_re = r"style/\w+\.jpg"
img_path_list = re.findall(img_path_re,html)
return img_path_list
def download_img(img_path) :
full_url = url + img_path
print(f"Image URL: {full_url}")
res =requests.get(url = full_url)
img_save_path = f"./img/{time.time()}.jpg"
with open(img_save_path,'wb') as f:
f.write(res.content)
html = get_html(url =url)
img_path_list = get_img_path_list(html = html)
for img_path in img_path_list:
download_img(img_path)
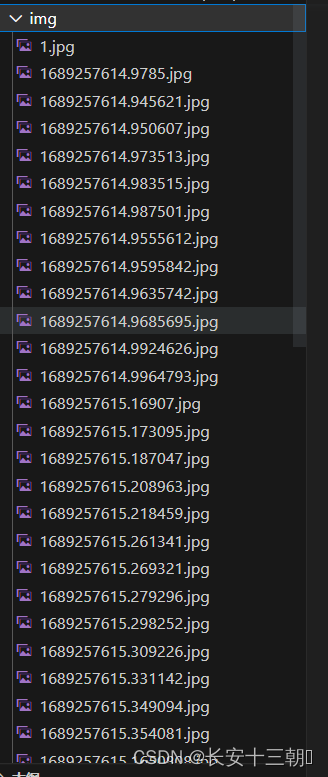
最后将图片下载到img目录下
爬虫的高效性与python密不可分
进行python开发时,可以使用多种库来进行实现,以下是几种常见的模块
time模块

datetime模块

random随机模块

注意 :文件名不要用random命名,不然会直接调用
正则模块
匹配规则
[0-9] 代表匹配所有的0-9数字
[a-z] 代表匹配所有a-z的字符
[A-Z]代表匹配所有A-Z的字符
[^0-9] 代表匹配除了0-9之外所有字符
\d代表数字字符 =0-9
\w代表英文字符 =a-z
\s 代表空白符 以及换行符
\D代表非数字字符
\W代表非单词字符
\S代表非空白字符
.代表任意字符,不包含换行符
^a只能匹配行首的a
a$只会匹配行尾的a
#[a-zA-Z0-9]{6} \b 匹配十六进制颜色
















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









