






1、研究背景

2、贡献
-
我们提出了第一个不依赖于配对和非配对训练数据的低光增强网络,从而避免了过拟合的风险。因此,我们的方法能够很好地泛化到各种光照条件。
-
我们设计了一种图像特定的曲线,能够通过迭代应用自身来逼近像素级和高阶曲线。这种图像特定的曲线可以在宽动态范围内有效地进行映射。
-
我们展示了在没有参考图像的情况下,通过任务特定的无参考损失函数间接评估增强质量,训练深度图像增强模型的潜力。
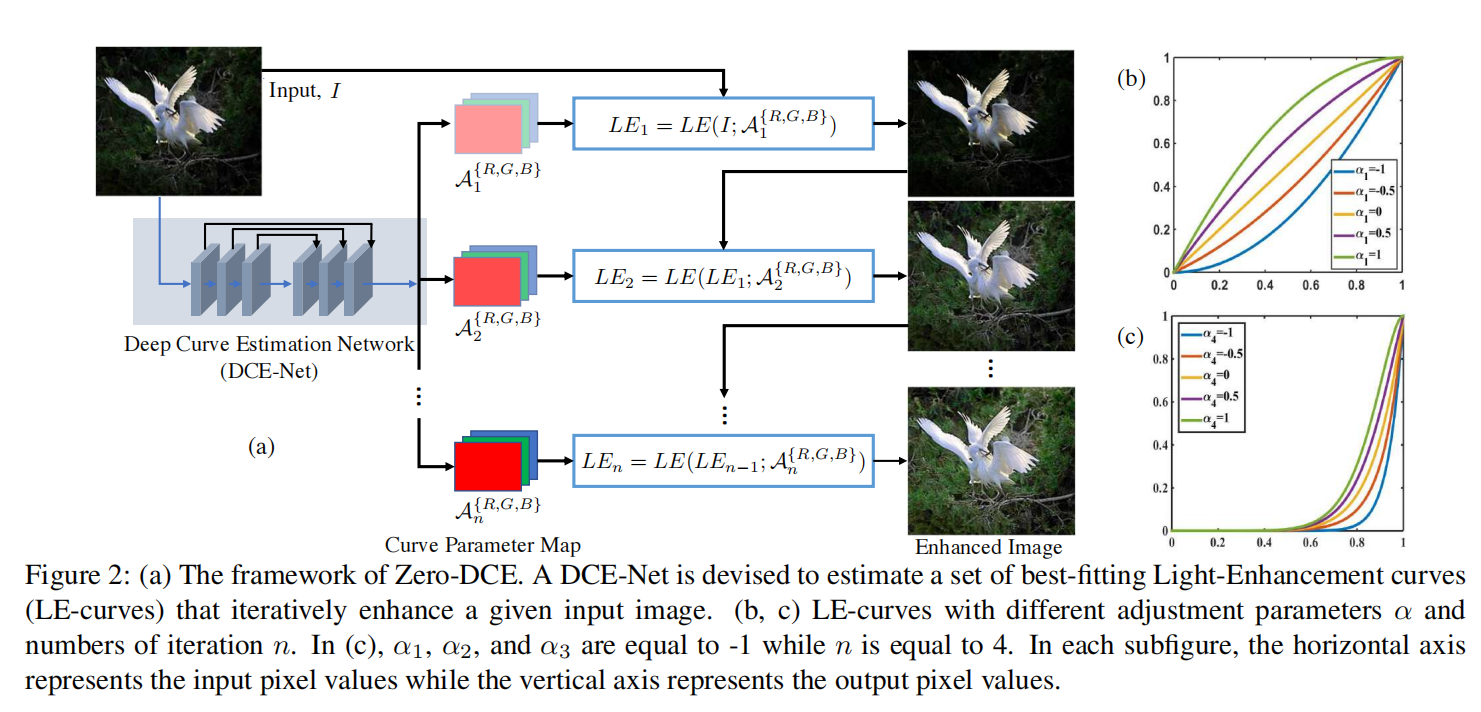
3、光照增强曲线
我们在图2中展示了Zero-DCE的框架。设计了一个深度曲线估计网络(DCE-Net),用于给定输入图像时估计一组最佳拟合的光照增强曲线(LE-curve)。该框架通过迭代应用这些曲线来映射输入图像RGB通道的所有像素,从而获得最终增强后的图像。接下来,我们将在以下部分详细说明Zero-DCE中的关键组件,即LE-curve、DCE-Net和无参考损失函数。





