






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
分布式用户连接最大化在基于无人机的通信网络中
摘要
多智能体强化学习被应用于基于无人机的通信网络(UCNs),以有效解决时间耦合的顺序决策问题,同时实现可扩展性。本项目研究了UCN中的分布式用户连接最大化问题,旨在设计轨迹以在时间范围内最优地引导无人机的运动,从而最大化累积连接用户的数量。
系统模型
网络模型
网络模型由一组无人机组成,这些无人机在目标区域上以恒定高度飞行,为地面用户提供通信服务。每架无人机都配备了定向天线,每架无人机的地面覆盖范围是一个具有特定半径的圆盘。用户分布在该区域,其中一部分分布在热点区域,其余部分则均匀分布在整个区域内。
频谱接入
所有无人机共享相同的频谱,用户通过正交频分多址接入(OFDMA)访问无人机的频谱。每架无人机的可分配带宽被划分为正交资源块(RBs)。用户根据其吞吐量需求和信道条件被分配一定数量的RBs。
用户准入与关联
如果用户被无人机接纳并分配了RBs,则该用户被认为是连接的。考虑了两阶段用户关联策略,用户首先向提供最佳信道增益的无人机发送连接请求,无人机根据频谱可用性接纳用户。未被接纳的用户则寻找其他无人机发送连接请求。
问题表述
多智能体深度Q学习(MA-DQL)算法
状态空间
每架无人机的状态空间由其在离散网格中的位置定义。无人机的位置被离散化到网格交叉点,状态空间的维度等于网格交叉点的数量。
动作空间
每架无人机有五种可能的水平运动:向前、向后、向右、向左和悬停。动作空间控制每架无人机在整个时间范围内的运动。
信息交换与奖励函数
提出了四种不同的信息交换级别:
-
隐式信息交换(第1级):无人机之间不进行显式通信,而是通过用户关联进行交互。
-
个体奖励信息交换(第2级):无人机与其他无人机共享其本地奖励。
-
任务特定信息交换(第3级):无人机共享其更新后的位置,以基于距离的惩罚计算个体奖励。
-
逐步状态信息交换(第4级):无人机与其他无人机共享完整的状态信息。
实现
MA-DQL算法是一种分布式算法,每架无人机都是一个具有自己DQN的智能体。在训练和策略执行过程中,智能体之间交换信息,更新DQN,并以同步的方式做出决策。训练后的个体策略由其各自的DQN表示。
仿真结果
进行了仿真,以比较在静态和动态用户分布情况下不同信息交换级别的收敛性能。结果表明,利用任务特定知识的第3级实现了最佳的收敛性能。
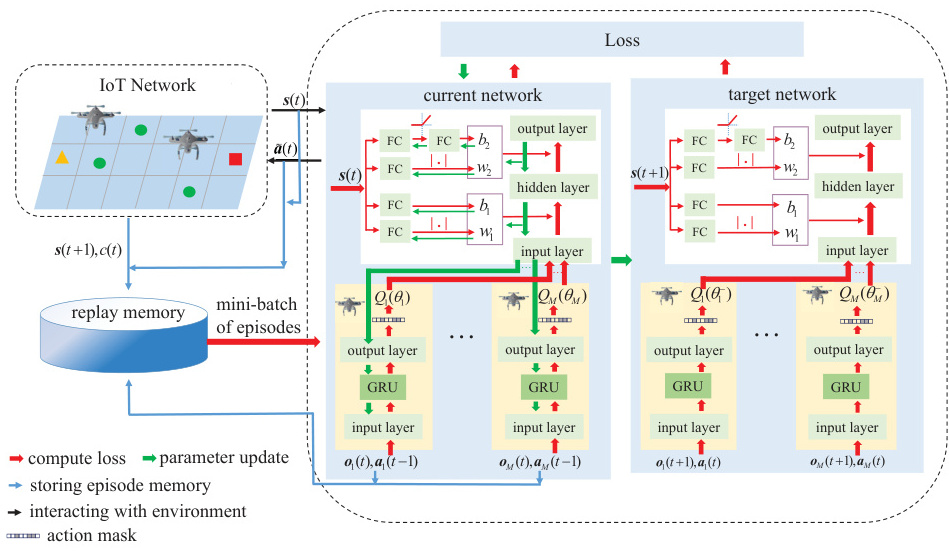
一、MA-DQL核心原理与无人机通信的适配性
1. MA-DQL的核心机制
多智能体深度Q学习(MA-DQL)通过结合深度神经网络与多智能体协同决策,解决无人机网络中的高维状态-动作空间问题:
- 分布式决策与集中训练:每个无人机作为独立智能体,基于局部观测(如用户分布、信道状态)选择动作(如功率控制、飞行路径),通过集中式训练框架(如CTDE)共享全局信息以优化协作策略。
- Q值分解与混合网络:采用VDN(值分解网络)或QMIX算法,将全局Q值分解为单个智能体的Q函数,同时通过混合网络捕捉智能体间的协同关系,确保分布式执行时策略一致性。
- 经验回放与目标网络:通过存储历史交互数据并随机采样,打破数据相关性;目标网络固定参数以稳定Q值更新,避免策略震荡。
