







 本文介绍了Kafka集群中Controller的角色及其重要性,探讨了如何通过Controller管理集群元数据及分区副本分配策略,并提供了针对大数据量场景下服务器配置的建议。
本文介绍了Kafka集群中Controller的角色及其重要性,探讨了如何通过Controller管理集群元数据及分区副本分配策略,并提供了针对大数据量场景下服务器配置的建议。
参考016 - 大数据 - Kafka - 组件扩展 - controller_哔哩哔哩_bilibili
链接:https://pan.baidu.com/s/1QMOJVkRy4nKkjzoDryvQXw
提取码:fcoe
本文接着上一篇kafka和flink的入门到精通 2 系统架构,实时数仓架构,Kafka_水w的博客-CSDN博客
目录
◼ 组件扩展:
1.broker有多个, 那么都用zookeeper来管理的话,会有什么问题?
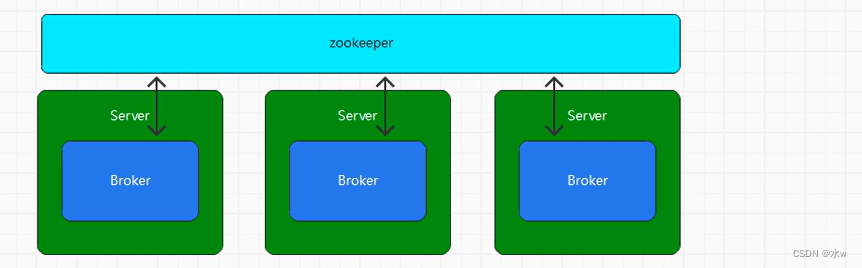
Kafka中如果所有的节点的管理,消息的管理全部都用zookeeper来管理,那么?
zookeeper不擅长这种管理,因为过程中会导致大量读写请求操作,而这个不是zookeeper擅长的。因此需要从所有的broker中选举一个节点作为管理者Controller。
其实在zookeeper中可以注册一个节点Controller,只要这个Controller存在,就说明已经选举一个节点。所有的broker节点向zookeeper发送创建Controller请求,第一个创建成功的节点就是Controller节点。

可以看到,说明broker-0先抢占到了Controller节点,成为Controller。
2.如果broker-0是Controller,来管理这个集群。那么如果broker-0宕掉了,怎么办?