4、DCE-Net 网络结构



class enhance_net_nopool(nn.Module):
def __init__(self):
super(enhance_net_nopool, self).__init__()
self.relu = nn.ReLU(inplace=True)
number_f = 32
self.e_conv1 = nn.Conv2d(3,number_f,3,1,1,bias=True)
self.e_conv2 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv3 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv4 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv5 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True)
self.e_conv6 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True)
self.e_conv7 = nn.Conv2d(number_f*2,24,3,1,1,bias=True)
self.maxpool = nn.MaxPool2d(2, stride=2, return_indices=False, ceil_mode=False)
self.upsample = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, x):
x1 = self.relu(self.e_conv1(x))
x2 = self.relu(self.e_conv2(x1))
x3 = self.relu(self.e_conv3(x2))
x4 = self.relu(self.e_conv4(x3))
x5 = self.relu(self.e_conv5(torch.cat([x3,x4],1)))
x6 = self.relu(self.e_conv6(torch.cat([x2,x5],1)))
x_r = F.tanh(self.e_conv7(torch.cat([x1,x6],1)))
r1,r2,r3,r4,r5,r6,r7,r8 = torch.split(x_r, 3, dim=1)
x = x + r1*(torch.pow(x,2)-x)
x = x + r2*(torch.pow(x,2)-x)
x = x + r3*(torch.pow(x,2)-x)
enhance_image_1 = x + r4*(torch.pow(x,2)-x)
x = enhance_image_1 + r5*(torch.pow(enhance_image_1,2)-enhance_image_1)
x = x + r6*(torch.pow(x,2)-x)
x = x + r7*(torch.pow(x,2)-x)
enhance_image = x + r8*(torch.pow(x,2)-x)
r = torch.cat([r1,r2,r3,r4,r5,r6,r7,r8],1)
return enhance_image_1,enhance_image,r
5、损失函数
为了在DCE-Net中实现零参考学习,我们提出了一组可微的无参考损失函数,使我们能够评估增强图像的质量。以下是用于训练我们的DCE-Net的四种类型的损失。

class L_spa(nn.Module):
def __init__(self):
super(L_spa, self).__init__()
# 创造梯度卷积核
kernel_left = torch.FloatTensor( [[0,0,0],[-1,1,0],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)
kernel_right = torch.FloatTensor( [[0,0,0],[0,1,-1],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)
kernel_up = torch.FloatTensor( [[0,-1,0],[0,1, 0 ],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)
kernel_down = torch.FloatTensor( [[0,0,0],[0,1, 0],[0,-1,0]]).cuda().unsqueeze(0).unsqueeze(0)
# 使其可以参与到pythorch运算中
self.weight_left = nn.Parameter(data=kernel_left, requires_grad=False)
self.weight_right = nn.Parameter(data=kernel_right, requires_grad=False)
self.weight_up = nn.Parameter(data=kernel_up, requires_grad=False)
self.weight_down = nn.Parameter(data=kernel_down, requires_grad=False)
# 池化层定义
self.pool = nn.AvgPool2d(4)
def forward(self, org , enhance ):
# 按通道维度计算RGB同一像素位置的平均值 形成亮度图
org_mean = torch.mean(org,1,keepdim=True)
enhance_mean = torch.mean(enhance,1,keepdim=True)
# 池化操作
org_pool = self.pool(org_mean)
enhance_pool = self.pool(enhance_mean)
# 进行3*3卷积操作 边缘填充1 后者对前者进行卷积 得到和原来大小一样的梯度变化图
D_org_letf = F.conv2d(org_pool , self.weight_left, padding=1)
D_org_right = F.conv2d(org_pool , self.weight_right, padding=1)
D_org_up = F.conv2d(org_pool , self.weight_up, padding=1)
D_org_down = F.conv2d(org_pool , self.weight_down, padding=1)
D_enhance_letf = F.conv2d(enhance_pool , self.weight_left, padding=1)
D_enhance_right = F.conv2d(enhance_pool , self.weight_right, padding=1)
D_enhance_up = F.conv2d(enhance_pool , self.weight_up, padding=1)
D_enhance_down = F.conv2d(enhance_pool , self.weight_down, padding=1)
# 梯度差异计算 张量运算尺寸不变
D_left = torch.pow(D_org_letf - D_enhance_letf,2)
D_right = torch.pow(D_org_right - D_enhance_right,2)
D_up = torch.pow(D_org_up - D_enhance_up,2)
D_down = torch.pow(D_org_down - D_enhance_down,2)
E = (D_left + D_right + D_up +D_down)
return E