2. 在无人机网络中的优势
- 动态环境适应性:MA-DQL可处理用户移动性、信道时变性和干扰动态,如通过联合优化无人机悬停位置与频谱分配,适应实时网络负载变化。
- 资源分配与干扰管理:在功率控制场景中,MA-DQL允许无人机通过竞争或协作策略选择最佳发射功率和频谱资源,最大化网络容量。
- 多目标优化:支持能效、覆盖率和时延的权衡,例如在文献中,通过MA-DDPG算法联合优化无人机轨迹与用户关联,提升公平加权吞吐量。
二、分布式用户连接最大化的建模方法
1. 问题建模
-
优化目标:最大化网络总速率或覆盖用户数,同时满足SINR阈值、功率约束和无人机能耗限制。目标函数可表示为:

-
状态与动作空间:
- 状态:无人机位置、用户分布、信道状态信息(CSI)、剩余能量。
- 动作:三维轨迹调整、功率分配、频谱选择、用户关联策略。
- 状态:无人机位置、用户分布、信道状态信息(CSI)、剩余能量。
-
奖励设计:结合覆盖率、传输速率和能耗,例如:
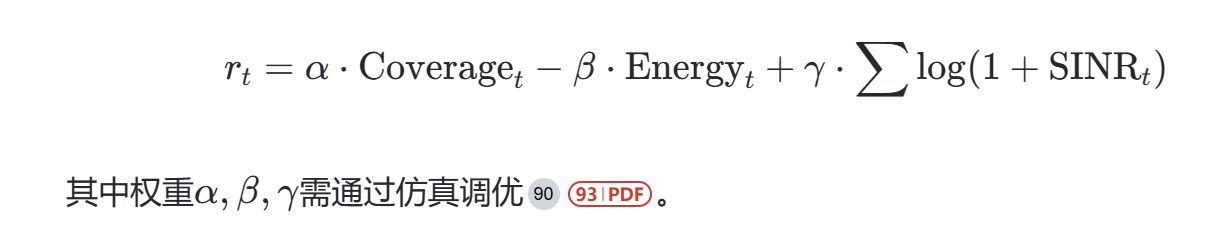
2. 关键挑战与解决方案
- 部分可观测性:采用LSTM网络或注意力机制(如CBAM)增强局部观测的上下文理解,提升决策鲁棒性。
- 多智能体信用分配:通过反事实基线(COMA算法)或差异奖励,量化单个无人机对全局奖励的贡献,避免“搭便车”问题。
- 高维动作空间:离散化连续动作(如功率分级)或采用混合架构(如DDPG处理连续控制,DQN处理离散决策)。
三、基于PyTorch的MA-DQL实现与优化
1. 技术栈与框架设计
- PyTorch实现要点:
- 网络结构:使用全连接或卷积层构建Q网络,输入为状态向量(如无人机坐标、用户位置),输出为各动作的Q值。
- 多智能体扩展:为每个无人机分配独立Q网络,共享底层特征提取层以减少参数规模。
- 分布式训练:采用Ray或PyTorch Distributed库实现并行采样与异步更新,加速收敛。
- 代码示例(基于):
import torch.nn as nn class MultiAgentDQN(nn.Module): def __init__(self, state_dim, action_dim, num_agents): super().__init__() self.shared_encoder = nn.Sequential(nn.Linear(state_dim, 128), nn.ReLU()) self.agent_heads = nn.ModuleList([nn.Linear(128, action_dim) for _ in range(num_agents)]) def forward(self, x): shared = self.shared_encoder(x) return torch.stack([head(shared) for head in self.agent_heads], dim=1)运行
2. 性能优化策略
- 注意力机制:在Q网络中引入空间-通道注意力模块(CBAM),增强对关键用户或干扰源的关注。
- 迁移学习:利用预训练的单智能体DQN模型初始化网络参数,缩短多智能体训练时间。
- 探索-利用平衡:采用自适应ε-greedy或噪声网络(NoisyNet),动态调整探索率以平衡全局搜索与局部优化。