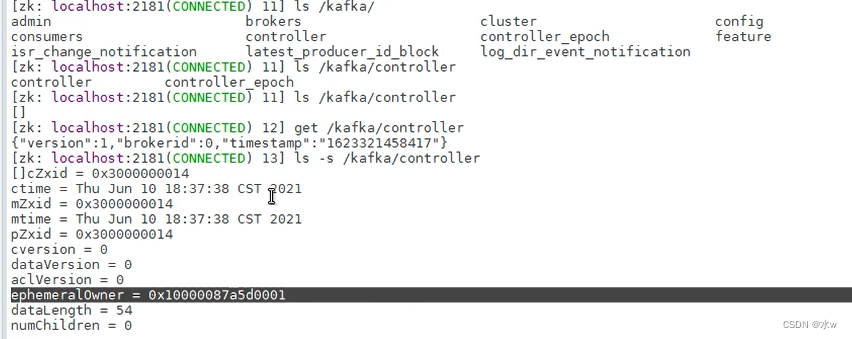
可以看到,当前的Controller节点其实是一个临时节点,一旦和broker节点失去联系,这个临时节点就会消失。一旦节点消失,就没有Controller了,其他的broker就可以抢占了,重新开始争抢节点操作,谁先抢到就是Controller。
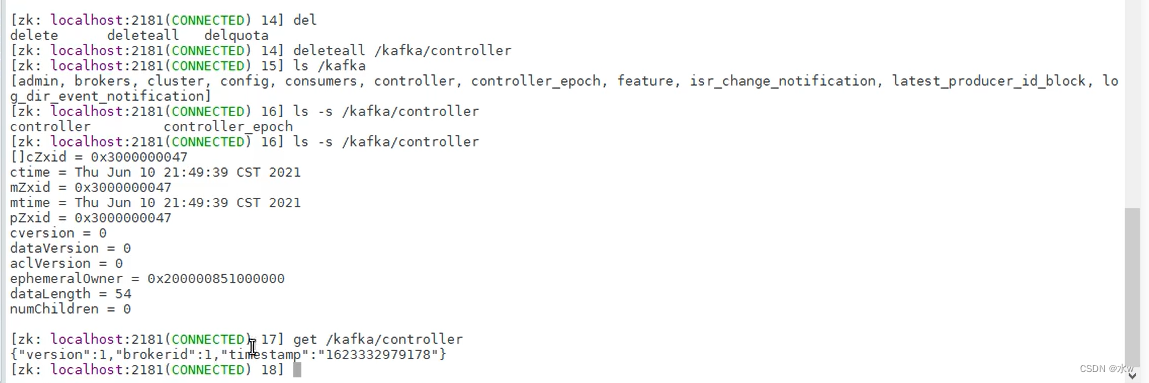
可以看到,当前的Controller节点不再是之前的broker-0了, 变成了broker-1。
3.可能会有多个Controller同时出现,同时起作用吗?
因为我们可以看到的节点当中,除了Controller,还有另外一个Controller-epoch选举版本号, 是控制器的选举操作。
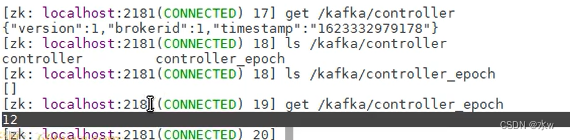
可以看到,这里面有一个号码“12”,这个号码就是我们的选举编号。选举一次,编号就不一样了。并且所有的集群只看最新的编号,不会看是不是Controller。
那么接着上文,一旦节点消失,就没有Controller了,其他的broker就可以抢占了,重新开始争抢节点操作,谁先抢到就是Controller。同时Controller-epoch会累加。累加后,所有的集群都遵循最新的编号的Controller的操作。
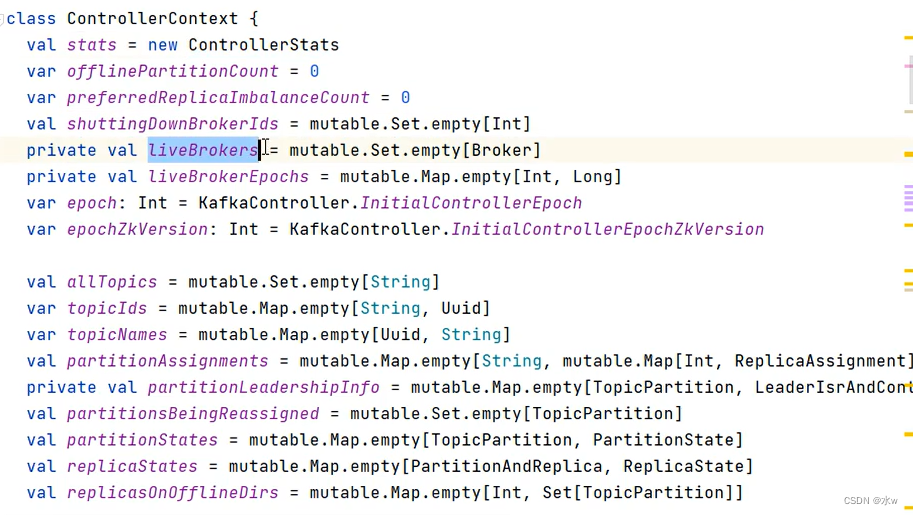
Controller:管理集群的全部元数据信息,将这些信息同步到其他Broker中。其他的Broker不和zookkeeper交互,只和Controller交互。
比如 ControllerContext包含了很多关于集群的信息,包括副本和分区的状态等等。
◼ 组件扩展:分区分配
4.Topic是主题(消息分类),那么我们怎么创建?