class L_exp(nn.Module):
def __init__(self,patch_size,mean_val):
super(L_exp, self).__init__()
# 池化层 利用池化层来指定范围情况
self.pool = nn.AvgPool2d(patch_size)
# 理想曝光水平
self.mean_val = mean_val
def forward(self, x ):
x = torch.mean(x,1,keepdim=True)
mean = self.pool(x)
d = torch.mean(torch.pow(mean- torch.FloatTensor([self.mean_val] ).cuda(),2))
return d

class L_color(nn.Module):
def __init__(self):
super(L_color, self).__init__()
def forward(self, x ):
# 按照w和h计算平均值 保持维度
mean_rgb = torch.mean(x,[2,3],keepdim=True)
# 按通道维度分开
mr,mg, mb = torch.split(mean_rgb, 1, dim=1)
# 进行损失计算
Drg = torch.pow(mr-mg,2)
Drb = torch.pow(mr-mb,2)
Dgb = torch.pow(mb-mg,2)
k = torch.pow(torch.pow(Drg,2) + torch.pow(Drb,2) + torch.pow(Dgb,2),0.5)
return k

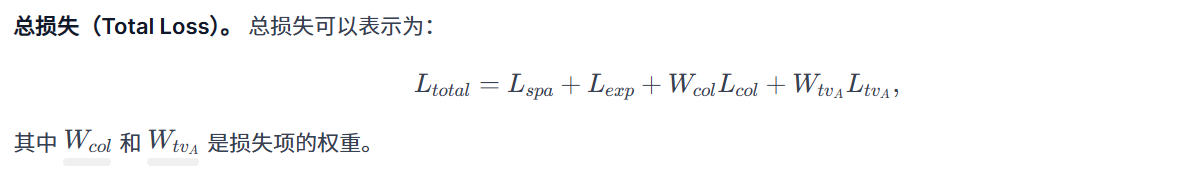
class L_TV(nn.Module):
def __init__(self,TVLoss_weight=1):
super(L_TV,self).__init__()
self.TVLoss_weight = TVLoss_weight
def forward(self,x):
batch_size = x.size()[0]
h_x = x.size()[2]
w_x = x.size()[3]
count_h = (x.size()[2]-1) * x.size()[3]
count_w = x.size()[2] * (x.size()[3] - 1)
h_tv = torch.pow((x[:,:,1:,:]-x[:,:,:h_x-1,:]),2).sum()
w_tv = torch.pow((x[:,:,:,1:]-x[:,:,:,:w_x-1]),2).sum()
return self.TVLoss_weight*2*(h_tv/count_h+w_tv/count_w)/batch_size
6、数据集
训练数据集:我们采用了来自SICE数据集Part1中的360个多曝光序列 [4] 来训练所提出的DCE-Net。我们将Part1子集中不同曝光级别的3,022张图像随机分为两部分(2,422张用于训练,其余用于验证)。我们将训练图像调整为512×512的尺寸。
Tips:这些结果表明在我们网络的训练过程中使用多曝光训练数据的合理性和必要性。



















 4123
4123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