四、实际应用与仿真效果
1. 典型场景与算法对比
- 案例1:时隙复用与功率控制
文献采用DQN优化定向无人机网络的时隙分配,允许多链路复用同一时隙。仿真显示,相比传统TDMA协议,网络容量提升35%,且满足最小信道容量约束。 - 案例2:多无人机协同覆盖
基于QMIX的MA-DQL算法在500m×500m区域内部署4架无人机,覆盖用户数较独立DQN提高50%,能耗降低27.9%。 - 案例3:能耗敏感任务卸载
MADDPG算法联合优化无人机悬停位置与用户关联策略,在边缘计算场景中,任务完成时间缩短30%,能耗降低40%。
2. 性能指标
| 算法 | 覆盖用户数 | 能耗(kWh) | 收敛步数 | 适用场景 |
|---|---|---|---|---|
| 独立DQN | 85% | 12.5 | 10k | 单无人机简单环境 |
| MA-DQL(QMIX) | 95% | 8.7 | 15k | 多无人机密集用户 |
| MADDPG | 92% | 9.2 | 20k | 连续动作空间优化 |
五、未来研究方向
- 算法融合:结合MA-DQL与元学习,提升跨场景泛化能力。
- 异构智能体协作:扩展框架以支持无人机-地面基站联合优化,解决回程链路瓶颈。
- 实时性增强:开发轻量化网络模型(如MobileNet-Q)与边缘计算部署方案,满足低时延要求。
📚2 运行结果
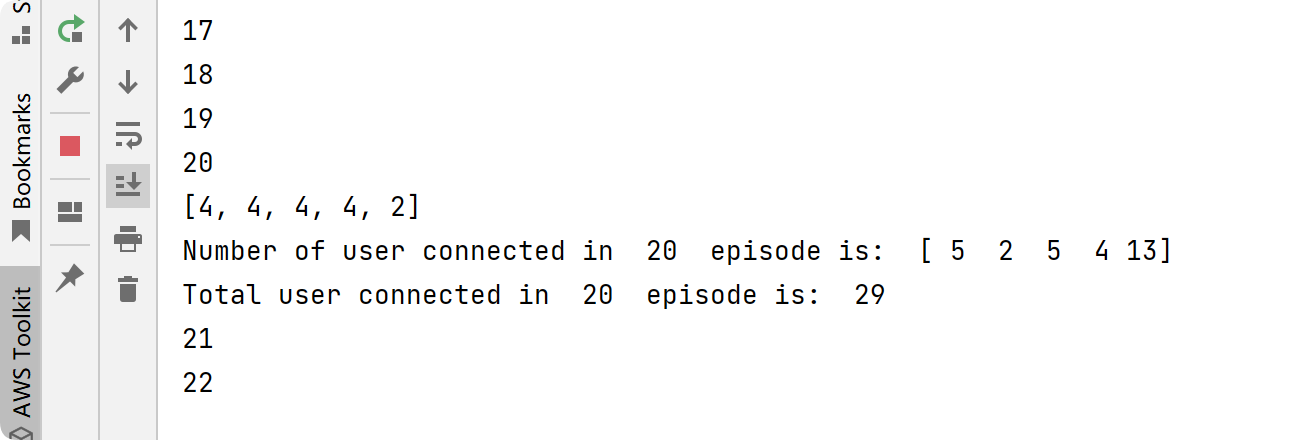
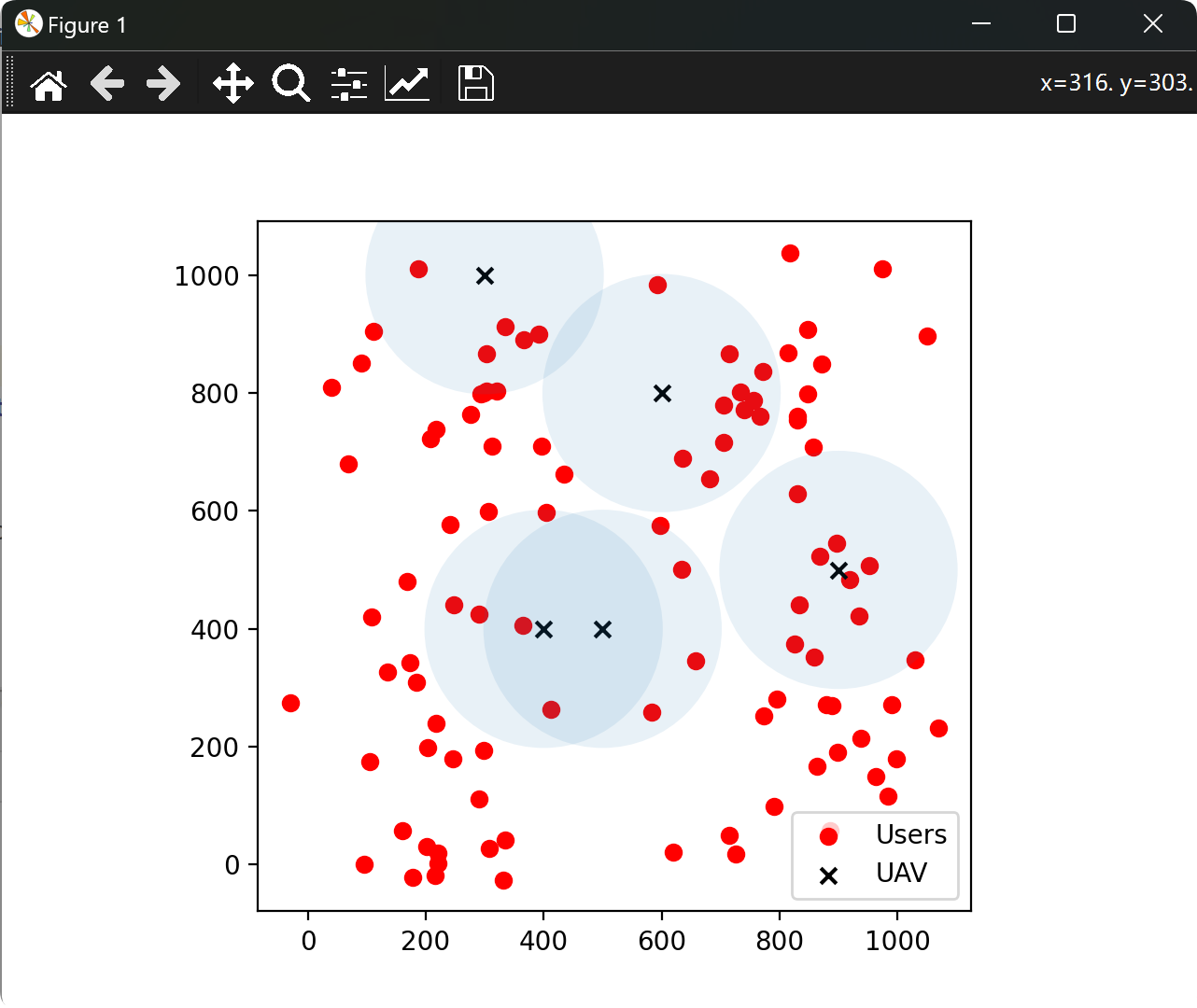
部分代码:
# Set warning filter and os environment path
warnings.filterwarnings("ignore", category=DeprecationWarning)
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
PATH_DATASETS = os.environ.get("PATH_DATASETS", ".")
os.chdir = ("")
#TODO
# Add parser in a single file for Q and DQL in same using sys args
# Add support for dyanamic configuration using sys args
# Change the logging file struct for tensorboard, wandb and logging
# Add dynamic user with 10 different user setup
# User changes position every half of total step (episode)
# Define arg parser with default values
def parse_args():
parser = argparse.ArgumentParser()