创建过程可以通过指令,也可以通过客户端:
- 连接kafka-topic.sh脚本文件,连接Linux1虚拟机的kafka集群。
- 向里面添加一个主题Topic;
- 创建Topic的名字,告诉里面有3个分区;
- 副本因子/系数为2,意思是每个分区给2个: leader和follower;

回车就会创建好了主题Topic。 我们也可以查看主题Topic信息,
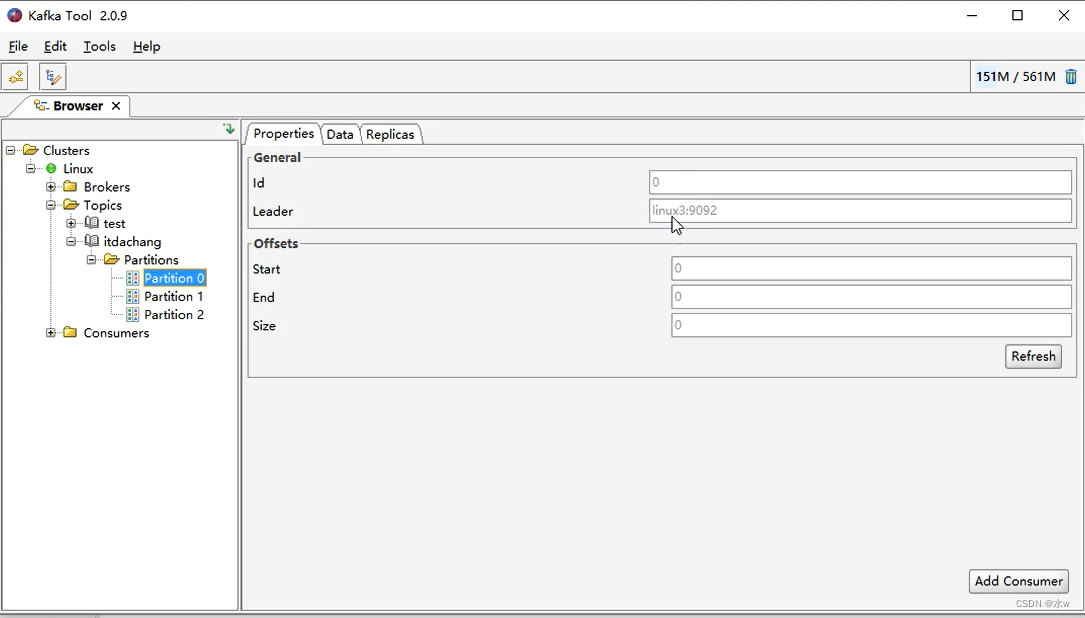
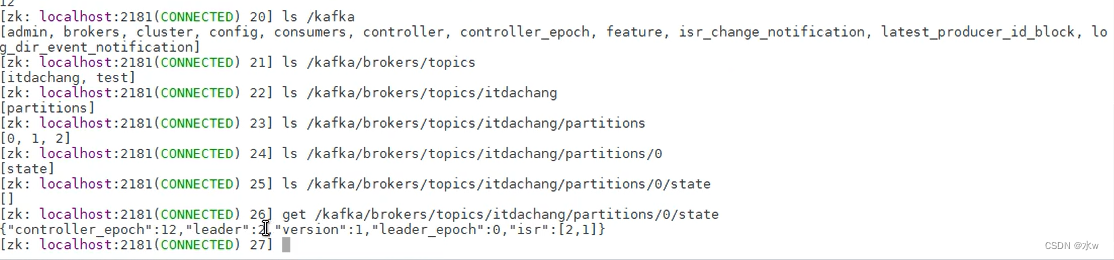
可以看到,当前在这个场合下的leader是“2”,而且ISR的第一个参数2就是leader,第二个参数2就是follower。
ISR:同步副本
而且分区里已经有了log日志文件。
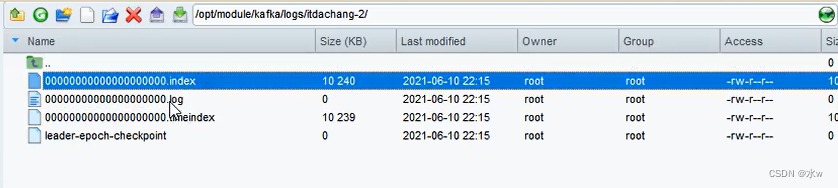
4.分区和副本的存放问题?
