









文章目录
前言
flume安装和使用
一、Flume定义
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
二、Flume安装部署
1.上传压缩包
如图:
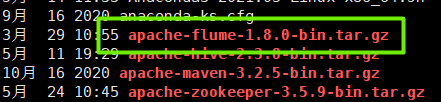
2.解压、修改配置文件
2.1解压
tar -zxvf apache-flume-1.8.0-bin.tar.gz -C /usr
#解压后进行改名
mv apache-flume-1.8.0-bin flume
flume目录下有如下文件

2.2修改配置文件
进入flume目录下的conf目录 cd conf
#改名
mv flume-env.sh.template flume-env.sh
#编辑文件
vim flume-env.sh
添加如下内容
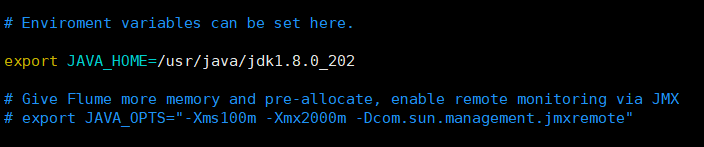
三、Flume简单使用
3.1 使用 Flume 监听一个端口,收集该端口数据,并打印到控制台
在flume下创建job目录,在job下创建任务文件
mkdir job
cd job
vim flume-netcat-logger.conf
文件内容如下
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
开启flume监听端口
[root@master1 flume]# ./bin/flume-ng agent --conf conf --name a1 --conf-file
job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
再开启一个窗口使用 nc工具对44444端口发送内容
若无nc工具可进行下载
yum install -y nc
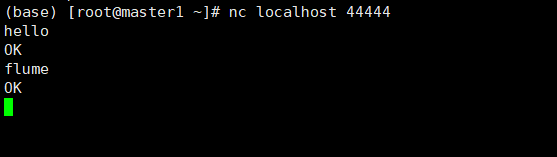
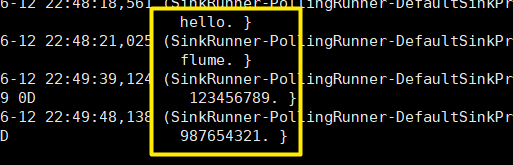
接收成功

也可以使用telnet工具
*两者区别*
telnet可以实现的功能:
连接服务器端口,并进行通信
登录远程telnet服务器,使用命令行对其进行控制
nc可以实现的功能:
监听服务器端口,并与客户端通信(最多只能接收一个客户端)
对指定服务器进行端口扫描
作为客户端连接到远程服务器进行通信
[详见](https://blog.csdn.net/iknow_nothing/article/details/84335647)

3.2 使用 Flume 监听本地目录,将目录下的文件上传hdfs
- 启动hadoop集群
#在hadoop安装目录下
sbin/start-all.sh
- 创建监听目录
在job目录下创建要监听的目录
mkdir [目录名]
- job目录下创建任务文件
vim flume-dir-hdfs.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
#监听的目录位置
a1.sources.r1.spoolDir = /usr/flume/job/[目录名]
a1.sources.r1.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a1.sources.r1.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a1.sinks.k1.type = hdfs
#要存储的hdfs目录位置
a1.sinks.k1.hdfs.path = hdfs://master1:9000/[hdfs目录名]/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix =[目录名]-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0
#最小冗余数
a1.sinks.k1.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 开启监听
[root@master1 flume]# ./bin/flume-ng agent --conf conf --name a1 --conf-file job/flume-dir-hdfs.conf
- 进入创建的本地监听目录下创建新的文件并写入内容
vim testflumefile.txt
- hdfs查看
hdfs dfs -ls -R /cjzhdfs dfs -cat /cjz/20210613/13/caojinze-.1623560682501.tmp
















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