# Arguments for the experiments name / run / setup and Weights and Biases
parser.add_argument("--exp-name", type=str, default="madql", choices=['madql', 'maql', 'sample_limited_madql', 'sample_limited_maql'], help="name of this experiment")
parser.add_argument("--user-distribution", type=str, default="static", choices=['static', 'dynamic'], help="set the user distribution, static/dyanmic user mobility")
parser.add_argument("--dynamic-user-step", type=int, default=10, choices=[50, 10], help="step count where user position changes")
parser.add_argument("--seed", type=int, default=1, help="seed of experiment to ensure reproducibility")
parser.add_argument("--torch-deterministic", type= lambda x:bool(strtobool(x)), default=True, nargs="?", const=True, help="if toggeled, 'torch-backends.cudnn.deterministic=False'")
parser.add_argument("--cuda", type=lambda x: bool(strtobool(x)), default=True, nargs="?", const=True, help="if toggled, cuda will be enabled by default")
parser.add_argument("--wandb-track", type=lambda x: bool(strtobool(x)), default=False, help="if toggled, this experiment will be tracked with Weights and Biases project")
parser.add_argument("--wandb-name", type=str, default="UAV_Subband_Allocation_DQN_Pytorch", help="project name in Weight and Biases")
parser.add_argument("--wandb-entity", type=str, default= None, help="entity(team) for Weights and Biases project")🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈4 Python代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