我们现在有3个broker,创建分区和副本之后,应该放在哪个broker当中?
3个broker,3个分区,每个分区2个副本,
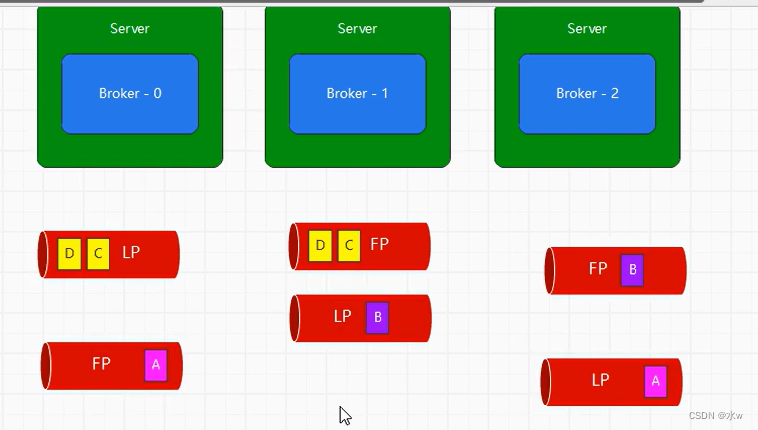
最直观的想法就是轮询进行存放,有风险:可能会在一个broker中存在大量的分区。
kafka采用特殊方式,实际分配分区和副本时,随机从当前的集群中找到一个节点进行存放。比如,找到的第一个节点时broker-2,那么存放的就是第一个分区。
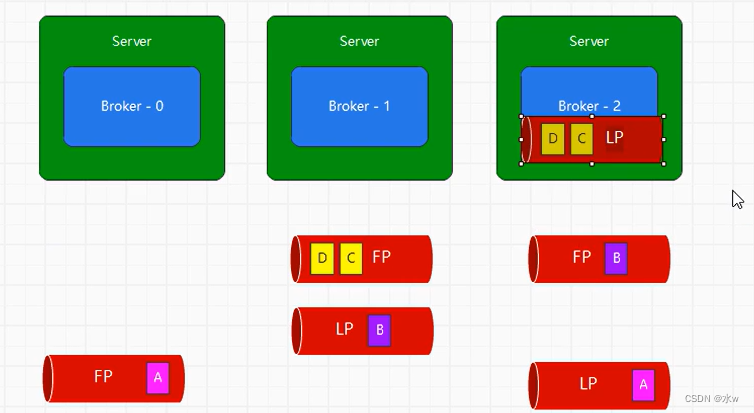
然后再轮询broker-2分区到其他分区broker-0,broker-1,进行存放。
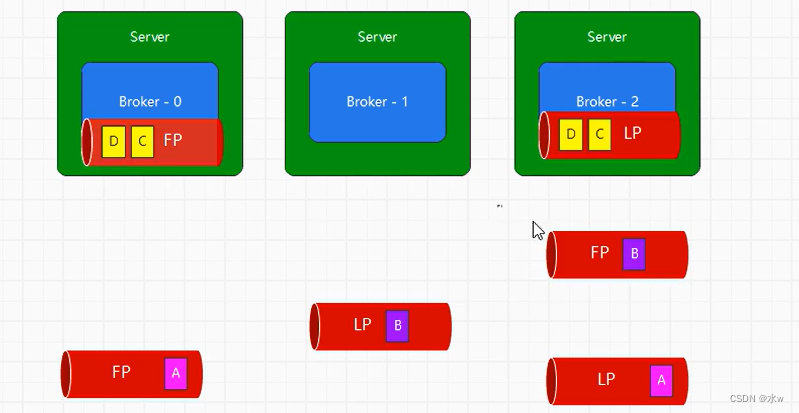

最后,
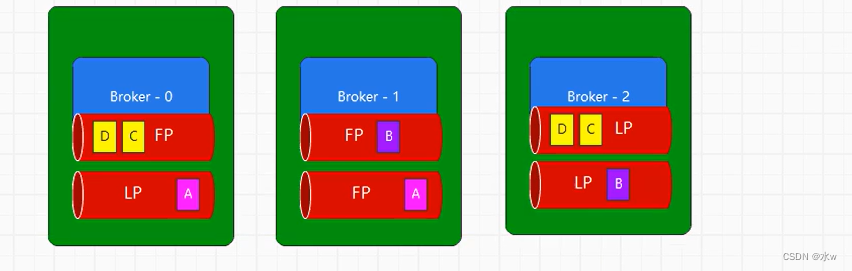
分配原则:
- 将副本平均分布在所有的broker上;
- 一个分区的多个副本,应该分配到不同的broker上;
- 如果boker有机架,那么副本应该分配搭配不同的机架上;
◼ 服务器推荐配置
假如100万的每天活动用户,会产生100万x100万条=1亿条的用户行为数据,每条数据1kb,那么大概有100G的数据量。
5.那么我们怎么去配置和购买服务器?网络带宽和磁盘数量该怎么去考虑?
凌晨12点-早上8点的数据量很少,可以忽略不记。那么1亿条基本上都在16个小时里面获取。那么每秒1750条,平均每秒处理2MB数据。

有一个比较权威的公式可以来计算,副本一般是2个, 那么服务器的数量应该是4台。

磁盘大小:2个副本,数据不可能来一条就删掉,kafka会有一个保存的时间,默认7天。那么我们设置存储3天的数据。
内存大小:原则上应该把日志文件都放在内存中,可以快速访问。而且副本是用来做备份的,并不是真正的。那么每一台大概128G。

我们把数据都放在内存,指的不是java的内存,而是操作系统的页缓冲上。JVM就不要占太多的内存,6-10G就可以了。
◼ 回顾kafka
四、kafka-生产者
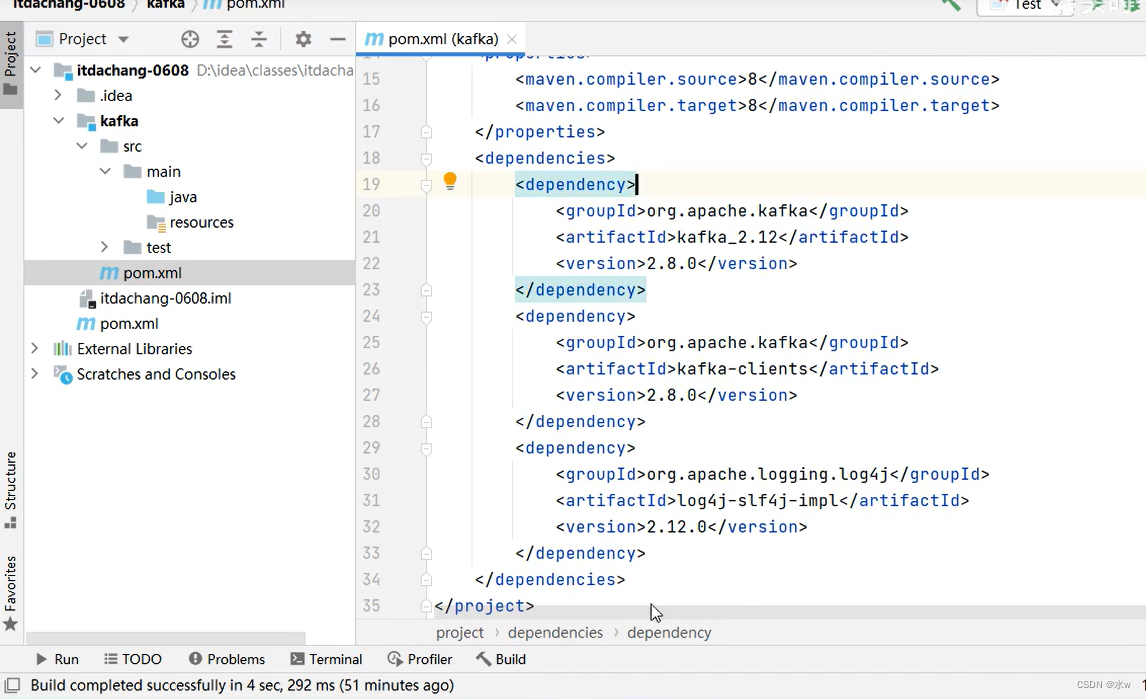
POM依赖:
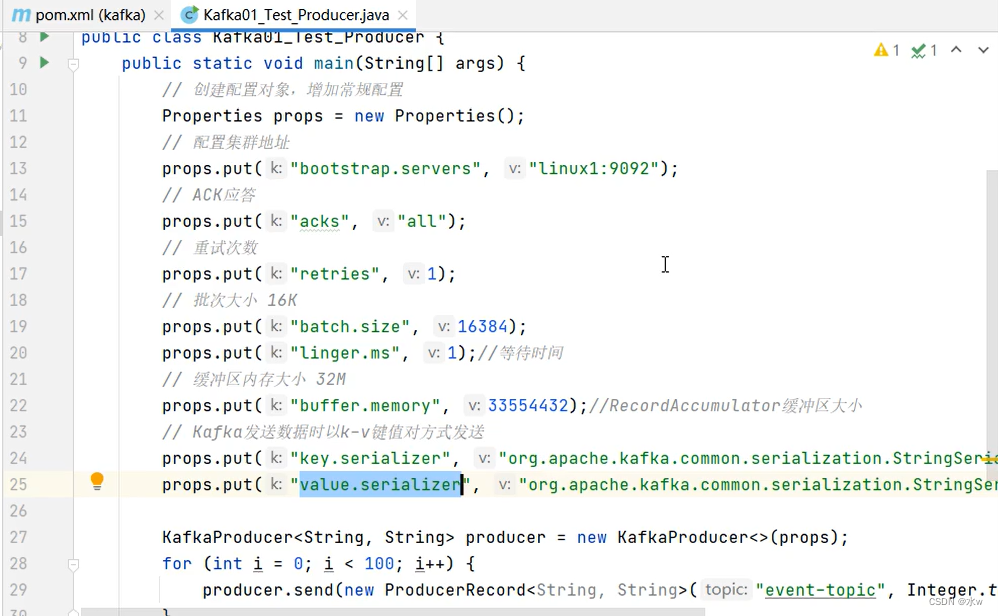
◼ 生产数据
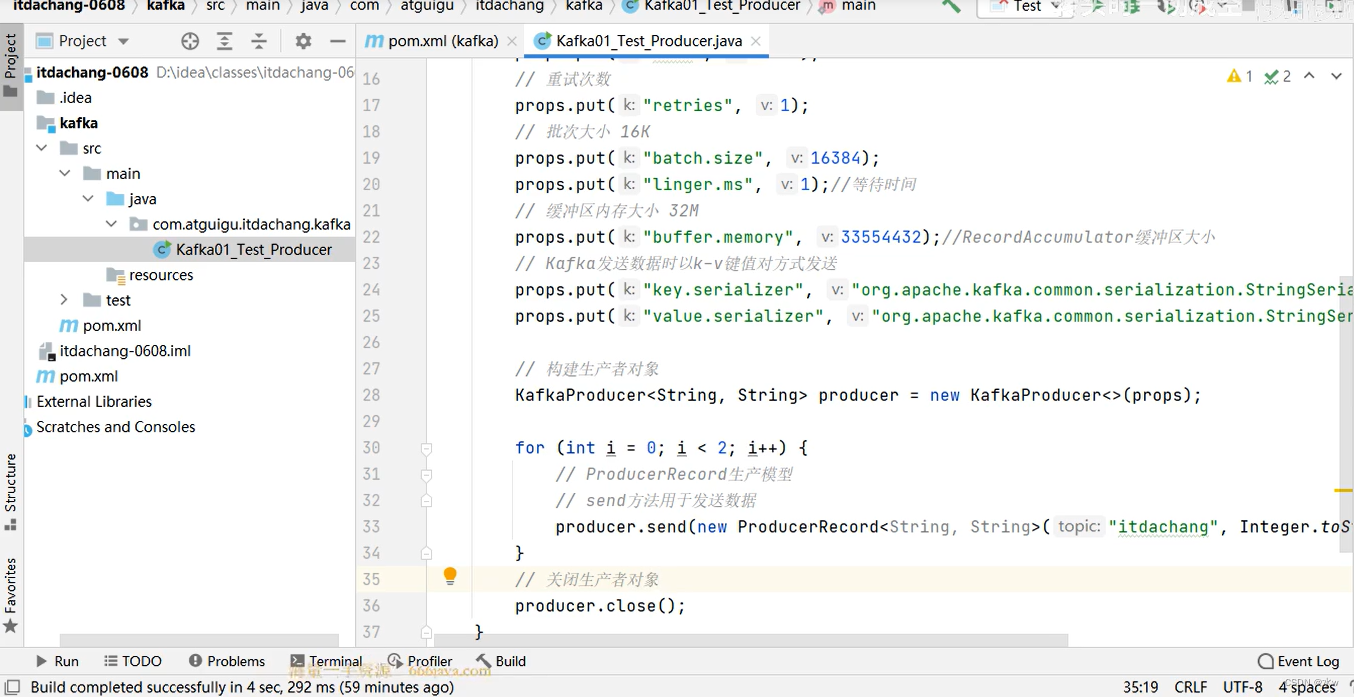
代码流程:
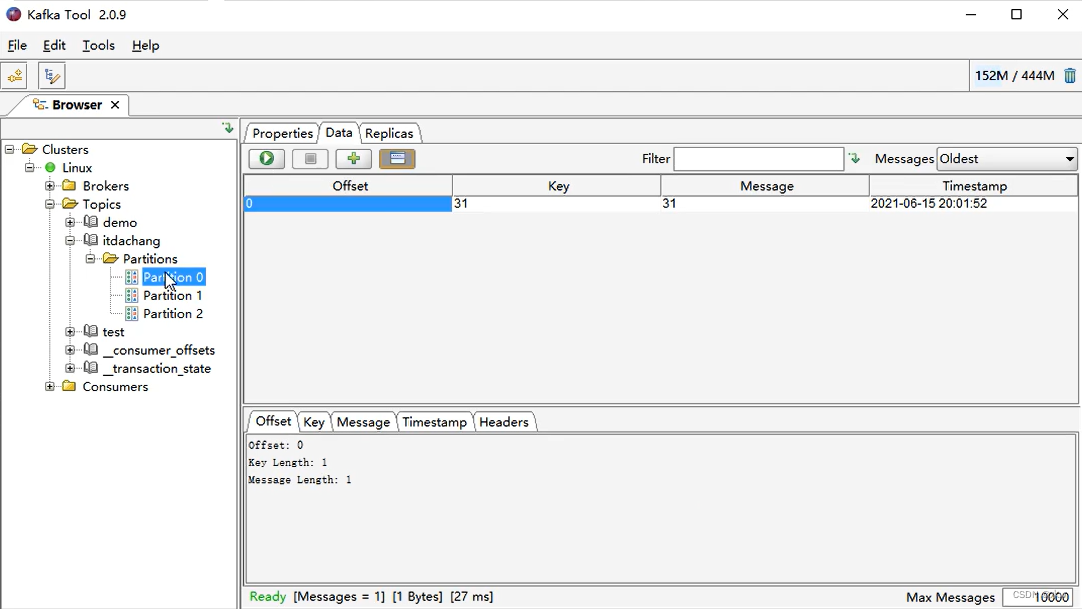
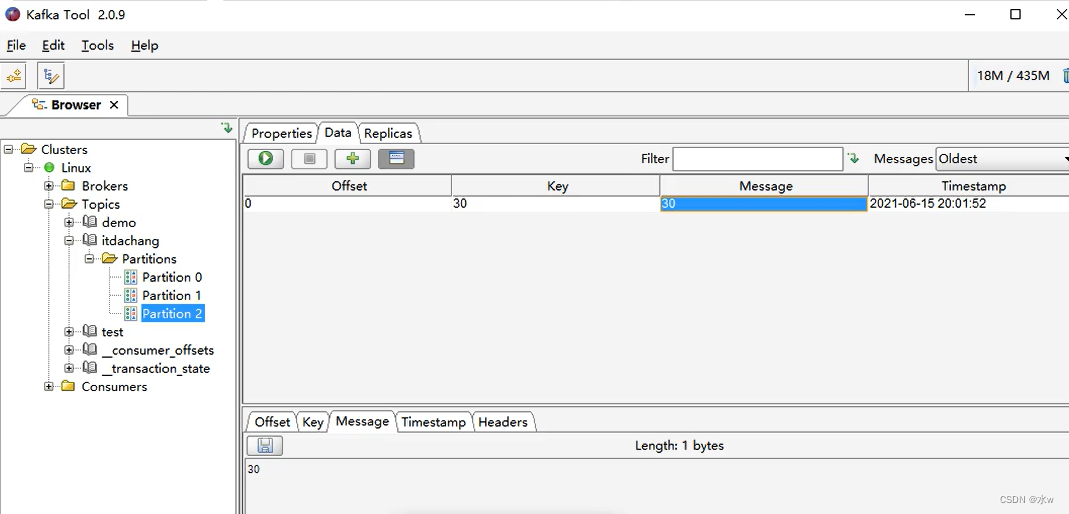
运行代码之后,可以看到只有Partition-0和Partition-2当中已经有数据了,Partition-1没有。(数据的展现方式不一样。)
◼ 发送数据
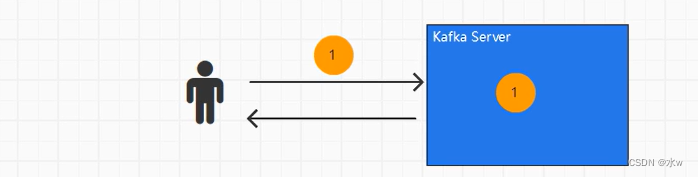
6.生产数据,怎么就可以让它快了?
如果用户发一条消息过来,接受到之后会发一条消息给用户说已经发送成功了,可以发下一个了。那么这样生产数据会很慢。
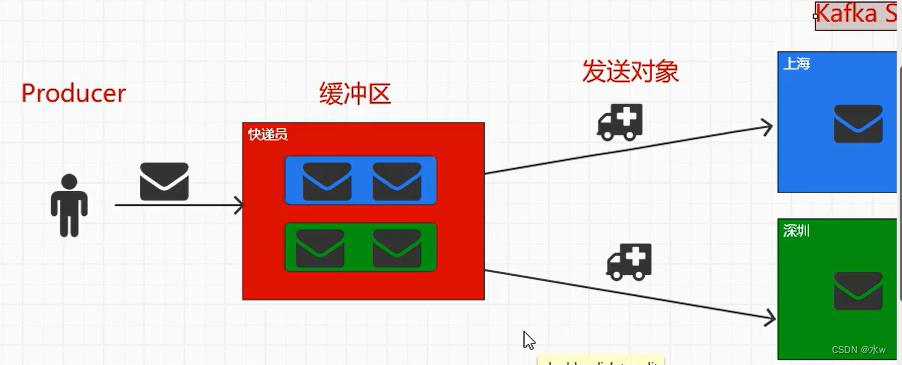
假设生活中我们要寄快递,我们应该直接把多个快递给快递员,快递员收到快递会进行分类整合,快递员的目的就是分拣,用运输工具来发送。 那么快递员就是缓冲区,运输工具就指的是发送对象。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











